
Abstract
With the rapid development of information technology and social network, the large-scale group decision-making (LSGDM) has become more and more popular due to the fact that large numbers of stakeholders are involved in different decision problems. To support the large-scale consensus-reaching process (LCRP), this paper proposes a LCRP framework based on a clustering method with the historical preference data of all decision makers (DMs). There are three parts in the proposed framework: the clustering process, the consensus process and the selection process. In the clustering process, we make use of an extended k-means clustering technique to divide the DMs into several clusters based on their historical preferences data. Next, the consensus process consists of the consensus measure and the feedback adjustment. The consensus measure aims to calculate the consensus level among DMs based on the obtained clusters. If the consensus level fails to reach the pre-defined consensus threshold, it is necessary to make the feedback adjustment to modify DMs' preferences. At last, the selection process is carried out to obtain a collective ranking of all alternatives. An illustrative example and detailed simulation experiments are demonstrated to show the validity of the proposed framework against the traditional LCRP models which just consider the preference information of DMs at only one stage for clustering.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Group decision-making (GDM) refers to a decision process where a group of decision makers (DMs) express their preferences regarding multiple alternatives and aim to obtain a ranking of the alternatives or select the best one(s) [1,2,3]. In GDM problems, the DMs usually express their opinions differently, while selecting a final solution with high consensus level among them is necessary. Therefore, the consensus-reaching process (CRP) was proposed and gradually became an effective tool to help DMs achieve a high consensus level, thus yielding a more acceptable solution [4,5,6]. Traditionally, the “hard” consensus in GDM considers only a full and unanimous agreement of DMs regarding the alternatives, which is sometimes time-consuming, difficult and unnecessary [7]. Therefore, the concept of “soft” consensus level [8, 9] was put forward and has been widely employed in different CRP models: (1) CRPs under different preference formats [6]; (2) CRPs with minimum adjustment or cost [10, 11]; (3) CRPs using consistency measure [12]; (4) CRPs considering the attitudes of DMs [13]; (5) CRPs under dynamic/Web contexts [14]; (6) CRPs based on trust relationship or DMs' weights [15, 16].
With the rapid development of information technology and social network, the increasing demands of organizations and the strengthening of the citizens' sense of democracy, more and more stakeholders are involved in different decision problems, which has led to the large-scale group decision-making (LSGDM) [17, 18]. Unlike traditional GDM problems which just involve a small number of DMs, LSGDM problems involve large numbers of DMs with various resources or information [19,20,21], and the number of DMs is usually no less than 20 in LSGDM events [22]. Generally speaking, decision outcome that may affect large numbers of groups or even the whole society is more appreciated if it is accepted by the masses with different backgrounds [23,24,25]. For example, the rescue plan about COVID-19 had great impact on the public, which might require the participation of large numbers of DMs from different fields. To date, the LSGDM has become a popular topic in decision analysis [26, 27], and many decision models were proposed to support the large-scale consensus-reaching process (LCRP). (1) LCRP addressing non-cooperative behaviors of DMs. For instance, Quesada et al. [27] proposed an expert weighting approach for the LCRP by incorporating the use of uninorm aggregation operators to manage experts' behaviors. Palomares et al. [28] incorporated a fuzzy clustering-based approach to detect and manage individual and subgroup non-cooperative behaviors in the LCRP. Furthermore, Gao and Zhang [29] proposed a consensus model to manage non-cooperative behaviors for personalized individual semantics-based social network GDM problems. (2) LCRP with individuals' different semantics or different formats of linguistic information. Li et al. [17] proposed a linguistic LCRP model based on personalized individual semantics, which took the individuals' different semantics into consideration. Zhang and Li [30] proposed a model for consistency control and consensus-reaching in linguistic GDM considering personalized individual semantics of DMs. Zhang et al. [31] proposed a linguistic distribution-based approach to deal with multiattribute LSGDM problems with multigranular unbalanced hesitant fuzzy linguistic information. (3) LCRP based on social network analysis. Liao et al. [32] proposed a LSGDM model based on social network analysis with probabilistic linguistic information. Ren et al. [33] developed a consensus model to manage minority opinions for LSGDM with social network analysis for micro-grid planning. There are also some other topics about LCRP. For instance, Wu and Xu [20] proposed a LCRP framework in which the fuzzy preference relations were used and the clusters were variable. Labella et al. [34] made a comparative study of different LCRP models by analyzing their different performances and sought out the main challenges of these models.
Although large numbers of LCRP models were proposed in the various studies, there are still some challenges which need to be pointed out.
-
1.
To our knowledge, the clustering is a widely used tool in LCRP models, and the obtained clusters are usually determined by the preference information of DMs. The existing studies just consider the preference information of DMs at only one stage for clustering. In fact, the DMs' preference information is changing in all decision rounds, thus forming the historical preference information. By comparison, the historical preference information is more comprehensive, and may better guide the clustering process. For example, some DMs may tend to make their preferences more similar to other DMs' preferences when a large gap exists between the DM's own preference and other preferences. Then, the preferences of these DMs are getting closer and closer to the average level during the LCRP. From this point, the preference information of DMs at only one stage fails to fully reflect the change of DMs' preferences. Hence, the historical preference information of DMs in all decision rounds needs to be taken into consideration.
-
2.
With the clustering method, the DMs are separated into a finite number of subgroups based on their preferences [35,36,37]. In most existing LCRP models, the clusters remain unchanged throughout the whole decision process [38, 39]. However, DMs' preferences are adjusted during the LCRP, so the clusters need to be variable in different decision stages. To our knowledge, only in few studies the clusters are variable, while their clusters are obtained based on the preference information of DMs at only one stage, rather than the historical preference information in all decision rounds. Therefore, it is important to propose a LCRP model where the clusters are variable in different decision stages through taking all the historical preference information of DMs into consideration.
To overcome the above challenges and shortcomings, this paper aims to propose a novel LCRP framework based on the clustering method using the historical preferences (CMHP) data of DMs. This framework is called CMHP-LCRP framework for simplicity. In the CMHP-LCRP framework, the historical preferences information of DMs in all decision rounds is used for clustering and the clusters are allowed to be variable accordingly in different decision stages. There are three parts in the proposed framework: the clustering process, the consensus process and the selection process. First, we divide the DMs into several clusters based on their historical preferences data. Next, it comes to the consensus process, which consists of the consensus measure and the feedback adjustment. The consensus level among DMs is measured based on the clustering results. If the consensus level fails to reach the pre-defined consensus threshold, the feedback adjustment strategy is employed to increase the consensus level among DMs. Otherwise, once the pre-defined consensus threshold is reached, the selection process is carried out to obtain a collective ranking of all alternatives. Finally, detailed simulation experiments and comparison analysis are demonstrated to show the validity of the CMHP-LCRP framework against the traditional LCRP models which just consider the preference information of DMs at only one stage for clustering.
This paper is organized as follows. Section 2 introduces some basic knowledge of GDM and the clustering technique. Then, the CMHP-LCRP framework is introduced in Sect. 3. Section 4 presents the clustering method, the consensus process and shows an illustrative example. Following this, in Sect. 5 the detailed simulation experiments and comparison analysis are demonstrated to show the validity of the CMHP-LCRP framework. Finally, concluding remarks and future studies are put forward in Sect. 6.
2 Preliminaries
In this section, we introduce the basic knowledge of GDM problem and k-means clustering technique, which can lay the foundation for the rest of this study.
2.1 GDM
We introduce the basic knowledge of GDM problem from the perspectives of preference relations, consensus process and selection process.
-
1.
GDM with preference relations
In a GDM problem, there exist two basic elements: a finite set of DMs \(E=\left\{{e}_{1},e,\dots ,{e}_{m}\right\}\left(m\ge 2\right)\), and a finite set of alternatives \(X=\left\{{x}_{1},{x}_{2},\dots ,{x}_{n}\right\}\left(n\ge 2\right)\). Each DM expresses the evaluation over these alternatives using a kind of preference structure. On the whole, there are a lot of preference representation formats, such as utility functions [40], preference orderings [41], multiplicative preference relations [42], additive preference relations [43,44,45] and linguistic preference relations [46]. Additive preference relations format proves to be an effective and advantageous tool to represent the preferences of DMs and thus is widely used in GDM problems [9, 47,48,49]. In this paper, it is assumed that DMs use the additive preference relations to express their opinions.
Definition 1
Additive preference relations. Let \({B}^{k}={[{b}_{ij}^{k}]}_{n\times n}\) be an additive preference relation provided by DM \({e}_{k}\left(k=\mathrm{1,2},\dots ,m\right)\), where \({b}_{ij}^{k}\) denotes the degree of preference for alternative \({x}_{i}\) over alternative \({x}_{j}\) for DM \({e}_{k}\). Notably, \({b}_{ij}^{k}>0.5\) means \({x}_{i}\) is preferred to \({x}_{j}\), \({b}_{ij}^{k}<0.5\) means \({x}_{j}\) is preferred to \({x}_{i}\), and \({b}_{ij}^{k}=0.5\) means there is no difference between \({x}_{i}\) and \({x}_{j}\). The additive preference relations have the additive reciprocity property, \({b}_{ij}^{k}+{b}_{ji}^{k}=1,\forall i,j\in \left\{\mathrm{1,2},\dots ,n\right\}.\)
Notably, the evaluation \({b}_{ii}^{k}\) \(\left(i=\mathrm{1,2},\dots ,n\right)\), situated in the diagonal of the matrix, means the alternative \({x}_{i}\) is evaluated with itself, so the values in such diagonal are all 0.5.
-
2.
Consensus process
In the existing literature, two processes are frequently used to solve GDM problems: consensus process and selection process.
The consensus process aims to raise the mutual agreement among DMs. There are different ways to interpret the consensus, such as the total agreement or some more flexible approaches. The consensus with a total agreement means the solution to the GDM problem is satisfactory for all DMs. In this situation, the cost might be unacceptable or the goal is sometimes hard to achieve in real life, which led to the development of soft consensus. In some studies, the flexible notion of consensus was proposed to soften the full and unanimous agreement [6, 50]. In this paper, a soft consensus-based approach is applied in LSGDM problems to obtain a satisfactory solution.
It is a dynamic and iterative discussion process to reach a certain degree of consensus in the CRP [8]. In general, there are two phases to achieve a consensus, which are described below. The first phase is to measure the consensus level that can reflect the degree of agreement among DMs based on their preferences. The second phase is feedback adjustment, which can provide guidance for DMs to modify their preferences and thus improve the degree of consensus among DMs. If the calculated consensus level does not reach the consensus threshold or it does not come to the maximum number of rounds allowed, the preferences resulting in disagreement are further recognized and the corresponding guidance for adjusting the DMs' preferences is provided so as to increase the consensus level in the next round.
-
3.
Selection process
The selection process aims to obtain a ranking of the alternatives or select the best alternative(s). The selection process usually consists of two phases: the aggregation phase and the exploitation phase.
