
Abstract
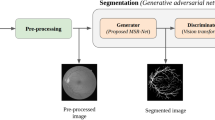
Automatic segmentation of the retinal vasculature and the optic disc is a crucial task for accurate geometric analysis and reliable automated diagnosis. In recent years, Convolutional Neural Networks (CNN) have shown outstanding performance compared to the conventional approaches in the segmentation tasks. In this paper, we experimentally measure the performance gain for Generative Adversarial Networks (GAN) framework when applied to the segmentation tasks. We show that GAN achieves statistically significant improvement in area under the receiver operating characteristic (AU-ROC) and area under the precision and recall curve (AU-PR) on two public datasets (DRIVE, STARE) by segmenting fine vessels. Also, we found a model that surpassed the current state-of-the-art method by 0.2 − 1.0% in AU-ROC and 0.8 − 1.2% in AU-PR and 0.5 − 0.7% in dice coefficient. In contrast, significant improvements were not observed in the optic disc segmentation task on DRIONS-DB, RIM-ONE (r3) and Drishti-GS datasets in AU-ROC and AU-PR.






Similar content being viewed by others


Notes
Our source code is available at https://bitbucket.org/woalsdnd/retinagan
Abbreviations
- Convolutional Neural Networks (CNN):
-
ᅟ
- Generative Adversarial Networks (GAN):
-
ᅟ
References
Sarah BW, Mitchell P, Liew G, Wong TY, Phan K, Thiagalingam A, Joachim N, Burlutsky G, Gopinath B: A spectrum of retinal vasculature measures and coronary artery disease. Atherosclerosis, 2017
Liew G, Benitez-Aguirre P, Craig ME, Jenkins AJ, Hodgson LAB, Kifley A, Mitchell P, Wong TY, Donaghue K: Progressive retinal vasodilation in patients with type 1 diabetes: A longitudinal study of retinal vascular geometryretinal vascular geometry in type 1 diabetes. Invest Ophthalmol Vis Sci 58 (5): 2503–2509, 2017
Taylor AM, MacGillivray TJ, Henderson RD, Ilzina L, Dhillon B, Starr JM, Deary IJ: Retinal vascular fractal dimension, childhood iq, and cognitive ability in old age: the lothian birth cohort study 1936. Plos one 10 (3): e0121119, 2015
McGrory S, Taylor AM, Kirin M, Corley J, Pattie A, Cox SR, Dhillon B, Wardlaw JM, Doubal FN, Starr JM, et al: Retinal microvascular network geometry and cognitive abilities in community-dwelling older people: The lothian birth cohort 1936 study. Br J Ophthalmol, pp bjophthalmol–2016, 2016
McGrory S, Cameron JR, Pellegrini E, Warren C, Doubal FN, Deary IJ, Dhillon B, Wardlaw JM, Trucco E, MacGillivray TJ: The application of retinal fundus camera imaging in dementia: A systematic review. Alzheimer’s & Dementia: Diagnosis, Assessment & Disease Monitoring 6: 91–107, 2017
Sumukadas D, McMurdo M, Pieretti I, Ballerini L, Price R, Wilson P, Doney A, Leese G, Trucco E: Association between retinal vasculature and muscle mass in older people. Arch Gerontol Geriatr 61 (3): 425–428, 2015
Seidelmann SB, Claggett B, Bravo PE, Gupta A, Farhad H, Klein BE, Klein R, Di Carli MF, Solomon SD: Retinal vessel calibers in predicting long-term cardiovascular outcomes: the atherosclerosis risk in communities study. Circulation, pp CIRCULATIONAHA–116, 2016
McGeechan K, Liew G, Macaskill P, Irwig L, Klein R, Sharrett AR, Klein BEK, Wang JJ, Chambless LE, Wong TY: Risk prediction of coronary heart disease based on retinal vascular caliber (from the atherosclerosis risk in communities [aric] study). Am J Cardiol 102 (1): 58–63, 2008
Perez-Rovira A, MacGillivray T, Trucco E, Chin KS, Zutis K, Lupascu C, Tegolo D, Giachetti A, Wilson PJ, Doney A, et al: Vampire: vessel assessment and measurement platform for images of the retina.. In: Engineering in medicine and biology society, EMBC, 2011 annual international conference of the IEEE. IEEE, 2011, pp 3391–3394
Nguyen UTV, Bhuiyan A, Park LAF, Ramamohanarao K: An effective retinal blood vessel segmentation method using multi-scale line detection. Pattern Recog 46 (3): 703–715, 2013
Jiang X, Mojon D: Adaptive local thresholding by verification-based multithreshold probing with application to vessel detection in retinal images. IEEE Transactions on Pattern Analysis and Machine Intelligence 25 (1): 131–137, 2003
Vlachos M, Dermatas E: Multi-scale retinal vessel segmentation using line tracking. Comput Med Imaging Graph 34 (3): 213–227, 2010
