
Abstract
Adoption of Artificial Intelligence (AI) algorithms into the clinical realm will depend on their inherent trustworthiness, which is built not only by robust validation studies but is also deeply linked to the explainability and interpretability of the algorithms. Most validation studies for medical imaging AI report the performance of algorithms on study-level labels and lay little emphasis on measuring the accuracy of explanations generated by these algorithms in the form of heat maps or bounding boxes, especially in true positive cases. We propose a new metric – Explainability Failure Ratio (EFR) – derived from Clinical Explainability Failure (CEF) to address this gap in AI evaluation. We define an Explainability Failure as a case where the classification generated by an AI algorithm matches with study-level ground truth but the explanation output generated by the algorithm is inadequate to explain the algorithm's output. We measured EFR for two algorithms that automatically detect consolidation on chest X-rays to determine the applicability of the metric and observed a lower EFR for the model that had lower sensitivity for identifying consolidation on chest X-rays, implying that the trustworthiness of a model should be determined not only by routine statistical metrics but also by novel ‘clinically-oriented’ models.

Similar content being viewed by others

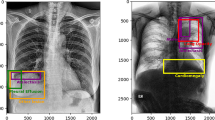

Data availability
Chest X-Ray data with bounding boxes drawn by AI and humans is available at https://github.com/caringresearch/clinical-explainability-failure-paper/https://github.com/caringresearch/clinical-explainability-failure-paper/
References
Qin ZZ, Sander MS, Rai B, Titahong CN, Sudrungrot S, Laah SN, Adhikari LM, Carter EJ, Puri L, Codlin AJ, Creswell J (2019) Using artificial intelligence to read chest radiographs for tuberculosis detection: A multi-site evaluation of the diagnostic accuracy of three deep learning systems. Sci Rep 9:15000. https://doi.org/10.1038/s41598-019-51503-3
Hurt B, Kligerman S, Hsiao A (2020) Deep learning localization of pneumonia: 2019 coronavirus (COVID-19) outbreak. J Thorac Imaging 35:W87–W89. https://doi.org/10.1097/RTI.0000000000000512
Crosby J, Chen S, Li F, MacMahon H, Giger M (2020) Network output visualization to uncover limitations of deep learning detection of pneumothorax. 11316:113160O. https://doi.org/10.1117/12.2550066
Pan I, Cadrin-Chênevert A, Cheng PM (2019) Tackling the radiological society of North America pneumonia detection challenge. AJR Am J Roentgenol 213:568–574. https://doi.org/10.2214/AJR.19.21512
Rajpurkar P, Irvin J, Ball RL, Zhu K, Yang B, Mehta H, Duan T, Ding D, Bagul A, Langlotz CP, Patel BN, Yeom KW, Shpanskaya K, Blankenberg FG, Seekins J, Amrhein TJ, Mong DA, Halabi SS, Zucker EJ, Ng AY, Lungren MP (2018) Deep learning for chest radiograph diagnosis: A retrospective comparison of the CheXNeXt algorithm to practicing radiologists. PLoS Medicine 15:e1002686. https://doi.org/10.1371/journal.pmed.1002686
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2020) Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int J Comput Vis 128:336–359. https://doi.org/10.1007/s11263-019-01228-7
Chicco D, Jurman G (2020) The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genomics 21:6. https://doi.org/10.1186/s12864-019-6413-7
Arun N, Gaw N, Singh P, Chang K, Aggarwal M, Chen B, Hoebel K, Gupta S, Patel J, Gidwani M, Adebayo J, Li MD, Kalpathy-Cramer J (2021) Assessing the (un)trustworthiness of saliency maps for localizing abnormalities in medical imaging
Venugopal VK, Vaidhya K, Murugavel M, Chunduru A, Mahajan V, Vaidya S, Mahra D, Rangasai A, Mahajan H (2020) Unboxing AI - radiological insights into a deep neural network for lung nodule characterization. Acad Radiol 27:88–95. https://doi.org/10.1016/j.acra.2019.09.015
Yala A, Lehman C, Schuster T, Portnoi T, Barzilay R (2019) A deep learning mammography-based model for improved breast cancer risk prediction. Radiology 292:60–66. https://doi.org/10.1148/radiol.2019182716
Ding Y, Sohn JH, Kawczynski MG, Trivedi H, Harnish R, Jenkins NW, Lituiev D, Copeland TP, Aboian MS, Mari Aparici C, Behr SC, Flavell RR, Huang S-Y, Zalocusky KA, Nardo L, Seo Y, Hawkins RA, Hernandez Pampaloni M, Hadley D, Franc BL (2019) A deep learning model to predict a diagnosis of alzheimer disease by using 18F-FDG PET of the brain. Radiology 290:456–464. https://doi.org/10.1148/radiol.2018180958
Mahajan V, Venugopal VK, Murugavel M, Mahajan H (2020) The algorithmic audit: Working with vendors to validate radiology-ai algorithms-how we do it. Acad Radiol 27:132–135. https://doi.org/10.1016/j.acra.2019.09.009
Acknowledgements
We would like to thank members of the CovBase (covbase.igib.res.in) initiative for helping spark discussion about this concept during its initial stages. We also thank Dr. Alexandre Cadrin-Chenevert for providing his Pneumonia Detection & Classification algorithm which was the winner of the RSNA- 2018 Kaggle Chest X-Ray challenge. We would also like to thank Ms. Nisha Syed Nasser who helped critically revise the paper in keeping with important intellectual content.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
All authors whose names appear on the submission: (1) made substantial contributions to the conception or design of the work; or the acquisition, analysis, or interpretation of data; or the creation of new software used in the work; (2) drafted the work/ revised it critically for important intellectual content and approved the version to be published.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Conflict of interest
All authors deny any potential conflict of interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Image & Signal Processing
Rights and permissions
About this article

Cite this article
Venugopal, V.K., Takhar, R., Gupta, S. et al. Clinical Explainability Failure (CEF) & Explainability Failure Ratio (EFR) – Changing the Way We Validate Classification Algorithms. J Med Syst 46, 20 (2022). https://doi.org/10.1007/s10916-022-01806-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10916-022-01806-2