The aggregation phase aims to derive a collective preference through aggregating all the individuals' preference relations. Let \({P}^{c}={\left[{p}_{ij}^{c}\right]}_{n\times n}\) be the collective preference relation, where \({p}_{ij}^{c}\) denotes the group's preference degree of alternative \({x}_{i}\) over \({x}_{j}\). In this paper, the widely used weighted average (WA) operator [51, 52] is employed to carry out the aggregation operation.
where \({w}_{k}\) denotes the weight of DM \({e}_{k}\in E\) and \({\sum }_{k=1}^{m}{w}_{k}=1\), \(0<{w}_{k}<1 \left(k=\mathrm{1,2},\dots ,m\right).\)
The exploitation phase aims to obtain a ranking of all alternatives, which is implemented by deriving the collective preference over alternatives \(X\) from the collective preference relation \({P}^{\mathrm{c}}={\left[{p}_{ij}^{\mathrm{c}}\right]}_{n\times n}\). Suppose \({pr}_{i}^{c}\ge 0\) means the collective preference over alternative \({x}_{i}\), and it is computed as follows.
The larger the value of \({pr}_{i}^{\mathrm{c}}\), the better the alternative \({x}_{i}\). According to the Eq. (3), the ranking of all the alternatives can be obtained.
2.2 K-means Clustering Technique
In the LCRP events, there are usually large numbers of DMs with diverse backgrounds and different preferences. For sake of analysis, these DMs are usually divided into several subgroups [20, 38, 53]. Clustering is a widely used tool contributing to data interpretation and analysis. With the clustering method, the data objects can be separated into a finite number of subgroups or clusters based on the similarity measure. In other words, the data objects in the same cluster share more similarities than those in different clusters. In the clustering process, each cluster is represented by a cluster center and the data belonging to such cluster show more similar characteristics. Many researches show that there are many clustering algorithms to compute the cluster centers and then determine the clustering results [54]. K-means clustering technique is one of the most popular clustering methods, and it also proves to be robust to determine the clustering result. Algorithm 1 shows the basic steps of the k-means clustering technique.
Algorithm 1. K-means clustering technique.
Input: The preference relations of all DMs \({B}^{k}={[{b}_{ij}^{k}]}_{n\times n} \left(k=\mathrm{1,2},\dots ,m\right)\) and the number of clusters \(Q (Q\ge 2)\).
Output: Clusters \(\left\{{G}_{1},{G}_{2},\dots ,{G}_{Q}\right\}\).
Step 1: Initialize \(Q\) cluster centers \({C}^{h}={\left[{c}_{ij}^{h}\right]}_{n\times n}\left(h=\mathrm{1,2},\dots ,Q\right)\) from the preference relations of DMs \({B}^{k}={[{b}_{ij}^{k}]}_{n\times n}\left( k=\mathrm{1,2},\dots ,m\right)\) randomly as the initial central matrices.
Step 2: For the preference relation \({B}^{k}\left(k=\mathrm{1,2},\dots ,m\right)\), calculate the Euclidean distance between it and each cluster center \({C}^{h}\left(h=\mathrm{1,2},\dots ,Q\right)\), denoted as \({N}_{kh}\), where
\({B}^{k}\) belongs to the corresponding cluster \({G}_{h}\) with the shortest distance \({N}_{kh}\).
Step 3: For each cluster \({G}_{h}\), update the center by averaging the preference relations \({B}^{k}\) assigned to it. Suppose the updated center is \({C}^{{h}^{^{\prime}}}={[{c}_{ij}^{{h}^{^{\prime}}}]}_{n\times n}\), then \({c}_{ij}^{{h}^{^{\prime}}}\)=\(\frac{1}{\left|{G}_{h}\right|}\sum_{{B}^{k}\in {G}_{h}}{b}_{ij}^{k}\), where \(\left|{G}_{h}\right|\) is the number of preference relations assigned to \({G}_{h}\).
Step 4: Compute the Euclidean distance between the cluster \({C}^{h}\) and \({C}^{{h}^{^{\prime}}}\), which is denoted as \(E\). The coefficient \(\varepsilon >0\) is set as a convergence threshold, and one common criterion is \(E\le \varepsilon\), where
If the criterion is not met, iterate Step 2 and Step 3 until convergence, which means the cluster centers are invariable. Otherwise, output the clusters \(\left\{{G}_{1},{G}_{2},\dots ,{G}_{Q}\right\}\).
3 The Proposed CMHP-LCRP Framework
In this section, we present a flexible LCRP framework using the clustering method with the historical preferences data of DMs.
3.1 Problem Description
As mentioned before, the clustering is a widely used tool to divide DMs into different clusters based on their preference relations in the LCRP. In the existing studies, the clustering process just considers the preference information of DMs at only one stage, which may fail to fully reflect the change of DMs' preferences. Therefore, it is of significance to take the historical preference information of DMs in all decision rounds into consideration and deal with it using proper theoretical models.
Recall that \(X=\left\{{x}_{1},{x}_{2},\dots ,{x}_{n}\right\}\left(n\ge 2\right)\) is a finite set of alternatives, \(E=\left\{{e}_{1},e,\dots ,{e}_{m}\right\}\) is a finite set of DMs,\({B}^{k}={[{b}_{ij}^{k}]}_{n\times n}\) is the additive preference relation provided by DM \({e}_{k}\) on \(X\), and \(W={\left({w}_{1},{w}_{2},\dots ,{w}_{m}\right)}^{T}\) is a weight vector, where the weight of DM \({e}_{k}\) is denoted as \({w}_{k}\) and \({\sum }_{i=1}^{m}{w}_{k}=1\).
In the decision process, the DMs are adjusting their preferences in all decision rounds, thus forming the historical preference information, which can better reflect the change of DMs' preferences. Therefore, how to design a LCRP framework based on a clustering method with the historical preference data of DMs is of significance.
3.2 The CMHP-LCRP Framework
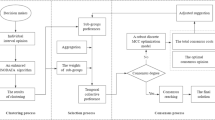
Figure 1 shows the CMHP-LCRP framework in detail. On the whole, there are three main parts, namely, the clustering process, the consensus process and the selection process.
-
1.
The clustering process

The CMHP-LCRP framework
Clustering is a popular tool to divide DMs into several clusters and it has been widely used to deal with LSGDM problems. According to the obtained clusters, the analysis becomes much easier. There are a lot of clustering techniques, and k-means algorithm is one of the most popular techniques because of its high efficiency, simplicity and fast convergence [54]. In this paper, an extended k-means algorithm is used for clustering purpose. In previous literatures, the clusters were obtained just based on the preference information of DMs in the latest decision round, rather than the total historical preference data in all decision rounds. As the total historical preference information can reflect the characteristics of DMs' preferences more comprehensively, in this paper the historical preference data of DMs in all decision rounds are employed for clustering, which is quite different from previous studies.
-
2.
The consensus process
For LCRP events, certain degree of consensus is essential. The consensus process aims to achieve the mutual agreement among DMs and it consists of the consensus measure and the feedback adjustment. The clustering process lays the foundation for the consensus measure. When the clusters are obtained, the consensus level among DMs can be calculated [55]. If the consensus level fails to reach the pre-defined consensus threshold or it does not come to the maximum number of rounds allowed, it is necessary to make the feedback adjustment strategy so as to achieve higher degree of consensus in the next round. Therefore, it is necessary to identify the DMs whose preference relations need to be adjusted. Based on this, some advice or suggestions are provided to modify the preference relations of DMs.
-
3.
The selection process
If the pre-defined consensus threshold is reached or it comes to the maximum number of rounds allowed, the selection process is carried out to obtain a collective ranking of all alternatives.
4 CMHP-LCRP Framework Analysis
In this section, we first present an extended k-means clustering method with the historical preference data. Next, the two main parts of LCRP, the consensus measure for obtained clusters and the corresponding feedback adjustment strategy are provided. Further, a detailed algorithm for the proposed CMHP-LCRP model to rank the alternatives is presented. At last, we use an example to illustrate the CMHP-LCRP model.
4.1 The Extended K-means Clustering Method with the Historical Preference Data
-
1.
The generation of historical preference data
K-means clustering technique proves to be robust to divide the DMs into several clusters and be widely used in the LSGDM problems. In this paper, an extended k-means clustering technique is used for clustering based on the DMs' historical preference data. Different from existing LCRP studies where clusters are usually obtained based on the preference information of DMs at only one stage, in this paper the historical preference data of DMs in all decision rounds are used for clustering. The detailed process of obtaining the historical preference data is described as follows.
Let \(E=\left\{{e}_{1},e,\dots ,{e}_{m}\right\}\) and \(X=\left\{{x}_{1},{x}_{2},\dots ,{x}_{n}\right\}\left(n\ge 2\right)\) be as before. The preference relation associated with DM \({e}_{k}\) on \(X\) in round \(z\) is denoted as \({B}^{k,z}\)=\({\left[{b}_{ij}^{k,z}\right]}_{n\times n}\left(k=\mathrm{1,2},\dots ,m\right)\). Next, we transform each preference relation \({B}^{k,z}\) into a vector that consists of its upper triangular elements, which is also denoted as \({B}^{k,z}\) for simplicity. Therefore,
Based on Eq. (6), the dimension of \({B}^{k,z}\) is \(n(n-1)/2\). In order to further simplify \({B}^{k,z}\), suppose \(y=n(n-1)/2\), and
For the DM \({e}_{k}\), all the historical preference data \(\left\{{B}^{k,z},{B}^{k,z-1},\dots ,{B}^{k,1}\right\}\left(k=\mathrm{1,2},\dots ,m\right)\) are used for clustering. Let all the historical preference of DM \({e}_{k}\) in round \(z\) be \({H}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\), which is presented as follows.
The dimension of \({H}^{k,z}\) is \(zy\), and \({H}^{k,z}\) can be further transformed as follows.
Based on \({H}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\), the DMs can be divided into different clusters, which lays the foundation for the LCRP analysis.
-
2.
The extended k-means clustering technique based on the historical preference data
Since k-means clustering method is a widely used tool and it proves to be robust to determine the clustering result, therefore we use it to divide the DMs into several clusters according to the total historical preference data \({H}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\). The procedures are as follows.
Input: All the historical preference relations \({H}^{k,z}=\left({b}_{1}^{k},{b}_{2}^{k},\dots ,{b}_{zy}^{k}\right)\left(k=\mathrm{1,2},\dots ,m\right)\) and the number of clusters \(Q (Q\ge 2)\)
Output: Clusters \(\left\{{G}_{1},{G}_{2},\dots ,{G}_{Q}\right\}.\)
Step 1: Initialize \(Q\) cluster centers \({C}^{h}=\left({c}_{1}^{h},{c}_{2}^{h},\dots ,{c}_{zy}^{h}\right)\left(h=\mathrm{1,2},\dots ,Q\right)\) from all the historical preference relations \({H}^{k,z}=\left({b}_{1}^{k},{b}_{2}^{k},\dots ,{b}_{zy}^{k}\right)\left(k=\mathrm{1,2},\dots ,m\right)\) randomly as the initial central vectors.