Martinez-Perez ME, Hughes AD, Thom SA, Bharath AA, Parker KH: Segmentation of blood vessels from red-free and fluorescein retinal images. Med Image Anal 11 (1): 47–61, 2007
Staal J, Abràmoff MD, Niemeijer M, Viergever MA, Ginneken BV: Ridge-based vessel segmentation in color images of the retina. IEEE Trans Med Imaging 23 (4): 501–509, 2004
Mendonca AM, Campilho A: Segmentation of retinal blood vessels by combining the detection of centerlines and morphological reconstruction. IEEE Trans Med Imaging 25 (9): 1200–1213, 2006
Niemeijer M, Abràmoff MD, Ginneken BV: Fast detection of the optic disc and fovea in color fundus photographs. Med Image Anal 13 (6): 859–870, 2009
Sinthanayothin C, Boyce JF, Cook HL, Williamson TH: Automated localisation of the optic disc, fovea, and retinal blood vessels from digital colour fundus images. Br J Ophthalmol 83 (8): 902–910, 1999
Marín D, Aquino A, Gegúndez-Arias ME, Bravo JM: A new supervised method for blood vessel segmentation in retinal images by using gray-level and moment invariants-based features. IEEE Trans Med Imaging 30 (1): 146–158, 2011
Soares JVB, Leandro JJG, Cesar RM, Jelinek HF, Cree MJ: Retinal vessel segmentation using the 2-d gabor wavelet and supervised classification. IEEE Trans Med Imaging 25(9): 1214–1222, 2006
Fraz MM, Remagnino P, Hoppe A, Uyyanonvara B, Rudnicka AR, Owen CG, Barman SA: An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Trans Biomed Eng 59(9): 2538–2548, 2012
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A: Going deeper with convolutions.. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp 1–9
He K, Zhang X, Ren S, Sun J: Deep residual learning for image recognition.. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp 770–778
Simonyan K, Zisserman A: Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014
Girshick R: Fast r-cnn.. In: Proceedings of the IEEE International Conference on Computer Vision, 2015, pp 1440–1448
Ren S, He K, Girshick R, Sun J: Faster r-cnn: Towards real-time object detection with region proposal networks.. In: Advances in neural information processing systems, 2015, pp 91–99
Noh H, Hong S, Han B: Learning deconvolution network for semantic segmentation.. In: Proceedings of the IEEE International Conference on Computer Vision, 2015, pp 1520–1528
Ronneberger O, Fischer P, Brox T: U-net: Convolutional networks for biomedical image segmentation.. In: International conference on medical image computing and computer-assisted intervention. Springer, 2015, pp 234–241
Long J, Shelhamer E, Darrell T: Fully convolutional networks for semantic segmentation.. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp 3431– 3440
Maninis K-K, Pont-Tuset J, Arbeláez P, Gool LV: Deep retinal image understanding.. In: International conference on medical image computing and computer-assisted intervention. Springer, 2016, pp 140–148
Fu H, Xu Y, Lin S, Wong DWKW, Liu J: Deepvessel: Retinal vessel segmentation via deep learning and conditional random field.. In: International conference on medical image computing and computer-assisted intervention. Springer, 2016, pp 132– 139
Xie S, Tu Z: Holistically-nested edge detection.. In: Proceedings of the IEEE International Conference on Computer Vision, 2015, pp 1395–1403
Melinščak M, Prentašić P, Lončarić S: Retinal vessel segmentation using deep neural networks.. In: VISAPP 2015 (10Th international conference on computer vision theory and applications), 2015
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y: Generative adversarial nets.. In: Advances in neural information processing systems, 2014, pp 2672–2680
Mirza M, Osindero S: Conditional generative adversarial nets. arXiv:1411.1784, 2014
Hoover AD, Kouznetsova V, Goldbaum M: Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans Med Imaging 19 (3): 203–210, 2000
Carmona EJ, Rincón M, García-feijoó J, Martínez-de-la Casa JM: Identification of the optic nerve head with genetic algorithms. Artif Intell Med 43 (3): 243–259, 2008
Fumero F, Alayón S, Sanchez JL, Sigut J, Gonzalez-Hernandez M: Rim-one: An open retinal image database for optic nerve evaluation.. In: 2011 24th international symposium on Computer-based medical systems (CBMS). IEEE, 2011, pp 1–6
Sivaswamy J, Krishnadas S, Joshi G, Jain M, Tabish AUS: Drishti-gs: Retinal image dataset for optic nerve head(onh) segmentation, 04 2014
