
Abstract
We use a genetic algorithm to simulate the evolution of error-prone finite automata in the repeated Prisoner’s Dilemma game. In particular, the automata are subjected to implementation and perception errors. The computational experiments examine whether and how the distribution of outcomes and genotypes of the coevolved automata change with different levels of errors. We find that the complexity of the automata is decreasing in the probability of errors. Furthermore, the prevailing structures tend to exhibit low reciprocal cooperation and low tolerance to defections as the probability of errors increases. In addition, by varying the error level, the study identifies a threshold. Below the threshold, the prevailing structures are closed-loop (history-dependent) and diverse, which impedes any inferential projections on the superiority of a particular automaton. However, at and above the threshold, the prevailing structures converge to the open-loop (history-independent) automaton Always-Defect (ALLD). Finally, we find that perception errors are more detrimental than implementation errors to the fitness of the automata. These resultsshow that the evolution of cooperative automata is considerably weaker than expected.










Similar content being viewed by others


Notes
Oscar Volij (2002) provides a theoretical framework which confirms that the only evolutionary stable strategy is ALLD when agents’ preferences are lexicographic (first, according to the limit of the means criterion, and second, according to the complexity of the automaton).
Abreu and Rubinstein (1988) defined the complexity of a strategy as the size of the minimal automaton implementing it, while Banks and Sundaram (1990) argued that the traditional number-of-states measure of complexity of an automaton neglects some essential features, such as informational requirements at a state. They proposed, instead, a criterion of complexity that takes into account both the size (number of states) and transitional structure of a machine. Under this proposition, they proved that the resulting Nash equilibria of the machine-game are now trivial: the machines recommend actions in every period that are invariably stage-game Nash equilibria.
We conjecture that similar results hold for other reciprocal strategies, such as Win-Stay, Lose-Shift. Win-Stay, Lose-Shift, also known as Pavlov, repeats the previous action if the resulting payoff has met the aspiration level, and changes otherwise.
To be consistent with the conventional notation in Markov chains, the word “outcome” is replaced with the word “state”.
A Markov transition matrix is a matrix used to describe the transitions of a Markov chain. Each of its entries is a nonnegative real number representing a probability. This is not to be confused with a transition function in the context of finite automata, which maps every two-tuple of state and opponent’s action to a state. (The concept of a finite automaton will be formally defined in Section 4).
The limit value of the payoff for 𝜖 → 0 and δ → 0 cannot be computed, as the transition matrix is no longer irreducible. Therefore, the stationary distribution Π is no longer uniquely defined.
The payoffs for TFT and ALLD for each possible value of x are provided in the Appendix.
We are grateful to an anonymous referee, who laid down the foundations to this analysis, and for pointing out the illusory nature of the process.
The transition function depends only on the present state and the other agent’s action. This formalization fits the natural description of a strategy as agent i’s plan of action in all possible circumstances that are consistent with agent i’s plans. However, the notion of a game-theoretic strategy for agent i requires the specification of an action for every possible history, including those that are inconsistent with agent i’s plan of action. To formulate the game-theoretic strategy, one would have to construct the transition function such that τ i: Q i × A → Q iinstead of τ i: Q i × A − i → Q i.
A more general definition would postulate that the automaton of agent i commits an implementation error with probability 𝜖, when, for any given state q, the automaton’s output function returns the action f i(q) with probability 1 − 𝜖 and draws another action a i ∈ A i ∖ f i(q) randomly and uniformly otherwise. However, since the action space in the PD game consists of only two actions, the former definition suffices.
To test the robustness of the results with respect to the size selection, computational experiments with automata that held 16 states were also conducted. The computations performed confirm that the results are robust.
For a more-detailed discussion of genetic algorithms, see An Introduction to Genetic Algorithms (Mitchell 1998). No previous knowledge of genetic algorithms is required to understand the description of this genetic algorithm.
Given this layout, there are 259possible structures. Yet, the total number of unique structures is much less since some of the automata are isomorphic. For example, every two-state automaton, such as TFT, can be renamed in any of \((P^{8}_{2}) (2^{42})\) ways.