Step 2: For the historical preference relation \({H}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\), calculate the Euclidean distance between it and each cluster center \({C}^{h}\left(h=\mathrm{1,2},\dots ,Q\right)\), denoted as \({N}_{kh}\), where
\({H}^{k,z}\) belongs to the corresponding cluster \({G}_{h}\) with the shortest distance \({N}_{kh}\).
Step 3: For each cluster \({G}_{h}\), update the center by averaging all the historical preference relations \({H}^{k,z}\) assigned to it. Suppose the updated center is \({C}^{{h}^{^{\prime}}}=\left({c}_{1}^{{h}^{^{\prime}}},{c}_{2}^{{h}^{^{\prime}}},\dots ,{c}_{zy}^{{h}^{^{\prime}}}\right)\), then \({c}_{i}^{{h}^{^{\prime}}}\)=\(\frac{1}{\left|{G}_{h}\right|}\sum_{{H}^{k,z} \in {G}_{h}}{b}_{i}^{k}\), where \(\left|{G}_{h}\right|\) is the number of historical preference relations assigned to \({G}_{h}\).
Step 4: Compute the Euclidean distance between the cluster \({C}^{h}\) and \({C}^{{h}^{^{\prime}}}\), which is denoted as \(E\). The coefficient \(\varepsilon >0\) is set as a convergence threshold, and one common criterion is \(E\le \varepsilon\), where.
If the criterion is not met, iterate Step 2 and Step 3 until convergence. Otherwise, output the clusters \(\left\{{G}_{1},{G}_{2},\dots ,{G}_{Q}\right\}\).
4.2 The LCRP for the Proposed Framework
To achieve a certain degree of consensus in the CMHP-LCRP framework, there are usually two essential processes: consensus measure for clusters and local feedback adjustment strategy. At last, a detailed algorithm for the proposed CMHP-LCRP model to obtain the ranking of alternatives is presented.
4.2.1 Consensus Measure for Clusters
The consensus measure aims to calculate the degree of agreement among all DMs based on the obtained clusters. The steps to measure the consensus level of DMs are as follows.
-
1.
Weight measure for clusters
Using the extended k-means clustering technique, the DMs are divided into several clusters, which are denoted as \(\left\{{G}_{1},{G}_{2},\dots ,{G}_{Q}\right\}\). Let the number of DMs in cluster \({G}_{l}\) be \({m}_{l}\), \({m}_{l}>0\) and \({\sum }_{l=1}^{Q}{m}_{l}=m\). The DMs in cluster \({G}_{l}\) are denoted as \(\left\{{e}_{1}^{{G}_{l}},{e}_{2}^{{G}_{l}},\dots ,{e}_{{m}_{l}}^{{G}_{l}}\right\}\). Suppose the weight for DM \({e}_{k}^{{G}_{l}}\) is \({w}_{k}^{{G}_{l}}\), and the weight of cluster \({G}_{l}\) can be calculated by adding all the weights of DMs in such cluster together, which is shown as follows.
If the weights of all DMs are the same, then it follows that
Next, normalize the weight of each DM in cluster \({G}_{l}\). The normalized weight of \({e}_{k}^{{G}_{l}}\), denoted as \({u}_{k}^{{G}_{l}}\), is as follows
-
2.
Preference measure for clusters
The preference relation for cluster \({G}_{l}(l=\mathrm{1,2},\dots ,Q)\) is denoted as \({B}^{{G}_{l}}={\left[{b}_{ij}^{{G}_{l}}\right]}_{n\times n}(l=\mathrm{1,2},\dots ,Q)\), and it is a combination of the preferences of DMs in cluster \({G}_{l}\). Suppose the number of DMs in cluster \({G}_{l}\) is \({m}_{l}\), the preference relations in cluster \({G}_{l}\) for the pair of alternatives \(\left({x}_{i},{x}_{j}\right)\) are denoted as \(\left\{{b}_{ij}^{1,{G}_{l}},{b}_{ij}^{2,{G}_{l}},\dots ,{b}_{ij}^{{m}_{l},{G}_{l}}\right\}\), and the collective preference relation for cluster \({G}_{l}\) over the pair of alternatives \(\left({x}_{i},{x}_{j}\right)\) can be presented as follows.
-
3.
Similarity measure among clusters
For each pair of clusters \({G}_{s},{G}_{t}(s<t,\forall s,t\in \left\{\mathrm{1,2},\dots ,Q\right\})\), the similarity matrix \({\text{SM}}^{st}={\left({sm}_{ij}^{st}\right)}_{n\times n}\) is denoted as follows.
where \({sm}_{ij}^{st}\) measures the similarity degree between cluster \({G}_{s}\) and cluster \({G}_{t}\) over the pair of alternatives \(\left({x}_{i},{x}_{j}\right)\left(i,j=\mathrm{1,2},\dots ,n\right)\), and the formula is represented as follows.
where \({sm}_{ij}^{st}={sm}_{ij}^{ts}\).
-
4.
Consensus measure
There are three different kinds of consensus degrees [23, 56], namely, consensus degree for each pair of alternatives, consensus degree for each alternative and consensus degree for the whole preference relations.
-
(a)
Consensus degree for each pair of alternatives
For the pair of alternatives \(({x}_{i},{x}_{j})\), the consensus degree is denoted as \({cm}_{ij}\), which is calculated by aggregating the similarity matrices associated with each pair of clusters \(\left({G}_{s},{G}_{t}\right)\).
where \({w}_{st}\) is obtained by
\({cm}_{ij}\) measures the consensus degree over the pair of alternatives \(({x}_{i},{x}_{j})\). The larger the value of \({cm}_{ij}\), the higher the degree of agreement among DMs over the pair of alternatives \(({x}_{i},{x}_{j})\). Such a measure helps to identify the pair of alternatives where the preferences need to be adjusted in the next round.
-
(b)
Consensus degree for each alternative
For each alternative \({x}_{i}\left(i=\mathrm{1,2},\dots ,n\right)\), the consensus degree is denoted as \({ca}_{i}\), which is calculated by aggregating the consensus measures over each pair of alternatives.
\({ca}_{i}\) measures the consensus degree for each alternative \({x}_{i}\). The larger the value of \({ca}_{i}\), the higher the degree of agreement among DMs over this alternative. Also, such a measure helps to identify the alternatives where the preferences need to be adjusted in the next round.
-
(iii)
Consensus degree for the whole preference relations
The consensus degree for the whole preference relations is denoted \(cl\), which is calculated by aggregating the consensus measures over each alternative.
\(cl\) measures the global consensus level among all DMs. The larger the value of \(cl\), the higher the degree of agreement among all DMs. Such a measure can determine whether to proceed to the next round by comparing such value with the consensus threshold.
4.2.2 Local Feedback Strategy
According to the consensus measure, we can calculate the global consensus level, which reflects the degree of agreement among all DMs. In general, there is a pre-defined consensus threshold. If the actual consensus level reaches the consensus threshold, which means the agreement among DMs is satisfactory, the consensus process ends and the selection process starts. Otherwise, DMs are urged to adjust the preferences in the next round so as to reach a higher consensus level. Overall, there are various models to adjust the preference of DMs. In this paper, a supervised mode, which requires the DMs to follow the following rules, is used.
The feedback adjustment strategy consists of two parts: the identification process and the adjustments process. The identification process aims to identify the preferences relations that need to be adjusted. Following this, the adjustments process gives the adjustment suggestions. The procedures are as follows.
-
1.
The identification process.
The identification process consists of four identification rules, which help to precisely determine the alternatives, the pairs of alternatives, the clusters, and the DMs where the preferences need to be adjusted in the next round.
(a) Identification of alternatives. The first step is to identify the alternatives where the preferences need to be adjusted. Such alternatives are denoted as \({\text{CHX}}\), which satisfy the following rules.
According to Eq. (20), \({ca}_{i}\) represents the consensus degree over the alternative \({x}_{i}\left(i=\mathrm{1,2},\dots ,n\right)\). If the value of \({ca}_{i}\) is smaller than the global consensus level, the preferences over the alternative \({x}_{i}\) are supposed to be adjusted in the next round so as to speed up the LCRP.
(b) Identification of the pairs of alternatives (positions). Based on the Eq. (22), the next step is to identify the pair of alternatives where the preferences need to be adjusted. Such pairs of alternatives are denoted as \({\text{CHP}}\), which satisfy the following rules.
According to Eq. (18), \({cm}_{ij}\) represents the consensus degree over the pair of alternatives \(({x}_{i},{x}_{j})\). If the value of \({cm}_{ij}\) is smaller than the global consensus level, the preferences over the pair of alternatives \(({x}_{i},{x}_{j})\) are supposed to be adjusted in the next round so as to speed up the LCRP.
(c) Identification of the best and worst clusters for each identified position. Based on Eq. (23), the next step is to further identify the best cluster and worst cluster for each identified position, which are denoted as \({\text{CLT}}_{ij}^{+}\) and \({\text{CLT}}_{ij}^{-}\), respectively. The two clusters satisfy the following rules.
There are just one best cluster and one worst cluster. To accelerate the LCRP, the DMs in all the other clusters except the best cluster \({\text{CLT}}_{ij}^{+}\) are supposed to adjust the preferences in the next round. The other clusters are denoted as \({{\text{CLT}}_{ij}^{-}}^{^{\prime}}\), which satisfy the following rules.
(d) Identification of DMs. According Eqs. (23) and (26), the pairs of alternatives and the clusters where the preferences need to be adjusted have been identified. The DMs in \({{CLU}_{ij}^{-}}^{^{\prime}}\) are denoted as \({G}_{{s}^{-}}\left({x}_{i},{x}_{j}\right)=\left\{{e}_{{s}_{1}},{e}_{{s}_{2}},\dots ,{e}_{{s}_{G({s}^{-})}}\right\},\) where \(G\left({s}^{-}\right)=\#\left({G}_{{S}^{-}}({x}_{i},{x}_{j})\right)\) is the number of DMs in \({{\text{CLT}}_{ij}^{-}}^{^{\prime}}\). Note that the preference relation of DM \({e}_{{s}_{y}}\) is denoted as \({B}^{{s}_{y}}={\left[{b}_{ij}^{{s}_{y}}\right]}_{n\times n}\). Meanwhile, the DMs in \({\text{CLT}}_{ij}^{+}\) are denoted \({G}_{{s}^{+}}\left({x}_{i},{x}_{j}\right)=\left\{{e}_{{t}_{1}},{e}_{{t}_{2}},\dots ,{e}_{{t}_{G({s}^{+})}}\right\},\) where \(G\left({s}^{+}\right)=\#\left({G}_{{S}^{+}}({x}_{i},{x}_{j})\right)\) is the number of DMs in \({\text{CLT}}_{ij}^{+}\). The whole preference for the best cluster over the pair of alternatives \(({x}_{i},{x}_{j})\) is as follows.
