
Abstract
This paper presents a method that uses engineering change forecast to identify and prioritise product components for modularisation. The method uses a matrix-based technique to map change requirements to affected product components and later converts the said matrix into a component dependency matrix referred to in this work as the Engineering Change Forecast (ECF) matrix. The risk of change for each component is subsequently computed based on the ECF matrix to prioritise components for modularisation. The method was applied to support modularisation efforts pertaining to the design of a truck at a multinational engineering firm based in Germany. Six hundred and forty-three change requirements were considered in this work. As a comparison study, an analysis was made at the component level and repeated at the sub-component level. It was found that out of the top ten sub-components that were ranked with high modularisation priority, nine are sub-components of the top three components prioritised for modularisation when the analysis was done at the component level. This suggests that the method can produce consistent results over different levels of modelling granularity.
Similar content being viewed by others


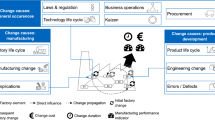
1 Introduction
It is common for products and systems to undergo engineering changes to meet new requirements. Usually, the aim is to meet the requirements with as little change as possible (Eckert et al. 2012). However, such endeavours can be tricky as changes can sometimes propagate, resulting in further changes to the design (Clarkson et al. 2004; Koh and Clarkson 2009; Maier and Langer 2011; Langer et al. 2012; Morkos et al. 2012; Bauer et al. 2015). Koh et al. (2012) define the propagation of engineering changes (i.e. engineering change propagation) as ‘the process by which an engineering change to parts of a product results in one or more additional engineering changes to other parts of the product, when those changes would not otherwise have been required’, where engineering change itself is defined by Jarratt et al. (2011) as ‘an alteration made to parts, drawings or software that have already been released during the product design process. The change can be of any size or type; the change can involve any number of people and take any length of time’. According to Eckert et al. (2004), it is possible for changes to propagate uncontrollably resulting in change ‘avalanches’. There is, hence, an incentive to develop engineering products and systems that can be easily changed.
Efforts to improve the changeability of engineering products are well documented by various researchers (Martin and Ishii 2002; Fricke and Schulz 2005; Palani Rajan et al. 2005; Jiao et al. 2007; Suh et al. 2007; Hamraz et al. 2012; Cardin et al. 2013; Hu and Cardin 2015). Some research also reveals that modularity can be the key to support changeability (Baldwin and Clark 2000; Jiao et al. 2007; Ross et al. 2008; Saleh et al. 2009; Krause et al. 2013; Hölttä-Otto et al. 2013). For instance, Ulrich and Eppinger (2012) point out that ‘modular chunks allow changes to be made to a few isolated functional elements of the product without necessarily affecting the design of other chunks. Changing an integral chunk may influence many functional elements and require changes to several related chunks’. This suggests that components that are modular can better contain changes and are also less likely to be affected by change propagation from other components.
Modularisation efforts can be carried out during the planning stage of an entirely new product by designing a highly modular product architecture right from the start (Ulrich 1995). However, in many cases, incremental improvements are made to existing product architectures instead due to legacy designs (Kreimeyer et al. 2014). This paper focuses on the latter scenario. Ideally, all product components should be made highly modular to minimise the impact of future changes. However, due to resource and financial constraints, it may not be possible to modularise all components at the same time. There is hence a need to prioritise modularisation efforts.
In this paper, a method that aims to better prioritise modularisation efforts is presented. The method converts change requirements into engineering change forecasts to identify product components that are vulnerable to changes. Subsequently, the risk of change for each component is computed based on the forecast and used to prioritise components for modularisation. The assumption is that components that are more exposed to changes can benefit more through modularisation and hence should be given priority to be modularised. The authors acknowledge that developing clean interfaces and ensuring independence between components is not a straightforward task and there may be other driving forces advocating for integral design solutions that are purposefully optimised (e.g. designing integral components with higher mechanical strength or pre-defined weight distribution) (Borjesson 2012). Nevertheless, this work can be used to better support decision makers in their modularisation efforts from a change perspective. The method was applied to support modularisation efforts pertaining to the design of a truck at a multinational engineering firm. The findings suggest that the method is consistent even when different levels of modelling abstraction are used.
The remainder of this paper is organised as follows: Sect. 2 further discusses the background and motivation of this work. Section 3 provides a step-by-step description of the method developed. Section 4 describes how the method can be applied using an industrial case example. Section 5 discusses the sensitivity analysis carried out in this work. Lastly, a summary of this work is provided in Sect. 6.
2 Background and motivation
Research in the modularisation of engineering products and systems is well documented in the literature. As classified by Gershenson et al. (2004), most work contributes to the development of methods to improve product modularity and the development of measures to assess product modularity. For instance, Sosa et al. (2003) describe an approach to identifying modular and integrative systems and assess their impact on design teams. Sered and Reich (2006) propose a method to identify modularisation opportunities by estimating and comparing the reduction in future design effort when different components are modularised. Yu et al. (2007) present a clustering method based on a simple genetic algorithm to partition product architectures into sets of modules where the interactions between modules are minimised. Sosa et al. (2007) introduce a technique to measure the level of modularity for components within complex products. Tchertchian et al. (2013) propose a method to identify modules from a re-manufacturing perspective. Koh et al. (2013) propose a method that can systematically examine the changeability of modules within complex engineering products based on their likelihood and impact of change. Borjesson and Hölttä-Otto (2014)present a module generation algorithm that considers the strategic requirements of the product and the interactions between different components.
The topic of modularity is also heavily discussed in research focusing on product platform and product family design (Meyer and Lehnerd 1997). For instance, a number of researchers suggest that commonality can be used as an indicator to support the identification of suitable platform modules (Jiao and Tseng 2000; Siddique and Rosen 2001; Simpson and D’Souza 2004). One of the most frequently used commonality indicator is functional commonality (McAdams et al. 1999; Stone et al. 2000; Nanda et al. 2005). The concept is to group system elements that share the same functions into independent modules that can be reused in future product variants. As an extensive discussion on the use of modularity and platform-based product family development is recently summarised by Simpson et al. (2013), a broad review of previous work will not be further discussed here. However, it is worthwhile to point out that the design context described in most work usually focuses on designing modular product architectures rather than redesigning existing product architectures to be more modular. As a result, prioritisation and integration issues are usually not discussed in the literature as modularisation is seldom seen as an incremental effort.
In this work, we developed a method that can better identify and prioritise product components for modularisation. The research is driven by an industrial need to incrementally redesign existing product architectures to be more modular. The work was carried out with reference to the design research methodology (DRM) presented by Blessing and Chakrabarti (2009). This paper focuses on introducing the output of our prescriptive study (Sect. 3) and describing the findings obtained when the method was applied in an industrial setting (Sect. 4).
3 Prioritising modularisation efforts
This section describes a method that uses engineering change forecast to better identify and prioritise product components for modularisation. The method consists of four steps as shown in Fig. 1. In Step 1, product components that may be affected by future change requirements are systematically forecasted and indicated in a matrix similar to the Domain Mapping Matrix (DMM) presented by Danilovic and Browning (2007). The goal is to identify the components targeted for change. Subsequently in Step 2, the DMM is converted into a square matrix to examine the asymmetrical change dependencies between product components. As described by Browning (2001) and Eppinger and Browning (2012), this square matrix is commonly referred to as the Design Structure Matrix (DSM). In Step 3, the change risk for each component is computed based on the information captured in the DSM. An additional column will later be inserted on the right of the DSM to summarise the computed change risk. The resulting matrix is referred to as the Engineering Change Forecast (ECF) matrix in this work. Subsequently, the computed change risk will be arranged in a descending order to sequence the product components in terms of their modularisation priority. The higher the change risk for a given component, the higher the priority to modularise it. Further details on each step are provided in the following subsections.

