
Abstract
Peer assessment has been the subject of considerable research interest over the last three decades, with numerous educational researchers advocating for the integration of peer assessment into schools and instructional practice. Research synthesis in this area has, however, largely relied on narrative reviews to evaluate the efficacy of peer assessment. Here, we present a meta-analysis (54 studies, k = 141) of experimental and quasi-experimental studies that evaluated the effect of peer assessment on academic performance in primary, secondary, or tertiary students across subjects and domains. An overall small to medium effect of peer assessment on academic performance was found (g = 0.31, p < .001). The results suggest that peer assessment improves academic performance compared with no assessment (g = 0.31, p = .004) and teacher assessment (g = 0.28, p = .007), but was not significantly different in its effect from self-assessment (g = 0.23, p = .209). Additionally, meta-regressions examined the moderating effects of several feedback and educational characteristics (e.g., online vs offline, frequency, education level). Results suggested that the effectiveness of peer assessment was remarkably robust across a wide range of contexts. These findings provide support for peer assessment as a formative practice and suggest several implications for the implementation of peer assessment into the classroom.
Similar content being viewed by others


Feedback is often regarded as a central component of educational practice and crucial to students’ learning and development (Fyfe & Rittle-Johnson, 2016; Hattie and Timperley 2007; Hays, Kornell, & Bjork, 2010; Paulus, 1999). Peer assessment has been identified as one method for delivering feedback efficiently and effectively to learners (Topping 1998; van Zundert et al. 2010). The use of students to generate feedback about the performance of their peers is referred to in the literature using various terms, including peer assessment, peer feedback, peer evaluation, and peer grading. In this article, we adopt the term peer assessment, as it more generally refers to the method of peers assessing or being assessed by each other, whereas the term feedback is used when we refer to the actual content or quality of the information exchanged between peers. This feedback can be delivered in a variety of forms including written comments, grading, or verbal feedback (Topping 1998). Importantly, by performing both the role of assessor and being assessed themselves, students’ learning can potentially benefit more than if they are just assessed (Reinholz 2016).
Peer assessments tend to be highly correlated with teacher assessments of the same students (Falchikov and Goldfinch 2000; Li et al. 2016; Sanchez et al. 2017). However, in addition to establishing comparability between teacher and peer assessment scores, it is important to determine whether peer assessment also has a positive effect on future academic performance. Several narrative reviews have argued for the positive formative effects of peer assessment (e.g., Black and Wiliam 1998a; Topping 1998; van Zundert et al. 2010) and have additionally identified a number of potentially important moderators for the effect of peer assessment. This meta-analysis will build upon these reviews and provide quantitative evaluations for some of the instructional features identified in these narrative reviews by utilising them as moderators within our analysis.
Evaluating the Evidence for Peer Assessment
Empirical Studies
Despite the optimism surrounding peer assessment as a formative practice, there are relatively few control group studies that evaluate the effect of peer assessment on academic performance (Flórez and Sammons 2013; Strijbos and Sluijsmans 2010). Most studies on peer assessment have tended to focus on either students’ or teachers’ subjective perceptions of the practice rather than its effect on academic performance (e.g., Brown et al. 2009; Young and Jackman 2014). Moreover, interventions involving peer assessment often confound the effect of peer assessment with other assessment practices that are theoretically related under the umbrella of formative assessment (Black and Wiliam 2009). For instance, Wiliam et al. (2004) reported a mean effect size of .32 in favor of a formative assessment intervention but they were unable to determine the unique contribution of peer assessment to students’ achievement, as it was one of more than 15 assessment practices included in the intervention.
However, as shown in Fig. 1, there has been a sharp increase in the number of studies related to peer assessment, with over 75% of relevant studies published in the last decade. Although it is still far from being the dominant outcome measure in research on formative practices, many of these recent studies have examined the effect of peer assessment on objective measures of academic performance (e.g., Gielen et al. 2010a; Liu et al. 2016; Wang et al. 2014a). The number of studies of peer assessment using control group designs also appears to be increasing in frequency (e.g., van Ginkel et al. 2017; Wang et al. 2017). These studies have typically compared the formative effect of peer assessment with either teacher assessment (e.g., Chaney and Ingraham 2009; Sippel and Jackson 2015; van Ginkel et al. 2017) or no assessment conditions (e.g., Kamp et al. 2014; L. Li and Steckelberg 2004; Schonrock-Adema et al. 2007). Given the increase in peer assessment research, and in particular experimental research, it seems pertinent to synthesise this new body of research, as it provides a basis for critically evaluating the overall effectiveness of peer assessment and its moderators.

Number of records returned by year. The following search terms were used: ‘peer assessment’ or ‘peer grading or ‘peer evaluation’ or ‘peer feedback’. Data were collated by searching Web of Science (www.webofknowledge.com) for the following keywords: ‘peer assessment’ or ‘peer grading’ or ‘peer evaluation’ or ‘peer feedback’ and categorising by year
Previous Reviews
Efforts to synthesise peer assessment research have largely been limited to narrative reviews, which have made very strong claims regarding the efficacy of peer assessment. For example, in a review of peer assessment with tertiary students, Topping (1998) argued that the effects of peer assessment are, ‘as good as or better than the effects of teacher assessment’ (p. 249). Similarly, in a review on peer and self-assessment with tertiary students, Dochy et al. (1999) concluded that peer assessment can have a positive effect on learning but may be hampered by social factors such as friendships, collusion, and perceived fairness. Reviews into peer assessment have also tended to focus on determining the accuracy of peer assessments, which is typically established by the correlation between peer and teacher assessments for the same performances. High correlations have been observed between peer and teacher assessments in three meta-analyses to date (r = .69, .63, and .68 respectively; Falchikov and Goldfinch 2000; H. Li et al. 2016; Sanchez et al. 2017). Given that peer assessment is often advocated as a formative practice (e.g., Black and Wiliam 1998a; Topping 1998), it is important to expand on these correlational meta-analyses to examine the formative effect that peer assessment has on academic performance.
In addition to examining the correlation between peer and teacher grading, Sanchez et al. (2017) additionally performed a meta-analysis on the formative effect of peer grading (i.e., a numerical or letter grade was provided to a student by their peer) in intervention studies. They found that there was a significant positive effect of peer grading on academic performance for primary and secondary (grades 3 to 12) students (g = .29). However, it is unclear whether their findings would generalise to other forms of peer feedback (e.g., written or verbal feedback) and to tertiary students, both of which we will evaluate in the current meta-analysis.
Moderators of the Effectiveness of Peer Assessment
Theoretical frameworks of peer assessment propose that it is beneficial in at least two respects. Firstly, peer assessment allows students to critically engage with the assessed material, to compare and contrast performance with their peers, and to identify gaps or errors in their own knowledge (Topping 1998). In addition, peer assessment may improve the communication of feedback, as peers may use similar and more accessible language, as well as reduce negative feelings of being evaluated by an authority figure (Liu et al. 2016). However, the efficacy of peer assessment, like traditional feedback, is likely to be contingent on a range of factors including characteristics of the learning environment, the student, and the assessment itself (Kluger and DeNisi 1996; Ossenberg et al. 2018). Some of the characteristics that have been proposed to moderate the efficacy of feedback include anonymity (e.g., Rotsaert et al. 2018; Yu and Liu 2009), scaffolding (e.g., Panadero and Jonsson 2013), quality and timing of the feedback (Diab 2011), and elaboration (e.g., Gielen et al. 2010b). Drawing on the previously mentioned narrative reviews and empirical evidence, we now briefly outline the evidence for each of the included theoretical moderators.
Role
It is somewhat surprising that most studies that examine the effect of peer assessment tend to only assess the impact on the assessee and not the assessor (van Popta et al. 2017). Assessing may confer several distinct advantages such as drawing comparisons with peers’ work and increased familiarity with evaluative criteria. Several studies have compared the effect of assessing with being assessed. Lundstrom and Baker (2009) found that assessing a peer’s written work was more beneficial for their own writing than being assessed by a peer. Meanwhile, Graner (1987) found that students who were receiving feedback from a peer and acted as an assessor did not perform better than students who acted as an assessor but did not receive peer feedback. Reviewing peers’ work is also likely to help students become better reviewers of their own work and to revise and improve their own work (Rollinson 2005). While, in practice, students will most often act as both assessor and assessee during peer assessment, it is useful to gain a greater insight into the relative impact of performing each of these roles for both practical reasons and to help determine the mechanisms by which peer assessment improves academic performance.