Radford A, Metz L, Chintala S: Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv:1511.06434, 2015
Ganin Y, Victor L: N∧ 4-fields: Neural network nearest neighbor fields for image transforms.. In: Asian conference on computer vision. Springer, 2014, pp 536–551
Becker C, Rigamonti R, Lepetit V, Fua P: Supervised feature learning for curvilinear structure segmentation.. In: International conference on medical image computing and computer-assisted intervention. Springer, 2013, pp 526–533
Orlando JI, Blaschko M: Learning fully-connected crfs for blood vessel segmentation in retinal images.. In: International conference on medical image computing and computer-assisted intervention. Springer, 2014, pp 634–641
Otsu N: A threshold selection method from gray-level histograms. IEEE Trans Syst Man Cybern 9 (1): 62–66, 1979
Orlando JI, Prokofyeva E, Blaschko MB: A discriminatively trained fully connected conditional random field model for blood vessel segmentation in fundus images. IEEE Trans Biomed Eng 64 (1): 16–27, 2017. https://doi.org/10.1109/TBME.2016.2535311
Sakata K, Funatsu H, Harino S, Noma H, Hori S: Relationship of macular microcirculation and retinal thickness with visual acuity in diabetic macular edema. Ophthalmology 114 (11): 2061–2069, 2007
Prentašić P, Heisler M, Mammo Z, Lee S, Merkur A, Navajas E, Beg MF, Šarunić M, Lončarić S: Segmentation of the foveal microvasculature using deep learning networks. J Biomed Op 21 (7): 075008–075008, 2016
Zhang Z, Liu J, Cherian NS, Sun Y, Lim JH, Wong WK, Tan NM, Lu S, Li H, Wong TY: Convex hull based neuro-retinal optic cup ellipse optimization in glaucoma diagnosis.. In: Annual international conference of the IEEE Engineering in medicine and biology society, 2009. EMBC 2009. IEEE, 2009, pp 1441– 1444
Nair V, Hinton GE: Rectified linear units improve restricted boltzmann machines.. In: Proceedings of the 27th international conference on machine learning (ICML-10), 2010, pp 807– 814
Ioffe S, Szegedy C: Batch Accelerating deep network training by reducing internal covariate shift.. In: 32nd international conference on international conference on machine learning, volume 37 of ICML’15, 2015, pp 448–456. JMLR.org
Isola P, Zhu J-Y, Zhou T, Efros AA: Image-to-image translation with conditional adversarial networks.. In: The IEEE conference on computer vision and pattern recognition (CVPR), 2017
Kingma D, Ba J: Adam: A method for stochastic optimization.. In: Proceedings of the International Conference on Learning Representations (ICLR), 2015
Funding
This study was supported by the Research Grant for Intelligence Information Service Expansion Project, which is funded by National IT Industry Promotion Agency (NIPA-C0202-17-1045) and the Small Grant for Exploratory Research of the National Research Foundation of Korea (NRF), which is funded by the Ministry of Science, ICT, and Future Planning (NRF- 2015R1D1A1A02062194). The sponsors or funding organizations had no role in the design or conduct of this research.
Author information
Authors and Affiliations
Corresponding author
Additional information
The first two authors are co-first authors.
Appendices
Appendix A: Network of a Generator
For the generator, we follow the main structure of U-Net [27] where initial convolutional feature maps are depth-concatenated to layers that are upsampled from the bottleneck layer. U-Net is a fully convolutional network [28] which consists only of convolutional layers and depth concatenation is known to be crucial to segmentation tasks as the initial feature maps maintain low-level features such as edges and blobs that can be properly exploited for accurate segmentation. We modified U-Net to maintain width and height of feature maps during convolution operations by padding zeros at the edges of each feature map (zero-padding). Though concerns could be cast on the boundary effect with zero-padding, we observed that our U-Net style network does not suffer from false positives at the boundary. Also, the number of feature maps for each layer is shrunk to avoid overfitting and accelerate training and inference. Details of the generator network are shown in Table 5. We used ReLU for the activation function [48] and batch-normalization [49] before the activation.