Framework of the method
3.1 Step 1: Map change requirements to product components
The goal of this step is to systematically identify product components that may require change due to future change requirements. It is carried out by mapping change requirements (e.g. ‘improved concept fuel filtering’) to product components (e.g. ‘gearbox’ and ‘fuel tank’) using a Domain Mapping Matrix (DMM) as shown in Fig. 2. The row headings of the DMM represent the change requirements to be addressed, while the column headings represent all the product components. The matrix can be populated by going through each change requirement row by row to systematically assign appropriate change dependencies to the affected product components. This can be carried out through interdisciplinary workshops with relevant staff members.

Using a DMM to map change requirements to product components
In this work, the terms ‘Responsible’, ‘Supporting’, and ‘Informing’ as described by Oppenheim et al. (2011) are adapted to represent the different types of change dependencies. An ‘R’ rating (i.e. Responsible) is assigned to a product component when it is identified as the primary change target to address a given change requirement, indicating that staff members linked to the component are responsible for the change. A ‘S’ rating (i.e. Supporting) is assigned to product components that are indirectly affected by the targeted change due to change propagation, indicating that staff members linked to the components will be supporting the change. An ‘I’ rating (i.e. Informing) is assigned to product components that may require minor changes due to change propagation, but the probability of changing them is low. This indicates that staff members linked to these components should be informed. For instance, with reference to Fig. 2, the ‘R’ rating in the second row fourth column indicates that Component D is identified as the primary change target to address Change Requirement II. The ‘S’ rating in the second row third column indicates that Component C is very likely to be affected by change propagation from Component D when addressing Change Requirement II. The ‘I’ rating in the second row fifth column indicates that Component E may need to undergo minor changes due to change propagation from Component D, but the probability of changing it is low.
In the case example presented in the later part of this paper, the rating of each change dependency was discussed in depth by relevant staff members in interdisciplinary workshops and reviewed by external experts from academia and consulting to ensure an accurate and unbiased reflection of the results. This consensus-based approach to determining change dependencies is similar to the one documented by Clarkson et al. (2004). However, unlike Clarkson et al. (2004) which elicits direct (first-order) change propagation dependencies to compute indirect ones (second-order and beyond), all change propagation dependencies (direct and indirect) presented in the case example were elicited straight from the workshops.
3.2 Step 2: Determine the change dependencies between product components
In the second step, the DMM produced in Step 1 is converted into a component-to-component Design Structure Matrix (DSM) using a novel DMM-to-DSM conversion technique. The technique consists of a series of mathematical matrix operations and is further described in the following subsections.
3.2.1 Matrix preparation
In order to facilitate the mathematical matrix operations, the ‘R’, ‘S’, and ‘I’ entries in the DMM are replaced by numerical values as shown in Fig. 3. In this work, ‘1’, ‘1’, and ‘0.1’ are used to replace ‘R’, ‘S’, and ‘I’ entries, respectively, in the first DMM matrix (DMM1). The value ‘1’ is used to replace both ‘R’ and ‘S’ entries as these two types of change dependencies are viewed as having a high and equal level of significance (a sensitivity analysis on the choice of numerical values for the ‘R’, ‘S’, and ‘I’ entries is presented in Sect. 5). In contrast, the value ‘0.1’ is used to represent a much lower level of significance for change dependencies with an ‘I’ entry. Cells without entries (i.e. no dependency) are assigned a value of ‘0’. Subsequently, a second DMM matrix (DMM2) that highlights the primary change targets is generated by using ‘1’, ‘0’, and ‘0’ to replace the ‘R’, ‘S’, and ‘I’ entries, respectively (see Fig. 3). The purpose of generating DMM2 is to provide a means to identify the origin of change propagation in the matrix operations to be described in Sect. 3.2.2. Similar to DMM1, cells without entries are assigned a value of ‘0’.