Peer Assessment Type
The characteristics of peer assessment vary greatly both in practice and within the research literature. Because meta-analysis is unable to capture all of the nuanced dimensions that determine the type, intensity, and quality of peer assessment, we focus on distinguishing between what we regard as the most prevalent types of peer assessment in the literature: grading, peer dialogs, and written assessment. Each of these peer assessment types is widely used in the classroom and often in various combinations (e.g., written qualitative feedback in combination with a numerical grade). While these assessment types differ substantially in terms of their cognitive complexity and comprehensiveness, each has shown at least some evidence of impactive academic performance (e.g., Sanchez et al. 2017; Smith et al. 2009; Topping 2009).
Freeform/Scaffolding
Peer assessment is often implemented in conjunction with some form of scaffolding, for example, rubrics, and scoring scripts. Scaffolding has been shown to improve both the quality peer assessment and increase the amount of feedback assessors provide (Peters, Körndle & Narciss, 2018). Peer assessment has also been shown to be more accurate when rubrics are utilised. For example, Panadero, Romero, & Strijbos (2013) found that students were less likely to overscore their peers.
Online
Increasingly, peer assessment has been performed online due in part to the growth in online learning activities as well as the ease by which peer assessment can be implemented online (van Popta et al. 2017). Conducting peer assessment online can significantly reduce the logistical burden of implementing peer assessment (e.g., Tannacito and Tuzi 2002). Several studies have shown that peer assessment can effectively be carried out online (e.g., Hsu 2016; Li and Gao 2016). Van Popta et al. (2017) argue that the cognitive processes involved in peer assessment, such as evaluating, explaining, and suggesting, similarly play out in online and offline environments. However, the social processes involved in peer assessment are likely to substantively differ between online and offline peer assessment (e.g., collaborating, discussing), and it is unclear whether this might limit the benefits of peer assessment through one or the other medium. To the authors’ knowledge, no prior studies have compared the effects of online and offline peer assessment on academic performance.
Anonymity
Because peer assessment is fundamentally a collaborative assessment practice, interpersonal variables play a substantial role in determining the type and quality of peer assessment (Strijbos and Wichmann 2018). Some researchers have argued that anonymous peer assessment is advantageous because assessors are more likely to be honest in their feedback, and interpersonal processes cannot influence how assessees receive the assessment feedback (Rotsaert et al. 2018). Qualitative evidence suggests that anonymous peer assessment results in improved feedback quality and more positive perceptions towards peer assessment (Rotsaert et al. 2018; Vanderhoven et al. 2015). A recent qualitative review by Panadero and Alqassab (2019) found that three studies had compared anonymous peer assessment to a control group (i.e., open peer assessment) and looked at academic performance as the outcome. Their review found mixed evidence regarding the benefit of anonymity in peer assessment with one of the included studies finding an advantage of anonymity, but the other two finding little benefit of anonymity. Others have questioned whether anonymity impairs the development of cognitive and interpersonal development by limiting the collaborative nature of peer assessment (Strijbos and Wichmann 2018).
Frequency
Peers are often novices at providing constructive assessment and inexperienced learners tend to provide limited feedback (Hattie and Timperley 2007). Several studies have therefore suggested that peer assessment becomes more effective as students’ experience with peer assessment increases. For example, with greater experience, peers tend to use scoring criteria to a greater extent (Sluijsmans et al. 2004). Similarly, training peer assessment over time can improve the quality of feedback they provide, although the effects may be limited by the extent of a student’s relevant domain knowledge (Alqassab et al. 2018). Frequent peer assessment may also increase positive learner perceptions of peer assessment (e.g., Sluijsmans et al. 2004). However, other studies have found that learner perceptions of peer assessment are not necessarily positive (Alqassab et al. 2018). This may suggest that learner perceptions of peer assessment vary depending on its characteristics (e.g., quality, detail).
Current Study
Given the previous reliance on narrative reviews and the increasing research and teacher interest in peer assessment, as well as the popularity of instructional theories advocating for peer assessment and formative assessment practices in the classroom, we present a quantitative meta-analytic review to develop and synthesise the evidence in relation to peer assessment. This meta-analysis evaluates the effect of peer assessment on academic performance when compared to no assessment as well as teacher assessment. To do this, the meta-analysis only evaluates intervention studies that utilised experimental or quasi-experimental designs, i.e., only studies with control groups, so that the effects of maturation and other confounding variables are mitigated. Control groups can be either passive (e.g., no feedback) or active (e.g., teacher feedback). We meta-analytically address two related research questions:
-
Q1
What effect do peer assessment interventions have on academic performance relative to the observed control groups?
-
Q2
What characteristics moderate the effectiveness of peer assessment?
Method
Working Definitions
The specific methods of peer assessment can vary considerably, but there are a number of shared characteristics across most methods. Peers are defined as individuals at similar (i.e., within 1–2 grades) or identical education levels. Peer assessment must involve assessing or being assessed by peers, or both. Peer assessment requires the communication (either written, verbal, or online) of task-relevant feedback, although the style of feedback can differ markedly, from elaborate written and verbal feedback to holistic ratings of performance.
We took a deliberately broad definition of academic performance for this meta-analysis including traditional outcomes (e.g., test performance or essay writing) and also practical skills (e.g., constructing a circuit in science class). Despite this broad interpretation of academic performance, we did not include any studies that were carried out in a professional/organisational setting other than professional skills (e.g., teacher training) that were being taught in a traditional educational setting (e.g., a university).
Selection Criteria
To be included in this meta-analysis, studies had to meet several criteria. Firstly, a study needed to examine the effect of peer assessment. Secondly, the assessment could be delivered in any form (e.g., written, verbal, online), but needed to be distinguishable from peer-coaching/peer-tutoring. Thirdly, a study needed to compare the effect of peer assessment with a control group. Pre-post designs that did not include a control/comparison group were excluded because we could not discount the effects of maturation or other confounding variables. Moreover, the comparison group could take the form of either a passive control (e.g., a no assessment condition) or an active control (e.g., teacher assessment). Fourthly, a study needed to examine the effect of peer assessment on a non-self-reported measure of academic performance.
In addition to these criteria, a study needed to be carried out in an educational context or be related to educational outcomes in some way. Any level of education (i.e., tertiary, secondary, primary) was acceptable. A study also needed to provide sufficient data to calculate an effect size. If insufficient data was available in the manuscript, the authors were contacted by email to request the necessary data (additional information was provided for a single study). Studies also needed to be written in English.
Literature Search
The literature search was carried out on 8 June 2018 using PsycInfo, Google Scholar, and ERIC. Google Scholar was used to check for additional references as it does not allow for the exporting of entries. These three electronic databases were selected due to their relevance to educational instruction and practice. Results were not filtered based on publication date, but ERIC only holds records from 1966 to present. A deliberately wide selection of search terms was used in the first instance to capture all relevant articles. The search terms included ‘peer grading’ or ‘peer assessment’ or ‘peer evaluation’ or ‘peer feedback’, which were paired with ‘learning’ or ‘performance’ or ‘academic achievement’ or ‘academic performance’ or ‘grades’. All peer assessment-related search terms were included with and without hyphenation. In addition, an ancestry search (i.e., back-search) was performed on the reference lists of the included articles. Conference programs for major educational conferences were searched. Finally, unpublished results were sourced by emailing prominent authors in the field and through social media. Although there is significant disagreement about the inclusion of unpublished data and conference abstracts, i.e., ‘grey literature’ (Cook et al. 1993), we opted to include it in the first instance because including only published studies can result in a meta-analysis over-estimating effect sizes due to publication bias (Hopewell et al. 2007). It should, however, be noted that none of the substantive conclusions changed when the analyses were re-run with the grey literature excluded.
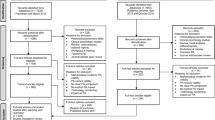
The database search returned 4072 records. An ancestry search returned an additional 37 potentially relevant articles. No unpublished data could be found. After duplicates were removed, two reviewers independently screened titles and abstracts for relevance. A kappa statistic was calculated to assess inter-rater reliability between the two coders and was found to be .78 (89.06% overall agreement, CI .63 to .94), which is above the recommended minimum levels of inter-rater reliability (Fleiss 1971). Subsequently, the full text of articles that were deemed relevant based on their abstracts was examined to ensure that they met the selection criteria described previously. Disagreements between the coders were discussed and, when necessary, resolved by a third coder. Ultimately, 55 articles with 143 effect sizes were found that met the inclusion criteria and included in the meta-analysis. The search process is depicted in Fig. 2.

