
Abstract
The main goal of time series analysis is to establish forecasting model based on past observations and to reduce forecasting error. To achieve these goals, the present paper proposes a new forecasting algorithm based on the fuzzy transform (F-transform) and the fuzzy logical relationships. First, the F-transform is performed based on partitioning of the universe, and the fuzzy logical relationships are employed to forecast. Two experimental applications are used to illustrate and verify the proposed algorithm. The accuracies are evaluated on the basis of average forecasting error percentage and index of agreement to compare the proposed algorithm with other existing methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
One of the main goals of time series analysis is to construct forecasting model that is used to predict future values based on past historical observations. The traditional time series models such as ARIMA and ARCH can not deal with forecasting problems with vague or ambiguous observations represented by linguistic concept. An appropriate way of solving such problem is by the use of time series model based on the fuzzy set theory. In addition, the time series models based on the fuzzy set theory can be applied to small sample data which is not easy to handle in traditional data analysis. To date, many forecasting models based on the fuzzy set theory [45] have been established by many authors and used to reduce forecasting error.
In this paper, we propose a new algorithm to forecast time series which is based on the fuzzy transform (F-transform) and fuzzy logical relationship. The F-transform introduced by Perfilieva [25] has been studied and found useful in many applications in function approximation, image processing [22, 27], numerical solutions of partial differential equations [36], data analysis [29] or neural network approaches [37]. The F-transform converts original data into weighted mean values where the weights are given by the basic functions which are membership functions to identify fuzzy sets. This is a novel method to find an approximation of given data or function.
In a time series analysis and forecast, the use of F-transform and inverse F-transform has been reported in many studies [22, 23, 36,37,38, 41]. In some studies, the F-transform was used to extract a low-frequency trend component [23, 36, 37], whereas it was used for the modeling of an autoregression function in [22]. Also, the inverse F-transform was used as a technical indicator in a stock market instead of the commonly used simple and exponential moving averages in other study [4]. \(\hbox {Nov}\acute{a}\hbox {k}\) et al. [23] have used inverse F-transform in combination with perception-based logical deduction, and \(\breve{S}\hbox {t}\breve{e}\hbox {pni}\breve{k}\hbox {a}\) et al. [36, 37] have provided forecasts of the future F-transform components.
Song and Chissom [32, 33] firstly introduced fuzzy time series which is a new algorithm of time series forecasting based on fuzzy logic. Many authors have suggested methods to modify and improve the model of Song and Chissom [2, 4, 9,10,11,12,13, 32,33,34,35, 40]. Some authors have applied their models to temperature forecasting [3, 18, 19], and others have used stock index forecasting [9,10,11, 16, 18, 19, 43, 44] to verify their models. Lee and Hong [20] have applied into electric power load forecasting.
Our proposed algorithm using fuzzy transform as defuzzified value of fuzzy sets corresponding to the partitioned intervals of domain is constructed by fuzzy logical relationships based on fuzzy time series. Generally, the fuzzy time series has used the non-overlapped membership functions. However, the proposed fuzzy time series algorithm based on the F-transform allows overlapping membership functions. The weighted sum of defuzzified values based on overlapping membership functions may play an important role in reducing the forecasting error. The proposed algorithm is applied to two well-known data sets: the enrollments of the University of Alabama and the number of patents granted in Taiwan, to show that it is superior to existing methods.
The rest of this paper is structured as follows: In Sect. 2, some preliminary concepts which are required to develop the main results are presented. In Sect. 3, the procedure of a forecasting method based on the F-transform applying fuzzy logical relationship is proposed. In Sect. 4, the experimental applications with enrollment data [32] and patents granted data of Taiwan [21] are provided. Section 5 concludes this study.