Using numerical DMM entries to facilitate matrix operations
3.2.2 Matrix multiplication
Although the DMM matrices shown in Fig. 3 are all in the form of a rectangular (requirements × components) matrix, a square (components × components) DSM matrix can be generated by simply multiplying a DMM with its transpose (Kreimeyer and Lindemann 2011). However, the resulting DSM matrix will be symmetrical if identical source entries are used for the matrix multiplication (i.e. multiplying DMM1 with the transpose of DMM1). Such DSM matrices have limited use as they cannot highlight asymmetrical change dependencies. Therefore, in this work, DMM2 is also used in the matrix multiplication to mark the primary change targets and consequently establish the origin of change propagation (see Fig. 4). The result is an asymmetrical DSM matrix with column headings representing the change-initiating product components and row headings representing the change-receiving product components. The diagonal of the DSM indicates the number of times a product component is identified as the primary change target. For example, the diagonal entry for Component C is ‘2’ as it is identified as the primary change target on two occasions (refer to the column under Component C in the DMM shown in Fig. 3). The off-diagonal entries indicate the strength of change dependencies between product components. For instance, out of the two occasions when Component C is the primary change target, Component A is expected to be affected due to Change Requirement III (see DMM in Fig. 3). Hence, a value of ‘1’ is produced in the DSM under the column for Component C and the row for Component A as a result of the matrix multiplication operation. Likewise, given that Component D is expected to be affected twice due to Change Requirement III and IV, a value of ‘2’ is produced in the DSM under the column for Component C and the row for Component D. A value of ‘0.1’ is produced under the column for Component C and the row for Component B as Component B may require minor changes due to change propagation from Component C, but the probability of change is low (see Change Requirement IV of the DMM in Fig. 3). Equation 1 shows how the matrix operation described above is expressed mathematically.

Generating a DSM using DMM matrix multiplication
3.3 Step 3: Estimate and rank the change risk for each product component
Based on the DSM produced in Sect. 3.2, the overall change risk for each product component can be computed by examining how it can be affected through targeted changes and component-to-component change propagation. This is carried out by summing up the row entries as shown in Fig. 5. In this work, the sum of each row is referred to as an Engineering Change Forecast (ECF) index for the corresponding product component. For instance, the ECF index for Component A is ‘2’. The ECF index is described as a ‘forecast’ as the predicted change risk is derived directly from change demands. For instance, the extent of change propagation is fully estimated through expert judgement in the form of ‘R’, ‘S’, and ‘I’ ratings captured through interdisciplinary workshops by company staff members. The connectivity between product components is not explicitly examined. It is also important to note that the ECF indices shown in Fig. 5 do not differentiate between components that are mildly affected by multiple sources and components that are affected multiple times by just one or two sources. This is because there is no evidence to suggest that the former is more severe than the latter and vice versa. Therefore, both cases are perceived to have the same level of significance in this work. As the computed ECF indices are presented as an additional column to the right of the original DSM generated in Step 2, the resulting matrix is referred to as the Engineering Change Forecast (ECF) matrix.

Engineering Change Forecast (ECF) matrix
The ECF indices computed are subsequently arranged in a descending order as shown in Fig. 6 to rank product components in terms of their modularisation priority. As discussed previously, product components with high ECF indices are more vulnerable to engineering changes and hence are ideal candidates to be made more modular. Therefore, product components that are ranked towards the top of the ranking should be assigned a higher priority to be made more modular. For example, with reference to Fig. 6, Component C should be assigned a higher priority to undergo modularisation compared to the rest of the components. In contrast, Component B should be assigned a lower priority. Modularisation efforts can therefore be prioritised systematically by using the method described in this section. It should, however, be pointed out that the ranking produced is strictly based on a change perspective, and other influences, such as the strategic value of each component, are not considered in this work.

