
Abstract
We study the performance of Fictitious Play (FP), when used as a heuristic for finding an approximate Nash equilibrium of a two-player game. We exhibit a class of two-player games having payoffs in the range \([0,1]\) that show that FP fails to find a solution having an additive approximation guarantee significantly better than \(1/2\). Our construction shows that for \(n\times n\) games, in the worst case both players may perpetually have mixed strategies whose payoffs fall short of the best response by an additive quantity \(1/2 - O(1/n^{1-\delta })\) for arbitrarily small \(\delta \). We also show an essentially matching upper bound of \(1/2 - O(1/n)\).

Similar content being viewed by others


Notes
An irrational number is used in order to guarantee that there is never an issue with tie-breaking.
It is notationally convenient to let the \(n\)-th game be of size \(4n\times 4n\); our bounds in terms of \(n\) use the big-O notation, so this is safe.
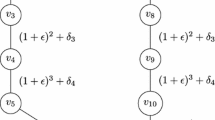
Fig. 1 
The game \(\mathcal{G}_5\) belonging to the class of games used to prove the lower bound

References
Berger U (2005) Fictitious play in \(2 \times n\) games. J Econ Theory 120:139–154
Bosse H, Byrka J, Markakis E (2007) New algorithms for approximate Nash equilibria in bimatrix games. In: Proceedings of the 3rd international workshop on internet and network economics (WINE), pp 17–29
Brandt F, Fischer F. Harrenstein P (2010) On the rate of convergence of fictitious play. In: Proceedings of the 3rd symposium on algorithmic game theory (SAGT), pp 102–113
Chen X, Deng X, Teng S-H (2009) Settling the complexity of computing two-player Nash equilibria. J ACM 56(3):1–57
Conitzer V (2009) Approximation guarantees for fictitious play. In: Proceedings of the 47th annual Allerton conference on communication, control, and computing, pp 636–643
Daskalakis C, Mehta A, Papadimitriou CH (2007) Progress in approximate Nash equilibria. In: Proceedings of the 8th ACM conference on electronic commerce (EC), pp 355–358
Daskalakis C, Mehta A, Papadimitriou CH (2009a) A note on approximate Nash equilibria. Theor Comput Sci 410(17):1581–1588
Daskalakis C, Goldberg PW, Papadimitriou CH (2009b) The complexity of computing a Nash equilibrium. SIAM J Comput 39(1):195–259
Daskalakis C, Frongillo R, Papadimitriou CH, Pierrakos G, Valiant G (2010) On learning algorithms for Nash equilibria. In Proceedings of the 3rd symposium on algorithmic game theory (SAGT), pp 114–125
Dudziak W (2006) Using fictitious play to find pseudo-optimal solutions for full-scale poker. In: Proceedings of the 2006 international conference on artificial intelligence (ICAI), pp 374–380
Fearnley J, Goldberg PW, Savani R, Sørensen TB (2012) Approximate well-supported Nash equilibria below two-thirds. arXiv tech report 1204.0707. In: Proceedings of the 5th symposium on algorithmic game theory (SAGT)
Feder T, Nazerzadeh H, Saberi A (2007) Approximating Nash equilibria using small-support strategies. In Proceedings of the 8th ACM conference on electronic commerce (EC), pp 352–354
Fudenberg D, Kreps DM (1993) Learning mixed equilibria. Games Econ Behav 5:320–367
Fudenberg D, Levine DK (1995) Consistency and cautious fictitious play. J Econ Dyn Control 19(5–7):1065–1089
Fudenberg D, Levine DK (1998) The theory of learning in games. MIT Press, Cambridge, MA
Ganzfried S, Sandholm T (2008) Computing an approximate jam/fold equilibrium for 3-player no-limit Texas Hold’em tournaments. In: Proceedings of the 7th international joint conference on autonomous agents and multi-agent systems (AAMAS), pp 919–925
Hart S, Mas-Colell A (2003) Uncoupled dynamics do not lead to Nash equilibrium. Am Econ Rev 93(5):1830–1836
Hart S, Mas-Colell A (2006) Stochastic uncoupled dynamics and Nash equilibrium. Games Econ Behav 57(2):286–303
Kontogiannis S, Spirakis PG (2010) Well supported approximate equilibria in bimatrix games. Algorithmica 57(4):653–667
Lambert TJ, Epelman MA, Smith RL (2005) A fictitious play approach to large-scale optimization. Oper Res 53(3):477–489
McMahan HB, Gordon GJ (2007) A fast bundle-based anytime algorithm for poker and other convex games. In: Proceedings of the eleventh international conference on artificial intelligence and statistics (AISTATS)
Miyasawa K (1961) On the convergence of the learning process in a 2 \(\times \) 2 nonzero sum two-person game. Research Memo 33. Princeton University, Princeton
Monderer D, Shapley LS (1996) Potential games. Games Econ Behav 14(1):124–143
Robinson J (1951) An iterative method of solving a game. Ann Math 54(2):296–301
Shapley L (1964) Some topics in two-person games. In: Dresher M, Shapley LS, Tucker AW (eds) Advances in game theory, vol 52. Annals of Mathematics Studies. Princeton University Press, Princeton, pp 1–29
Tsaknakis H, Spirakis Paul G (2008) An optimization approach for approximate Nash equilibria. Internet Math 5(4):365–382
Acknowledgments
This work was supported by EPSRC grants EP/G069239/1 and EP/G069034/1 “Efficient Decentralised Approaches in Algorithmic Game Theory.”