2 Preliminaries
A fuzzy subset of \({\mathbb {R}}\) is a map, the so-called membership function, from \({\mathbb {R}}\) into [0, 1]. Thus, a fuzzy subset A is identified by its membership function \(\mu _A(x)\). For any \(\alpha \in (0,1]\), the crisp set \(A_{\alpha }= \{ x \in {\mathbb {R}}: \mu _A(x) \ge \alpha \}\) is called the \(\alpha\)-cut or \(\alpha\)-level set of A. The set of all fuzzy numbers will be denoted by \({\mathcal {F}}_c({\mathbb {R}})\). As a special case, we often use the following parametric class of fuzzy numbers, the so-called LR-fuzzy numbers:
where \(L,R: {\mathbb {R}}^{+} \rightarrow [0,1]\) are fixed left-continuous and non-increasing functions with \(R(0) = L(0) = 1\) and \(R(1) = L(1) = 0\). L and R are called left and right shape functions of A, m the mode of A and \(l, r > 0\) are left, right spread of A. For any fuzzy set A, the function \(\mu _A(x) : {\mathbb {R}} \rightarrow [0,1]\) represents the membership function for which \(\mu _A(x)\) indicates the degree of membership of \(x \in {\mathbb {R}}\) that belongs to the fuzzy set A.
Fuzzy partitions which are needed in F-transform are introduced in several studies [8, 22, 25]. Here, we introduce some basic concepts defined in [25, 26, 28].
Let \(c_1< \cdots < c_k\) be fixed nodes within [a, b], such that \(c_1 = a, c_k = b\) and \(k \ge 2\). We say that fuzzy sets \(A_1\), \(\ldots\), \(A_k\), identified with their membership functions \(\mu _{A_1}(x)\), \(\ldots\), \(\mu _{A_k}(x)\) defined on [a, b], constitute a fuzzy partition of [a, b] if they fulfill the following conditions for \(l = 1,\ldots , k\):
-
1.
\(\mu _{A_l} : [a, b] \rightarrow [0, 1]\), \(\mu _{A_l}(c_l) = 1;\)
-
2.
\(\mu _{A_l }(x) = 0\) if \(x \not \in (c_{l-1}, c_{l+1})\) where for uniformity of the notation, we put \(c_0 = a\) and \(c_{k} = b\);
-
3.
\(\mu _{A_l} (x)\) is continuous;
-
4.
For all \(x \in [a, b]\),
$$\sum _{l=1}^{k} \mu _{A_l} (x) >0.$$The membership functions \(\mu _{A_1},\ldots , \mu _{A_k}\) are called basic functions.
The example of fuzzy sets \(A_1, \ldots ,A_k\) with symmetric triangular membership functions on the interval [a, b] is given for \((l = 1, \ldots , k)\) below:
where \(h_l =c_{l+1}-c_l\), \(c_0 =a\) and \(c_{k+1} =b\).
Let a discrete function \(f:X\rightarrow {\mathbb {R}}\) be given at a finite set of points \(X= \{x_t : t=1 \ldots , n \} \subseteq [a,b]\). The F-transform of a discrete function f with respect to \(A_1, \ldots , A_k\) defines the numerical vector \(F_k[f]=[F_1, F_2, \ldots , F_k]\), where each \(F_l\) is given by
The \(F_l\) are weighted mean values of f, where the weights are determined by the membership values. The \(F_l\) are called components of the discrete F-transform.
Let \(F_k[f]=[F_1, \ldots , F_k]\) be the F-transform of f with respect to \(A_1, \ldots , A_k\). Then the function
is called the inverse F-transform of f. The inverse F-transform \(f_{F,k}\) can approximate f with an arbitrary precision. For various properties of the F- transform and detailed proofs, see [28].
Next, we give some definitions of fuzzy time series proposed by Song and Chissom [32,33,34] and present a well-known fuzzy time series algorithm.