Based on Eq. (27), a new parameter \(\beta\) is set and the DMs satisfying the following conditions need to adjust the preferences over the pair of alternatives \(({x}_{i},{x}_{j})\) in the next round.
According to Eq. (28), the DMs in \({E}_{ij}^{-}\) need to adjust their preferences over the pair of alternatives \(({x}_{i},{x}_{j})\). The parameter \(\beta\) plays the role of identifying the DMs that need to adjust the preferences. The larger the value of \(\beta\), the fewer the DMs that need to adjust their preferences.
-
2.
The adjustments process
Based on Eq. (28), the DMs that need to adjust their preferences have been identified. The next step is to adjust the preferences of the identified DMs. The updated preference of identified DM \({e}_{{s}_{y}}\) over the pair of alternatives \(({x}_{i},{x}_{j})\) is denoted as \({b}_{ij}^{{s}_{{y}^{^{\prime}}}}\), which satisfies the following two conditions.
According to Eqs. (29) and (30), for any identified \(i\mathrm{ and }j ( i<j),\) the updated preference relations follow certain direction and these updated preference relations become closer to the preference of the best cluster. Correspondingly, according to the rule of additive preference relations, \({b}_{ji}^{{s}_{{y}^{^{\prime}}}}\) is computed as follows.
4.2.3 Algorithm for the Proposed CMHP-LCRP Model
Based on the above, the details of the proposed CMHP-LCRP model are described in Algorithm 2.
Algorithm 2. CMHP-LCRP model.
Input: The preference relations of all DMs \({B}^{k}={[{b}_{ij}^{k}]}_{n\times n} \left(k=\mathrm{1,2},\dots ,m\right)\), the weights of DMs\(\left\{{w}_{1},{w}_{2},\dots ,{w}_{m}\right\}\), the number of clusters\(Q\), the parameter to adjust preference \(\beta\) and the consensus threshold\(\overline{cl }\).
Output: The ranking of alternatives.
Step 1: Let \(z=1\), \({B}^{k,z}={B}^{k}\) and \({w}_{k,z}={w}_{k}\left(k=\mathrm{1,2},\dots ,m\right)\). According to the WA operator, aggregate all DMs' preference relations \(\left\{{B}^{1,z},{B}^{2,z},\dots ,{B}^{m,z}\right\}\) to obtain the collective preference relation \({P}^{c,z}={\left[{p}_{ij}^{c,z}\right]}_{n\times n}\) based on Eq. (2).
Step 2: Gather the individuals' preference relations in each round \(\left\{{B}^{k,z},{B}^{k,z-1},\dots ,{B}^{k,1}\right\}\left(k=\mathrm{1,2},\dots ,m\right)\) and transform them into the historical preference relations \({H}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\) according to Eqs. (8) and (9).
Step 3: Based on the historical preference relations \({H}^{k,z}\), use the k-means clustering method to classify DMs into different clusters \(\left\{{G}_{1},{G}_{2},\dots ,{G}_{Q}\right\}.\)
Step 4: Calculate the global consensus level \({cl}_{z}\). If \({cl}_{z}\ge \overline{cl }\), go to step 6; otherwise continue with the next step.
Step 5: Identify the alternatives, the pairs of alternatives, the clusters and the DMs where the preferences need to be adjusted using the identification rules described in Sect. 4.2.2. The identified DMs are advised to adjust their preferences based on Eqs. (29)–(31), and back to step 2.
Step 6: Derive the ranking of alternatives from the evaluation values \({pr}_{i}^{c}=\frac{{\sum }_{j=1}^{n}{p}_{ij}^{c,z}}{n}\) according to Eq. (3). Output the ranking of alternatives.
4.3 Illustrative Example
To demonstrate the applicability of the CMHP-LCRP framework, we further present an illustrative example. In this example, a set of twenty DMs \(E=\left\{{e}_{1},{e}_{2},\dots ,{e}_{20}\right\}\) is assumed and a set of five alternatives \(X=\left\{{x}_{1},{x}_{2},{x}_{3},{x}_{4},{x}_{5}\right\}\) are involved. The weights of all DMs are supposed to be the same, i.e., \({w}_{k}=0.05 (k=\mathrm{1,2},\dots ,20)\). Let \(Q=3\), \(\beta =0.1\) and \(\overline{cl }=0.85\). The preference relations \({B}^{k}={\left[{b}_{ij}^{k}\right]}_{5\times 5}\) \(\left(k=\mathrm{1,2},\dots ,20\right)\) are listed below.
\({B}^{\mathrm{1,1}}=\left(\begin{array}{lll}0.5& 0.56& \begin{array}{lll}0.10& 0.65& 0.88\end{array}\\ 0.44& 0.5& \begin{array}{lll}0.65& 0.96& 0.86\end{array}\\ \begin{array}{c}0.90\\ 0.35\\ 0.12\end{array}& \begin{array}{c}0.35\\ 0.04\\ 0.14\end{array}& \begin{array}{lll}0.5& 0.33& 0.30\\ 0.67& 0.5& 0.12\\ 0.70& 0.88& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{2,1}}=\left(\begin{array}{lll}0.5& 0.35& \begin{array}{lll}0.47& 0.28& 0.50\end{array}\\ 0.65& 0.5& \begin{array}{lll}0.06& 0.61& 0.88\end{array}\\ \begin{array}{c}0.53\\ 0.72\\ 0.50\end{array}& \begin{array}{c}0.94\\ 0.39\\ 0.12\end{array}& \begin{array}{lll}0.5& 0.03& 0.78\\ 0.97& 0.5& 0.50\\ 0.22& 0.50& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{5,1}}=\left(\begin{array}{lll}0.5& 0.87& \begin{array}{lll}0.83& 1.00& 0.58\end{array}\\ 0.13& 0.5& \begin{array}{lll}0.33& 0.98& 0.88\end{array}\\ \begin{array}{c}0.17\\ 0\\ 0.42\end{array}& \begin{array}{c}0.67\\ 0.02\\ 0.12\end{array}& \begin{array}{lll}0.5& 0.51& 0.14\\ 0.49& 0.5& 1.00\\ 0.86& 0& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{6,1}}=\left(\begin{array}{lll}0.5& 0.43& \begin{array}{lll}0.02& 0.15& 0.72\end{array}\\ 0.57& 0.5& \begin{array}{lll}0.01& 0.92& 0.75\end{array}\\ \begin{array}{c}0.98\\ 0.85\\ 0.28\end{array}& \begin{array}{c}0.99\\ 0.08\\ 0.25\end{array}& \begin{array}{lll}0.5& 0.20& 0.26\\ 0.80& 0.5& 0.41\\ 0.74& 0.59& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{7,1}}=\left(\begin{array}{lll}0.5& 0.22& \begin{array}{lll}0.31& 0.53& 0.74\end{array}\\ 0.78& 0.5& \begin{array}{lll}0.68& 0.09& 0.11\end{array}\\ \begin{array}{c}0.69\\ 0.47\\ 0.26\end{array}& \begin{array}{c}0.32\\ 0.91\\ 0.89\end{array}& \begin{array}{lll}0.5& 0.48& 0.37\\ 0.52& 0.5& 0.18\\ 0.63& 0.82& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{8,1}}=\left(\begin{array}{lll}0.5& 0.62& \begin{array}{lll}0.19& 0.76& 0.12\end{array}\\ 0.38& 0.5& \begin{array}{lll}0.75& 0.75& 0.23\end{array}\\ \begin{array}{c}0.81\\ 0.24\\ 0.88\end{array}& \begin{array}{c}0.25\\ 0.25\\ 0.77\end{array}& \begin{array}{lll}0.5& 0.25& 0.02\\ 0.75& 0.5& 0.54\\ 0.98& 0.46& 0.50\end{array}\end{array}\right),\)
\({B}^{\mathrm{9,1}}=\left(\begin{array}{lll}0.5& 0.27& \begin{array}{lll}0.48& 0.21& 0.80\end{array}\\ 0.73& 0.5& \begin{array}{lll}0.20& 0.32& 0.05\end{array}\\ \begin{array}{c}0.52\\ 0.79\\ 0.20\end{array}& \begin{array}{c}0.80\\ 0.68\\ 0.95\end{array}& \begin{array}{lll}0.5& 0.39& 0.68\\ 0.61& 0.5& 0.38\\ 0.32& 0.62& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{10,1}}=\left(\begin{array}{lll}0.5& 0.94& \begin{array}{lll}0.25& 0.58& 0.19\end{array}\\ 0.06& 0.5& \begin{array}{lll}0.01& 0.28& 0.59\end{array}\\ \begin{array}{c}0.75\\ 0.42\\ 0.81\end{array}& \begin{array}{c}0.99\\ 0.72\\ 0.41\end{array}& \begin{array}{lll}0.5& 0.93& 0.88\\ 0.07& 0.5& 0.86\\ 0.12& 0.14& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{11,1}}=\left(\begin{array}{lll}0.5& 0.71& \begin{array}{lll}0.73& 0.41& 0.52\end{array}\\ 0.29& 0.5& \begin{array}{lll}0.06& 0.38& 0.72\end{array}\\ \begin{array}{c}0.27\\ 0.59\\ 0.48\end{array}& \begin{array}{c}0.94\\ 0.62\\ 0.28\end{array}& \begin{array}{lll}0.5& 0.12& 0.39\\ 0.88& 0.5& 0.56\\ 0.61& 0.44& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{12,1}}=\left(\begin{array}{lll}0.5& 0.95& \begin{array}{lll}0.26& 0.96& 0.05\end{array}\\ 0.05& 0.5& \begin{array}{lll}0.49& 0.76& 0.74\end{array}\\ \begin{array}{c}0.74\\ 0.04\\ 0.95\end{array}& \begin{array}{c}0.51\\ 0.24\\ 0.26\end{array}& \begin{array}{lll}0.5& 0.25& 0.89\\ 0.75& 0.5& 0.91\\ 0.11& 0.09& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{13,1}}=\left(\begin{array}{lll}0.5& 0.69& \begin{array}{lll}0.60& 0.12& 0.30\end{array}\\ 0.31& 0.5& \begin{array}{lll}0.71& 0.72& 0.99\end{array}\\ \begin{array}{c}0.40\\ 0.88\\ 0.70\end{array}& \begin{array}{c}0.29\\ 0.28\\ 0.01\end{array}& \begin{array}{lll}0.5& 0.71& 0.76\\ 0.29& 0.5& 0.44\\ 0.24& 0.56& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{14,1}}=\left(\begin{array}{lll}0.5& 0.67& \begin{array}{lll}0.25& 0.36& 0.83\end{array}\\ 0.33& 0.5& \begin{array}{lll}0.75& 0.42& 0.08\end{array}\\ \begin{array}{c}0.75\\ 0.64\\ 0.17\end{array}& \begin{array}{c}0.25\\ 0.58\\ 0.92\end{array}& \begin{array}{lll}0.5& 0.69& 0.94\\ 0.31& 0.5& 0.11\\ 0.06& 0.89& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{15,1}}=\left(\begin{array}{lll}0.5& 0.80& \begin{array}{lll}0.78& 0.02& 0.41\end{array}\\ 0.20& 0.5& \begin{array}{lll}0.10& 0.81& 1.00\end{array}\\ \begin{array}{c}0.22\\ 0.98\\ 0.59\end{array}& \begin{array}{c}0.90\\ 0.19\\ 0\end{array}& \begin{array}{lll}0.5& 0.96& 0.40\\ 0.04& 0.5& 0.05\\ 0.60& 0.95& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{16,1}}=\left(\begin{array}{lll}0.5& 0.70& \begin{array}{lll}0.20& 0.20& 0.22\end{array}\\ 0.30& 0.5& \begin{array}{lll}0.29& 0.01& 