
Abstract
True-lift modeling, also known as uplift modeling, combines predictive modeling and experimental method to enable marketers to identify the characteristics of ‘true’ treatment responders separately from the characteristics of ‘baseline’ or control responders (that is, those who would have responded anyway). By concentrating truly ‘persuadable’ treatment targets in the top deciles, true-lift models achieve the same (or more) amount of response with fewer treatments (and lower treatment costs). The identified characteristics of the ‘persuadable’ population can then guide the hypotheses of future experiments and pinpoint the most responsive recipients for the treatment in future. This article explains the concept of true-lift modeling in detail, reviews existing methods, contrasts with the traditional approach, proposes new methods that can be implemented with most standard software, and recommends metrics for model assessment and comparison in true-lift modeling. Several new and existing methods are applied to three data sets from the financial services, online merchandise and retail industries. Built on the findings from our study and prior experience, we recommend some guidelines on usage of true-lift modeling methods.














Similar content being viewed by others

Notes
For simplicity, this article defines response as a binary action (responded versus did not respond); continuous responses (such as $ amount purchased) are not addressed here, although some of the methods discussed (A1 and A2) can be easily applied to continuous response data.
For simplicity of illustration, the cost of the treatment is assumed to be negligible compared with the benefit of any positive response, so a campaign with statistically significant lift above 0 per cent is considered a success. In practice, a campaign’s lift usually needs to be above a certain threshold to pay for the campaign before generating positive net profit. Alternatively, the lift in response can be translated to lift in profit for target selection.
Standard stepwise regression can be used with the main and interaction effects. Pre-modeling variable selection procedures can also be used in practice. In addition to logistic regression, the same estimation process can also be used along with other supervised learning methods such as decision tree, naïve Bayes and neural network, as mentioned in Lo (2012).
For the three data sets in this article, a gradient-boosted decision tree is applied for data set 1 and a multinomial logistic regression is used for data sets 2 and 3.
Lai (2006) created a binary classification for TR+CN versus TN+CR. Instead of aggregating outcomes, our approach for B1 predicts all four outcomes using a multi-class model before aggregating because the characteristics driving each outcome can be different, resulting in a potential benefit over a binary approach.
Although the data has both men’s and women’s merchandise in the campaign, only the data for promoting women’s merchandise was used for analysis as the situation for handling multiple treatments is beyond the scope of this article. Details of the data can be found at Kevin Hillstrom’s site at http://blog.minethatdata.com/2008/03/minethatdata-e-mail-analytics-and-data.html
Profit is defined as sales revenue – product cost – coupon cost. A binary response variable was created as the response variable using whether or not Profit>c (a threshold), where c was chosen such that 15 per cent of the data met the threshold.
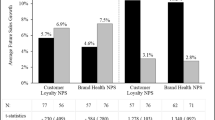