Let \(y_t (t=\ldots ,0,1,2,\ldots )\), a subset of \({\mathbb {R}}\), be the universe of discourse on which fuzzy sets \(A_i (i=1,2, \ldots )\) are defined and let F(t) be a collection of \(A_i\). Then, F(t) is called a fuzzy time series on \(y_t (t=\cdots ,0,1,2,\ldots )\). If for any time t, \(F(t)=F(t-1)\) and F(t) only has finite elements, then F(t) is called a time-invariant fuzzy time series. Otherwise, it is called a time-variant fuzzy time series.
Suppose \(F(t-1)=A_i\) and \(F(t)=A_j\), a fuzzy logical relationship is defined as \(A_i \rightarrow A_j\). Fuzzy logical relationships can be further grouped together into fuzzy logical relationship groups according to the same left-hand sides of the fuzzy logical relationships. For example, there are fuzzy logical relationships: \(A_i \rightarrow A_{j1}\), \(A_i \rightarrow A_{j2}, \ldots\), and \(A_i \rightarrow A_{jk}\). These fuzzy logical relationships can be grouped into a fuzzy logical relationship group as follows: \(A_i \rightarrow A_{j1}, A_{j2},\ldots , A_{jk}.\)
Song and Chissom employed five main procedures in fuzzy time series as follows: (1) define and partition the universe of discourse; (2) define fuzzy sets and fuzzify the observed data; (3) establish the fuzzy logical relationships; (4) divide the derived fuzzy logical relationships into fuzzy logical relationship groups and forecast; and (5) defuzzify the forecasting results.
3 Fuzzy Time Series Forecasting
It is assumed in this paper that observed time series \(\{y_t\}\) is time invariant. In case \(\{y_t\}\) is time variant, we transform it to invariant time series applying proper time differences with proper time lags. The prediction procedure is proposed as follows:
-
1.
Determine the universe of discourse U. Let \(D_{\text {max}}\) and \(D_{\text {min}}\) be the maximum and the minimum values of the observed time series data \(\{y_t : t=1,2, \ldots , n \}\). Then the universe of discourse U is defined by \([{D_{\text {min}} }-c_1, D_{\text {max}} + c_2]\), where \(c_1\) and \(c_2\) are the proper positive real numbers for simplifying these end points.
-
2.
Partition the universe of discourse U into several subintervals and generate fuzzy sets \(\{A_1, A_2, \ldots , A_{k}\}\) forming a fuzzy partition of U. A fuzzy partition for U is constructed by a decomposition \(\{a=c_1< c_2< \cdots < c_k=b \}\) of U into \(k-1\) subintervals \(I_j=[c_j,c_{j+1}],\) \(j=1,\ldots , k-1\) and by fuzzy sets \(\{A_1, A_2, \ldots , A_{k}\}\) identified by the membership functions (the basic functions) \(\mu _{A_1}(x),\ldots , \mu _{A_k}(x)\) for \(x \in U\).
-
3.
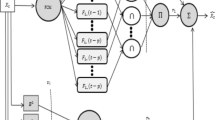
Fuzzify the observed time series data \(\{y_t : t=1,2, \ldots , n \}\). Each of the data is fuzzified q times which is the number of overlapped membership functions of corresponding data. In Fig. 1a, if \(y_t\) is included in the subinterval \(I_j\) and membership function defined on \(I_j\) is a left shape function of \(\mu _{A_{j+1}}(x)\), then we obtain \(A _{j+1}^{1}\) for its fuzzification. If membership function of defined on \(I_j\) is a right shape function of \(\mu _{A_{j}}(x)\), then we obtain \(A _{j}^{2}\) for its fuzzification. In Fig. 1, the number of overlapped membership functions \(q = 2\) in (a), (b) and \(q = 3\) in (c) (Fig. 2).
-
4.
Calculate \(F_1^h, F_2^h, \ldots F_{k}^h\) \((h=1, 2, \ldots , q)\) which are corresponding to \(A_1^h, A_2^h\), \(\ldots , A_{k}^h\) based on the following formula:
$$F_j^h=\frac{\sum _{t=1}^{n}y_t \mu _{A_j^h} (y_t )}{\sum _{t=1}^{n} \mu _{A_j^h} (y_t)}, \quad j=1, \ldots , k,$$(3)where \(\mu _{A_j^h} (y_t)\) is the membership degree of \(A_j^h\) at \(y_t\).