0.84\end{array}\\ \begin{array}{c}0.80\\ 0.80\\ 0.78\end{array}& \begin{array}{c}0.71\\ 0.99\\ 0.16\end{array}& \begin{array}{lll}0.5& 0.15& 0.19\\ 0.85& 0.5& 0.22\\ 0.81& 0.78& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{17,1}}=\left(\begin{array}{lll}0.5& 0.37& \begin{array}{lll}0.42& 0.25& 0.85\end{array}\\ 0.63& 0.5& \begin{array}{lll}0.15& 0.66& 0.72\end{array}\\ \begin{array}{c}0.58\\ 0.75\\ 0.15\end{array}& \begin{array}{c}0.85\\ 0.34\\ 0.28\end{array}& \begin{array}{lll}0.5& 0.46& 0.13\\ 0.54& 0.5& 0.04\\ 0.87& 0.96& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{18,1}}=\left(\begin{array}{lll}0.5& 0.55& \begin{array}{lll}0.99& 0.53& 0.05\end{array}\\ 0.45& 0.5& \begin{array}{lll}0.57& 0.17& 0.18\end{array}\\ \begin{array}{c}0.01\\ 0.47\\ 0.95\end{array}& \begin{array}{c}0.43\\ 0.83\\ 0.82\end{array}& \begin{array}{lll}0.5& 0.26& 0.26\\ 0.74& 0.5& 0.15\\ 0.74& 0.85& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{19,1}}=\left(\begin{array}{lll}0.5& 0.68& \begin{array}{lll}0.89& 0.62& 0.67\end{array}\\ 0.32& 0.5& \begin{array}{lll}0.47& 0.48& 0.23\end{array}\\ \begin{array}{c}0.11\\ 0.38\\ 0.33\end{array}& \begin{array}{c}0.53\\ 0.52\\ 0.77\end{array}& \begin{array}{lll}0.5& 0.67& 0.43\\ 0.33& 0.5& 0.80\\ 0.57& 0.20& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{20,1}}=\left(\begin{array}{lll}0.5& 0.43& \begin{array}{lll}0.59& 0.99& 0.30\end{array}\\ 0.57& 0.5& \begin{array}{lll}0.94& 0.64& 0.77\end{array}\\ \begin{array}{c}0.41\\ 0.01\\ 0.70\end{array}& \begin{array}{c}0.06\\ 0.36\\ 0.23\end{array}& \begin{array}{lll}0.5& 0.95& 0.62\\ 0.05& 0.5& 0.67\\ 0.38& 0.33& 0.5\end{array}\end{array}\right).\)
In the following, the proposed CMHP-LCRP framework is employed to show the LCRP.
4.4 First Round
In this example, three clusters are set for analysis. Based on individuals' preference relations, use the k-means clustering technique to classify DMs into the following clusters.
Based on Eq. (15), we can obtain the collective preferences for each cluster.
Based on Eq. (17), the similarity matrices are obtained as follows.
From Eqs. (18)–(20), we can obtain the consensus degrees for each alternative.
Therefore, according to Eq. (21) the global consensus level is calculated.
As \({cl}_{1}<0.85\), the feedback adjustment strategy is provided. As shown above, the consensus degrees for each alternative as well as those for each pair of alternatives are obtained. According to Eq. (22), we conclude the preferences over the alternatives \({x}_{1}\) and \({x}_{4}\) are supposed to be adjusted. According to Eq. (23), we further conclude the preferences over these pairs of alternatives \(\left({x}_{1},{x}_{3}\right)\), \(\left({x}_{1},{x}_{4}\right)\), \(\left({x}_{1},{x}_{5}\right)\) and \(\left({x}_{4},{x}_{5}\right)\) need to be adjusted. Then, the next step is to identify the best and worst clusters for each identified position. In order to accelerate the LCRP, in this paper the DMs in all the other clusters except the best cluster are supposed to adjust the preferences. Based on Eqs. (24) and (26), the ideal cluster and all the other clusters are presented as follows.
4.5 Second Round
In the example \(\beta =0.1\), from Eqs. (29)–(31) the DMs who need to adjust the preferences are identified, and the updated preferences for DMs are listed below.
Based on the historical preference relations, use the k-means clustering technique to classify DMs into the following clusters.
Based on Eq. (15), we can obtain the collective preferences for each cluster.
Based on Eq. (17), the similarity matrices are obtained as follows.
From Eqs. (18)–(20), we can obtain the consensus degrees for each alternative.
Therefore, according to Eq. (21) the global consensus level is calculated.
As \({cl}_{2}<0.85\), the feedback adjustment strategy is provided. According to Eq. (22), we conclude the preferences over the alternatives \({x}_{2}\) and \({x}_{3}\) are supposed to be adjusted. According to Eq. (23), we further conclude the preferences over these pairs of alternatives \(\left({x}_{2},{x}_{3}\right)\), \(\left({x}_{2},{x}_{5}\right)\) and \(\left({x}_{3},{x}_{4}\right)\) need to be adjusted. According to Eqs. (24) and (26), the ideal cluster and all the other clusters are presented as follows.
4.6 Third Round
From Eqs. (29)–(31), the DMs who need to adjust the preferences are identified, and the updated preferences for DMs are listed below.
\({B}^{\mathrm{3,3}}=\left(\begin{array}{lll}0.5& 0.22& \begin{array}{lll}0.51& 0.89& 0.33\end{array}\\ 0.78& 0.5& \begin{array}{lll}0.32& 0.96& 0.78\end{array}\\ \begin{array}{c}0.49\\ 0.11\\ 0.67\end{array}& \begin{array}{c}0.68\\ 0.04\\ 0.22\end{array}& \begin{array}{lll}0.5& 0.93& 0.01\\ 0.07& 0.5& 0.28\\ 0.99& 0.72& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{4,3}}=\left(\begin{array}{lll}0.5& 0.69& \begin{array}{lll}0.05& 0.32& 0.49\end{array}\\ 0.31& 0.5& \begin{array}{lll}0.50& 0.79& 0.81\end{array}\\ \begin{array}{c}0.95\\ 0.68\\ 0.51\end{array}& \begin{array}{c}0.50\\ 0.21\\ 0.19\end{array}& \begin{array}{lll}0.5& 0.51& 0.49\\ 0.49& 0.5& 0.33\\ 0.51& 0.67& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{5,3}}=\left(\begin{array}{lll}0.5& 0.87& \begin{array}{lll}0.83& 0.49& 0.58\end{array}\\ 0.13& 0.5& \begin{array}{lll}0.33& 0.98& 0.88\end{array}\\ \begin{array}{c}0.17\\ 0.51\\ 0.42\end{array}& \begin{array}{c}0.67\\ 0.02\\ 0.12\end{array}& \begin{array}{lll}0.5& 0.51& 0.14\\ 0.49& 0.5& 0.36\\ 0.86& 0.64& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{6,3}}=\left(\begin{array}{lll}0.5& 0.43& \begin{array}{lll}0.40& 0.31& 0.42\end{array}\\ 0.57& 0.5& \begin{array}{lll}0.40& 0.92& 0.75\end{array}\\ \begin{array}{c}0.60\\ 0.69\\ 0.58\end{array}& \begin{array}{c}0.60\\ 0.08\\ 0.25\end{array}& \begin{array}{lll}0.5& 0.54& 0.26\\ 0.46& 0.5& 0.41\\ 0.74& 0.59& 0.5\end{array}\end{array}\right)\),
\({B}^{\mathrm{7,3}}=\left(\begin{array}{lll}0.5& 0.22& \begin{array}{lll}0.41& 0.47& 0.40\end{array}\\ 0.78& 0.5& \begin{array}{lll}0.48& 0.09& 0.76\end{array}\\ \begin{array}{c}0.59\\ 0.53\\ 0.60\end{array}& \begin{array}{c}0.52\\ 0.91\\ 0.24\end{array}& \begin{array}{lll}0.5& 0.48& 0.37\\ 0.52& 0.5& 0.18\\ 0.63& 0.82& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{8,3}}=\left(\begin{array}{lll}0.5& 0.62& \begin{array}{lll}0.19& 0.46& 0.12\end{array}\\ 0.38& 0.5& \begin{array}{lll}0.43& 0.75& 0.74\end{array}\\ \begin{array}{c}0.81\\ 0.54\\ 0.88\end{array}& \begin{array}{c}0.57\\ 0.25\\ 0.26\end{array}& \begin{array}{lll}0.5& 0.25& 0.02\\ 0.75& 0.5& 0.33\\ 0.98& 0.67& 0.50\end{array}\end{array}\right),\)
\({B}^{\mathrm{11,3}}=\left(\begin{array}{lll}0.5& 0.71& \begin{array}{lll}0.49& 0.41& 0.40\end{array}\\ 0.29& 0.5& \begin{array}{lll}0.32& 0.38& 0.72\end{array}\\ \begin{array}{c}0.51\\ 0.59\\ 0.60\end{array}& \begin{array}{c}0.68\\ 0.62\\ 0.28\end{array}& \begin{array}{lll}0.5& 0.53& 0.39\\ 0.47& 0.5& 0.56\\ 0.61& 0.44& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{12,3}}=\left(\begin{array}{lll}0.5& 0.95& \begin{array}{lll}0.26& 0.44& 0.05\end{array}\\ 0.05& 0.5& \begin{array}{lll}0.49& 0.76& 0.74\end{array}\\ \begin{array}{c}0.74\\ 0.56\\ 0.95\end{array}& \begin{array}{c}0.51\\ 0.24\\ 0.26\end{array}& \begin{array}{lll}0.5& 0.25& 0.89\\ 0.75& 0.5& 0.31\\ 0.11& 0.69& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{17,3}}=\left(\begin{array}{lll}0.5& 0.37& \begin{array}{lll}0.42& 0.38& 0.44\end{array}\\ 0.63& 0.5& \begin{array}{lll}0.33& 0.66& 0.72\end{array}\\ \begin{array}{c}0.58\\ 0.62\\ 0.56\end{array}& \begin{array}{c}0.67\\ 0.34\\ 0.28\end{array}& \begin{array}{lll}0.5& 0.48& 0.13\\ 0.52& 0.5& 0.04\\ 0.87& 0.96& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{18,3}}=\left(\begin{array}{lll}0.5& 0.55& \begin{array}{lll}0.52& 0.53& 0.26\end{array}\\ 0.45& 0.5& \begin{array}{lll}0.50& 0.17& 0.75\end{array}\\ \begin{array}{c}0.48\\ 0.47\\ 0.74\end{array}& \begin{array}{c}0.50\\ 0.83\\ 0.25\end{array}& \begin{array}{lll}0.5& 0.26& 0.26\\ 0.74& 0.5& 0.27\\ 0.74& 0.73& 0.5\end{array}\end{array}\right),\)
\({B}^{\mathrm{19,3}}=\left(\begin{array}{lll}0.5& 0.68& \begin{array}{lll}0.89& 0.49& 0.67\end{array}\\ 0.32& 0.5& \begin{array}{lll}0.47& 0.48& 0.79\end{array}\\ \begin{array}{c}0.11\\ 0.51\\ 0.33\end{array}& \begin{array}{c}0.53\\ 0.52\\ 0.21\end{array}& \begin{array}{lll}0.5& 0.67& 0.43\\ 0.33& 0.5& 0.36\\ 0.57& 0.64& 0.5\end{array}\end{array}\right), \quad {B}^{\mathrm{20,3}}=\left(\begin{array}{lll}0.5& 0.43& \begin{array}{lll}0.59& 0.40& 0.30\end{array}\\ 0.57& 0.5& \begin{array}{lll}0.47& 0.64& 0.77\end{array}\\ \begin{array}{c}0.41\\ 0.50\\ 0.70\end{array}& \begin{array}{c}0.53\\ 0.36\\ 0.23\end{array}& \begin{array}{lll}0.5& 0.95& 0.62\\ 0.05& 0.5& 0.36\\ 0.38& 0.64& 0.5\end{array}\end{array}\right)\).