Flow chart for the identification, screening protocol, and inclusion of publications in the meta-analyses
Data Extraction
A research assistant and the first author extracted data from the included papers. We took an iterative approach to the coding procedure whereby the coders refined the classification of each variable as they progressed through the included studies to ensure that the classifications best characterised the extant literature. Below, the coding strategy is reviewed along with the classifications utilised. Frequency statistics and inter-rater reliability for the extracted data for the different classifications are presented in Table 1. All extracted variable showed at least moderate agreement except for whether the peer assessment was freeform or structured, which showed fair agreement (Landis and Koch 1977).
Publication Type
Publications were classified into journal articles, conference papers, dissertations, reports, or unpublished records.
Education Level
Education level was coded as either graduate tertiary, undergraduate tertiary, secondary, or primary. Given the small number of studies that utilised graduate samples (N = 2), we subsequently combined this classification with undergraduate to form a general tertiary category. In addition, we recorded the grade level of the students. Generally speaking, primary education refers to the ages of 6–12, secondary education refers to education from 13–18, and tertiary education is undertaken after the age of 18.
Age and Sex
The percentage of students in a study that were female was recorded. In addition, we recorded the mean age from each study. Unfortunately, only 55.5% of studies recorded participants’ sex and only 18.5% of studies recorded mean age information.
Subject
The subject area associated with the academic performance measure was coded. We also recorded the nature of the academic performance variable for descriptive purposes.
Assessment Role
Studies were coded as to whether the students acted as peer assessors, assessees, or both assessors and assessees.
Comparison Group
Four types of comparison group were found in the included studies: no assessment, teacher assessment, self-assessment, and reader-control. In many instances, a no assessment condition could be characterised as typical instruction; that is, two versions of a course were run—one with peer assessment and one without peer assessment. As such, while no specific teacher assessment comparison condition is referenced in the article, participants would most likely have received some form of teacher feedback as is typical in standard instructional practice. Studies were classified as having teacher assessment on the basis of a specific reference to teacher feedback being provided.
Studies were classified as self-assessment controls if there was an explicit reference to a self-assessment activity, e.g., self-grading/rating. Studies that only included revision, e.g., working alone on revising an assignment, were classified as no assessment rather than self-assessment because they did not necessarily involve explicit self-assessment. Studies where both the comparison and intervention groups received teacher assessment (in addition to peer assessment in the case of the intervention group) were coded as no assessment to reflect the fact that the comparison group received no additional assessment compared to the peer assessment condition. In addition, Philippakos and MacArthur (2016) and Cho and MacArthur (2011) were notable in that they utilised a reader-control condition whereby students read, but did not assess peers’ work. Due to the small frequency of this control condition, we ultimately classified them as no assessment controls.
Peer Assessment Type
Peer assessment was characterised using coding we believed best captured the theoretical distinctions in the literature. Our typology of peer assessment used three distinct components, which were combined for classification:
-
1.
Did the peer feedback include a dialog between peers?
-
2.
Did the peer feedback include written comments?
-
3.
Did the peer feedback include grading?
Each study was classified using a dichotomous present/absent scoring system for each of the three components.
Freeform
Studies were dichotomously classified as to whether a specific rubric, assessment script, or scoring system was provided to students. Studies that only provided basic instructions to students to conduct the peer feedback were coded as freeform.
Was the Assessment Online?
Studies were classified based on whether the peer assessment was online or offline.
Anonymous
Studies were classified based on whether the peer assessment was anonymous or identified.
Frequency of Assessment
Studies were coded dichotomously as to whether they involved only a single peer assessment occasion or, alternatively, whether students provided/received peer feedback on multiple occasions.
Transfer
The level of transfer between the peer assessment task and the academic performance measure was coded into three categories:
-
1.
No transfer—the peer-assessed task was the same as the academic performance measure. For example, a student’s assignment was assessed by peers and this feedback was utilised to make revisions before it was graded by their teacher.
-
2.
Near transfer—the peer-assessed task was in the same or very similar format as the academic performance measure, e.g., an essay on a different, but similar topic.
-
3.
Far transfer—the peer-assessed task was in a different form to the academic performance task, although they may have overlapping content. For example, a student’s assignment was peer assessed, while the final course exam grade was the academic performance measure.
Allocation
We recorded how participants were allocated to a condition. Three categories of allocation were found in the included studies: random allocation at the class level, at the student level, or at the year/semester level. As only two studies allocated students to conditions at the year/semester level, we combined these studies with the studies allocated at the classroom level (i.e., as quasi-experiments).
Statistical Analyses of Effect Sizes
Effect Size Estimation and Heterogeneity
A random effects, multi-level meta-analysis was carried out using R version 3.4.3 (R Core Team 2017). The primary outcome was standardised mean difference between peer assessment and comparison (i.e., control) conditions. A common effect size metric, Hedge’s g, was calculated. A positive Hedge’s g value indicates comparatively higher values in the dependent variable in the peer assessment group (i.e., higher academic performance). Heterogeneity in the effect sizes was estimated using the I2 statistic. I2 is equivalent to the percentage of variation between studies that is due to heterogeneity (Schwarzer et al. 2015). Large values of the I2 statistics suggest higher heterogeneity between studies in the analysis.
Meta-regressions were performed to examine the moderating effects of the various factors that differed across the studies. We report the results of these meta-regressions alongside sub-groups analyses. While it was possible to determine whether sub-groups differed significantly from each other by determining whether the confidence interval around their effect sizes overlap, sub-groups analysis may also produce biased estimates when heteroscedasticity or multicollinearity are present (Steel and Kammeyer-Mueller 2002). We performed meta-regressions separately for each predictor to test the overall effect of a moderator.
Finally, as this meta-analysis included students from primary school to graduate school, which are highly varied participant and educational contexts, we opted to analyse the data both in complete form, as well as after controlling for each level of education. As such, we were able to look at the effect of each moderator across education levels and for each education level separately.
Robust Variance Estimation
Often meta-analyses include multiple effect sizes from the same sample (e.g., the effect of peer assessment on two different measures of academic performance). Including these dependent effect sizes in a meta-analysis can be problematic, as this can potentially bias the results of the analysis in favour of studies that have more effect sizes. Recently, Robust Variance Estimation (RVE) was developed as a technique to address such concerns (Hedges et al. 2010). RVE allows for the modelling of dependence between effect sizes even when the nature of the dependence is not specifically known. Under such situations, RVE results in unbiased estimates of fixed effects when dependent effect sizes are included in the analysis (Moeyaert et al. 2017). A correlated effects structure was specified for the meta-analysis (i.e., the random error in the effects from a single paper were expected to be correlated due to similar participants, procedures). A rho value of .8 was specified for the correlated effects (i.e., effects from the same study) as is standard practice when the correlation is unknown (Hedges et al. 2010). A sensitivity analysis indicated that none of the results varied as a function of the chosen rho. We utilised the ‘robumeta’ package (Fisher et al. 2017) to perform the meta-analyses. Our approach was to use only summative dependent variables when they were provided (e.g., overall writing quality score rather than individual trait measures), but to utilise individual measures when overall indicators were not available. When a pre-post design was used in a study, we adjusted the effect size for pre-intervention differences in academic performance as long as there was sufficient data to do so (e.g., t tests for pre-post change).
Results
Overall Meta-analysis of the Effect of Peer Assessment
Prior to conducting the analysis, two effect sizes (g = 2.06 and 1.91) were identified as outliers and removed using the outlier labelling rule (Hoaglin and Iglewicz 1987). Descriptive characteristics of the included studies are presented in Table 2. The meta-analysis indicated that there was a significant positive effect of peer assessment on academic performance (g = 0.31, SE = .06, 95% CI = .18 to .44, p < .001). A density graph of the recorded effect sizes is provided in Fig. 3. A sensitivity analysis indicated that the effect size estimates did not differ with different values of rho. Heterogeneity between the studies’ effect sizes was large, I2 = 81.08%, supporting the use of a meta-regression/sub-groups analysis in order to explain the observed heterogeneity in effect sizes.