Ranking product components by their Engineering Change Forecast (ECF) index
4 Case example
As mentioned previously, this research is driven by an industrial need to develop a more systematic way to incrementally improve the modularity of existing product architectures. The output is a method that uses engineering change forecast to identify and prioritise product components for modularisation. To demonstrate the feasibility of the method, it was applied to a case example provided by the industrial partner of this work. This section provides a detailed account of the analysis made.
4.1 Background of industrial partner
The industrial partner of this work is a major producer of commercial vehicles with a product portfolio consisting of light-duty and heavy-duty trucks, coaches, and buses. It is based in Germany and is a market leader for the commercial vehicle industry. The company has about 50,000 employees and generates about €15 billion of annual revenues. The primary niche of the industrial partner is the development of commercial vehicles that can support mass customisation for specialised markets. The vehicles designed by the industrial partner therefore need to have highly modular product architectures that can support a wide range of applications and market segments (Kreimeyer et al. 2013, 2014). Over the years, a stronger emphasis on product architecture planning has been put in place at the company, especially during the concept design phase (Kreimeyer 2012). The work described in this paper seeks to contribute to this continuing initiative to better support modularisation efforts. The coordination of this work at the industrial partner was led by the Engineering Architecture Department with inputs from various staff members captured from internal interdisciplinary workshops (Karrer-Müller et al. 2013). An evaluation of this work was also carried out by the Engineering Architecture Department and discussed in Sect. 4.3.
4.2 Applying the method on a truck design
The method presented in Sect. 3 was applied with the industrial partner to support the design of a modular product architecture for a truck. The modelling data used in this work were derived from an existing dataset previously acquired through a series of workshops with concept development experts at the industrial partner. The dataset is primarily used to support strategic portfolio planning and exists in the form of a Domain Mapping Matrix (DMM) as shown in Fig. 7. Note that the original dataset uses the German terms ‘Verantwortlich’, ‘Mitarbeiten’, and ‘Informiert’ to describe ‘Responsible’, ‘Supporting’, and ‘Informing’, respectively (Kreimeyer 2014). Sensitive details were removed due to confidentiality issues (an excerpt of the original dataset is provided in the "Appendix 1"). The row headings represent change requirements such as ‘improve concept fuel filtering’ and ‘allow for more fuel’. These change requirements were elicited from customers and extracted from the overall specification book worked out by the product management departments at the company. They cover a range of issues such as marketing, engineering capacities, and technical restrictions for a time horizon beyond the year 2020. A total of 643 change requirements were considered in this dataset. The column headings represent different product components that make up the truck, and two levels of granularity were used to represent them in the dataset: one at the component level (17 components, as shown in Fig. 7) and the other at the sub-component level (144 sub-components, to be discussed in Sect. 5). Note that the two granularity levels were not artificially created for this research and exist prior to this work for business administration reasons.

An excerpt of the dataset used in this work
The mapping between the product component domain and the change requirement domain in the DMM was carried out as part of a regular concept design process by staff members in interdisciplinary workshops based on the company’s standard methodology (Karrer-Müller et al. 2013). Each mapping was discussed in depth within the performing concept team and reviewed by external experts from academia and consulting to ensure an accurate and unbiased reflection of the results. However, the authors acknowledge that some dependencies may still be overlooked in the workshops and ‘unexpected’ change propagation may occur later. The use of change prediction techniques such as Koh et al. (2012) to systematically examine direct and indirect change propagation is thus recommended to better support the mapping of change dependencies (note that change prediction techniques were not used in this case example but is part of an ongoing work at the industrial partner).
The DMM shown in Fig. 7 was later converted into a component-to-component Design Structure Matrix (DSM) using the novel DMM-to-DSM conversion technique described earlier in this work. The ‘R’, ‘S’, and ‘I’ entries were replaced with ‘1’, ‘1’, and ‘0.1’ entries, respectively. According to the industrial partner, the use of the value ‘1’ to replace both the ‘R’ and ‘S’ entries is justified as they represent the same level of change and only differ in terms of whether the engineers involved are Responsible (‘R’) or Supporting (‘S’) the change. The use of the value ‘0.1’ to replace the ‘I’ entries is also justified as they are known to have significantly lesser importance. The set of numerical values used in this analysis can thus be considered as homomorphous to the implied semantics (Zuse 1998). Further discussions on the choice of numerical values for the ‘R’, ‘S’, and ‘I’ entries are presented in Sect. 5.
The Engineering Change Forecast (ECF) index for each product component was subsequently computed as shown in Fig. 8. It can be seen from Fig. 8 that Component 14 was identified as the primary change target on 162 occasions based on the 643 change requirements considered (see diagonal entry for Component 14). It is the primary change target for the highest number of times followed by Component 7 (139 times) and Component 16 (79 times). In contrast, Component 5 was identified as the primary change target on only one occasion. Component 13 was also identified as the component that is most affected by engineering change propagation due to changes arising from another component. It has an off-diagonal row entry of ‘127.2’ on the column under Component 14. The entry consists of decimal values as the ‘I’ entries shown in Fig. 7 was replaced by the value ‘0.1’ in the matrix operations. Hence, Component 13 was in fact identified on more than 127 occasions to be vulnerable to change propagation arising from Component 14.