Based on the historical preference relations, use the k-means clustering technique to classify DMs into the following clusters.
Based on Eq. (15), we can obtain the collective preferences for each cluster.
\({B}^{{G}_{3}}=\left(\begin{array}{lll}0.5& 0.4350& \begin{array}{lll}0.4425& 0.4075& 0.3425\end{array}\\ 0.5650& 0.5& \begin{array}{lll}0.4225& 0.1475& 0.7750\end{array}\\ \begin{array}{c}0.5575\\ 0.5925\\ 0.6575\end{array}& \begin{array}{c}0.5775\\ 0.8525\\ 0.2250\end{array}& \begin{array}{lll}0.5& 0.4125& 0.3750\\ 0.5875& 0.5& 0.2625\\ 0.6250& 0.7375& 0.5\end{array}\end{array}\right)\).
Based on Eq. (17), the similarity matrices are obtained as follows.
\({\text{SM}}_{13}=\left(\begin{array}{lll}-& 0.6990& \begin{array}{lll}0.9395& 0.9505& 0.9095\end{array}\\ 0.6990& -& \begin{array}{lll}0.9125& 0.5835& 0.9950\end{array}\\ \begin{array}{c}0.9395\\ 0.9505\\ 0.9095\end{array}& \begin{array}{c}0.9125\\ 0.5835\\ 0.9950\end{array}& \begin{array}{lll}-& 0.7265& 0.5570\\ 0.7265& -& 0.9585\\ 0.5570& 0.9585& -\end{array}\end{array}\right),\)
From Eqs. (18)–(20), we can obtain the consensus degrees for each alternative.
Therefore, according to Eq. (21) the global consensus level is calculated.
Since \({cl}_{3}>0.85\), it is concluded that the consensus threshold is reached. We can further obtain the collective preference relation according to Eq. (2).
Then, based on Eq. (3) the collective ranking of alternatives is \({x}_{2}\succ {x}_{3}\succ {x}_{5}\succ {x}_{1}\succ {x}_{4}\).
5 Simulation and Comparison Analysis
In this section, the simulation experiments and comparison analysis are designed to show the validity of the CMHP-LCRP framework.
5.1 Simulation Experiment
In the simulation experiment, at first the initial preference relations of DMs are randomly generated and further transformed into the historical preference format. Based on these historical preference data, we use the k-means clustering technique to classify DMs into several clusters. Further, the consensus level is computed. If the consensus level fails to reach the consensus threshold, then it comes to the local feedback adjustment stage. According to Eqs. (22), (23), (26) and (28), the alternatives, the pairs of alternatives, the clusters and the DMs where the preferences need to be adjusted are identified. Next, the identified DMs are supposed to adjust their preference over the identified positions based on Eqs. (29)–(31) and we obtain the updated preference relations of DMs. In the next round, the updated preference relations, together with all the previous preference relations, are transformed into the historical preference format again and it comes to the next clustering process. All the processes loop until the pre-defined consensus threshold is reached or it comes to the maximum number of rounds allowed.
The detailed simulation method for the CMHP-LCRP framework (\({\text{SM}}\)) is given below.
Input: \(m,n, Q, \beta ,\overline{cl }\) and \({z}_{max}\).
Output: \(z\) and \(s\).
Step 1: Let \(z=1\), initialize DMs' preference relations and weights. We randomly generate \(m\) \(n\times n\) preference relations \({B}^{k}={\left[{b}_{ij}^{k}\right]}_{n\times n}\left(k=\mathrm{1,2},\dots ,m\right)\), and \({B}^{k,z}={B}^{k}\). The weights of DMs are supposed to be the same, i.e., \({w}_{k}=1/m(k=\mathrm{1,2},\dots ,m)\).
Step 2: Gather the individuals' preference relations in each round \(\left\{{B}^{k,z},{B}^{k,z-1},\dots ,{B}^{k,1}\right\}\left(k=\mathrm{1,2},\dots ,m\right)\) and transform them into the historical preference relations \({H}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\) according to Eqs. (8) and (9).
Step 3: Use the k-means clustering technique to classify DMs into \(Q\) clusters \(\left\{{G}_{1},{G}_{2},\dots ,{G}_{Q}\right\}\) based on \({H}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\).
Step 4: Compute the global consensus level among DMs \({cl}_{z}\) according to Eq. (21). If \({cl}_{z}\ge \overline{cl }\) or \(z\ge {z}_{\mathrm{max}}\), go to step 7; otherwise continue with the next step.
Step 5: According to the identification rules described in Sect. 4.2.2, the alternatives, the pairs of alternatives, the clusters and the DMs where the preferences need to be adjusted are identified. The identified set of DMs over the identified positions is denoted as \({E}_{ij}^{-}\).
Step 6: Feedback adjustment. For the other DMs except those in \({E}_{ij}^{-}\), the preferences over the pair of alternatives \(\left({x}_{i},{x}_{j}\right)\) keep unchanged in the next round. For the DM \({e}_{k}\) in \({E}_{ij}^{-}\), use the following rule to modify the preferences.
where the value of \(\tau\) is uniformly randomly generated from the interval \(\left[0, 1\right]\) and it guarantees \({b}_{ij}^{k,z+1}\in [min({b}_{ij}^{k,z},{b}_{ij}^{{G}_{{s}^{+}},z}),max({b}_{ij}^{k,z},{b}_{ij}^{{G}_{{s}^{+}},z})]\). The value of \(\varphi\) is uniformly randomly generated from the interval \(\left[-1, 1\right]\), and it guarantees the preference difference between \({b}_{ij}^{k,z+1}\) and \({b}_{ij}^{{G}_{{s}^{+}},z}\) is no more than the threshold \(\beta\). Let \(z=z+1\), and go to step 2.
Step 7: Output. If \({cl}_{z}\ge \overline{cl }\), \(s=1\); otherwise, \(s=0\). Output \(z\) and \(s\).
Note. In the simulation method, (1) \(m\), \(n\) and \(Q\) represent the number of DMs, alternatives and clusters respectively; \(\overline{cl }\) and \({z}_{max}\) represent the consensus threshold and the maximum number of rounds allowed respectively. (2) The parameter \(\beta\) denotes the coefficient to guide direction for preference adjustment. The smaller the value of \(\beta\), the larger the degree to adjust the preferences of DMs. (3) The output parameter \(z\) denotes the iteration number to reach the consensus threshold. The smaller the value of \(z\), the faster the speed to reach the consensus threshold. (4) The parameter \(s\) reflects whether the consensus can be achieved or not. If the consensus is achieved within the maximum number of rounds allowed, \(s=1\); otherwise, \(s=0\).
Let \({z}_{max}=5\) and \(\overline{cl }=0.85\), and different input parameters \(m, \; n\), \(Q, \; \beta\) are set for the simulation experiment. To be specific, we run the simulations method (\(\mathrm{SM}\)) 1000 times to obtain \({\text{AZ}}\) and \({\text{AS}}\), which represent the average values of \(z\) and \(s\) respectively. The indicator \({\text{AZ}}\) reflects the average iteration number to reach the consensus threshold, and that of \({\text{AS}}\) reflects the success ratio of achieving a consensus. Under different input parameters, the results are listed in Table 1.
From Table 1, the following observations can be obtained.
-
1.
In general, it takes an average of 2–3 rounds to reach the consensus threshold, and it has high success ratios of achieving a consensus (close to 1) for most cases in the CMHP-LCRP framework.
-
2.
With increasing \(m\) and \(n\) values, the value \({\text{AZ}}\) decreases and that of \({\text{AS}}\) increases. The finding implies that more DMs or alternatives involved will increase the speed to reach the consensus threshold and will improve the success ratio of achieving a consensus in the CMHP-LCRP framework. With increasing \(Q\) values, on the whole the value \({\text{AZ}}\) shows increasing trend while that of \({\text{AS}}\) shows decreasing trend. The finding implies that a relatively small number of clusters may increase the speed to reach the consensus threshold and shows higher success ratio of achieving a consensus.
-
3.
With increasing \(\beta\) values, the value \({\text{AZ}}\) increases and that of \({\text{AS}}\) decreases. In the CMHP-LCRP framework the smaller the value of \(\beta\), the more the DMs that are supposed to adjust their preferences. Therefore, it is faster to reach the consensus threshold, and the success ratio of achieving a consensus is higher by comparison.
5.2 Comparison Analysis
As for LSGDM problem, clustering is a widely used tool. In this paper we propose a CMHP-LCRP framework in which all the historical preferences of DMs are employed for clustering. However, the traditional LCRP models are based on a clustering method using just the latest round of preference information of DMs, which may fail to fully reflect the change of DMs' preferences. In order to show the validity of the CMHP-LCRP framework, we aim to compare the CMHP-LCRP framework with the traditional LCRP framework.
