
Abstract
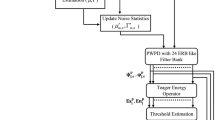
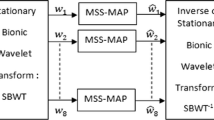
It has been shown in the literature that the perceptual wavelet packet decomposition (PWPD) and the Teager energy operator (TEO) are useful for various speech processing systems and speech enhancement applications, respectively. By the use of the PWPD and the TEO, this paper presents an improved wavelet-based speech enhancement method. The main advantage of the proposed method is that the over thresholding of speech segments which is usually occurred in conventional wavelet-based speech enhancement schemes can be avoided. As a consequence, the enhanced speech quality of the proposed method can be increased substantially from those of conventional approaches. In addition, the proposed method does not require a complicated estimation of the noise level or any knowledge of the SNR. Using speech signals corrupted by additive and real noises, experimental results demonstrate that the speech enhancement method presented in this paper is capable of outperforming conventional noise cancellation schemes.
Similar content being viewed by others

References
B.H. Juang, ‘Recent Developments in Speech Recognition Under Adverse Conditions,’ in Proceedings of Int. Conf. Spoken Language Process '90, 1990, pp. 1113-1116.
J.H. Chen and A. Gersho, ‘Adaptive Postfiltering for Quality Enhancement of Coded Speech,’ IEEE Trans. Speech and Audio Processing, vol. 3, 1995, pp. 57-71.
R. Le Bouquin, ‘Enhancement of Noisy Speech Signals: Application To Mobile Radio Communications,’ Speech Communication, vol. 18, no. 1, 1996, pp. 3-19.
Y. Ephraim and D. Malah, ‘Speech Enhancement Using a Minimum Mean Square Error Short Time Spectral Amplitude Estimator,’ IEEE Trans. Acoust. Speech Signal Processing ASSP-32, 1984, pp. 1109-1121.
J. Meyer and K.U. Simmer, ‘Multi-Channel Speech Enhancement in a Car Environment Using Wiener Filtering and Spectral Subtraction,’ in Proceedings of IEEE Int. Conf. Acoustics, Speech, and Signal Processing '97, vol. 2, 1997, pp. 1167-1170.
B. Yegnanarayana, C. Avendano, H. Hermansky, and P. Satyanarayana Murthy, ‘Speech Enhancement Using Linear Prediction Residual,’ Speech Communication, vol. 28, 1999, pp. 25-42.
J.W. Seok and K.S. Bae, ‘Speech Enhancement with Reduction of Noise Components in The Wavelet Domain,’ in Proceedings of IEEE Int. Conf. Acoustics, Speech, and Signal Processing '97, vol. 2, 1997, pp. 1323-1326.
I. Pinter, ‘Perceptual Wavelet-Representation of Speech Signals and its Application to Speech Enhancement,’ Computer Speech and Language, vol. 10, no. 1, 1996, pp. 1-22.
B. Carneno and A. Drygajlo, ‘Perceptual Speech Coding and Enhancement Using Frame-Synchronized Fast Wavelet Packet Transform Algorithms,’ IEEE Tans. Signal Processing, vol. 47, no. 6, 1999, pp. 1622-1635.
M. Bahoura and J. Rouat, ‘Wavelet Speech Enhancement Based on the Teager Energy Operator,’ IEEE Signal Processing Lett., vol. 8, 2001, pp. 10-12.
S.G. Chang, B. Yu, and M. Vetterli, ‘Adaptive Wavelet Thresholding for Image Denoising and Compression,’ IEEE Trans. Image Processing, vol. 9, 2000, pp. 1532-1546.
D.L. Donoho, ‘De-Noising by Soft-Thresholding,’ IEEE Trans. Inform. Theory, vol. 41, 1995, pp. 613-627.
D.L. Donoho and I.M. Johnstone, ‘Ideal Spatial Adaptation by Wavelet Shrinkage,’ Biometrika, vol. 81, 1994, pp. 425-455.
D.L. Donoho, ‘Unconditional Bases are Optimal Bases for Data Compression and Statistical Estimation,’ Applied and Computational Harmonic Analysis, vol. 1, 1994, pp. 100-115.
I.M. Johnstone and B.W. Silverman, ‘Wavelet Threshold Estimators for Data with Correlated Noise,’ J. Roy. Statist. Soc. B, vol. 59, 1997, pp. 319-351.
O. Farooq and S. Datta, ‘Mel Filter-Like Admissible Wavelet Packet Structure for Speech Recognition,’ IEEE Signal Processing Letters, vol. 8, no 7, 2001, pp. 196-198.
R. Sarikaya, B. Pellom, and J.H.L. Hansen, ‘Wavelet Packet Transform Features with Application to Speaker Identification,’ in NORSIG-98, IEEE Nordic Signal Processing Symposium, Vigso, Denmark, 1998, pp. 81-84.
P. Srinivasan and L.H. Jamieson, ‘High Quality Audio Compression Using an Adaptive Wavelet Decomposition and Psychoacoustic Modeling,’ IEEE Trans. Signal Processing, vol. 46, no. 4, 1998, pp. 1085-1093.
J.F. Kaiser, ‘On a Simple Algorithm to Calculate the ‘Energy’ of a Signal,’ in Proceedings of IEEE Int. Conf. Acoustics, Speech, and Signal Processing '90, 1990, pp. 381-384.
J.F. Kaiser, ‘Some Useful Properties of Teager's Energy Operator,’ in Proceedings of IEEE Int. Conf. Acoustics, Speech, and Signal Processing '93, 1993, pp. 149-152.
F. Jabloun, A.E. Cetin, and E. Erzin, ‘Teager Energy Based Feature Parameters for Speech Recognition in Car Noise,’ IEEE Signal Processing Lett., vol. 6, 1999, pp. 259-261.
G. Zhou, J.H.L. Hansen, and J.F. Kaiser, ‘Nonlinear Feature Based Classification of Speech Under Stress,’ IEEE Trans. Speech and Audio Processing, vol. 9, 2001, pp. 201-216.
C.S. Burrus, R.A. Gopinath, and H. Guo, Introduction to Wavelets and Wavelet Transforms, A Primer, Upper Saddle River, Nj: Prentice-Hall, 1998.
I. Daubechies, Ten Lectures on Wavelets, CBMS, SIAM Publ., 1992.
S. Mallat, ‘Multifrequency Channel Decomposition of Images and Wavelet Model,’ IEEE Trans. Acoustic, Speech and Signal Processing, vol. 37, 1989, pp. 2091-2110.
O. Ghitza, ‘Auditory Model and Human Performance in Tasks Related to Speech Coding and Speech Recognition,’ IEEE Trans. Speech and Audio Processing, vol. 2, 1994, pp. 115-132.
L. Rabiner and B.H. Juang, Fundamental of Speech Recognition, Upper Saddle River, NJ: Prentice-Hall, 1993.
E. Zwicker and E. Terhardt, ‘Analytical Expressions for Critical-Band Rate and Critical Bandwidth as a Function of Frequency,’ JASA, vol. 68, 1980, pp. 1523-1525.
See http://www.icp.inpg.fr/ELRA/aurora2.html.
Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Chen, SH., Wang, JF. Speech Enhancement Using Perceptual Wavelet Packet Decomposition and Teager Energy Operator. The Journal of VLSI Signal Processing-Systems for Signal, Image, and Video Technology 36, 125–139 (2004). https://doi.org/10.1023/B:VLSI.0000015092.19005.62
Published:
Issue Date:
DOI: https://doi.org/10.1023/B:VLSI.0000015092.19005.62