-
5.
Construction of fuzzy logical relationships. A fuzzy logical relationship is defined as the transition of the state at time \(t-1\) to the state at time t. This is expressed as \(A_i^h \rightarrow A_j^h (h = 1, 2, \ldots , p)\), where \(A_i^h\) and \(A_j^h\) are the states at \(t- 1\) and t, respectively.
-
6.
Calculate defuzzified predicted value \(m_j^h\) for each h at time t. At time t, \(m_j^h (h=1,\ldots , p)\) is determined by the following rules:
-
(i)
Rule 1: If the fuzzy logical relationship in the \(\lambda\)th order FLRGs is defined as
$$A_{i \lambda }^h, A_{i(\lambda -1)}^h, \ldots , A_{i 2}^h, A_{i1}^h \longrightarrow A_{j}^h$$then the value of \(m_j^h\) is equal to \(F_j^h\) corresponding to \(A_j^h\).
-
(ii)
Rule 2: If the fuzzy logical relationship in the FLRGs is shown as
$$A_{i \lambda }^h, A_{i(\lambda -1)}^h, \ldots , A_{i 2}^h, A_{i1}^h \longrightarrow A_{j1}^h, A_{j2}^h,\ldots , A_{jr}^h(r \ge 2)$$then the value of \(m_j^h\) is equal to average of \(F_{j1}^h, F_{j2}^h, \ldots F_{jr}^h\) corresponding to \(A_{j1}^h,A_{j2}^h, \ldots , A_{jr}^h\), respectively. Thus, \(m_j^h\) is given by
$$m_j^h=\frac{1}{r}\sum _{s=1}^{r}F_{js}^h.$$(4) -
(iii)
Rule 3: If the fuzzy logical relationship in the FLRGs is shown as
$$A_{i \lambda }^h, A_{i(\lambda -1)}^h, \ldots , A_{i 2}^h, A_{i1}^h \longrightarrow \text {empty}$$(5)then the value of \(m_j^h\) is
$$m_j^h=\frac{\lambda F_{i1}^h+(\lambda -1)F_{i2}^h +\cdots +1 F_{i \lambda }^h}{\lambda +(\lambda -1)+\cdots +1}.$$(6)
-
(i)
-
7.
Calculate the forecasted value \(m_j\) at time t as follows:
$$m_j= \frac{\sum _{h=1}^{p}w_j^h m_j^h}{\sum _{h=1}^{p} w_j^h},$$(7)where \(w_j^h= \frac{\lambda \mu _{A_{i1}^h}(y_t)+(\lambda -1) \mu _{A_{i2}^h}(y_t)+\cdots + \mu _{A_{i \lambda }^h}(y_t)}{\lambda +(\lambda -1)+\cdots +1}\) is the weighted value of \(m_j^h\) with respect to its membership degree.
Based on the seven steps presented above, the estimator for time series prediction can be obtained using F-transform.

Examples of basic functions. a Triangular function, b sinusoidal function, c trapezoidal function

Comparison of the predicted value and the actual value
The accuracy of the forecast can be evaluated by the basis of the index of \(\hbox {agreement}\,(D_1)\) and the basis of the index of \(\hbox {agreement}\,(D_2)\) suggested by Willmott [42]. These are computed as follows:
where N is the total number of data and \(O_i\), and \(P_i\) are the observed and predicted loads, respectively. \(O_i\) is the mean value of the observed value. The metric \(D_2\) quantifies the relative contribution of systematic error to random error and has a value of 1 in a perfect model [42].
4 Applications
In this section, we compare the accuracies of the fuzzy time series predictions by the method using F-transform provided in Sect. 3 on two data sets which are frequently used in fuzzy time series analysis.