The simulation method for the traditional LCRP framework (\({\text{SM}}^{\prime}\)) is given below. Considering the Input, Output, Step 1 and Steps 3–7 are the same as \({\text{SM}}\) for the CMHP-LCRP framework, we omit them. We just need to replace Step 2 with Step 2' for \({\text{SM}}^{\prime}\).
Step 2': Transform \({B}^{k,z}\left(k=\mathrm{1,2},\dots ,m\right)\) into a vector that consists of its upper triangular elements based on Eqs. (6) and (7).
Considering that input parameters may have influence on the simulation results, three groups of comparisons are conducted by using different input parameters: (1) different input parameters \(m\) and \(n\); (2) different input parameters \(m\) and \(Q\); (3) different input parameters \(m\) and \(\beta\).
For the first comparison analysis, let \({z}_{max}=5\), \(\overline{cl }=0.85\), \(Q=4\) and \(\beta =0.2\), different input parameters \(m\) and \(n\) are set and we run the simulations methods \({\text{SM}}\) and \({\text{SM}}^{\prime}\) 1000 times to obtain values \({\text{AZ}}\) and \({\text{AS}}\) using the k-means clustering technique. The results are described in Fig. 2.

\({\text{AZ}}\) and \({\text{AS}}\) under different parameters \(m\) and \(n\)
For the second comparison analysis, let \({z}_{max}=5\), \(\overline{cl }=0.85\), \(n=5\) and \(\beta =0.2\), different input parameters \(m\) and \(Q\) are set and we run the simulations methods \({\text{SM}}\) and \({\text{SM}}^{\prime}\) 1000 times to obtain values \({\text{AZ}}\) and \({\text{AS}}\) using the k-means clustering technique. The results are described in Fig. 3.

\({\text{AZ}}\) and \({\text{AS}}\) under different parameters \(m\) and \(Q\)
For the third comparison analysis, let \({z}_{max}=5\), \(\overline{cl }=0.85\), \(n=5\) and \(Q=4\), different input parameters \(m\) and \(\beta\) are set and we run the simulations methods \({\text{SM}}\) and \({\text{SM}}^{\prime}\) 1000 times to obtain values \({\text{AZ}}\) and \({\text{AS}}\) using the k-means clustering technique. The results are described in Fig. 4.

\({\text{AZ}}\) and \({\text{AS}}\) under different parameters \(m\) and \(\beta\)
From Figs. 2, 3 and 4, the following observations can be obtained.
-
1.
No matter how the input parameters change, the values \({\text{AZ}}\) in the proposed CMHP-LCRP framework are smaller than those in the traditional LCRP framework. It indicates the proposed CMHP-LCRP framework can increase the speed to reach the consensus threshold. Meanwhile, the values \({\text{AS}}\) in the proposed CMHP-LCRP framework are larger than those in the traditional LCRP framework. It indicates the success ratio of achieving a consensus is higher in the CMHP-LCRP framework by comparison.
-
2.
When setting different input parameters, the values of \({\text{AZ}}\) and \({\text{AS}}\) are different. As for the preference adjustment parameter \(\beta\), the smaller the value of \(\beta\), the more the DMs that need to adjust their preferences and the DMs' updated preferences are closer to each other. Therefore, it is faster to reach the consensus threshold and the success ratio of achieving a consensus is higher. With increasing \(m\) and \(n\) values, the more the DMs and alternatives involved, so the speed to reach the consensus threshold is faster and the success ratio of achieving a consensus is higher. As for the parameter \(Q\), on the whole a relatively small number of clusters may increase the speed to reach the consensus threshold and improve the success ratio of achieving a consensus. It may lie in that fewer clusters result in more stable clustering results and the direction in which DMs adjust the preference is clearer, and it may result in smoother LCPR.
6 Conclusion
Clustering is a widely used tool to deal with LSGDM problems. In traditional LCRP framework, just the DMs' preference information in the latest decision round is used for clustering. This paper explores a consensus model using a novel clustering method that takes the historical preference information of DMs in all decision rounds into consideration. By comparison, the historical data can more fully reflect the change of DMs' preferences, thus better guiding the clustering process. To show the validity of the proposed CMHP-LCRP framework, we further compare the CMHP-LCRP framework with the traditional LCRP framework under different input parameters. Compared with the traditional LCRP framework, it is faster to reach the consensus threshold and the success ratio of achieving a consensus is higher for our CMHP-LCRP framework no matter how the input parameters change. The result shows that the CMHP-LCRP framework outperforms the traditional LCRP framework.
Meanwhile, three research directions are interesting for future studies. (1) In this paper, we apply the additive preference relations for analysis. However, there are some other preference representation structures, such as multiplicative preference relations and linguistic preference relations. It is of significance to explore other preference representation structures with historical data to further support the proposed model in this paper. (2) Some DMs may adopt non-cooperative behaviors in the LCRP to achieve their own goal or interests. For instance, some DMs may provide dishonest opinions or refuse to change their evaluations for the sake of their own interests [28, 29]. Therefore, it will be very interesting to explore a more flexible consensus model by taking the non-cooperative behaviors into consideration and build the corresponding mechanism to detect and manage non-cooperative behaviors in the CMHP-LCRP framework in future. (3) The social network among DMs plays an important role in the aggregation process of opinions and the social network analysis has become a hot topic in GDM research [3, 29, 32]. Therefore, it will be interesting to extend the proposed model with the consideration of the social network to provide decision support for practical LCRP problems.
Availability of Data and Materials
The datasets generated during the current study are available from the corresponding author on reasonable request.
Abbreviations
- LSGDM:
-
Large-scale group decision-making
- LCRP:
-
Large-scale consensus-reaching process
- DMs:
-
Decision makers
- GDM:
-
Group decision-making
- CRP:
-
Consensus-reaching process
- CMHP:
-
Clustering method using the historical preferences data
- CMHP-LCRP:
-
Large-scale consensus-reaching process framework based on the clustering method using the historical preferences data of decision makers
- WA:
-
Weighted average
- SM:
-
Simulation method
References
Hochbaum, D.S., Levin, A.: Methodologies and algorithms for group-rankings decision. Manag. Sci. 52(9), 1394–1408 (2006). https://doi.org/10.1287/mnsc.1060.0540
Kacprzyk, J.: Group decision making with a fuzzy linguistic majority. Fuzzy Sets Syst. 18(2), 105–118 (1986). https://doi.org/10.1016/0165-0114(86)90014-X
Wu, J., Chang, J.L., Cao, Q.W., Liang, C.Y.: A trust propagation and collaborative filtering based method for incomplete information in social network group decision making with type-2 linguistic trust. Comput. Ind. Eng. 127, 853–864 (2019). https://doi.org/10.1016/j.cie.2018.11.020
Cao, M.S., Wu, J., Chiclana, F., Herrera-Viedma, E.: A bidirectional feedback mechanism for balancing group consensus and individual harmony in group decision making. Inf. Fusion 76, 133–144 (2021). https://doi.org/10.1016/j.inffus.2021.05.012
Xu, W.J., Chen, X., Dong, Y.C., Chiclana, F.: Impact of decision rules and non-cooperative behaviors on minimum consensus cost in group decision making. Group Decis. Negot. 30(6), 1239–1260 (2021). https://doi.org/10.1007/s10726-020-09653-7
Herrera-Viedma, E., Cabrerizo, F.J., Kacprzyk, J., Pedrycz, W.: A review of soft consensus models in a fuzzy environment. Inf. Fusion 17, 4–13 (2014). https://doi.org/10.1016/j.inffus.2013.04.002
Palomares, I., Estrella, F.J., Martínez, L., Herrera, F.: Consensus under a fuzzy context: taxonomy, analysis framework AFRYCA and experimental case of study. Inf. Fusion. 20, 252–271 (2014). https://doi.org/10.1016/j.inffus.2014.03.002
Palomares, I., Martínez, L.: A semi-supervised multiagent system model to support consensus-reaching processes. IEEE Trans. Fuzzy Syst. 22(4), 762–777 (2014). https://doi.org/10.1109/TFUZZ.2013.2272588
Dong, Y.C., Zhang, H.J., Herrera-Viedma, E.: Integrating experts’ weights generated dynamically into the consensus reaching process and its applications in managing non-cooperative behaviors. Decis. Support Syst. 84, 1–15 (2016). https://doi.org/10.1016/j.dss.2016.01.002
Kacprzyk, J., Zadrożny, S., Raś, Z.W.: How to support consensus reaching using action rules: a novel approach. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 18(4), 451–470 (2010). https://doi.org/10.1142/S0218488510006647
Dong, Y.C., Li, C.C., Xu, Y.F., Gu, X.: Consensus-based group decision making under multi-granular unbalanced 2-tuple linguistic preference relations. Group Decis. Negot. 24(2), 217–242 (2015). https://doi.org/10.1007/s10726-014-9387-5
Zhang, G.Q., Dong, Y.C., Xu, Y.F.: Consistency and consensus measures for linguistic preference relations based on distribution assessments. Inf. Fusion 17, 46–55 (2014). https://doi.org/10.1016/j.inffus.2012.01.006
Xu, X.H., Du, Z.J., Chen, X.H.: Consensus model for multi-criteria large-group emergency decision making considering non-cooperative behaviors and minority opinions. Decis. Support Syst. 79, 150–160 (2015). https://doi.org/10.1016/j.dss.2015.08.009
Pérez, I.J., Cabrerizo, F.J., Herrera-Viedma, E.: A mobile decision support system for dynamic group decision-making problems. IEEE Trans. Syst. Man Cybern. Syst. 40(6), 1244–1256 (2010). https://doi.org/10.1109/TSMCA.2010.2046732
Pérez, I.J., Cabrerizo, F.J., Alonso, S., Herrera-Viedma, E.: A new consensus model for group decision making problems with non-homogeneous experts. IEEE Trans. Syst. Man Cybern. Syst. 44(4), 494–498 (2014). https://doi.org/10.1109/TSMC.2013.2259155
Wu, J., Chiclana, F.: A social network analysis trust-consensus based approach to group decision-making problems with interval-valued fuzzy reciprocal preference relations. Knowl. Based Syst. 59, 97–107 (2014). https://doi.org/10.1016/j.knosys.2014.01.017