Bergin and Lipman (1996) indicate that mutation rates represent either experimentation or computational errors. In our context, mutation rates represent experimentation. In addition, we assume that the mutation rate is constant across strings, across agents and over time.
A higher mutation rate increases the variation in the population; as a result, in such an environment, the automaton ALLD is hugely favored. The computational simulations performed with higher rates of mutation ( 8% and 12% independent chance of mutation per element, which implies an expectation of 2 and 3 elements-mutation per string, respectively) confirm this claim. On the other hand, the choice of a 4% independent chance of mutation is a conservative one that allows forms of innovation to appear in the structure of the automata while controlling for the variation in the population.
The average payoff of a given generation t is calculated as the sample average of the payoffs of the thirty members of the population and over the thirty simulations conducted for each treatment.
This definition does not mandate that the opponent is part of the current population. Thus, we circumvent the problem that some states may not be reached, given the set of opponents. We clarify further our definition with an example. Suppose that, in some generation, t, the population consists of one-state automata that Always-Cooperate (ALLC) and one automaton that cooperates unless the opponent defects for seven consecutive periods, after which the automaton defects forever. Given our definition, such an automaton has eight accessible states. The ALLCs have one accessible state. We thank an anonymous referee for bringing to our attention the necessity of this clarification.
The “temptation” payoff is the payoff upon unilaterally defecting in the PD game.
Due to its generosity, NAF lost in its pairwise play with every one of its opponents. In contrast to NAF’s pattern, VIGILANT, the strategy that placed dead last in the tournament, beat every one of its partners in bilateral play. VIGILANT was a highly provocable and unforgiving strategy that retaliated sharply if it inferred that its partner was playing anything less than maximal cooperation.
Recall that the “sucker’s” payoff is the payoff upon unilaterally cooperating in the PD game and the “temptation” payoff is the payoff upon unilaterally defecting.
The Negative Binomial Distribution model assumes that purchases follow a Poisson process with a purchase parameter λ, that customers’ lifetimes follow an exponential distribution with a dropout rate parameter μ, and that, across customers, purchase and dropout rates are distributed according to a gamma distribution.
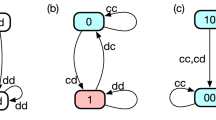
Once the automaton enters an absorbing state, it remains there for the duration of the game-play. Trigger automata have absorbing states as well as open-loop automata.
We thank an anonymous referee for suggesting this vital direction.
References
Abreu D, Rubinstein A (1988) The structure of nash equilibrium in repeated games with finite automata. Econometrica 56:1259–1282
Aumann R (1981) Survey of repeated games. In: Essays in game theory and mathematical economics in honor of Oskar Morgenstern. Mannheim, Bibliographisches Institut
Axelrod R (1984) The evolution of cooperation. Basic Books, New York
Axelrod R (1987) The evolution of strategies in the iterated prisoner’s dilemma. In: Davis L (ed) Genetic algorithms and simulated annealing. London, California, Pitman, Morgan Kaufman, Los Altos, pp 32–41
Axelrod R, Dion D (1988) The further evolution of cooperation. Science 242:1385–1390
Banks JS, Sundaram RK (1990) Repeated games, finite automata, and complexity. Games Econ Behav 2:97–117
Bendor J, Kramer R, Stout S (1991) When in doubt... cooperation in a noisy prisoner’s dilemma. J Confl Resolut 35:691–719
Ben-Shoham A, Serrano R, Volij O (2004) The evolution of exchange. J Econ Theory 114:310–328
Bergin J, Lipman BL (1996) Evolution with state-dependent mutations. Econometrica 64:943–956
Binmore KG, Samuelson L (1992) Evolutionary stability in repeated games played by finite automata. J Econ Theory 57:278–305