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Proof of Claim 1
Proof
We first show the claim for \(i=4n\). At time step \(t^\star \), FP prescribes to play \(4n\). This in particular means that the action \(4n\) achieves a payoff which is at least as much as that of action \(2n+1\) after \(t^\star -1\) time steps. We write down the inequality given by this fact focusing only on the last \(2n\) actions (we will consider actions \(1, 2, \ldots , n\) below) and obtain:
and then since \(\alpha >1\)
Similarly to the proof of Lemma 3 above this can be shown to imply
We now bound from above the ratio \(\frac{\beta }{\alpha -1}\frac{p_{t^\star }(3n)}{p_{t^\star }(4n-1)}\). By repeatedly using Lemmas 3 and 4 we have that
This yields
where the last inequality has been proved above (see 11). Therefore, since \(t \ge n^{1-\delta }\), (19) implies
To conclude this part of the proof we must now consider the contribution to (18) of the actions \(1,\ldots , 2n\) that are not in the last block. However, Lemma 5 shows that all those actions are played with probability \(1/2^{n^{\delta }}\) at time \(t^\star \). Thus the overall contribution of these actions is bounded from above by \(\frac{1}{2^{n^{\delta }}} (\alpha -\beta ) \le \frac{1}{2^{n^{\delta }}}\). Similarly to the above, we observe that, for \(n\) sufficiently large, \(n^\delta \ge \log _2(4n)\ge (1-\delta ) \log _2(4n)\), which implies that \(\frac{1}{2^{n^{\delta }}} \le \frac{1}{4n^{1-\delta }}\). This concludes the proof of the upper bound at time \(t^\star \) for \(i=4n\).
Consider now the case \(i=2n+1\). At time step \(t^\star +1\), \(4n\) is not played by FP, which means that \(4n\) is not a best response after \(t^\star \) time steps. By Lemma 1, the best response is \(2n+1\); then, in particular, the payoff of \(2n+1\) is not smaller than the payoff of \(4n\) at that time. We write down the inequality given by this fact focusing only on the last \(2n\) actions (we will consider the actions in \(\{1, 2, \ldots , 2n\}\) below) and obtain
and then since \(\alpha >1\)
We next show that \(\frac{\beta p_{t^\star }(3n) - p_{t^\star }(2n+1)}{(\alpha -1)p_{t^\star }(4n-1)}\ge \) \(- \frac{1}{4n^{1-\delta }}\) or equivalently that \(\frac{p_{t^\star }(3n)}{p_{t^\star }(2n+1)} \ge \frac{1}{\beta }-\frac{(\alpha -1)p_{t^\star }(4n-1)}{4\beta n^{1-\delta } p_{t^\star }(2n+1)}\). To prove this it is enough to show that \(\frac{p_{t^\star }(3n)}{p_{t^\star }(2n+1)} \ge \frac{1}{\beta }\). We observe that
where the first inequality follows from Lemma 3 and the second inequality follows from the observation (similar to the above) that for \(n\) sufficiently large \(n^{\delta }\ge 2 \log _2(2n)\). Then to summarize, for \(\alpha \) and \(\beta \) as in the hypothesis, (20) implies that
As above we consider actions \(1,\ldots , 2n\) and observe that their contribution to the payoffs is bounded from above by \(\frac{1}{4n^{1-\delta }}\). Now to conclude the proof of the claim for the case \(i=2n+1\) we simply notice that the above implies \(p_{t^\star }(4n-1)<p_{t^\star }(4n)\) and Lemmas 3 and 4 imply that \(p_{t^\star }(2n+1)<p_{t^\star }(4n-1)\) which together prove the claim. \(\square \)
Appendix B: Proof of Claim 2
Proof
To prove the claim we first focus on the last block of the game, i.e., the block in which players have actions in \(\{2n+1,\ldots ,4n\}\). Recall that our notation uses circular arithmetic on the number of actions of the block.