Li, C.C., Dong, Y.C., Herrera, F.: A consensus model for large-scale linguistic group decision making with a feedback recommendation based on clustered personalized individual semantics and opposing consensus groups. IEEE Trans. Fuzzy Syst. 27(2), 221–233 (2019). https://doi.org/10.1109/TFUZZ.2018.2857720
Dong, Y.C., Zhao, S.H., Zhang, H.J., Chiclana, F., Herrera-Viedma, E.: A self-management mechanism for noncooperative behaviors in large-scale group consensus reaching processes. IEEE Trans. Fuzzy Syst. 26(6), 3276–3288 (2018). https://doi.org/10.1109/TFUZZ.2018.2818078
Gong, Z.W., Zhang, N., Li, K.W., Martínez, L., Zhao, W.: Consensus decision models for preferential voting with abstentions. Comput. Ind. Eng. 115, 670–682 (2018). https://doi.org/10.1016/j.cie.2017.12.007
Wu, Z.B., Xu, J.P.: A consensus model for large-scale group decision making with hesitant fuzzy information and changeable clusters. Inf. Fusion. 41, 217–231 (2018). https://doi.org/10.1016/j.inffus.2017.09.011
Dong, Y.C., Liu, Y.T., Liang, H.M., Chiclana, F., Herrera-Viedma, E.: Strategic weight manipulation in multiple attribute decision making. Omega 75, 154–164 (2018). https://doi.org/10.1016/j.omega.2017.02.008
Herrera-Viedma, E., Martínez, L., Mata, F., Chiclana, F.: A consensus support system model for group decision making problems with multigranular linguistic preference relations. IEEE Trans. Fuzzy Syst. 13(5), 644–658 (2005). https://doi.org/10.1109/TFUZZ.2005.856561
Wang, Y.X., Dong, Y.C., Zhang, H.J., Gao, Y.: Personalized individual semantics based approach to MAGDM with the linguistic preference information on alternatives. Int. J. Comput. Intell. Syst. 11(1), 496–513 (2018). https://doi.org/10.2991/ijcis.11.1.37
Li, C.C., Gao, Y., Dong, Y.C.: Managing ignorance elements and personalized individual semantics under incomplete linguistic distribution context in group decision making. Group Decis. Negot. 30(1), 97–118 (2021). https://doi.org/10.1007/s10726-020-09708-9
Zhang, B.W., Dong, Y.C., Herrera-Viedma, E.: Group decision making with heterogeneous preference structures: an automatic mechanism to support consensus reaching. Group Decis. Negot. 28(3), 585–617 (2019). https://doi.org/10.1007/s10726-018-09609-y
Liu, Y.T., Zhang, H.J., Wu, Y.Z., Dong, Y.C.: Ranking range based approach to MADM under incomplete context and its application in venture investment evaluation. Technol. Econ. Dev. Econ. 25(5), 877–899 (2019). https://doi.org/10.3846/tede.2019.10296
Quesada, F.J., Palomares, I., Martínez, L.: Managing experts behavior in large-scale consensus reaching processes with uninorm aggregation operators. Appl. Soft. Comput. 35, 873–887 (2015). https://doi.org/10.1016/j.asoc.2015.02.040
Palomares, I., Martínez, L., Herrera, F.: A consensus model to detect and manage noncooperative behaviors in large-scale group decision making. IEEE Trans. Fuzzy Syst. 22(3), 516–530 (2014). https://doi.org/10.1109/TFUZZ.2013.2262769
Gao, Y., Zhang, Z.: Consensus reaching with non-cooperative behavior management for personalized individual semantics-based social network group decision making. J. Oper. Res. Soc. (2021). https://doi.org/10.1080/01605682.2021.1997654.(in press)
Zhang, Z., Li, Z.L.: Personalized individual semantics-based consistency control and consensus reaching in linguistic group decision making. IEEE Trans. Syst. Man Cybern. Syst. (2021). https://doi.org/10.1109/TSMC.2021.3129510. (in press)
Zhang, Z., Yu, W.Y., Martínez, L., Gao, Y.: Managing multigranular unbalanced hesitant fuzzy linguistic information in multiattribute large-scale group decision making: A linguistic distribution-based approach. IEEE Trans. Fuzzy Syst. 28(11), 2875–2889 (2020). https://doi.org/10.1109/TFUZZ.2019.2949758
Liao, H.C., Li, X.F., Tang, M.: How to process local and global consensus? A large-scale group decision making model based on social network analysis with probabilistic linguistic information. Inf. Sci. 579, 368–387 (2021). https://doi.org/10.1016/j.ins.2021.08.014
Ren, R.X., Tang, M., Liao, H.C.: Managing minority opinions in micro-grid planning by a social network analysis-based large scale group decision making method with hesitant fuzzy linguistic information. Knowl. Based Syst. 189, 105060 (2020). https://doi.org/10.1016/j.knosys.2019.105060
Labella, A., Liu, Y., Rodríguez, R.M., Martínez, L.: Analyzing the performance of classical consensus models in large scale group decision making: a comparative study. Appl. Soft. Comput. 67, 677–690 (2018). https://doi.org/10.1016/j.asoc.2017.05.045
Liang, M.S., Mi, J.S., Feng, T., Xie, B.: Multi-adjoint based group decision-making under an intuitionistic fuzzy information system. Int. J. Comput. Intell. Syst. 12(1), 172–182 (2019). https://doi.org/10.2991/ijcis.2018.25905190
Dong, Y.C., Zha, Q.B., Zhang, H.J., Herrera, F.: Consensus reaching and strategic manipulation in group decision making with trust relationships. IEEE Trans. Syst. Man Cybern. Syst. 51(10), 6304–6318 (2021). https://doi.org/10.1109/TSMC.2019.2961752
Liu, Y., Fan, Z.P., Zhang, X.: A method for large group decision making based on evaluation information provided by participators from multiple groups. Inf. Fusion 29, 132–141 (2016). https://doi.org/10.1016/j.inffus.2015.08.002
Wu, T., Liu, X.W.: An interval type-2 fuzzy clustering solution for large-scale multiple-criteria group decision-making problems. Knowl. Based Syst. 114, 118–127 (2016). https://doi.org/10.1016/j.knosys.2016.10.004
Roselló, L., Sánchez, M., Agell, N., Prats, F., Mazaira, F.A.: Using consensus and distances between generalized multi-attribute linguistic assessments for group decision-making. Inf. Fusion 17, 83–92 (2014). https://doi.org/10.1016/j.inffus.2011.09.001
Tanino, T.: On group decision making under fuzzy preferences. In: Kacprzyk, J., Fedrizzi, M. (eds.) Multiperson Decision Making Using Fuzzy Sets and Possibility Theory, pp. 172–185. Kluwer Academic Publishers, Dordrecht (1990)
Seo, F., Sakawa, M.: Fuzzy multiattribute utility analysis for collective choice. IEEE Trans. Syst. Man Cybern. 15(1), 45–53 (1985). https://doi.org/10.1109/TSMC.1985.6313393
Saaty, T.L.: The analytic hierarchy process. McGraw-Hill, New York (1980)
Herrera-Viedma, E., Chiclana, F., Herrera, F., Alonso, S.: Group decision-making model with incomplete fuzzy preference relations based on additive consistency. IEEE Trans. Syst. Man Cybern. 37(1), 176–189 (2007). https://doi.org/10.1109/TSMCB.2006.875872
Orlovsky, S.A.: Decision-making with a fuzzy preference relation. Fuzzy Sets Syst. 1(3), 155–167 (1978). https://doi.org/10.1016/0165-0114(78)90001-5
Zha, Q.B., Dong, Y.C., Zhang, H.J., Chiclana, F., Herrera-Viedma, E.: A personalized feedback mechanism based on bounded confidence learning to support consensus reaching in group decision making. IEEE Trans. Syst. Man Cybern. Syst. 51(6), 3900–3910 (2021). https://doi.org/10.1109/TSMC.2019.2945922
Pérez-Asurmendi, P., Chiclana, F.: Linguistic majorities with difference in support. Appl. Soft. Comput. 18, 196–208 (2014). https://doi.org/10.1016/j.asoc.2014.01.010
Li, Y.H., Cheng, Y.L., Mou, Q., Xian, S.D.: Novel cross-entropy based on multi-attribute group decision-making with unknown experts’ weights under interval-valued intuitionistic fuzzy environment. Int. J. Comput. Intell. Syst. 13(1), 1295–1304 (2020). https://doi.org/10.2991/ijcis.d.200817.001
Li, C.C., Dong, Y.C., Pedrycz, W., Herrera, F.: Integrating continual personalized-individual-semantics learning in consensus reaching in linguistic group decision making. IEEE Trans. Syst. Man Cybern. Syst. 52(3), 1525–1536 (2022). https://doi.org/10.1109/TSMC.2020.3031086
Zhao, S.H., Dong, Y.C., He, Y.: The reliability analysis of rating systems in decision making: when scale meets multi-attribute additive value model. Decis. Support Syst. 138, 113384 (2020). https://doi.org/10.1016/j.dss.2020.113384
Xu, Y.J., Li, K.W., Wang, H.M.: Distance-based consensus models for fuzzy and multiplicative preference relations. Inf. Sci. 253, 56–73 (2013). https://doi.org/10.1016/j.ins.2013.08.029
Yager, R.R.: On ordered weighted averaging aggregation operators in multicriteria decision-making. IEEE Trans. Syst. Man Cybern. 18(1), 183–190 (1988). https://doi.org/10.1109/21.87068
Yager, R.R., Filev, D.P.: Induced ordered weighted averaging operators. IEEE Trans. Syst. Man Cybern. 29(2), 141–150 (1999). https://doi.org/10.1109/3477.752789
Xu, Y.J., Wen, X.W., Zhang, W.C.: A two-stage consensus method for large-scale multi-attribute group decision making with an application to earthquake shelter selection. Comput. Ind. Eng. 116, 113–129 (2018). https://doi.org/10.1016/j.cie.2017.11.025
Likas, A., Vlassis, N., Verbeek, J.J.: The global k-means clustering algorithm. Pattern Recognit. 36(2), 451–461 (2003). https://doi.org/10.1016/S0031-3203(02)00060-2
Liu, X., Xu, Y.J., Herrera, F.: Consensus model for large-scale group decision making based on fuzzy preference relation with self-confidence: Detecting and managing overconfidence behaviors. Inf. Fusion 52, 245–256 (2019). https://doi.org/10.1016/j.inffus.2019.03.001
Ding, R.X., Palomares, I., Wang, X.Q., Yang, G.R., Liu, B.S., Dong, Y.C., Herrera-Viedma, E., Herrera, F.: Large-scale decision-making: characterization, taxonomy, challenges and future directions from an artificial intelligence and applications perspective. Inf. Fusion 59, 84–102 (2020). https://doi.org/10.1016/j.inffus.2020.01.006
Funding
This work was supported by the National Natural Science Foundation of China (Grant number [71871149]); and the Guangdong Province Universities and Colleges Pearl River Scholar Funded Scheme.
Author information
Authors and Affiliations
Contributions
Conceptualization, methodology, writing—original draft, software and data curation were performed by Kai Xiong. Conceptualization, methodology, writing—review and editing, funding acquisition and supervision were performed by Yucheng Dong. Conceptualization, methodology and writing—review and editing were performed by Sihai Zhao.
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no competing interests to declare that are relevant to the content of this article.
Ethics Approval and Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiong, K., Dong, Y. & Zhao, S. A Clustering Method with Historical Data to Support Large-Scale Consensus-Reaching Process in Group Decision-Making. Int J Comput Intell Syst 15, 17 (2022). https://doi.org/10.1007/s44196-022-00072-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-022-00072-x