A density plot of effect sizes
Meta-Regressions and Sub-Groups Analyses
Effect sizes for sub-groups are presented in Table 3. The results of the meta-regressions are presented in Table 4.
Education Level
A meta-regression with tertiary students as the reference category indicated that there was no significant difference in effect size as a function of education level. The effect of peer assessment was similar for secondary students (g = .44, p < .001) and primary school students (g = .41, p = .006) and smaller for tertiary students (g = .21, p = .043). There is, however, a strong theoretical basis for examining effects separately at different education levels (primary, secondary, tertiary), because of the large degree of heterogeneity across such a wide span of learning contexts (e.g., pedagogical practices, intellectual and social development of the students). We therefore will proceed by reporting the data both as a whole and separately for each of the education levels for all of the moderators considered here. Education level is contrast coded such that tertiary is compared to the average of secondary and primary and secondary and primary are compared to each other.
Comparison Group
A meta-regression indicated that the effect size was not significantly different when comparing peer assessment with teacher assessment, than when comparing peer assessment with no assessment (b = .02, 95% CI − .26 to .31, p = .865). The difference between peer assessment vs. no assessment and peer assessment vs. self-assessment was also not significant (b = − .03, CI − .44 to .38, p = .860), see Table 4. An examination of sub-groups suggested that peer assessment had a moderate positive effect compared to no assessment controls (g = .31, p = .004) and teacher assessment (g = .28, p = .007) and was not significantly different compared with self-assessment (g = .23, p = .209). The meta-regression was also re-run with education level as a covariate but the results were unchanged.
Assessment Role
Meta-regressions indicated that the participant’s role was not a significant moderator of the effect size; see Table 4. However, given the extremely small number of studies where participants did not act as both assessees (n = 2) and assessors (n = 4), we did not perform a sub-groups analysis, as such analyses are unreliable with small samples (Fisher et al. 2017).
Subject Area
Given that many subject areas had few studies (see Table 1) and the writing subject area made up the majority of effect sizes (40.74%), we opted to perform a meta-regression comparing writing with other subject areas. However, the effect of peer assessment did not differ between writing (g = .30, p = .001) and other subject areas (g = .31, p = .002); b= − .003, 95% CI − .25 to .25, p = .979. Similarly, the results did not substantially change when education level was entered into the model.
Peer Assessment Type
The effect of peer assessment did not differ significantly when peer assessment included a written component (g = .35, p < .001) than when it did not (g = .20, p = .015) , b= .144, 95% CI − .10 to .39, p = .241. Including education as a variable in the model did not change the effect written feedback. Similarly, studies with a dialog component (g = .21, p = .033) did not differ significantly from those that did not (g = .35, p < .001), b= − .137, 95% CI − .39 to .12, p = .279.
Studies where peer feedback included a grading component (g = .37, p < .001) did not differ significantly from those that did not (g = .17, p = .138). However, when education level was included in the model, the model indicated significant interaction effect between grading in tertiary students and the average effect of grading in primary and secondary students (b= .395, 95% CI .06 to .73, p = .022). A follow-up sub-groups analysis showed that grading was beneficial for academic performance in tertiary students (g = .55, p = .009), but not secondary school students (g = .002, p = .991) or primary school students (g = − .08, p = .762). When the three variables used to characterise peer assessment were entered simultaneously, the results were unchanged.
Freeform
The average effect size was not significantly different for studies where assessment was freeform, i.e., where no specific script or rubric was given (g = .42, p = .030) compared to those where a specific script or rubric was provided (g = .29, p < .001); b= − .13, 95% CI − .51 to .25, p = .455. However, there were few studies where feedback was freeform (n = 9, k =29). The results were unchanged when education level was controlled for in the meta-regression.
Online
Studies where peer assessment was online (g = .38, p = .003) did not differ from studies where assessment was offline (g = .24, p = .004); b= .16, 95% CI − .10 to .42, p = .215. This result was unchanged when education level was included in the meta-regression.
Anonymity
There was no significant difference in terms of effect size between studies where peer assessment was anonymised (g = .27, p = .019) and those where it was not (g = .25, p = .004); b= .03, 95% CI − .22 to .28, p = .811). Nor was the effect significant when education level was controlled for.
Frequency
Studies where peer assessment was performed just a single time (g = .19, p = .103) did not differ significantly from those where it was performed multiple times (g = .37, p < .001); b= -.17, 95% CI − .45 to .11, p = .223. Although it is worth noting that the results of the sub-groups analysis suggest that the effect of peer assessment was not significant when only considering studies that applied it a single time. The result did not change when education was included in the model.
Transfer
There was no significant difference in effect size between studies utilising far transfer (g = .21, p = .124) than those with near (g = .42, p < .001) or no transfer (g = .29, p = .017). Although it is worth noting that the sub-groups analysis suggests that the effect of peer assessment was only significant when there was no transfer to the criterion task. As shown in Table 4, this was also not significant when analysed using meta-regressions either with or without education in the model.
Allocation
Studies that allocated participants to experimental condition at the student level (g = .21, p = .14) did not differ from those that allocated condition at the classroom/semester level (g = .31, p < .001 and g = .79, p = .223 respectively), see Table 4 for meta-regressions.
Publication Bias
Risk of publication bias was assessed by inspecting the funnel plots (see Fig. 4) of the relationship between observed effects and standard error for asymmetry (Schwarzer et al. 2015). Egger’s test was also run by including standard error as a predictor in a meta-regression. Based on the funnel plots and a non-significant Egger’s test of asymmetry (b = .886, p = .226), risk of publication bias was judged to be low

A funnel plot showing the relationship between standard error and observed effect size for the academic performance meta-analysis
Discussion
Proponents of peer assessment argue that it is an effective classroom technique for improving academic performance (Topping 2009). While previous narrative reviews have argued for the benefits of peer assessment, the current meta-analysis quantifies the effect of peer assessment interventions on academic performance within educational contexts. Overall, the results suggest that there is a positive effect of peer assessment on academic performance in primary, secondary, and tertiary students. The magnitude of the overall effect size was within the small to medium range for effect sizes (Sawilowsky 2009). These findings also suggest that that the benefits of peer assessment are robust across many contextual factors, including different feedback and educational characteristics.
Recently, researchers have increasingly advocated for the role of assessment in promoting learning in educational practice (Wiliam 2018). Peer assessment forms a core part of theories of formative assessment because it is seen as providing new information about the learning process to the teacher or student, which in turn facilitates later performance (Pellegrino et al. 2001). The current results provide support for the position that peer assessment can be an effective classroom technique for improving academic performance. The result suggest that peer assessment is effective compared to both no assessment (which often involved ‘teaching as usual’) and teacher assessment, suggesting that peer assessment can play an important formative role in the classroom. The findings suggest that structuring classroom activities in a way that utilises peer assessment may be an effective way to promote learning and optimise the use of teaching resources by permitting the teacher to focus on assisting students with greater difficulties or for more complex tasks. Importantly, the results indicate that peer assessment can be effective across a wide range of subject areas, education levels, and assessment types. Pragmatically, this suggests that classroom teachers can implement peer assessment in a variety of ways and tailor the peer assessment design to the particular characteristics and constraints of their classroom context.
Notably, the results of this quantitative meta-analysis align well with past narrative reviews (e.g., Black and Wiliam 1998a; Topping 1998; van Zundert et al. 2010). The fact that both quantitative and qualitative syntheses of the literature suggest that peer assessment can be beneficial provides a stronger basis for recommending peer assessment as a practice. However, several of the moderators of the effectiveness of peer feedback that have been argued for in the available narrative reviews (e.g., rubrics; Panadero and Jonsson 2013) have received little support from this quantitative meta-analysis. As detailed below, this may suggest that the prominence of such feedback characteristics in narrative reviews is more driven by theoretical considerations rather than quantitative empirical evidence. However, many of these moderating variables are complex, for example, rubrics can take many forms, and due to this complexity may not lend themselves as well to quantitative synthesis/aggregation (for a detailed discussion on combining qualitative and quantitative evidence, see Gorard 2002).