Boyd R, Loberbaum J (1987) No pure strategy is evolutionary stable in the repeated prisoner’s dilemma game. Nature 327:58–59
Dal Bó P, Fréchette GR (2011) The evolution of cooperation in infinitely repeated games: experimental evidence. Am Econ Rev 101:411–429
Dawes RM, Thaler RH (1988) Anomalies: cooperation. J Econ Perspect 2:187–197
Foster DP, Young HP (1990) Stochastic evolutionary game dynamics. Theor Popul Biol 38:219–232
Franchini E, Brito CJ, Artioli GG (2012) Weight loss in combat sports: physiological, psychological and performance effects. J Int Soc Sports Nutr 9:52
Fudenberg D, Maskin E (1986) The folk theorem in repeated games with discounting and with incomplete information. Econometrica 54:533–554
Gigerenzer G, Gaissmaier W (2011) Heuristic decision making. Annu Rev Psychol 62:451–482
Glover F, Laguna M (1993) Tabu search. In: CR Reeves (ed) Modern heuristic techniques for combinatorial problems. Blackwell Scientific Publishing, Oxford, p 70
Goldberg D (1989) Genetic algorithms in search optimization, and machine learning. Addison-Wesley Publishing Company, New York
Hamo Y, Markovitch S (2005) The compset algorithm for subset selection. In: Proceedings of the nineteenth international joint conference for artificial intelligence, p 728–733
Heiner R (1983) The origins of predictable behavior. Am Econ Rev 73:560–595
Holland J (1975) Adaptation in natural and artificial systems. MIT Press, Cambridge
Ioannou C, Qi S, Rustichini A (2012) Group outcomes and group behavior. Working Paper, University of Southampton
Kandori M, Mailath G, Rob R (1993) Learning, mutation, and long run equilibria in games. Econometrica 61:29–56
Kirkpatrick S, Gelatt CD, Vecchi MP (1983) Optimization by simulated annealing. Science 220:671–680
Marks RE (1992) Breeding hybrid strategies: optimal behavior for oligopolists. J Evol Econ 2:17–38
Miller J (1996) The coevolution of automata in the repeated prisoner’s dilemma. J Econ Behav Organ 29:87–112
Mitchell M (1998) An introduction to genetic algorithms. MIT Press, Cambridge
Moore E (1956) Gedanken experiments on sequential machines. Ann Math Stud 34:129–153
Nowak MA, Sigmund K (1992) Tit-For-Tat in heterogeneous populations. Nature 355:250–253
Nowak MA, Sigmund K (1993) A strategy of win-stay, lose-shift that outperforms Tit-For-Tat in prisoner’s dilemma. Nature 364:56–58
Neyman A (1985) Bounded complexity justifies cooperation in the finitely repeated prisoner’s dilemma. Econ Lett 19:227–229
Rubinstein A (1986) Finite automata play the repeated prisoner’s dilemma. J Econ Theory 39:83–96
Rust J, Miller JH, Palmer R (1994) Characterizing effective trading strategies. J Econ Dyn Control 18:61–96
Selten R, Mitzkewitz G, Uhlich R (1997) Duopoly strategies programmed by experienced traders. Econometrica 65:517–555
Steen SN, Brownell KD (1990) Patterns of weight loss and regain in wrestlers: has the tradition changed? Med Sci Sports Exerc 22:762–768
Volij O (2002) In defense of defect. Games Econ Behav 39:309–321
Vega-Redondo F (1997) The evolution of walrasian behaviour. Econometrica 65:375–384
Wubben M, von Wangenheim F (2008) Instant customer base analysis: managerial heuristics often get it right. J Mark 72:82–93
Acknowledgments
I am indebted to Aldo Rustichini and Ket Richter for their continuous support and invaluable discussions. I would also like to thank John H. Miller, Scott E. Page, Larry Blume, David Rahman, Itai Sher, Ichiro Obara, Snigdhansu Chatterjee, Ioannis Nompelis, Shi Qi, Miltos Makris, Maria Kyriacou, Kostas Biliouris, and Panayotis Mertikopoulos as well as the seminar participants at the University of Vienna, Santa Fe Institute, University of Minnesota, and Washington University for their suggestions. Finally, I am grateful to the editor, Uwe Cantner, and two anonymous referees for their thoughtful and detailed comments, which significantly improved the paper. Errors are mine.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Ioannou, C.A. Coevolution of finite automata with errors. J Evol Econ 24, 541–571 (2014). https://doi.org/10.1007/s00191-013-0325-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00191-013-0325-5