The treatment and control response rates cannot be reported for data sets 1 and 3 since they are considered proprietary corporate information. For data set 2, the response rates for treatment and control are 15.1 and 10.65 per cent, respectively.
Our experience to-date with the Gini repeatability index, that is, R 2 measure of stability, suggests that values in the range of 0.2–0.4 are among the best we have seen in real data. An R 2 target value of 0.7 or above may be too much to hope for.
References
Brand, J.E. and Xie, Y. (2010) Who benefits most from college? Evidence for negative selection in heterogeneous economic returns to higher education. American Sociological Review 75 (2): 273–302.
Cai, T., Tian, L., Wong, P.H. and Wei, L.J. (2011) Analysis of randomized comparative clinical trial data for personalized treatment selections. Biostatistics 12 (2): 270–282.
Deichmann, J., Eshghi, A., Haughton, D., Dominique, S.S. and Teebag, N. (2002) Application of multiple adaptive regression splines (MARS) in direct response modeling. Journal of Interactive Marketing 16 (4): 15–27.
Frigyik, B.A., Kapila, A. and Gupta, M.R. (2010) Introduction to the Dirichlet Distribution and Related Processes. University of Washington Electrical Engineering (UWEE) Technical Report, UWEETR-2010-0006.
Greenland, S., Lash, T.L. and Rothman, K.J. (2008) Concepts of interaction. In: K.J. Rothman, S. Greenland and T.L. Lash (eds.) Modern Epidemiology, 3rd edn. Philadelphia, PA: Lippincott Williams & Wilkins.
Haughton, D. and Oulabi, S. (1997) Direct marketing modeling with CART and CHAID. Journal of Direct Marketing 11 (4): 42–52.
Jackson, R. and Wang, P. (1996) Strategic Database Marketing. Chicago, IL: NTC Publishing.
Kane, K., Zheng, J., Lo, V.S.Y. and Arias-Vargas, A. (2011) True lift modeling: Mining for the most truly responsive customers and prospects. Invited seminar at the Predictive Analytics World (PAW) Conference, San Francisco, CA.
Knott, A., Hayes, A. and Neslin, S.A. (2002) Next-product-to-buy models for cross-selling applications. Journal of Interactive Marketing 16 (3): 59–75.
Kubiak, R. (2012) Net lift model for effective direct marketing campaigns at 1800flowers.com. SAS Global Forum, Paper 108-2012.
Lai, L.Y.-T. (2006) Influential marketing: A new direct marketing strategy addressing the existence of voluntary buyers. Master of Science thesis, Simon Fraser University School of Computing Science, Burnaby, BC, Canada.
Lo, V.S.Y. (2002) The true lift model – A novel data mining approach to response modeling in database marketing. ACM SIGKDD Explorations 4 (2): 78–86.
Lo, V.S.Y. (2009) New opportunities in marketing data mining. In: J. Wang (ed.) Encyclopedia of Data Warehousing and Mining, Hershey, PA: IGI Global, pp. 1409–1505.
Lo, V.S.Y. (2012) Opportunities in causal business analytics. Invited seminar at the Inaugural Statistical Practice Conference of the American Statistican Association (ASA), Orlando, FL.
Lund, B. (2012) Direct marketing profit model. Proceedings of Midwest SAS Users Group, Paper CI-04.
Maex, D. and Brown, P.B. (2012) Sexy Little Numbers: How to Grow Your Business Using the Data Your Already Have. New York: Crown Business.
Malthouse, E.C. and Derenthal, KM (2008) Improving predictive scoring models through model aggregation. Journal of Interactive Marketing 22 (3): 51–68.
Porter, D. (2013) Pinpointing the persuadables: Convincing the right voters to support Barack Obama. Presented at Predictive Analytics World; Oct, Boston, MA. http://www.predictiveanalyticsworld.com/patimes/pinpointing-the-persuadables-convincing-the-right-voters-to-support-barack-obama/, accessed 1 March 2013 (available with free subscription).