Mechanisms and Moderators
Indeed, the current findings suggest that the feedback characteristics deemed important by current theories of peer assessment may not be as significant as first thought. Previously, individual studies have argued for the importance of characteristics such as rubrics (Panadero and Jonsson 2013), anonymity (Bloom & Hautaluoma, 1987), and allowing students to practice peer assessment (Smith, Cooper, & Lancaster, 2002). While these feedback characteristics have been shown to affect the efficacy of peer assessment in individual studies, we find little evidence that they moderate the effect of peer assessment when analysed across studies. Many of the current models of peer assessment rely on qualitative evidence, theoretical arguments, and pedagogical experience to formulate theories about what determines effective peer assessment. While such evidence should not be discounted, the current findings also point to the need for better quantitative and experimental studies to test some of the assumptions embedded in these models. We suggest that the null findings observed in this meta-analysis regarding the proposed moderators of peer assessment efficacy should be interpreted cautiously, as more studies that experimentally manipulate these variables are needed to provide more definitive insight into how to design better peer assessment procedures.
While the current findings are ambiguous regarding the mechanisms of peer assessment, it is worth noting that without a solid understanding of the mechanisms underlying peer assessment effects, it is difficult to identify important moderators or optimally use peer assessment in the classroom. Often the research literature makes somewhat broad claims about the possible benefits of peer assessment. For example, Topping (1998, p.256) suggested that peer assessment may, ‘promote a sense of ownership, personal responsibility, and motivation… [and] might also increase variety and interest, activity and interactivity, identification and bonding, self-confidence, and empathy for others’. Others have argued that peer assessment is beneficial because it is less personally evaluative—with evidence suggesting that teacher assessment is often personally evaluative (e.g., ‘good boy, that is correct’) which may have little or even negative effects on performance particularly if the assessee has low self-efficacy (Birney, Beckmann, Beckmann & Double 2017; Double and Birney 2017, 2018; Hattie and Timperley 2007). However, more research is needed to distinguish between the many proposed mechanisms for peer assessment’s formative effects made within the extant literature, particularly as claims about the mechanisms of the effectiveness of peer assessment are often evidenced by student self-reports about the aspects of peer assessment they rate as useful. While such self-reports may be informative, more experimental research that systematically manipulates aspects of the design of peer assessment is likely to provide greater clarity about what aspects of peer assessment drive the observed benefits.
Our findings did indicate an important role for grading in determining the effectiveness of peer feedback. We found that peer grading was beneficial for tertiary students but not beneficial for primary or secondary school students. This finding suggests that grading appears to add little to the peer feedback process in non-tertiary students. In contrast, a recent meta-analysis by Sanchez et al. (2017) on peer grading found a benefit for non-tertiary students, albeit based on a relatively small number of studies compared with the current meta-analysis. In contrast, the present findings suggest that there may be significant qualitative differences in the performance of peer grading as students develop. For example, the criteria students use to assesses ability may change as they age (Stipek and Iver 1989). It is difficult to ascertain precisely why grading has positive additive effects in only tertiary students, but there are substantial differences in pedagogy, curriculum, motivation of learning, and grading systems that may account for these differences. One possibility is that tertiary students are more ‘grade orientated’ and therefore put more weight on peer assessment which includes a specific grade. Further research is needed to explore the effects of grading at different educational levels.
One of the more unexpected findings of this meta-analysis was the positive effect of peer assessment compared to teacher assessment. This finding is somewhat counterintuitive given the greater qualifications and pedagogical experience of the teacher. In addition, in many of the studies, the teacher had privileged knowledge about, and often graded the outcome assessment. Thus, it seems reasonable to expect that teacher feedback would better align with assessment objectives and therefore produce better outcomes. Despite all these advantages, teacher assessment appeared to be less efficacious than peer assessment for academic performance. It is possible that the pedagogical disadvantages of peer assessment are compensated for by affective or motivational aspects of peer assessment, or by the substantial benefits of acting as an assessor. However, more experimental research is needed to rule out the effects of potential methodological issues discussed in detail below.
Limitations
A major limitation of the current results is that they cannot adequately distinguish between the effect of assessing versus being an assessee. Most of the current studies confound giving and receiving peer assessment in their designs (i.e., the students in the peer assessment group both provide assessment and receive it), and therefore, no substantive conclusions can be drawn about whether the benefits of peer assessment extend from giving feedback, receiving feedback, or both. This raises the possibility that the benefit of peer assessment comes more from assessing, rather than being assessed (Usher 2018). Consistent with this, Lundstrom and Baker (2009) directly compared the effects of giving and receiving assessment on students’ writing performance and found that assessing was more beneficial than being assessed. Similarly, Graner (1987) found that assessing papers without being assessed was as effective for improving writing performance as assessing papers and receiving feedback.
Furthermore, more true experiments are needed, as there is evidence from these results that they produce more conservative estimates of the effect of peer assessment. The studies included in this meta-analysis were not only predominantly randomly allocated at the classroom level (i.e., quasi-experiments), but in all but one case, were not analysed using appropriate techniques for analysing clustered data (e.g., multi-level modelling). This is problematic because it makes disentangling classroom-level effects (e.g., teacher quality) from the intervention effect difficult, which may lead to biased statistical inferences (Hox 1998). While experimental designs with individual allocation are often not pragmatic for classroom interventions, online peer assessment interventions appear to be obvious candidates for increased true experiments. In particular, carefully controlled experimental designs that examine the effect of specific assessment characteristics, rather than ‘black-box’ studies of the effectiveness of peer assessment, are crucial for understanding when and how peer assessment is most likely to be effective. For example, peer assessment may be counterproductive when learning novel tasks due to students’ inadequate domain knowledge (Könings et al. 2019).
While the current results provide an overall estimate of the efficacy of peer assessment in improving academic performance when compared to teacher and no assessment, it should be noted that these effects are averaged across a wide range of outcome measures, including science project grades, essay writing ratings, and end-of-semester exam scores. Aggregating across such disparate outcomes is always problematic in meta-analysis and is a particular concern for meta-analyses in educational research, as some outcome measures are likely to be more sensitive to interventions than others (William, 2010). A further issue is that the effect of moderators may differ between academic domains. For example, some assessment characteristics may be important when teaching writing but not mathematics. Because there were too few studies in the individual academic domains (with the exception of writing), we are unable to account for these differential effects. The effects of the moderators reported here therefore need to be considered as overall averages that provide information about the extent to which the effect of a moderator generalises across domains.
Finally, the findings of the current meta-analysis are also somewhat limited by the fact that few studies gave a complete profile of the participants and measures used. For example, few studies indicated that ability of peer reviewer relative to the reviewee and age difference between the peers was not necessarily clear. Furthermore, it was not possible to classify the academic performance measures in the current study further, such as based on novelty, or to code for the quality of the measures, including their reliability and validity, because very few studies provide comprehensive details about the outcome measure(s) they utilised. Moreover, other important variables such as fidelity of treatment were almost never reported in the included manuscripts. Indeed, many of the included variables needed to be coded based on inferences from the included studies’ text and were not explicitly stated, even when one would reasonably expect that information to be made clear in a peer-reviewed manuscript. The observed effect sizes reported here should therefore be taken as an indicator of average efficacy based on the extant literature and not an indication of expected effects for specific implementations of peer assessment.
Conclusion
Overall, our findings provide support for the use of peer assessment as a formative practice for improving academic performance. The results indicate that peer assessment is more effective than no assessment and teacher assessment and not significantly different in its effect from self-assessment. These findings are consistent with current theories of formative assessment and instructional best practice and provide strong empirical support for the continued use of peer assessment in the classroom and other educational contexts. Further experimental work is needed to clarify the contextual and educational factors that moderate the effectiveness of peer assessment, but the present findings are encouraging for those looking to utilise peer assessment to enhance learning.
References
References marked with an * were included in the meta-analysis
*AbuSeileek, A. F., & Abualsha'r, A. (2014). Using peer computer-mediated corrective feedback to support EFL learners'. Language Learning & Technology, 18(1), 76-95.
Alqassab, M., Strijbos, J. W., & Ufer, S. (2018). Training peer-feedback skills on geometric construction tasks: Role of domain knowledge and peer-feedback levels. European Journal of Psychology of Education, 33(1), 11–30.
*Anderson, N. O., & Flash, P. (2014). The power of peer reviewing to enhance writing in horticulture: Greenhouse management. International Journal of Teaching and Learning in Higher Education, 26(3), 310–334.
