
Abstract
The performance of economic producers is often affected by external or environmental factors that, unlike the inputs and the outputs, are not under the control of the Decision Making Units (DMUs). These factors can be included in the model as exogenous variables and can help to explain the efficiency differentials, as well as improve the managerial policy of the evaluated units. A fully nonparametric methodology, which includes external variables in the frontier model and defines conditional DEA and FDH efficiency scores, is now available for investigating the impact of external-environmental factors on the performance.
In this paper, we offer a state-of-the-art review of the literature, which has been proposed to include environmental variables in nonparametric and robust (to outliers) frontier models and to analyse and interpret the conditional efficiency scores, capturing their impact on the attainable set and/or on the distribution of the inefficiency scores. This paper develops and complements the approach of Bădin et al. (2012) by suggesting a procedure that allows us to make local inference and provide confidence intervals for the impact of the external factors on the process. We advocate for the nonparametric conditional methodology, which avoids the restrictive “separability” assumption required by the two-stage approaches in order to provide meaningful results. An illustration with real data on mutual funds shows the usefulness of the proposed approach.








Similar content being viewed by others

Notes
See Simar and Wilson (2008) for a recent survey on statistical issues with nonparametric estimators of frontiers.
See Daraio and Simar (2007a) for more details and examples of empirical applications.
The conditional efficiency estimators are based on a nonstandard conditional survival function, therefore smoothing procedures and the estimation of a bandwidth parameter are required. Bădin et al. (2010) proposed an adaptive data-driven method for selecting the optimal bandwidth, by extending to the frontier framework some theoretical results obtained by Hall et al. (2004) and Li and Racine (2007, 2008). An extension of this approach for selecting the optimal bandwidth, to the case where the external variables also have discrete components, is presented in Bădin and Daraio (2011).
See Daraio and Simar (2007a, p. 47 and ff.) for a detailed description, in a non-formalised way, of the main asymptotic properties of nonparametric and robust efficiency estimators.
For more details on how to handle discrete variables in this framework, see Bădin and Daraio (2011).
It should be noticed that we are not interested in the individual random variables R(X i ,Y i |Z i ), but rather in the expectation τ z(P), given that Z=z, and to analyse this as a function of z. An individual confidence interval for a particular fixed point of interest for R(x 0,y 0|z 0) could be obtained by standard bootstrap techniques as described in Kneip et al. (2008, 2011) or in Simar and Wilson (2011a).
The number of subsets N m can be a huge number: \(N_{m} = \binom{n}{m}\). In practice, of course, we do not compute all these subsets, but we would just take a random selection of B such subsamples, where B should not be too small.
We follow the approach described in Daraio et al. (2010) and refer the reader to their paper for the full details. With our data we obtained an optimal subsample size of 82, an observed Test statistics (based on FDH and conditional FDH efficiency measures) of 133856.53, whilst the 95 % quantile for the Test statistics is 114208.12, hence we rejected the null hypothesis of separability condition with a p-value=0.0005.
For more details on the complementarity between full frontier ratios and partial frontier ratios, see the Appendix B of Bădin et al. (2012).
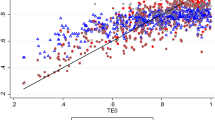
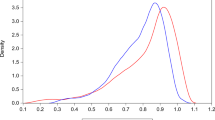
We first remark that a few large funds are isolated at the right of each picture (there are 9 observations with a value of Z 2>1000), whereas most of the data are concentrated with much smaller values. These huge funds certainly influence the general shape of the picture.
We point out here also the caveat done above, about the lack of more data points with high values of the Size Z 2.
Here we could recompute the bandwidth \(h_{m}^{z}\) by crossvalidation, but at a computational cost. By doing what is suggested in [3.3], the desired theoretical order of the bandwidth is achieved.
The choice of this grid is really open and depends on the computational burden: we should cover a wide spectrum of values for m. Simar and Wilson (2011a) and Daraio et al. (2010) suggest, for instance, to choose the 49 subsamples sizes m∈{[n/50],2[n/50],…,49[n/50]}, where [a] denotes the integer parts of a.
References
Avkiran, N. K. (2009). Removing the impact of environment with units-invariant efficient frontier analysis: an illustrative case study with intertemporal panel data. Omega, International Journal of Management Science, 37(3), 535–544.