Appendix B: Network of Discriminators
There is variability in the choice of discriminators by the size of pixels on which the decision is made. We explored several models for the discriminators with different output size as done in the previous work [50]. In the atomic level, a discriminator can determine the authenticity pixel-wise (Pixel GAN) while the judgment can also be made in the image level (Image GAN). Between the extremes, it is also possible to set the receptive field to a K × K patch where the decision can be given in the patch level (Patch GAN). We investigated Pixel GAN, Image GAN, and Patch GAN with two intermediary patch sizes (8 × 8, 64 × 64). Details of the network configuration for discriminators are given in Table 6.
Appendix C: Objective Function
Let the generator G be a mapping from a fundoscopic image x to a probability map y, or G : x↦y. Then, the discriminator D maps a pair of {x, y} to binary classification {0, 1}N where 0 represents machine-generated y and 1 denotes human-annotated y and N is the number of decisions. Note that N = 1 for Image GAN and N = W × H for Pixel GAN with image size of W × H.
Then, the objective function of GAN for the segmentation problem can be formulated as
Note that G takes the input of an image, thus, analogous to conditional GAN [34], but there is no randomness involved in G. Then, the GAN framework solves the optimization problem of
For training the discriminator D to make correct judgment, D(x, y) needs to be maximized while D(x, G(x)) should be minimized. On the other hand, the generator should prevent the discriminator from making the correct judgment by producing outputs that are indiscernible to real data. Since the ultimate goal is to obtain realistic outputs from the generator, the objective function is defined as the minimax of the objective.
In fact, the segmentation task can also utilizes gold standard images by adding a loss function that penalizes distance from the gold standard such as binary cross entropy
By summing up both the GAN objective and the segmentation loss, we can formulate the objective function as
where λ balances the two objective functions.
Appendix D: Experimental Details
D.1 Image Preprocessing
In the public datasets that are used in our experiments, the number of data is not sufficient for successful training. To overcome the limitation, we augmented the data to retrieve new images that are similar but slightly different to the originals. First, each image is rotated with interval of 3 degrees and flipped horizontally yielding additional 239 augmented images from one original image. We empirically found that 3 degree was sufficient for the rotational augmentation. Finally, photographic information is perturbed by the following formula,
where Ixyd is a pixel value in channel d ∈{r, g, b} at coordinate (x, y) in an image I and α is a coefficient that balances a color-deprived image (gray image) and the original image. In our experiment, α is randomly sampled from [0.8, 1.2]. When α is above 1, color in each channel intensifies while subtracting intensity in gray scale. From multiple experiments, we found that these augmentation methods can result in a reliable segmentation for both vessels and the optic discs.
When feeding fundoscopic input images to the network, we computed z-score by subtracting the mean and dividing by standard deviation per channel for each individual image. Formally, the following equation is applied to each pixel,
where Ixyd denotes a pixel value in channel d ∈{r, g, b} at (x, y) in an image \(I\in \mathbb {R}^{W\times H}\). Since the mean and standard deviation in every image are set to 0 and 1 respectively, the sheer difference in brightness and contrast between the two images is eliminated. Therefore, any meaningful features will not be extracted based upon brightness or contrast during training.
D.2 Validation and Training
After the augmentation of original images, 5% of images are reserved for validation set and the remaining 95% of images are used for training. The models with the least generator loss on the validation set are chosen for comparison. We ran 10 rounds of training in which the discriminator and the generator are trained for 240 epochs alternatively. Total of 2400 epochs during training was enough to observe convergence in the generator loss. We emphasize that training both networks alternatively with sufficient iterations can lead to stable learning in which the discriminator perfectly classifies at first and the generator completely fakes the discriminator by letting the discriminator become gradually weaker.
D.3 Hyper-parameters
As an optimizer during training, we used Adam [51] with fixed learning rate of 2e− 4 and first moment coefficient (β1) of 0.5, and second moment coefficient (β2) of 0.999. We fixed the trade-off coefficient in Eq. 5 to 10 (λ = 10).
Rights and permissions
About this article

Cite this article
Son, J., Park, S.J. & Jung, KH. Towards Accurate Segmentation of Retinal Vessels and the Optic Disc in Fundoscopic Images with Generative Adversarial Networks. J Digit Imaging 32, 499–512 (2019). https://doi.org/10.1007/s10278-018-0126-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10278-018-0126-3