*Bangert, A. W. (1995). Peer assessment: an instructional strategy for effectively implementing performance-based assessments. (Unpublished doctoral dissertation). University of South Dakota.
*Benson, N. L. (1979). The effects of peer feedback during the writing process on writing performance, revision behavior, and attitude toward writing. (Unpublished doctoral dissertation). University of Colorado, Boulder.
*Bhullar, N., Rose, K. C., Utell, J. M., & Healey, K. N. (2014). The impact of peer review on writing in apsychology course: Lessons learned. Journal on Excellence in College Teaching, 25(2), 91-106.
*Birjandi, P., & Hadidi Tamjid, N. (2012). The role of self-, peer and teacher assessment in promoting Iranian EFL learners’ writing performance. Assessment & Evaluation in Higher Education, 37(5), 513–533.
Birney, D. P., Beckmann, J. F., Beckmann, N., & Double, K. S. (2017). Beyond the intellect: Complexity and learning trajectories in Raven’s Progressive Matrices depend on self-regulatory processes and conative dispositions. Intelligence, 61, 63–77.
Black, P., & Wiliam, D. (1998a). Assessment and classroom learning. Assessment in Education: Principles, Policy & Practice, 5(1), 7–74.
Black, P., & Wiliam, D. (2009). Developing the theory of formative assessment. Educational Assessment, Evaluation and Accountability (formerly: Journal of Personnel Evaluation in Education), 21(1), 5.
Bloom, A. J., & Hautaluoma, J. E. (1987). Effects of message valence, communicator credibility, and source anonymity on reactions to peer feedback. The Journal of Social Psychology, 127(4), 329–338.
Brown, G. T., Irving, S. E., Peterson, E. R., & Hirschfeld, G. H. (2009). Use of interactive–informal assessment practices: New Zealand secondary students' conceptions of assessment. Learning and Instruction, 19(2), 97–111.
*Califano, L. Z. (1987). Teacher and peer editing: Their effects on students' writing as measured by t-unit length, holistic scoring, and the attitudes of fifth and sixth grade students (Unpublished doctoral dissertation), Northern Arizona University.
*Chaney, B. A., & Ingraham, L. R. (2009). Using peer grading and proofreading to ratchet student expectations in preparing accounting cases. American Journal of Business Education, 2(3), 39-48.
*Chang, S. H., Wu, T. C., Kuo, Y. K., & You, L. C. (2012). Project-based learning with an online peer assessment system in a photonics instruction for enhancing led design skills. Turkish Online Journal of Educational Technology-TOJET, 11(4), 236–246.
*Cho, K., & MacArthur, C. (2011). Learning by reviewing. Journal of Educational Psychology, 103(1), 73.
Cho, K., Schunn, C. D., & Charney, D. (2006). Commenting on writing: Typology and perceived helpfulness of comments from novice peer reviewers and subject matter experts. Written Communication, 23(3), 260–294.
Cook, D. J., Guyatt, G. H., Ryan, G., Clifton, J., Buckingham, L., Willan, A., et al. (1993). Should unpublished data be included in meta-analyses?: Current convictions and controversies. JAMA, 269(21), 2749–2753.
*Crowe, J. A., Silva, T., & Ceresola, R. (2015). The effect of peer review on student learning outcomes in a research methods course. Teaching Sociology, 43(3), 201–213.
*Diab, N. M. (2011). Assessing the relationship between different types of student feedback and the quality of revised writing. Assessing Writing, 16(4), 274-292.
Demetriadis, S., Egerter, T., Hanisch, F., & Fischer, F. (2011). Peer review-based scripted collaboration to support domain-specific and domain-general knowledge acquisition in computer science. Computer Science Education, 21(1), 29–56.
Dochy, F., Segers, M., & Sluijsmans, D. (1999). The use of self-, peer and co-assessment in higher education: A review. Studies in Higher Education, 24(3), 331–350.
Double, K. S., & Birney, D. (2017). Are you sure about that? Eliciting confidence ratings may influence performance on Raven’s progressive matrices. Thinking & Reasoning, 23(2), 190–206.
Double, K. S., & Birney, D. P. (2018). Reactivity to confidence ratings in older individuals performing the latin square task. Metacognition and Learning, 13(3), 309–326.
*Enders, F. B., Jenkins, S., & Hoverman, V. (2010). Calibrated peer review for interpreting linear regression parameters: Results from a graduate course. Journal of Statistics Education, 18(2).
*English, R., Brookes, S. T., Avery, K., Blazeby, J. M., & Ben-Shlomo, Y. (2006). The effectiveness and reliability of peer-marking in first-year medical students. Medical Education, 40(10), 965-972.
*Erfani, S. S., & Nikbin, S. (2015). The effect of peer-assisted mediation vs. tutor-intervention within dynamic assessment framework on writing development of Iranian Intermediate EFL Learners. English Language Teaching, 8(4), 128–141.
Falchikov, N., & Goldfinch, J. (2000). Student peer assessment in higher education: A meta-analysis comparing peer and teacher marks. Review of Educational Research, 70(3), 287–322.
*Farrell, K. J. (1977). A comparison of three instructional approaches for teaching written composition to high school juniors: teacher lecture, peer evaluation, and group tutoring (Unpublished doctoral dissertation), Boston University, Boston.
Fisher, Z., Tipton, E., & Zhipeng, Z. (2017). robumeta: Robust variance meta-regression (Version 2). Retrieved from https://CRAN.R-project.org/package = robumeta
Fleiss, J. L. (1971). Measuring nominal scale agreement among many raters. Psychological Bulletin, 76(5), 378.
Flórez, M. T., & Sammons, P. (2013). Assessment for learning: Effects and impact: CfBT Education Trust. England: Reading.
Fyfe, E. R., & Rittle-Johnson, B. (2016). Feedback both helps and hinders learning: The causal role of prior knowledge. Journal of Educational Psychology, 108(1), 82.
Gielen, S., Peeters, E., Dochy, F., Onghena, P., & Struyven, K. (2010a). Improving the effectiveness of peer feedback for learning. Learning and Instruction, 20(4), 304–315.
*Gielen, S., Tops, L., Dochy, F., Onghena, P., & Smeets, S. (2010b). A comparative study of peer and teacher feedback and of various peer feedback forms in a secondary school writing curriculum. British Educational Research Journal, 36(1), 143-162.
Gorard, S. (2002). Can we overcome the methodological schism? Four models for combining qualitative and quantitative evidence. Research Papers in Education Policy and Practice, 17(4), 345–361.
Graner, M. H. (1987). Revision workshops: An alternative to peer editing groups. The English Journal, 76(3), 40–45.
Hattie, J., & Timperley, H. (2007). The power of feedback. Review of Educational Research, 77(1), 81–112.
Hays, M. J., Kornell, N., & Bjork, R. A. (2010). The costs and benefits of providing feedback during learning. Psychonomic bulletin & review, 17(6), 797–801.
Hedges, L. V. (1981). Distribution theory for Glass's estimator of effect size and related estimators. journal of. Educational Statistics, 6(2), 107–128.
Hedges, L. V., Tipton, E., & Johnson, M. C. (2010). Robust variance estimation in meta-regression with dependent effect size estimates. Research Synthesis Methods, 1(1), 39–65.
Higgins, J. P., & Green, S. (2011). Cochrane handbook for systematic reviews of interventions. The Cochrane Collaboration. Version 5.1.0, www.handbook.cochrane.org
Hoaglin, D. C., & Iglewicz, B. (1987). Fine-tuning some resistant rules for outlier labeling. Journal of the American Statistical Association, 82(400), 1147–1149.
Hopewell, S., McDonald, S., Clarke, M. J., & Egger, M. (2007). Grey literature in meta-analyses of randomized trials of health care interventions. Cochrane Database of Systematic Reviews.
*Horn, G. C. (2009). Rubrics and revision: What are the effects of 3 RD graders using rubrics to self-assess or peer-assess drafts of writing? (Unpublished doctoral thesis), Boise State University
Hox, J. J. (1998). Multilevel modeling: When and why. In I. Balderjahn, R. Mathar, & M. Schader (Eds.), Classification, data analysis, and data highways (pp. 147–154). New Yor: Springer Verlag.
*Hsia, L. H., Huang, I., & Hwang, G. J. (2016). A web-based peer-assessment approach to improving junior high school students’ performance, self-efficacy and motivation in performing arts courses. British Journal of Educational Technology, 47(4), 618–632.