Avkiran, N. K., & Rowlands, T. (2008). How to better identify the true managerial performance: state of the art using DEA. Omega, International Journal of Management Science, 36(2), 317–324.
Banker, R. D., & Morey, R. C. (1986). Efficiency analysis for exogenously fixed inputs and outputs. Operations Research, 34(4), 513–521.
Banker, R. D., & Natarajan, R. (2008). Evaluating contextual variables affecting productivity using data envelopment analysis. Operations Research, 56(1), 48–58.
Bădin, L., & Daraio, C. (2011). Explaining efficiency in nonparametric frontier models: recent developments in statistical inference. In I. Van Keilegom & P. W. Wilson (Eds.), Exploring research frontiers in contemporary statistics and econometrics. Berlin: Springer.
Bădin, L., Daraio, C., & Simar, L. (2010). Optimal bandwidth selection for conditional efficiency measures: a data-driven approach. European Journal of Operational Research, 201(2), 633–640.
Bădin, L., Daraio, C., & Simar, L. (2012, forthcomming). How to measure the impact of environmental factors in a nonparametric production model? European Journal of Operational Research.
Cazals, C., Florens, J. P., & Simar, L. (2002). Nonparametric frontier estimation: a robust approach. Journal of Econometrics, 106, 1–25.
Charnes, A., Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision making units. European Journal of Operational Research, 2, 429–444.
Cooper, W. W., Seiford, L. M., & Tone, K. (2000). Data envelopment analysis: a comprehensive text with models, applications, references and DEA-solver software. Boston: Kluwer Academic.
Daouia, A., & Simar, L. (2007). Nonparametric efficiency analysis: a multivariate conditional quantile approach. Journal of Econometrics, 140, 375–400.
Daraio, C., & Simar, L. (2005). Introducing environmental variables in nonparametric frontier models: a probabilistic approach. Journal of Productivity Analysis, 24, 93–121.
Daraio, C., & Simar, L. (2006). A robust nonparametric approach to evaluate and explain the performance of mutual funds. European Journal of Operational Research, 175(1), 516–542.
Daraio, C., & Simar, L. (2007a). Advanced robust and nonparametric methods in efficiency analysis. Methodology and applications. New York: Springer.
Daraio, C., & Simar, L. (2007b). Conditional nonparametric frontier models for convex and non convex technologies: a unifying approach. Journal of Productivity Analysis, 28, 13–32.
Daraio, C., Simar, L., & Wilson, P. (2010). Testing whether two-stage estimation is meaningful in nonparametric models of production (Discussion Paper #1030). Institut de Statistique, Université Catholique de Louvain, Louvain-la-Neuve, Belgium.
Debreu, G. (1951). The coefficient of resource utilization. Econometrica, 19(3), 273–292.
Deprins, D., Simar, L., & Tulkens, H. (1984). Measuring labor-efficiency in post offices. In M. Marchand, P. Pestieau & H. Tulkens (Eds.), The performance of public enterprises—concepts and measurement (pp. 243–267). Amsterdam: North-Holland.
Fan, J., & Gijbels, I. (1996). Local polynomial modelling and its applications. London: Chapman & Hall.
Farrell, M. J. (1957). The measurement of the productive efficiency. Journal of the Royal Statistical Society. Series A, CXX(3), 253–290.
Fukuyama, H., & Weber, W. L. (2010). A slacks-based inefficiency measure for a two-stage system with bad outputs. Omega, International Journal of Management Science, 38(5), 398–409.
Färe, R., Grosskopf, S., & Lovell, C. A. K. (1994). Production frontiers. Cambridge: Cambridge University Press.
Gattoufi, S., Oral, M., & Reisman, A. (2004). Data envelopment analysis literature: a bibliography update (1951–2001). Socio-Economic Planning Sciences, 38, 159–229.
Hall, P., Racine, J. S., & Li, Q. (2004). Cross-validation and the estimation of conditional probability densities. Journal of the American Statistical Association, 99(486), 1015–1026.
Härdle, W., & Bowman, A. W. (1988). Bootstrapping in nonparametric regression: local adaptive smoothing and confidence bands. Journal of the American Statistical Association, 83(401), 102–110.
Härdle, W., & Marron, J. S. (1991). Bootstrap simultaneous error bars for nonparametric regression. Annals of Statistics, 19(2), 778–796.