4.1 Enrollment Data
The enrollment of the University of Alabama was introduced by Song and Chissom [32]. Many authors have used this data set which is provided in Table 1 to compare their works with other methods [5,6,7, 14, 24, 30, 31, 39]. Before we apply the whole procedure, we transform the data to time-invariant data using difference. The enrollment data from 1971 to 1992 are used as training data set to forecast the enrollment from 1993 to 2006 as follows:
-
1.
Define the universe of discourse U as \([{D_{\text {min}} }-c_1, D_{\text {max}} + c_2]\) = \([-1000,1400]\), where \(D_{\text {min}}=-955\) and \(D_{\text {max}}=1291\) with proper constants \(c_1\) and \(c_2\).
-
2.
Partition U into 8 intervals \(I_j=[c_j, c_{j+1}]\) where \(c_1=-1000\) and \(c_{j+1}=-1000+300j\) \((j=1,\ldots ,8)\). Construct a fuzzy partition of an interval by fuzzy sets with symmetric triangular basic functions as follows: \(A_1 =[-1000, -700]\), \(A_2 =[-1000, -400]\), \(A_3 =[-700, -100]\), \(A_4 =[-400, 200]\), \(A_5 =[-100, 500]\), \(A_6 =[200, 800]\), \(A_7 =[500, 1100]\), \(A_8 =[800, 1400]\), \(A_9 =[1000, 1400]\).
-
3.
There are two triangular membership functions for each \(y_t\); \(y_t\) can be fuzzified into two different types. For example, at \(t=1972\), 508 has corresponding membership degree 0.027 of fuzzy set \(A_7=[500,1100]\); it is fuzzified into \(A_7^1\). At the same time, 508 has corresponding membership degree 0.973 of fuzzy set \(A_6=[200,800]\); it is fuzzified into \(A_6^2\). Similarly, at \(t=1973\), 304 has corresponding membership degree 0.347 of fuzzy set \(A_6=[200,800]\); it is fuzzified into \(A_6^1\). At the same time, 304 has corresponding membership degree 0.653 of fuzzy set \(A_5\); it is fuzzified into \(A_5^2\).
-
4.
From (3), Table 2 shows \(F_1^h, \ldots , F_9^h\) \((h=1,2)\) which are corresponding to fuzzy sets \((A_1^h, \ldots , A_9^h)\). All values are rounded off to three decimal places.
-
5.
Table 3 shows 1st order fuzzy logical relationship obtained from given fuzzy time series.
-
6.
From Table 3, defuzzified values of predicted can be obtained. For example, left and right FLRs at \(t=1973\) are \(A_7^1 \rightarrow \{ A_6^1, A_4^1\}\), \(A_6^2 \rightarrow \{ A_5^2, A_3^2\}\), respectively. By Rule 2, defuzzified values of predicted fuzzy numbers are:
$$m_{1973}^1=\frac{1}{2}\left( F_4^1 +F_6^1\right) =66.98, m_{1973}^2=\frac{1}{2}\left( F_3^2 +F_5^2\right) =-11.26$$At \(t=1983\), left and right FLRs are \(A_2^1 \rightarrow \{ A_5^1\}\), \(A_1^2 \rightarrow \{ A_4^2\}\). By Rule 1, defuzzified values of predicted fuzzy numbers are:
$$m_{1983}^1=F_5^1 =61.93, m_{1983}^2=F_4^2=39.46$$ -
7.