Engineering Change Forecast (ECF) matrix of the truck
The product components were later ranked according to their ECF indices as shown in Fig. 9. It was found that Component 14 has the highest ECF index of ‘389.6’ and hence should be given a higher priority to be made more modular. In contrast, Component 5 has the lowest ECF index of ‘14.7’ and should be given a lower priority. It should also be pointed out that Component 16 which was identified as the primary change target for 79 times (third highest) was only ranked fifth in Fig. 9. This suggests that the forecasted change propagation between product components (off-diagonal entries) can play a non-trivial role in this analysis. The impact of considering change propagation in the computation of ECF indices is further discussed in Sect. 5.

Ranking of truck components by Engineering Change Forecast (ECF) index
4.3 Feedback from industrial partner
The findings presented in Sect. 4.2 were subsequently discussed with the industrial partner. It was revealed that the top three components shown in Fig. 9 are in fact the ‘Interior’ (Component 14), the ‘Electrics/Electronics’ (Component 7), and the ‘Cabin’ (Component 13). In addition, the Cabin has always been designed as a separate module at the company. The Interior, however, was not an obvious candidate to be made into a separate module. This is due to the fact that the Interior is confined within the Cabin and is perceived as having low change dependency with the rest of the truck. A re-examination of the ECF matrix shown in Fig. 8 was therefore conducted. It was revealed that the Interior is the target of change for 162 out of the 643 (25 %) change requirements. This confirms that the Interior is indeed very vulnerable to engineering changes, and hence, the high priority ranking is justified. Regarding Electrics/Electronics, the industrial partner commented that it will be very difficult to design it as a separate module given that it has a lot of interfaces. However, the need for modularisation should be independent from the ease of modularisation. Hence, from an engineering change forecast perspective, the high priority ranking for the Electrics/Electronics is justified as it is the target of change for 139 out of the 643 (more than 20 %) change requirements. Component 5 shown in Fig. 9 was identified as the Cooling System of the truck and is ranked the lowest in terms of modularisation priority. The low ranking is supported by the industrial partner which revealed that the Cooling System is indeed a relatively small component with little change risk. In fact, it should have been considered at the sub-component level if not for its importance in the context of addressing new emission standards. Hence, in summary, the results produced were found to be reasonable by the industrial partner. It was also revealed that the method is useful in providing a structured means to analyse and compare product components in terms of their exposure to engineering change. For instance, by using components such as the Cabin (highest ECF index) and the Cooling System (lowest ECF index) as benchmarks, critical components that are less obvious (e.g. the Interior) can be highlighted systematically and be assigned a higher priority for modularisation.
5 Discussion
The findings from Sect. 4 suggest that the method described in this paper is feasible in an industrial setting. In this section, the sensitivity of the results produced in Sect. 4 is further discussed with respect to the set of numerical values and the level of modelling granularity used in the analysis. The impact of considering change propagation in the analysis is discussed as well.
5.1 On using a different set of numerical values
In order to examine the impact of using a different set of numerical values for the ‘R’, ‘S’, and ‘I’ entries, the analysis in Sect. 4 was repeated using the settings shown in Fig. 10. The settings were not randomly generated. They represent modelling scenarios where different assumptions were made. For instance, Set 2 in Fig. 10 represents the modelling scenario where components identified to be indirectly affected (‘S’ entries) were perceived to have lesser change influence than those identified as primary change targets (‘R’ entries). The value ‘0.5’ was therefore used in Set 2 to represent the ‘S’ entries instead of the value ‘1’ as used in Set 1. Note that ‘1’, ‘0.5’, and ‘0.1’ are used in the settings shown in Fig. 10 to maximise the difference between each combination within the numerical range of 0–1. The ranking results are as shown in Fig. 11. A correlation study was later conducted to compare the ranking results produced with respect to the original ranking presented in Sect. 4 (i.e. ranking results of Set 1). It was found that the Spearman’s rank correlation coefficients (ρ) for the rankings are at least more than 0.968 with P values of less than 0.01. For instance, as shown in Fig. 11, the rankings produced based on Set 1 and Set 2 have a Spearman’s rank correlation coefficients (ρ) of 0.99 with a P value of less than 0.01. This implies that the rankings are similar and suggest that the method is indeed insensitive to the sets of numerical values used in the analysis.

The sets of numerical values used in the sensitivity analysis

Results of the correlation study
5.2 On using a different level of modelling granularity
As mentioned previously, the truck design was described at two levels of granularity in the dataset provided by the industrial partner. One level describes the truck at a coarser granularity with 17 product components, and the other describes the truck at a finer granularity with 144 sub-components. For instance, the ‘Electrics/Electronics’ component used in the analysis presented in Sect. 4 is also represented by a set of sub-components such as the ‘Control Unit’ and the ‘Driver’s Console’ in the dataset. This allows us to repeat the analysis in Sect. 4 at the sub-component level to examine the effect of using a different level of modelling granularity (see Chiriac et al. (2011) on the impact of using different granularity levels in modularisation analysis). An excerpt of the analysis result is as shown in Fig. 12 (a more complete set of the result with the original dataset is provided in "Appendix 2").