Jeong, S. O., Park, B. U., & Simar, L. (2010). Nonparametric conditional efficiency measures: asymptotic properties. Annals of Operations Research, 173, 105–122.
Kneip, A., Simar, L., & Wilson, P. W. (2008). Asymptotics and consistent bootstraps for DEA estimators in non-parametric frontier models. Econometric Theory, 24, 1663–1697.
Kneip, A., Simar, L., & Wilson, P. W. (2011). A computational efficient, consistent bootstrap for inference with non-parametric DEA estimators. Computational Economics, 38, 483–515.
Li, Q., & Racine, J. (2007). Nonparametric econometrics: theory and practice. Princeton: Princeton University Press.
Li, Q., & Racine, J. (2008). Nonparametric estimation of conditional CDF and quantile functions with mixed categorical and continuous data. Journal of Business & Economic Statistics, 26(4), 423–434.
Murthi, B., Choi, Y., & Desai, P. (1997). Efficiency of mutual funds and portfolio performance measurement: a nonparametric measurement. European Journal of Operational Research, 98, 408–418.
Pagan, A., & Ullah, A. (1999). Nonparametric econometrics. Cambridge: Cambridge University Press.
Paradi, J. C., Rouatt, S., & Zhu, H. (2011). Two-stage evaluation of bank branch efficiency using data envelopment analysis. Omega, International Journal of Management Science, 39(1), 99–109.
Park, B., Simar, L., & Weiner, C. (2000). The FDH estimator for productivity efficiency scores: asymptotic properties. Econometric Theory, 16, 855–877.
Politis, D. N., Romano, J. P., & Wolf, M. (2001). On the asymptotic theory of subsampling. Statistica Sinica, 11, 1105–1124.
Park, B., Simar, L., & Zelenyuk, V. (2008). Local likelihood estimation of truncated regression and its partial derivatives: theory and application. Journal of Econometrics, 146(1), 185–198.
Shephard, R. W. (1970). Theory of cost and production function. Princeton: Princeton University Press.
Simar, L., & Vanhems, A. (2012). Probabilistic characterization of directional distances and their robust versions. Journal of Econometrics, 166, 342–354.
Simar, L., & Wilson, P. W. (2007). Estimation and inference in two-stage, semi-parametric models of production processes. Journal of Econometrics, 136(1), 31–64.
Simar, L., & Wilson, P. W. (2008). Statistical inference in nonparametric frontier models: recent developments and perspectives. In H. Fried, C.A. Knox Lovell & S. Schmidt (Eds.), The measurement of productive efficiency (2nd ed.). London: Oxford University Press.
Simar, L., & Wilson, P. W. (2011a). Inference by the m out of n bootstrap in nonparametric frontier models. Journal of Productivity Analysis, 36, 33–53.
Simar, L., & Wilson, P. W. (2011b). Two-stage DEA: caveat emptor. Journal of Productivity Analysis, 36, 205–218.
Author information
Authors and Affiliations
Corresponding author
Additional information
Financial support from the Romanian National Authority for Scientific Research, CNCS—UEFISCDI, project PN-II-ID-PCE-2011-3-0893, from the “Inter-university Attraction Pole”, Phase VI (No. P6/03) of the Belgian Government (Belgian Science Policy) and from the INRA-GREMAQ, Toulouse, France are gratefully acknowledged. This paper was completed during an academic visit of L. Simar at the DIAG, University of Rome “La Sapienza”, in 2012.
Appendix: The bootstrap algorithm
Appendix: The bootstrap algorithm
The bootstrap algorithm can be described by the following steps:
-
[1]
Based on the sample \({\mathcal{S}}_{n} =\{(X_{i},Y_{i},Z_{i})|\; i=1,\ldots ,n\}\) compute the n efficiency scores \(\widehat{\lambda}(X_{i}, Y_{i})\) and the conditional efficiency scores \(\widehat{\lambda}(X_{i}, Y_{i}|Z_{i})\). For the conditional efficiency scores, compute the optimal bandwidth h n,i , attached to the ith observation, via the LSCV procedure proposed in Bădin et al. (2010). Compute the n ratios \(\widehat{R}(X_{i}, Y_{i}|Z_{i})\).