The fact that action \(i+1\) is better than action \(i\) after \(t-1\) time steps implies that
and then since \(\alpha >1\),
We next show that \(\frac{\beta p_{t-1}(i-n) - p_{t-1}(i-2n+1)}{(\alpha -1)p_{t-1}(i-1)}\ge - \frac{1}{4n^{1-\delta }}\) or equivalently
To prove this it is enough to show that \(\frac{p_{t-1}(i-n)}{p_{t-1}(i-2n+1)} \ge \frac{1}{\beta }\). We observe that
where the first inequality follows from inductive hypothesis (we can use the inductive hypothesis as all the actions involved above are different from \(i\) and \(i+1\)) and the second inequality follows from the aforementioned observation that, for sufficiently large \(n\), \(n^{\delta }\ge 2 \log _2(2n)\). Then to summarize, for \(\alpha \) and \(\beta \) as in the hypothesis, (21) implies that
where the first equality follows from \(\ell _{t-1}(i)=\ell _{t}(i)\) and \(\ell _{t-1}(i-1)=\ell _{t}(i-1)\), which are true because \(s_t=i+1\).
Since action \(i+1\) is worse than action \(i\) at time step \(t-1\) we have that
and then since \(\alpha >1\)
Similarly to the proof of Lemma 3 above this can be shown to imply
We now bound from above the ratio \(\frac{\beta }{\alpha -1}\frac{p_{t}(i-n)}{p_{t}(i-1)}\). By repeatedly using the inductive hypothesis (14) we have that
(Note again that we can use the inductive hypothesis as none of the actions above is \(i\) or \(i+1\).) This yields
where the last inequality is proved above (see 11). Therefore, since \(t \ge n^{1-\delta }\), (22) implies that
To conclude the proof we must now consider the contribution to the payoffs of the actions \(1,\ldots , 2n\) that are not in the last block. However, Lemma 5 shows that all those actions are played with probability \(1/2^{n^{\delta }}\) at time \(t^\star \). Since we prove above (see Lemma 1) that these actions are not played anymore after time step \(t^\star \) this implies that \(\sum _{j=1}^{2n} p_{t}(j) \le \sum _{j=1}^{2n} p_{t^\star }(j) \le 2^{-n^{\delta }}\). Thus the overall contribution of these actions is bounded from above by \(\frac{1}{2^{n^{\delta }}} (\alpha -\beta ) \le \frac{1}{2^{n^{\delta }}} \le \frac{1}{4n^{1-\delta }}\) where the last bound follows from the aforementioned fact that, for \(n\) sufficiently large, \(n^\delta \ge (1-\delta )\log _2(4n)\). This concludes the proof of Claim 2. \(\square \)
Appendix C: Proof of Claim 3
Proof
From (21) (and subsequent arguments) we get \(p_t(i)>p_t(i-1)\) and from (14) we get \(p_t(i-1) > p_t(i-2) > \ldots > p_t(i-2n+1)=p_t(i+1)\). Therefore, \(p_t(i)>p_t(i+1)\) thus proving the upper bound. \(\square \)
Rights and permissions
About this article
Cite this article
Goldberg, P.W., Savani, R., Sørensen, T.B. et al. On the approximation performance of fictitious play in finite games. Int J Game Theory 42, 1059–1083 (2013). https://doi.org/10.1007/s00182-012-0362-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00182-012-0362-6