Ranking of sub-components by Engineering Change Forecast (ECF) index
It can be seen from Fig. 12 that out of the top 10 sub-components that were ranked with high modularisation priority, nine are sub-components of the top three components prioritised for modularisation when the analysis was done at the component level (i.e. Component 14, 7, and 13 in Fig. 9). This provides an indication that the ranking produced is insensitive to the level of modelling granularity used. A more detailed correlation study was therefore conducted to further compare the ranking results. The study was carried out by firstly computing the corresponding ECF index for each product component based on the analysis done at the sub-component level (see Fig. 13). For instance, Component 7 has a corresponding ECF index of 1252.7 by adding up the ECF indices of its sub-components (see "Appendix 3" for the computation of corresponding ECF indices using the original dataset). Subsequently, a ranking of product components based on their corresponding ECF indices was produced as shown in Fig. 14. By comparing the ranking results derived directly from the component analysis (Fig. 9) and indirectly from the sub-component analysis (Fig. 14), it was found that the two sets of ranking have a Spearman’s rank correlation coefficient of 0.89 with a P value of less than 0.01. This implies that the two sets of ranking are indeed similar, and hence, the modularisation priority assigned to the product components should be similar as well. The correlation study therefore corroborates that the method can produce consistent results even when a different level of modelling granularity is used.

Computing the corresponding Engineering Change Forecast (ECF) index for each product component

Ranking of truck components based on the corresponding Engineering Change Forecast (ECF) index computed
It should also be pointed out that the results derived from the analysis done at the sub-component level can also be used to better support redesign and modularisation efforts at the product component level. For instance, Component 7 was ranked as the component with the highest ECF index in Fig. 14. However, the ECF index for its sub-components can differ significantly as shown in Fig. 13. Sub-component 51 is ranked second out of all the sub-components in terms of its ECF index, while Sub-component 50 is ranked last. Therefore, it can be argued that a finer modelling granularity can help to pinpoint areas that are more critical and better support the prioritisation of modularisation efforts.
5.3 On the impact of considering change propagation in the analysis
The ECF index of each product component is computed as the sum of its respective roll entries in the ECF matrix (refer to Fig. 8). The diagonal entries in the ECF matrix provide an indication of how each component can be affected through targeted changes (exogenous sources), while the off-diagonal entries provide an indication of how each component can be affected through change propagation (endogenous sources). In order to examine the impact of considering change propagation in the analysis, the ECF index of each truck component is recomputed without considering the off-diagonal entries (referred to as ECF index* in Fig. 15). The components were later ranked with respect to their ECF index* and compared with the original ECF index ranking as shown in Fig. 16.

Engineering Change Forecast (ECF) indices with and without change propagation consideration