-
[2]
Select a fixed grid of values for Z, say {z 1,…,z k } to evaluate the regression. We compute the nonparametric regression by one of the methods described in (4.21): this provides \(\hat{\tau}^{z_{j}}_{n}\) for j=1,…,k. The bandwidth \(h_{n}^{z}\) is selected by least-squares crossvalidation.
-
[3]
For a given value of m<n and a large B (e.g. B=2000), repeat steps [3.1] to [3.3] for b=1,…,B.
-
[3.1]
Draw a random sample \({\mathcal{S}}^{*}_{m,b}=\{ (X^{*,b}_{i},Y^{*,b}_{i},Z^{*,b}_{i})|\;i=1,\ldots,m\}\) without replacement from \({\mathcal{S}}_{n}\). By doing so, we keep also the value of the bandwidth \(h^{*,b}_{n,i}\) computed at step [1] attached to the corresponding selected data \((X^{*,b}_{i},Y^{*,b}_{i},Z^{*,b}_{i})\).
-
[3.2]
Compute the m ratios \(\widehat{R}^{*,b}(X^{*,b}_{i}, Y^{*,b}_{i}|Z^{*,b}_{i})\), i=1,…,m by the same techniques as in [1]. Note that here we have to rescale the corresponding bandwidths \(h^{*,b}_{n,i}\) at the appropriate size, so we use the bandwidths \(h^{*,b}_{m,i} = (n/m)^{1/(r+4)} h^{*,b}_{n,i}\) for computing the conditional scores in the bootstrap sample \({\mathcal{S}}^{*}_{m,b}\).
-
[3.3]
By the same nonparametric method as in [2], estimate the regressions \(\hat{\tau}^{*,b,z_{j}}_{m}\) at the fixed points z j , for j=1,…,k. One can use here the same bandwidth computed in [2], but rescaled to the appropriate size.Footnote 13 So we use here \(h_{m}^{z}=(n/m)^{1/(r+4)} h_{n}^{z}\) and obtain \(\hat{\tau}^{*,b,z_{j}}_{m}\) for j=1,…,k.
-
[3.1]
-
[4]
For each j=1,…,k, compute \((q^{*,z_{j}}_{m;\alpha /2},q^{*,z_{j}}_{m;1-\alpha/2})\), the α/2 and 1−α/2 quantiles of the B bootstrapped values of \(\hat{\tau}^{*,b,z_{j}}_{m} -\hat{\tau}^{z_{j}}_{n} \). This provides the k confidence intervals of \(\tau^{z_{j}}(P)\) at each fixed z j :
 (A.1)
(A.1)

The selection of m is done as follows. We redo the steps [3] to [4] over a grid of L values of m, say, m 1<m 2<⋯<m L and we obtain for each m ℓ , the k resulting confidence intervals (A.1).Footnote 14 Then we compute the volatility of the quantity of interest seen as a function of m. Here the two bounds of the confidence intervals (A.1) are of the quantities of interest, Politis et al. (2001) suggest in this case to take \(c^{z_{j}}(m) = (1/2)[\mathrm{low}_{m}^{z_{j}} + \mathrm{up}_{m}^{z_{j}}]\), where the notation is implicit. The volatility is measured by the “moving” standard deviation of 3 adjacent values of \(c^{z_{j}}(m)\) centred at the current value of m ℓ , ℓ=2,…,L−1. As explained in Politis et al. (2001), a reasonable value for \(m^{z_{j}}\) should correspond to the value that minimises this volatility. Intensive Monte Carlo experiments in Simar and Wilson (2011a) and Daraio et al. (2010), in similar setups of nonparametric frontier estimation, indicate that this procedure provides very good results in terms of coverage, size of tests, power of tests, etc.
A simpler alternative is to select a common value of m for the different values of z j . Is possible, for instance, to select the m equal to the average of all the m z. One could also use the same approach as above, but then, the volatility would be measured on an average value \(c(m)= (1/k) \sum_{j} c^{z_{j}}(m)\). This approach could provide a more stable behaviour of c(m) as a function of m.
Rights and permissions
About this article
Cite this article
Bădin, L., Daraio, C. & Simar, L. Explaining inefficiency in nonparametric production models: the state of the art. Ann Oper Res 214, 5–30 (2014). https://doi.org/10.1007/s10479-012-1173-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-012-1173-7