*Hsu, T. C. (2016). Effects of a peer assessment system based on a grid-based knowledge classification approach on computer skills training. Journal of Educational Technology & Society, 19(4), 100-111.
*Hussein, M. A. H., & Al Ashri, El Shirbini A. F. (2013). The effectiveness of writing conferences and peer response groups strategies on the EFL secondary students' writing performance and their self efficacy (A Comparative Study). Egypt: National Program Zero.
*Hwang, G. J., Hung, C. M., & Chen, N. S. (2014). Improving learning achievements, motivations and problem-solving skills through a peer assessment-based game development approach. Educational Technology Research and Development, 62(2), 129–145.
*Hwang, G. J., Tu, N. T., & Wang, X. M. (2018). Creating interactive E-books through learning by design: The impacts of guided peer-feedback on students’ learning achievements and project outcomes in science courses. Journal of Educational Technology & Society, 21(1), 25–36.
*Kamp, R. J., van Berkel, H. J., Popeijus, H. E., Leppink, J., Schmidt, H. G., & Dolmans, D. H. (2014). Midterm peer feedback in problem-based learning groups: The effect on individual contributions and achievement. Advances in Health Sciences Education, 19(1), 53–69.
*Karegianes, M. J., Pascarella, E. T., & Pflaum, S. W. (1980). The effects of peer editing on the writing proficiency of low-achieving tenth grade students. The Journal of Educational Research, 73(4), 203-207.
*Khonbi, Z. A., & Sadeghi, K. (2013). The effect of assessment type (self vs. peer) on Iranian university EFL students’ course achievement. Procedia-Social and Behavioral Sciences, 70, 1552-1564.
Kluger, A. N., & DeNisi, A. (1996). The effects of feedback interventions on performance: A historical review, a meta-analysis, and a preliminary feedback intervention theory. Psychological Bulletin, 119(2), 254.
Könings, K. D., van Zundert, M., & van Merriënboer, J. J. G. (2019). Scaffolding peer-assessment skills: Risk of interference with learning domain-specific skills? Learning and Instruction, 60, 85–94.
*Kurihara, N. (2017). Do peer reviews help improve student writing abilities in an EFL high school classroom? TESOL Journal, 8(2), 450–470.
Landis, J. R., & Koch, G. G. (1977). The measurement of observer agreement for categorical data. Biometrics, 33(1), 159–174.
*Li, L., & Gao, F. (2016). The effect of peer assessment on project performance of students at different learning levels. Assessment & Evaluation in Higher Education, 41(6), 885–900.
*Li, L., & Steckelberg, A. (2004). Using peer feedback to enhance student meaningful learning. Chicago: Association for Educational Communications and Technology.
Li, H., Xiong, Y., Zang, X., Kornhaber, M. L., Lyu, Y., Chung, K. S., & Suen, K. H. (2016). Peer assessment in the digital age: a meta-analysis comparing peer and teacher ratings. Assessment & Evaluation in Higher Education, 41(2), 245–264.
*Lin, Y.-C. A. (2009). An examination of teacher feedback, face-to-face peer feedback, and google documents peer feedback in Taiwanese EFL college students’ writing. (Unpublished doctoral dissertation), Alliant International University, San Diego, United States
Lipsey, M. W., & Wilson, D. B. (2001). Practical Meta-analysis. Thousand Oaks: SAGE publications.
*Liu, C.-C., Lu, K.-H., Wu, L. Y., & Tsai, C.-C. (2016). The impact of peer review on creative self-efficacy and learning performance in Web 2.0 learning activities. Journal of Educational Technology & Society, 19(2):286-297
Lundstrom, K., & Baker, W. (2009). To give is better than to receive: The benefits of peer review to the reviewer's own writing. Journal of Second Language Writing, 18(1), 30–43.
*McCurdy, B. L., & Shapiro, E. S. (1992). A comparison of teacher-, peer-, and self-monitoring with curriculum-based measurement in reading among students with learning disabilities. The Journal of Special Education, 26(2), 162-180.
Moeyaert, M., Ugille, M., Natasha Beretvas, S., Ferron, J., Bunuan, R., & Van den Noortgate, W. (2017). Methods for dealing with multiple outcomes in meta-analysis: a comparison between averaging effect sizes, robust variance estimation and multilevel meta-analysis. International Journal of Social Research Methodology, 20(6), 559–572.
*Montanero, M., Lucero, M., & Fernandez, M.-J. (2014). Iterative co-evaluation with a rubric of narrative texts in primary education. Journal for the Study of Education and Development, 37(1), 184-198.
Morris, S. B. (2008). Estimating effect sizes from pretest-posttest-control group designs. Organizational Research Methods, 11(2), 364–386.
*Olson, V. L. B. (1990). The revising processes of sixth-grade writers with and without peer feedback. The Journal of Educational Research, 84(1), 22–29.
Ossenberg, C., Henderson, A., & Mitchell, M. (2018). What attributes guide best practice for effective feedback? A scoping review. Advances in Health Sciences Education, 1–19.
*Ozogul, G., Olina, Z., & Sullivan, H. (2008). Teacher, self and peer evaluation of lesson plans written by preservice teachers. Educational Technology Research and Development, 56(2), 181.
Panadero, E., & Alqassab, M. (2019). An empirical review of anonymity effects in peer assessment, peer feedback, peer review, peer evaluation and peer grading. Assessment & Evaluation in Higher Education, 1–26.
Panadero, E., & Jonsson, A. (2013). The use of scoring rubrics for formative assessment purposes revisited: A review. Educational Research Review, 9, 129–144.
Panadero, E., Romero, M., & Strijbos, J. W. (2013). The impact of a rubric and friendship on peer assessment: Effects on construct validity, performance, and perceptions of fairness and comfort. Studies in Educational Evaluation, 39(4), 195–203.
*Papadopoulos, P. M., Lagkas, T. D., & Demetriadis, S. N. (2012). How to improve the peer review method: Free-selection vs assigned-pair protocol evaluated in a computer networking course. Computers & Education, 59(2), 182–195.
Paulus, T. M. (1999). The effect of peer and teacher feedback on student writing. Journal of second language writing, 8(3), 265–289.
Pellegrino, J. W., Chudowsky, N., & Glaser, R. (2001). Knowing what students know: the science and design of educational assessment. Washington: National Academy Press.
Peters, O., Körndle, H., & Narciss, S. (2018). Effects of a formative assessment script on how vocational students generate formative feedback to a peer’s or their own performance. European Journal of Psychology of Education, 33(1), 117–143.
*Philippakos, Z. A., & MacArthur, C. A. (2016). The effects of giving feedback on the persuasive writing of fourth-and fifth-grade students. Reading Research Quarterly, 51(4), 419-433.
*Pierson, H. (1967). Peer and teacher correction: A comparison of the effects of two methods of teaching composition in grade nine English classes. (Unpublished doctoral dissertation), New York University.
*Prater, D., & Bermudez, A. (1993). Using peer response groups with limited English proficient writers. Bilingual Research Journal, 17(1-2), 99-116.
Reinholz, D. (2016). The assessment cycle: A model for learning through peer assessment. Assessment & Evaluation in Higher Education, 41(2), 301–315.
*Rijlaarsdam, G., & Schoonen, R. (1988). Effects of a teaching program based on peer evaluation on written composition and some variables related to writing apprehension. (Unpublished doctoral dissertation), Amsterdam University, Amsterdam
Rollinson, P. (2005). Using peer feedback in the ESL writing class. ELT Journal, 59(1), 23–30.
Rotsaert, T., Panadero, E., & Schellens, T. (2018). Anonymity as an instructional scaffold in peer assessment: its effects on peer feedback quality and evolution in students’ perceptions about peer assessment skills. European Journal of Psychology of Education, 33(1), 75–99.
*Rudd II, J. A., Wang, V. Z., Cervato, C., & Ridky, R. W. (2009). Calibrated peer review assignments for the Earth Sciences. Journal of Geoscience Education, 57(5), 328-334.
*Ruegg, R. (2015). The relative effects of peer and teacher feedback on improvement in EFL students' writing ability. Linguistics and Education, 29, 73-82.
*Sadeghi, K., & Abolfazli Khonbi, Z. (2015). Iranian university students’ experiences of and attitudes towards alternatives in assessment. Assessment & Evaluation in Higher Education, 40(5), 641–665.