Ranking of truck components based on ECF index* (i.e. without considering change propagation)
A correlation study between the two rankings was subsequently carried out. It was found that the two rankings have a Spearman’s rank correlation coefficient of 0.864 with a P value of less than 0.01. This suggests that the ranking result based on ECF index* is similar to the one based on ECF index for this case example. However, it is worth noting that the correlation coefficient computed in this section is lower than the ones computed in the earlier sections (Sects. 5.1, 5.2). This implies that the consideration of change propagation has a larger influence on the ranking results in this case example compared to the use of a different numerical input scale or granularity level.
6 Conclusion
This paper presents a method that uses engineering change forecast to identify and prioritise product components for modularisation. It aims to address an industrial need to incrementally redesign existing product architectures to be more modular. The method developed consists of three main steps which include (1) mapping change requirements to product components using a matrix-based technique, (2) determining the change dependencies between product components based on the change requirements given and establishing an engineering change forecast, and (3) using the engineering change forecast to rank product components based on their exposure to changes and assigning modularisation priorities accordingly.
The method was applied to support modularisation efforts pertaining to the design of a truck at a multinational engineering firm based in Germany. A total of 643 change requirements were considered in this work. The analysis was at first conducted at the component level with 17 truck components. It was found that the method can produce reasonable results and can highlight critical areas that were not previously recognised. Subsequently, the analysis was repeated at a finer modelling granularity with 144 sub-components. It was revealed that out of the top ten sub-components that were ranked with high modularisation priority, nine are sub-components of the top three components prioritised for modularisation when the analysis was done at the component level. A follow-up correlation study also confirms that the ranking results generated at the sub-component level is heavily correlated to the ranking results generated at the component level, producing a Spearman’s rank correlation coefficient of 0.89 with a P value of less than 0.01. Hence, the overall findings suggest that the method can produce consistent results over different levels of modelling granularity.
One important industrial implication of this work is that the presented approach goes beyond the idealised paradigm of modularising the entire product at the same time as often discussed in scenarios concerning product modularity (Ulrich 1995). Based on real-life industrial operation mode, the method presented in this paper was developed and applied in an established brownfield product development environment as described by Kreimeyer et al. (2014) and succeeded in prioritising incremental modularisation efforts for existing product architectures. The output of the method empowered decision makers to ask more advanced questions, leaping from ‘which component should I modularise first?’ to ‘how should I modularise the prioritised component?’ Hence, in summary, it can be concluded that the method described in this work can indeed be used to better prioritise modularisation efforts and is feasible to be used in an industrial setting.
References
Baldwin CY, Clark KB (2000) Design rules: volume 1—the power of modularity. MIT Press, Cambridge
Bauer W, Nepomuk C, Lindemann U, Mauer M (2015) Domain-spanning change propagation in changing technical systems. In: Cardin M-A et al (eds) Complex systems design & management Asia. Springer International, Switzerland, pp 111–123. ISBN 978-3-319-12543-5
Blessing LTM, Chakrabarti A (2009) DRM—a design research methodology. Springer, Berlin
Borjesson F (2012) Approaches to modularity in product architecture. PhD Thesis, Department of Machine Design, Royal Institute of Technology, Sweden
Borjesson F, Hölttä-Otto K (2014) A module generation algorithm for product architecture based on component interactions and strategic drivers. Res Eng Des 25(1):31–51
Browning TR (2001) Applying the Design Structure Matrix to system decomposition and integration problems: a review and new directions. IEEE Trans Eng Manag 48(3):292–306
Cardin M-A, Kolfschoten GL, Frey DD, de Neufville R, de Weck O, Geltner DM (2013) Empirical evaluation of procedures to generate flexibility in engineering systems and improve lifecycle performance. Res Eng Des 24(3):277–295
Chiriac N, Hölttä-Otto K, Lysy D, Suh ES (2011) Level of modularity and different levels of system granularity. J Mech Des 133(10):101007-01–101007-10
Clarkson PJ, Simons C, Eckert CM (2004) Predicting change propagation in complex design. J Mech Des 126(5):765–797
Danilovic M, Browning TR (2007) Managing complex product development projects with design structure matrices and domain mapping matrices. Int J Proj Manag 25(3):300–314
Eckert CM, Clarkson PJ, Zanker W (2004) Change and customisation in complex engineering domains. Res Eng Des 15(1):1–21
Eckert CM, Stacey M, Wyatt D, Garthwaite P (2012) Change as little as possible: creativity in design by modification. J Eng Des 23(4):337–360
Eppinger SD, Browning TR (2012) Design Structure Matrix methods and applications. MIT Press, Cambridge
Fricke E, Schulz AP (2005) Design for changeability (DFC): principles to enable changes in systems throughout their entire lifecycle. Syst Eng 8(4):342–359
Gershenson JK, Prasad GJ, Zhang J (2004) Product modularity: measures and design methods. J Eng Des 15(1):33–51
Hamraz B, Caldwell NHM, Clarkson PJ (2012) A multi-domain engineering change propagation model to support uncertainty reduction and risk management in design. J Mech Des 134(10):100905-1–100905-14
Hölttä-Otto K, Otto K, Simpson TW (2013) Defining modules for platforms: An overview of the architecting process. In: Simpson TW et al (eds) Advances in product family and product platform design—methods & applications. Springer, New York, 323–342. ISBN 1461479363
Hu J, Cardin M-A (2015) Generating flexibility in the design of engineering systems to enable better sustainability and lifecycle performance. Res Eng Des 26(2):121–143
Jarratt TAW, Eckert CM, Caldwell NHM, Clarkson PJ (2011) Engineering change: an overview and perspective on the literature. Res Eng Des 22(2):103–124
