
Abstract
Previous researchers of citation analysis often analyze patent data of a single authority because of the availability of the data and the simplicity of analysis. Patent analysis, on the other hand, is used not only for filing and litigation, but also for technology trend analysis. However, global technology trends cannot be understood only with the analysis of patent data issued by a single authority. In this paper, we propose the use of patents from multiple authorities and discuss the effect of bundling patent family information. We investigate the effect of patent families with cases from automobile drivetrain technology. Based on the results, we conclude that the use of multiple authorities’ patent data bundled with the patent family information can significantly improve the coverage and practicability of patent citation analysis.





Similar content being viewed by others
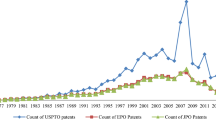
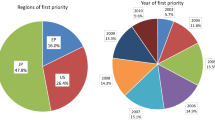
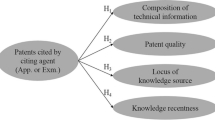
Notes
In this paper , Mr. Osawa, an expert in the domain of drivetrain technology and one of the authors of this paper, attributes meaning to the clusters based on the patents they contain.
The frequency of word i in Cluster s (FreWsi) was evaluated using the following formula:
$${\text{FreW}}_{{\text{si}}} = \frac{{n_{\text{s}} }}{{n_{\text{s}} }}{ \times }\log \left( {\frac{N}{{N_{\text{i}} }}} \right)$$Here, n si represents the number of word i that appeared in the DWPI title and the abstract of the patents of Cluster s obtained in citation analysis. n s represents the number of words that appeared in the title and the abstract of patents of Cluster s. N is the number of clusters in total. N i is the number of clusters in which a patent contains the word i in the title and the abstract.
References
Alberts, D., et al. (2011). Practical experience and requirements for searching the patent space. In M. Lupu, K. Mayer, J. Tait, & A. Trippe (Eds.), Current challenges in patent information retrieval (pp. 3–43). Heidelberg: Springer.
Alcácer, A., & Gittelman, M. (2006). Patent citations as a measure of knowledge flows: The influence of examiner citations. Review of Economics and Statistics, 88, 774–779.
Charkrabarti, A. K. (1991). Competition in high technology: Analysis of problems of US, Japan, UK, France, West Germany and Canada. IEEE Transactions on Engineering Management, 38(1), 78–84.
Clark, K. L., & Kowalski, S. P. (2012). Harnessing the power of patent information to accelerate innovation (pp. 427–435). Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery.
Cronin, B. (2001). Bibliometrics and beyond: some thoughts on web-based citation analysis. Journal of Information Science, 27(1), 1–7.
Erdi, P., et al. (2012). Prediction of emerging technologies based on analysis of the US patent citation network. Scientometrics, 95(1), 225–242.
Griliches, Z. (1990). Patent statistics as economic indicators: A survey. Journal of Economic Literature, 28(4), 1661–1707.
Kajikawa, Y., Yoshikawa, J., Takeda, Y., & Matsushima, K. (2008). Tracking emerging technologies in energy research: Toward a roadmap for sustainable energy. Technological Forecasting and Social Change, 75(6), 771–782.
Lai, K., & Wu, S. J. (2005). Using the patent co-citation approach to establish a new patent classification system. Information Processing and Management, 41, 313–330.
Lee, C., Park, H., & Park, Y. (2013). Keeping abreast of technology-driven business model evolution: A dynamic patent analysis approach. Technology Analysis and Strategic Management,. doi:10.1080/09537325.2013.785513.
Leydesdorff, L. (2008). Patent classifications as indicators of intellectual organization. Journal of the American Society for Information Science and Technology, 59(10), 1582–1597.
Leydesdorff, L., Kushnir, D., & Rafols, I. (2014). Interactive overlay maps for US patent (USPTO) data based on international patent classification (IPC). Scientometrics, 98, 1583–1599.
Lloyd, M. (2013). Can patent citation analysis be used with pharma or biotech patents? Amberblog. http://www.ambercite.com/index.php/amber/entry/can-patent-citation-analysis-be-used-with-pharma-or-biotech-patents#sthash.hyZaMXVD.dpuf. Accessed 5 June 2014.
Meyer, M. (2000). What is special about patent citations? Differences between scientific and patent citations. Scientometrics, 49, 93–123.
Meyer, M. (2002). Tracing knowledge flows in innovation systems. Scientometrics, 54(2), 193–212.
Nakamura, H., Suzuki, S., Tomobe, H., Kajikawa, Y., & Sakata, I. (2011). Citation lag analysis in supply chain research. Scientometrics, 87, 221–232.
Narin, F. (1994). Patent bibliometrics. Scientometrics, 30(1), 147–155.
Newman, M. E. J. (2004). Fast algorithm for detecting community structure in networks. Physical Review, 69, 066133.
Newman, M. E. J., & Girvan, M. (2004). Finding and evaluating community structure in networks. Physical Review, 69, 026133.
Nicolaisen, J. (2007). Citation analysis. Annual Review of Information Science and Technology, 14(3), 609–641.
Pavitt, K. (1985). Patent statistics as indicators of innovative activities: possibilities and problems. Scientometrics, 7, 77–99.
Simmons, E. S. (2009). “Black sheep” in the patent family. World Patent Information, 31, 11–18.
Su, F. P., Kai, K. K., Sharma, R. R. K., & Kuo, T. H. (2009). Patent priority network: Linking patent portfolio to strategic goals. Journal of the American Society for Information Science and Technology, 60(11), 2353–2361.
Su, F., Yang, W., & Lai, K. (2011). A heuristic procedure to identify the most valuable chain of patent priority network. Technological Forecasting and Social Change, 78, 319–331.
Trippe, T. (2013). Data mining lessons applied to analyzing patent documents, http://www.ipwatchdog.com/2013/03/12/data-mining-lessons-applied-to-analyzing-patent-documents-2/id=37137/. Accessed 5 June 2014.
Acknowledgments
A part of this research was carried out by the joint research program of the University of Tokyo and Toyota Central R&D Lab.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nakamura, H., Suzuki, S., Kajikawa, Y. et al. The effect of patent family information in patent citation network analysis: a comparative case study in the drivetrain domain. Scientometrics 104, 437–452 (2015). https://doi.org/10.1007/s11192-015-1626-2
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-015-1626-2