Forecasted values can be obtained as follows: For example, for \(1972 \rightarrow 1973\), the weight of 1th order FLR is \(w_{1973}^h=\mu _{A_{l}^h(508)}\). So, we get \(w_{1973}^1=0.027\), \(w_{1973}^2=0.973\). Hence, the forecasted value at \(t=1973\) is
$$m_{1983}=\frac{0.027*66.98+0.973*(-11.26)}{0.027+0.973}+13{,}452=13{,}553.83.$$Similarly, when \(1982 \rightarrow 1983\), \(w_{1983}^1=0.150\), \(w_{1983}^2=0.850\) are the weights. Hence, the forecasted value at \(t=1983\) is
$$m_{1983}=\frac{0.150*61.93+0.850*39.46}{0.150+0.850}+15{,}433=15{,}475.83.$$
For training set, we have used the data from 1971 to 1992. Table 3 shows 1st order FLR, and Table 4 shows the accuracies of the results. As it is shown in Table 5, generally higher order may improve the accuracy, but it may cause difficulties to find the forecasting value because of its complexity. Table 6 provides comparison with many method suggested by many authors such as Chen et al. [5].
From the FLR of the training set in Table 3, the corresponding fuzzy set of \(t=1992\) are \(t=1992\) are \(A_3^1\), \(A_2^2\). So we obtain \(m_{1993}^1=61.93\), \(m_{1993}^2=39.46\), and \(w_{1993}^1=0.797\), \(w_{1993}^2=0.203\) at \(t=1993\). So, the 1th order forecasted value at \(t=1993\) can be represented by
Forecasted value \((m_{1994})\) of \(t=1994\) can be obtained after we add one more data item \((m_{1993})\) of \(t=1993\) to the training data set. Table 7 shows the forecasted values from 1993 to 2006.
4.2 The Number of Patents Granted in Taiwan
Table 8 shows the number of patents granted in Taiwan from 1980 to 2000 introduced by Liu [21]. The data set is transformed to be invariant time series by using first-order time difference because it is increasing. \([-7000, 11,000]\) is chosen to be the universe discourse based on minimum value \(-6017\) and maximum value 10675. Here, we have used triangular fuzzy numbers for basic functions on 9 \(\hbox {intervals}\,(q = 9)\). Forecasted data are provided in Table 8 with original data. Table 9 shows the accuracies after performing all 7 steps based on the orders of transform through time differences. 2nd order is chosen to forecast the data. Comparisons of the proposed method with other existing methods are provided in Table 10.
Next, we perform validations to confirm the superiority of the proposed method. The data from 1980 to 1995 have been used for training data set, and from 1996 to 2000 for testing data. The data from 1980 to 1995 are used to forecast the data at \(t=1996\). For forecasting the data at \(t=1997\), we add the data at \(t=1996\) to training data set. Likewise, we update the training data set adding one data point for the next forecasting. The forecasted results and the accuracies are provided in Table 11, which shows very good performances with \(D_1=2.8826\) and \(D_2=0.9882\).
5 Conclusions
In this paper, we propose a novel forecasting method based on F-transform and fuzzy time series to improve the forecasting accuracy. After applying F-transform to observed data, we construct a new fuzzy time series algorithm based on fuzzy logical relationships and F-transformed data. Through the real applications to enrollments of the University of Alabama and the number of patents granted in Taiwan, we show that forecasting accuracy can be further enhanced thorough applying F-transform. In addition, it is confirmed from these applications that the proposed method has better forecasting performances than existing methods. Future work involves extending the proposed method to handle two-factors fuzzy time series model and giving some results using various real applications to prove that it is correct.