*Sadler, P. M., & Good, E. (2006). The impact of self- and peer-grading on student learning. Educational Assessment, 11(1), 1-31.
Sanchez, C. E., Atkinson, K. M., Koenka, A. C., Moshontz, H., & Cooper, H. (2017). Self-grading and peer-grading for formative and summative assessments in 3rd through 12th grade classrooms: A meta-analysis. Journal of Educational Psychology, 109(8), 1049.
Sawilowsky, S. S. (2009). New effect size rules of thumb. Journal of Modern Applied Statistical Methods, 8(2), 26.
*Schonrock-Adema, J., Heijne-Penninga, M., van Duijn, M. A., Geertsma, J., & Cohen-Schotanus, J. (2007). Assessment of professional behaviour in undergraduate medical education: Peer assessment enhances performance. Medical Education, 41(9), 836-842.
Schwarzer, G., Carpenter, J. R., & Rücker, G. (2015). Meta-analysis with R. Cham: Springer.
*Sippel, L., & Jackson, C. N. (2015). Teacher vs. peer oral corrective feedback in the German language classroom. Foreign Language Annals, 48(4), 688-705.
Sluijsmans, D. M., Brand-Gruwel, S., van Merriënboer, J. J., & Martens, R. L. (2004). Training teachers in peer-assessment skills: Effects on performance and perceptions. Innovations in Education and Teaching International, 41(1), 59–78.
Smith, H., Cooper, A., & Lancaster, L. (2002). Improving the quality of undergraduate peer assessment: A case for student and staff development. Innovations in education and teaching international, 39(1), 71–81.
Smith, M. K., Wood, W. B., Adams, W. K., Wieman, C., Knight, J. K., Guild, N., & Su, T. T. (2009). Why peer discussion improves student performance on in-class concept questions. Science, 323(5910), 122–124.
Steel, P. D., & Kammeyer-Mueller, J. D. (2002). Comparing meta-analytic moderator estimation techniques under realistic conditions. Journal of Applied Psychology, 87(1), 96.
Stipek, D., & Iver, D. M. (1989). Developmental change in children's assessment of intellectual competence. Child Development, 521–538.
Strijbos, J. W., & Wichmann, A. (2018). Promoting learning by leveraging the collaborative nature of formative peer assessment with instructional scaffolds. European Journal of Psychology of Education, 33(1), 1–9.
Strijbos, J.-W., Narciss, S., & Dünnebier, K. (2010). Peer feedback content and sender's competence level in academic writing revision tasks: Are they critical for feedback perceptions and efficiency? Learning and Instruction, 20(4), 291–303.
*Sun, D. L., Harris, N., Walther, G., & Baiocchi, M. (2015). Peer assessment enhances student learning: The results of a matched randomized crossover experiment in a college statistics class. PLoS One 10(12),
Tannacito, T., & Tuzi, F. (2002). A comparison of e-response: Two experiences, one conclusion. Kairos, 7(3), 1–14.
Team, R. (2017). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing; 2017: R Core Team.
Topping, K. (1998). Peer assessment between students in colleges and universities. Review of Educational Research, 68(3), 249-276.
Topping, K. (2009). Peer assessment. Theory Into Practice, 48(1), 20–27.
Usher, N. (2018). Learning about academic writing through holistic peer assessment. (Unpiblished doctoral thesis), University of Oxford, Oxford, UK.
*van den Boom, G., Paas, F., & van Merriënboer, J. J. (2007). Effects of elicited reflections combined with tutor or peer feedback on self-regulated learning and learning outcomes. Learning and Instruction, 17(5), 532-548.
*van Ginkel, S., Gulikers, J., Biemans, H., & Mulder, M. (2017). The impact of the feedback source on developing oral presentation competence. Studies in Higher Education, 42(9), 1671-1685.
van Popta, E., Kral, M., Camp, G., Martens, R. L., & Simons, P. R. J. (2017). Exploring the value of peer feedback in online learning for the provider. Educational Research Review, 20, 24–34.
van Zundert, M., Sluijsmans, D., & van Merriënboer, J. (2010). Effective peer assessment processes: Research findings and future directions. Learning and Instruction, 20(4), 270–279.
Vanderhoven, E., Raes, A., Montrieux, H., Rotsaert, T., & Schellens, T. (2015). What if pupils can assess their peers anonymously? A quasi-experimental study. Computers & Education, 81, 123–132.
Wang, J.-H., Hsu, S.-H., Chen, S. Y., Ko, H.-W., Ku, Y.-M., & Chan, T.-W. (2014a). Effects of a mixed-mode peer response on student response behavior and writing performance. Journal of Educational Computing Research, 51(2), 233–256.
*Wang, J. H., Hsu, S. H., Chen, S. Y., Ko, H. W., Ku, Y. M., & Chan, T. W. (2014b). Effects of a mixed-mode peer response on student response behavior and writing performance. Journal of Educational Computing Research, 51(2), 233-256.
*Wang, X.-M., Hwang, G.-J., Liang, Z.-Y., & Wang, H.-Y. (2017). Enhancing students’ computer programming performances, critical thinking awareness and attitudes towards programming: An online peer-assessment attempt. Journal of Educational Technology & Society, 20(4), 58-68.
Wiliam, D. (2010). What counts as evidence of educational achievement? The role of constructs in the pursuit of equity in assessment. Review of Research in Education, 34(1), 254–284.
Wiliam, D. (2018). How can assessment support learning? A response to Wilson and Shepard, Penuel, and Pellegrino. Educational Measurement: Issues and Practice, 37(1), 42–44.
Wiliam, D., Lee, C., Harrison, C., & Black, P. (2004). Teachers developing assessment for learning: Impact on student achievement. Assessment in Education: Principles, Policy & Practice, 11(1), 49–65.
*Wise, W. G. (1992). The effects of revision instruction on eighth graders' persuasive writing (Unpublished doctoral dissertation), University of Maryland, Maryland
*Wong, H. M. H., & Storey, P. (2006). Knowing and doing in the ESL writing class. Language Awareness, 15(4), 283.
*Xie, Y., Ke, F., & Sharma, P. (2008). The effect of peer feedback for blogging on college students' reflective learning processes. The Internet and Higher Education, 11(1), 18-25.
Young, J. E., & Jackman, M. G.-A. (2014). Formative assessment in the Grenadian lower secondary school: Teachers’ perceptions, attitudes and practices. Assessment in Education: Principles, Policy & Practice, 21(4), 398–411.
Yu, F.-Y., & Liu, Y.-H. (2009). Creating a psychologically safe online space for a student-generated questions learning activity via different identity revelation modes. British Journal of Educational Technology, 40(6), 1109–1123.
Acknowledgements
The authors would like to thank Kristine Gorgen and Jessica Chan for their help coding the studies included in the meta-analysis.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
ESM 1
(XLSX 40 kb)
Appendix
Appendix
Effect Size Calculation
Standardised mean differences were calculated as a measure of effect size. Standardised mean difference (d) was calculated using the following formula, which is typically used in meta-analyses (e.g., Lipsey and Wilson 2001).
where
As standardized mean difference (d) is known to have a slight positive bias (Hedges 1981), we applied a correction to bias-correct estimates (resulting in what is often referred to as Hedge’s g).
with
For studies where there was insufficient information to calculate Hedge’s g using the above method, we used the online effect size calculator developed by Lipsey and Wilson (2001) available http://www.campbellcollaboration.org/escalc. For pre-post design studies where adjusted means were not provided, we used the critical value relevant to the difference between peer feedback and control groups from the reported pre-intervention adjusted analysis (e.g., Analysis of Covariances) as suggested by Higgins and Green (2011). For pre-post designs studies where both pre and post intervention means and standard deviations were provided, we used an effect size estimate based on the mean pre-post change in the peer feedback group minus the mean pre-post change in the control group, divided by the pooled pre-intervention standard deviation as such an approach minimised bias and improves estimate precision (Morris 2008).
Variance estimates for each effect size were calculated using the following formula:
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Double, K.S., McGrane, J.A. & Hopfenbeck, T.N. The Impact of Peer Assessment on Academic Performance: A Meta-analysis of Control Group Studies. Educ Psychol Rev 32, 481–509 (2020). https://doi.org/10.1007/s10648-019-09510-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10648-019-09510-3