Quinonero-Candela, J., Sugiyama, M., Schwaighofer, A. and Lawrence, N.D. (2009) Dataset Shift in Machine Learning. Cambridge, MA: MIT Press.
Radcliffe, N.J. (2007a) Using control groups to target on predicted lift. Direct Marketing Analytics Journal 1: 14–21.
Radcliffe, N.J. (2007b) Generating incremental sales: Maximizing the incremental impact of cross-selling, up-selling and deep-selling through uplift modelling. Stochastic Solutions Limited, http://stochasticsolutions.com/pdf/CrossSell.pdf, accessed 24 February 2013.
Radcliffe, N.J. and Surry, P.D. (1999) Differential response analysis: modeling true response by isolating the effect of a single action. Proceedings of Credit Scoring and Credit Control VI, Credit Research Centre, University of Edinburgh Management School.
Radcliffe, N.J. and Surry, P.D. (2011) Real-world uplift modelling with significance-based uplift trees. Portrait Technical Report TR-2011-1 and Stochastic Solutions White Paper 2011. http://stochasticsolutions.com/pdf/sig-based-up-trees.pdf, accessed 31 December 2011.
Rexer, K. (2012) 5th Annual Data Mining Survey – 2011 Survey Summary Report. Rexer Analytics.
Roberts, M.L. and Berger, P.D. (1999) Direct Marketing Management. New Jersey: Prentice-Hall.
Samuelson, D.A. (2013) Analytics: Key to Obama’s victory. OR/MS Today February: 20–24.
Siegel, E. (2011) Upilft Modeling: Predictive Analytics Can’t Optimize Marketing Decisions Without It. Prediction Impact white paper sponsored by Pitney Bowes Business Insight.
Siegel, E. (2013a) The real story behind Obama’s election victory. The Fiscal Times 21 January, http://www.thefiscaltimes.com/Articles/2013/01/21/The-Real-Story-Behind-Obamas-Election-Victory.aspx#page1, accessed 31 January 2013.
Siegel, E. (2013b) Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die. New Jersey: Wiley.
Scherer, M. (2012) How Obama’s data crunchers helped him win. CNN News, http://www.cnn.com/2012/11/07/tech/web/obama-campaign-tech-team/index.html?hpt=hp_bn5, accessed 7 November 2012.
Schneeweiss, S., Gagne, J.J., Glynn, R.J., Ruhl, M. and Rassen, J.A. (2011) Assessing the comparative effectiveness of newly marked medications: Methodological challenges and implications for drug development. Clinical Pharmacology & Therapeutics 90 (6): 777–790.
Swait, J. and Louviere, J. (1993) The role of the scale parameter in the estimation and comparison of multinomial logit models. Journal of Marketing Research 30 (3): 305–314.
Wolpert, D.H. (1995) The relationship between PAC, the statistical physics framework, the bayesian framework, and the VC framework. In: D.H. Wolpert (ed.) The Mathematics of Generalization, Reading, MA: Addison-Wesley, pp. 117–214.
Wolpert, D.H. (2001) The supervised learning no-free-lunch theorems. Proceedings of the 6th Online World conference on Soft Computing in Industrial Applications, pp. 25–42.
Zheng, J., Zhou, J., Kane, K., Lo, V.S.Y. and Arias-Vargas, A. (2012) True Lift Modeling: Mining for the Most Truly Responsive Customers and Prospects. Invited seminar at the International Chinese Statistical Association (ICSA), Boston, MA, and also at Predictive Analytics World (PAW), Boston, MA.
Acknowledgements
The authors would like to thank Lidan Luo and Florence H. Yong for reviewing an earlier draft.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A
Proof of method B2; modifying the Lai method with addition of probability weights
Consider the 2 × 2 table in Figure 8. Define our estimation objective, that is, lift as a function of covariates x:

where R=event of response.
Z(x) is the response probability difference (lift) between the treatment and control groups given a set of characteristics, x. Then, it can be re-expressed as follows.

due to randomization of treatment and control, that is, assignment of treatment/control is random and does not depend on x, where P(T)=proportion of treated individuals in the sample and P(C)=1−P(T).
Note that (A.1) indicates that P(TR∣x) and P(CN∣x) have positive contributions to the lift.
Similarly, if we look at Z(x) in another way,

where (A.2) indicates that P(TN|x) and P(CR∣x) have negative contributions to the lift.
Note that (A.1) and (A.2) are the same equations except that we are expressing them differently. Adding (A.1) and (A.2) together, we have:

Quite often, marketing programs have a larger sample in the treatment group than the control group, that is, P(C)<P(T), as marketers often aim at gaining more revenue by contacting more individuals. It can be easily shown that Lai’s (2006) method is a special situation where P(T)=P(C)=0.5, which is not mathematically correct in general cases. However, Lai (2006) also proposed using a weight based on empirical findings but, in fact, there is a simple mathematical equation as shown in (A.3). Note that although this method has the same mathematical objective as Methods A1 and A2, that is, maximizing P(R∣T)−P(R∣C), empirically, because of the different estimation methods, it results in different estimates.
Appendix B
Comparison between methods B1 and B2
This appendix extends Appendix A to provide further exploration of Method B1 and a mathematical comparison with Method B2. As in Appendix A, we have the lift function of covariates:

where R = event of response

using Bayes’ and the randomization of treatment and control.
For Method B1, we define: Z′(x)=P(TR∣x)+P(CN∣x)−P(TN∣x)−P(CR∣x) (see Lai, 2006). Although Appendix A shows that the formula Z′(x) is only mathematically correct, that is, Z′(x)=Z(x), when the treatment and control groups are of equal size, that is, P(T)=P(C)=0.5. It is not mathematically clear how good or bad it is supposed to be in a general situation. To address this, we would like to investigate how closely related Z′(x) and Z(x) are, and whether the former could serve as an approximation to the latter. Specifically, we will evaluate the correlation between these two measures across observations. We will suppress x to simplify notations.
Consider expressing Z′ in a simpler form:

Then,

We now assume that the four outcome probabilities P(TR), P(CR), P(TN) and P(CN) follow the Dirichlet distribution with parameters α
1, α
2, α
3 and α
4, respectively, and  (see, for example, Frigyik et al, 2010). Since the expected value of each outcome probability is proportional to its own probability α
j
and the response probabilities tend to be much lower than non-response probabilities, it is reasonable to assume that
(see, for example, Frigyik et al, 2010). Since the expected value of each outcome probability is proportional to its own probability α
j
and the response probabilities tend to be much lower than non-response probabilities, it is reasonable to assume that  . With these, it can then be shown that (using standard Dirichlet properties from Frigyik et al, 2010):
. With these, it can then be shown that (using standard Dirichlet properties from Frigyik et al, 2010):

Then, it can be shown that, as α 0→∞ (essentially assuming that response probabilities are much smaller than non-response probabilities), (B.2) becomes:

If we further assume that α 1=5 and α 2=1 (essentially the expected value of P(TR)/P(CR) across individuals=5), (B.3) becomes:

One can easily verify that the correlation in (B.4) equals 1.0 when P(T)=P(C)=0.5, as expected, that is, Z and Z′ would be the same for ranking individuals under this condition. We now plot the relationship between the above correlation and the proportion of treatment, P(T), in Figure B1, which shows that the correlation is relatively high in a wide range of values, at least under the above assumptions. This may provide a possible explanation why Method B1 appears to have done pretty well in our empirical analysis.

Corr(Z, Z′) based on methods B1 and B2, by proportion of treatment group, P(T).
Appendix C
Computations of gini coefficient and top 15 per cent Gini
Assume we rank the hold-out sample by semi-decile, that is, 20 groups with 5 per cent in each group. Define the average lift at group j as:

where P(R∣T, j) and P(R∣C, j) represent the response probabilities in semi-decile subgroup j in the treatment and control groups, respectively, and can be estimated by the relative frequencies of response in the hold-out sample. Then,

where




In the common Gini formula for regular supervised learning, there is a denominator representing the maximum possible value of the numerator, that is, the gap between the best possible model (horizontal line at 100 per cent) and the diagonal random line, which can be approximated by (1-0.05)+(1-0.1)+⋯+(1-0.95)+(1-1)=9.5. However, for true-lift modeling, the maximum value is data dependent and much more complicated and can be greater than the traditional maximum value. Hence, we choose not to use a constant denominator as model comparisons within the same data set remain valid.
Similarly, Top 15 per cent Gini is simply focused on the top 15 per cent, or the top 3 semideciles, of the Gini coefficient formula:

Rights and permissions
About this article

Cite this article
Kane, K., Lo, V. & Zheng, J. Mining for the truly responsive customers and prospects using true-lift modeling: Comparison of new and existing methods. J Market Anal 2, 218–238 (2014). https://doi.org/10.1057/jma.2014.18
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1057/jma.2014.18