References
Boukezzoula, R., Galichet, S., Foulloy, L.: MIN and MAX operator for fuzzy intervals and their potential use in aggregation operators. IEEE Trans. Fuzzy Syst. 15, 1135–1144 (2007)
Chen, S.M.: Forecasting enrollments based on fuzzy time series. Fuzzy Sets Syst. 81, 311–319 (1996)
Chen, S.M., Hwang, J.R.: Temperature prediction using fuzzy time series. IEEE Trans. Syst. Man Cybern. Part B Cybern. 30, 263–275 (2000)
Chen, S.M.: Forecasting enrollments based on high order fuzzy time series. Cybern. Syst. 33, 1–16 (2002)
Chen, S.M., Hsu, C.C.: A new method to forecast enrollments using fuzzy time series. Int. J. Appl. Sci. Eng. 2, 234–244 (2004)
Chou, M.T.: Long-term predictive value interval with the fuzzy time series. J. Mar. Sci. Technol. 19, 509–513 (2011)
Eğrioğlu, E.: A New Time-Invariant Fuzzy Time Series Forecasting Method Based on Genetic Algorithm. Advances in Fuzzy Systems. Hindawi Publishing Corporation, Cairo (2012)
Holcapeka, M., Tichy, T.: A smoothing filter based on fuzzy transform. Fuzzy Sets Syst. 180, 69–97 (2011)
Huarng, K.: Effective lengths of intervals to improve forecasting in fuzzy time series. Fuzzy Sets Syst. 123, 155–162 (2001a)
Huarng, K.: Heuristic models of fuzzy time series for forecasting. Fuzzy Sets Syst. 123, 369–386 (2001b)
Huarng, K., Yu, H.K.: A type 2 fuzzy time series model for stock index forecasting. Phys. A Stat. Mech. Appl. 353, 445–462 (2005)
Huarng, K., Yu, H.K.: Ratio-based lengths of intervals to improve fuzzy time series forecasting. IEEE Trans. Syst. Man Cybern. B Cybern. 36, 328–340 (2006)
Hwang, J.R., Chen, S.M., Lee, C.H.: Handling forecasting problems using fuzzy time series. Fuzzy Sets Syst. 100, 217–228 (1998)
Jilani, T., Burney, S., Ardil, C.: Multivariate high order fuzzy time series forecasting for car road accidents. Proc. World Acad. Sci. Eng. Technol. 25, 288–293 (2007)
Jung, H.Y., Choi, S.H.: Time series using fuzzy logic. Commun. Korean Stat. Soc. 15, 517–530 (2008)
Kuo, S.C., Chen, C.C., Li, S.T.: Evolutionary fuzzy relational modeling for fuzzy time series forecasting. Int. J. Fuzzy Syst. 17, 1295–1306 (2015)
Lee, H.S., Chou, M.T.: Fuzzy forecasting based on fuzzy time series. Int. J. Comput. Math. 81, 781–789 (2004)
Lee, L.W., Wang, L.H., Chen, S.M., Leu, Y.H.: Handling forecasting problems based on two factor high-order fuzzy time series. IEEE Trans. Fuzzy Syst. 14, 468–477 (2006)
Lee, L.W., Wang, L.H., Chen, S.M.: Temperature prediction and TAIFEX forecasting based on fuzzy logical relationships and genetic algorithms. Expert Syst. Appl. 33, 539–550 (2007)
Lee, W.J., Hong, J.A.: A hybrid dynamic and fuzzy time series model for mid-term power load forecasting. Int. J. Electr. Power Energy Syst. 64, 1057–1062 (2015)
Liu, H.T.: An improved fuzzy time series forecasting method using trapezoidal fuzzy numbers. Fuzzy Optim. Decis. Mak. 6, 63–80 (2007)
Di Martino, F., Loiab, V., Sessa, S.: Fuzzy transforms method in prediction data analysis. Fuzzy Sets Syst. 180, 146–163 (2011)
Novák, V., Štĕpnik̆a, V.M., Dvor̆ák, A., Perfilieva, I., Pavliska, V.: Analysis of seasonal time series using fuzzy approach. Int. J. Gen. Syst. 39, 305–328 (2010)
Nurhayadi, Subanar, Abdurakhman, Abadi, A.M.: Fuzzy model translation for time series data in the extent of median error and its application. Appl. Math. Sci. 8, 2113–2124 (2014)