Jiao J, Tseng MM (2000) Understanding product family for mass customisation by developing commonality indices. J Eng Des 11(3):225–243
Jiao J, Gershenson JK, Michalek JJ (2007a) Managing modularity and commonality in product and process development. Concur Eng Res Appl 15(2):81–83
Jiao J, Simpson TW, Siddique Z (2007b) Product family design and platform-based product development: a state-of-the-art review. J Intell Manuf 18(1):5–29
Karrer-Müller E, Deubzer F, Kreimeyer M (2013) Lastenheftabbarbeitung in den frühen Phasen der Entwicklung. In: VDI-Berichte Nr. 2186, VDI. Düsseldorf, 285–294. ISBN 978-3-18-092186-0
Koh ECY, Clarkson PJ (2009) A modelling method to manage change propagation. In: Proceedings of the 17th international conference on engineering design (ICED 2009), Palo Alto, CA, USA
Koh ECY, Caldwell NHM, Clarkson PJ (2012) A method to assess the effects of engineering change propagation. Res Eng Des 23(4):329–351
Koh ECY, Caldwell NHM, Clarkson PJ (2013) A technique to assess the changeability of complex engineering systems. J Eng Des 24(7):477–498
Krause D, Beckmann G, Eilmus S, Gebhardt N, Jonas H, Rettberg R (2013) Integrated development of modular product families: a methods toolkit. In: Simpson TW et al (eds) Advances in product family and product platform design—methods & applications. Springer, New York, pp 245–269. ISBN 1461479363
Kreimeyer M (2012) A Product model to support plm-based variant planning and management. In: Proceedings of the 12th international design conference (DESIGN 2012), Dubrovnik, Croatia
Kreimeyer M (2014) Implementing architecture in industry: impact of engineering design research. In: Lindemann U, Chakrabarti A (eds) Impact of design research on industrial practice: tools, technology, and training. Springer, Berlin
Kreimeyer M, Lindemann U (2011) Complexity metrics in engineering design. Springer, Berlin. ISBN 978-3-642-20962-8
Kreimeyer M, Förg A, Lienkamp M (2013) Mehrstufige modulorientierte Baukastenentwicklung für Nutzfahrzeuge. In: VDI-Berichte Nr. 2186. VDI, Düsseldorf, pp 99–112. ISBN 978-3-18-092186-0
Kreimeyer M, Förg A, Lienkamp M (2014) Fostering modular kits in an industrial brownfield environment. In: Horváth I, Rusák Z (eds) Proceedings of TMCE 2014, Budapest, Hungary. ISBN 978-94-6186-177-1
Langer S, Maier A, Wilberg J, Mϋnch TJ, Lindemann U (2012) Exploring differences between average and critical engineering changes: survey results from Denmark. In: Proceedings of the 12th international design conference (DESIGN 2012), Dubrovnik, Croatia
Maier A, Langer S (2011) Engineering change management report 2011: survey results on causes and effects, current practice, problems, and strategies in Denmark, Report. Technical University of Denmark
Martin MV, Ishii K (2002) Design for variety: developing standardized and modularized product platform architectures. Res Eng Des 13(4):213–235
McAdams DA, Stone RB, Wood KL (1999) Functional interdependence and product similarity based on customer needs. Res Eng Des 11(1):1–19
Meyer M, Lehnerd A (1997) The power of product platforms: building value and cost leadership. Free Press, New York
Morkos B, Shankar P, Summers JD (2012) Predicting requirement change propagation, using higher order design structure matrices: an industry case study. J Eng Des 23(12):905–926
Nanda J, Simpson T, Shooter S, Stone R (2005) A unified information model for product family design management. In: ASME international design engineering technical conference (IDETC/CIE’05), Long Beach, CA, USA
Oppenheim BW, Murman EM, Secor DA (2011) Lean enablers for systems engineering. Syst Eng 14(1):29–55
Palani Rajan PK, Van Wie M, Campbell MI, Wood KL, Otto KN (2005) An empirical foundation for product flexibility. Des Stud 26(4):405–438
Ross AM, Rhodes DH, Hastings DE (2008) Defining changeability: reconciling flexibility, adaptability, scalability, modifiability, and robustness for maintaining system lifecycle value. Syst Eng 11(3):246–262
Saleh JH, Mark G, Jordan NC (2009) Flexibility: a multi-disciplinary literature review and a research agenda for designing flexible engineering systems. J Eng Des 20(3):307–323
Sered Y, Reich Y (2006) Standardization and modularization driven by minimizing overall process effort. Comput Aided Des 38(5):405–416
Siddique Z, Rosen DW (2001) On combinatorial design spaces for the configuration design of product families. Artif Intell Eng Des Anal Manuf 15(2):91–108
Simpson TW, D’Souza BS (2004) Assessing variable levels of platform commonality within a product family using a multiobjective genetic algorithm. Concur Eng 12(2):119–129
Simpson TW, Jiao J, Siddique Z, Hölttä-Otto K (eds) (2013) Advances in product family and product platform design—methods & applications. Springer, New York. ISBN 1461479363
Sosa ME, Eppinger SD, Rowles CM (2003) Identifying modular and integrative systems and their impact on design team interactions. J Mech Des 125(2):240–252
Sosa ME, Eppinger SD, Rowles CM (2007) A network approach to define modularity of components in complex products. J Mech Des 129(11):1118–1129
Stone RB, Wood KL, Crawford RH (2000) A heuristic method for identifying modules for product architectures. Des Stud 21(1):5–31
Suh ES, de Weck OL, Chang D (2007) Flexible product platform: framework and case study. Res Eng Des 18(2):67–89
Tchertchian N, Millet D, Pialot O (2013) Modifying module boundaries to design remanufacturable products: the modular grouping explorer tool. J Eng Des 24(8):546–574
Ulrich K (1995) The role of product architecture in the manufacturing firm. Res Policy 24(3):419–441
Ulrich K, Eppinger SD (2012) Product design and development, 5th edn. McGraw-Hill, New York. ISBN 978-007-108695-0
Yu T, Yassine AA, Goldberg DE (2007) An information theoretic method for developing modular architectures using genetic algorithms. Res Eng Des 18(2):91–109
Zuse H (1998) A Framework of Software Measurement. de Gruyter, Berlin., ISBN 3-11-015587-7
Acknowledgments
The authors gratefully acknowledge the staff members at the Industrial Partner for their valuable support, especially Martin Schumacher. This research is supported by the EDIC Seed Fund (R-261-503-003-133), National University of Singapore.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1
See Table 1.
Appendix 2
See Table 2.
Appendix 3
See Table 3.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Koh, E.C.Y., Förg, A., Kreimeyer, M. et al. Using engineering change forecast to prioritise component modularisation. Res Eng Design 26, 337–353 (2015). https://doi.org/10.1007/s00163-015-0200-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00163-015-0200-5