Perfilieva, I., Haldeeva, E.: Fuzzy transformation. In: Proceedings of the Joint 9th IFSA World Congress and 20th NAFIPS International Conference, pp. 127–130 (2001)
Perfilieva, I.: Fuzzy transforms. Lecture notes in computer science 3135, 63–81 (2004)
Perfilieva, I., Valás̆ek, R.: Fuzzy transforms in removing noise. In: Reusch, B. (ed.) Computational Intelligence, Theory and Applications, Advances in Soft Computing, pp. 221–230. Springer, Berlin (2005)
Perfilieva, I.: Fuzy transforms: theory and applications. Fuzzy Sets Syst. 157, 993–1023 (2006)
Perfilieva, I., Novák, V., Antonín, Dvor̆ák, A.: Fuzzy transform in the analysis of data. Int. J. Approx. Reason. 48, 36–46 (2008)
Rzayev, R., Askerov, N., Agamaliyev, M.: Modifying a fuzzy time series models based on point-estimate of fuzzy outputs. Int. J. Data Min. Intell. Inf. Technol. Appl. 3, 24–30 (2013)
Saxena, P., Sharma, K., Easo, S.: Forecasting enrollments based on fuzzy time series with higher forecast accuracy rate. Comput. Technol. Appl. 3, 957–961 (2012)
Song, Q., Chissom, B.S.: Forecasting enrollments with fuzzy time series-part I. Fuzzy Sets Syst. 54, 1–10 (1993a)
Song, Q., Chissom, B.S.: Fuzzy time series and its models. Fuzzy Sets Syst. 54, 269–277 (1993b)
Song, Q., Chissom, B.S.: Forecasting enrollments with fuzzy time series-part II. Fuzzy Sets Syst. 62, 1–8 (1994)
Song, Q., Leland, R.P., Chissom, B.S.: A new fuzzy time-series model of fuzzy number observations. Fuzzy Sets Syst. 73, 341–348 (1995)
Štĕpnik̆a, M., Valás̆ek, R.: Numerical solution of partial differential equations with help of fuzzy transform. In: IEEE International Conference on Fuzzy Systems, pp. 1104–1109 (2005)
Štĕpnik̆a, M., Polakovic, O.: A neural network approach to the fuzzy transform. Fuzzy Sets Syst. 160, 1037–1047 (2009)
Štĕpnik̆, M., Dvor̆ák, A., Pavliska, V., Vavr̆íc̆ková, L.: Linguistic approach to time series modeling with the help of \(F\)-transform. Fuzzy Sets Syst. 180, 164–184 (2011)
Stevenson, M., Porter, J.E.: Fuzzy time series forecasting using percentage change as the universe of discourse. Proc. World Acad. Sci. Eng. Technol. 55, 154–157 (2009)
Sullivan, J., Woodal, W.H.: A comparison of fuzzy forecasting and Markov modeling. Fuzzy Sets Syst. 64, 279–293 (1994)
Troiano, L., Kriplani, P.: Supporting trading strategies by inverse fuzzy transform. Fuzzy Sets Syst. 180, 121–145 (2011)
Willmott, C.J.: Some comments on the evaluation of model performance. Bull. Am. Meteorol. Soc. 63, 1309–1313 (1982)
Xihao, S., Yimin, L.: Average-based fuzzy time series models for forecasting Shanghai compound index. World J. Model. Simul. 2, 104–111 (2008)
Yu, H.K.: Weighted fuzzy time series models for TAIEX forecasting. Phys. A 349, 609–624 (2005)
Zadeh, L.A.: Fuzzy sets. Inf. Control 8, 338–353 (1965)
Acknowledgements
This research was supported by Basic Science Research Program through the National Research Foundation of Korea(NRF) funded by the Ministry of Education(2017R1D1A1B03034813).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Lee, WJ., Jung, HY., Yoon, J.H. et al. A Novel Forecasting Method Based on F-Transform and Fuzzy Time Series. Int. J. Fuzzy Syst. 19, 1793–1802 (2017). https://doi.org/10.1007/s40815-017-0354-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-017-0354-6