
Abstract
In this paper, I provide a selective survey of the literature on the social welfare implications of regulations that restrict insurers' use of classification by personal characteristics. I refer to this practice as regulatory adverse selection. To differentiate this survey from earlier ones, I focus on directly addressing the question “What can canonical models of insurance tell us about policy effects of restrictions on risk classification?” Rather than only focus on efficiency properties of such regulations, I adopt an explicit welfare function approach of the sort inspired by Harsanyi's veil of ignorance. This allows for an explicit trade-off concerning the equity and efficiency effects of regulatory adverse selection. Also, I pay more attention than do earlier surveys to the possibility of pooling equilibria under nonexclusivity of provision and additional considerations that specifically affect the life insurance market. I derive some explicit conditions that determine when such regulations are either welfare enhancing or detrimental.
Similar content being viewed by others


Introduction
For the joint Seminar of the European Association of Law and Economics (EALE) and the Geneva Association, I was asked to address the question of how to determine the welfare effects of government restrictions on risk classification – a practice I will refer to as regulatory adverse selection. As the other papers in this special issue demonstrate, this is a very timely question given recent anti-discrimination legislation in Europe and North America. There already exist some very good surveys on the problem of adverse selection and risk classification. However, from the policy perspective, I do believe there are some angles that have not been fully explored. Most, but not all, of the economics literature has considered welfare implications from the perspective of the criterion of potential Pareto improvements. I have focused instead on the question of whether commonly adopted government restrictions on insurers' use of characteristics such as gender and genetic test results to risk-rate insurance premiums directly reduce or increase social welfare.Footnote 1 To do this, I adopt an explicit welfare function analysis as motivated by Harsanyi'sFootnote 2 veil of ignorance approach. This allows for a direct comparison of the equity and efficiency implications of banning specific variables from risk classification by insurers. Another gap in the literature that I attempt to fill is due to the fact that the existing work on adverse selection and risk classification mostly concerns the problems of self-selection through menus of separating contacts that arise when insurers face adverse selection. This classic exercise is a very valuable one and I do pay some attention to it. However, by also treating cases in which pooling equilibria persist, rather than separating contracts, I can also address scenarios in which exclusivity of provision in contracting does not apply, as in the life insurance market.
The seminal contributions of Rothschild and StiglitzFootnote 3 and WilsonFootnote 4 have provided extremely useful models for guidance in arriving at sensible policy prescriptions as have simple models of life and annuity insurance.Footnote 5 But as with all canonical models, there are many additional real-world considerations not reflected in those models that can alter matters dramatically. Nonetheless, I believe that some well-reasoned policy conclusions can be drawn from insights gained from these and subsequent analyses at least for some scenarios. This is done in the next section of this paper where it is shown that the quantitative characteristics of the information effectively determines whether regulatory adverse selection reduces or improves social welfare. In the following section, I consider how policy prescriptions derived from the canonical models of insurance markets under conditions of adverse selection need to be reconsidered in light of the introduction of a series of real-world factors that are not included in those models. These factors include dynamic or life cycle concerns that are especially relevant for life and disability insurance and taste differences that are especially relevant to health-care insurance. Introducing behavioural or moral hazard effects is also very important for policy considerations. A summary of lessons learned and further research required to sharpen our understanding of the policy perspectives on the use of information to classify insureds is provided in the final section.Footnote 6
Risk classification and welfare effects on insurance markets: the canonical models
In this section, I will first be explicit about the welfare analysis to be adopted and then look at the welfare implications of banning risk classification in the simple Rothschild–Stiglitz–Wilson (RSW) model. This is followed by a consideration of some other public policies including compulsory insurance and public provision. Similar questions are addressed for a model of insurance better suited to considerations of the life insurance market.
Description of social welfare approach
The social welfare approach here uses fully interpersonally comparable cardinal utilities.Footnote 7 In the context of the models being considered in this paper, this approach can be justified by Harsanyi'sFootnote 8 veil of ignorance argument. That is, society is assumed to be a von Neumann–Morgenstern expected utility maximizer and this corresponds to using a utilitarian social welfare function to compare alternative social states. The justification is based on the notion that behind a (hypothetical) veil of ignorance, the appropriate probability to assign to being any individual is simply 1/n, where n is the number of individuals in society. Furthermore, if it turns out to be the case that individuals in some early time of life (ex ante) do not have personal information about their relative risk exposure, then the “hypothetical” veil of ignorance turns out to be an actual veil of ignorance and so this objective function is the same as an (uninformed) individual's expected utility function. That is, maximization of utilitarian social welfare turns out to be the same problem as maximizing an individual's ex ante utility (i.e., ex ante to revelation of person-specific information). For this reason, I will refer to expected welfare rather than utilitarian welfare when describing results.Footnote 9
While the above correspondence between Harsanyi's notion of utilitarian social welfare and expected utility maximization behind a veil of ignorance requires at least that people have the same beliefs about states of the world, this does not mean that everyone has the same probability distribution over his/her personal outcomes.Footnote 10 In all of the insurance models referred to in this paper, the above line of thought is not problematic. Adoption of a social welfare function approach allows one to explicitly consider equity-efficiency trade-offs. The analysis of how this trade-off is made in this paper is made clearer by utilizing an important result due to Atkinson.Footnote 11
Theorem:
-
Footnote 12 Let F(x) and G(x) be two income distributions with equal means and let L F (k) and L G (k) represent their respective Lorenz curves. Then for every function U(x) that satisfies the properties U′(x)>0, U″(x)<0, we have
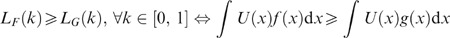
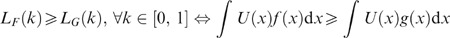
Note that if F(x) and G(x) represent possible income distributions for an individual and we plot the associated Lorenz curves for these distributions, then the above theorem tells us that the criterion of Lorenz dominance can also be used to check whether an individual expected utility maximizer prefers income distribution F over G.
Welfare comparison of alternative information scenarios
Now consider the comparative welfare implications of various possible information scenarios, including situations that arise due to regulation or public provision of insurance, using the standard RSW model of insurance. A variety of equilibrium concepts, based on alternative strategies by firms, have been developed since these seminal works.Footnote 13 We focus our attention on the so-called Rothschild–Stiglitz separating (no cross-subsidizing) equilibrium and the Wilson anticipatory (E2) pooling equilibrium. Comparing these two equilibria demonstrates how radically different one's conclusions about policies on risk classification will be according to the equilibrium concept that is assumed to be in force.
The basic model of Rothschild and StiglitzFootnote 14 considers two risk types (high or H-types and low or L-types) that are distinguished by their different exogenously determined probabilities of incurring some loss (p H >p L ) of amount d. In the case of no financial loss, income is W0 and so if no insurance is purchased state contingent income (or wealth) levels are W1=W0 (the no loss state) and W2=W0−d (the loss state). The fraction of H-types in the population is represented by q H , while the fraction of L-types is q L =1−q H . In our context, the information may or may not be intrinsically private. But even if it is not intrinsically private, regulations that prohibit its use by insurers in rate-making (i.e., the case of regulatory adverse selection) mean the asymmetric information model applies. If insurers are privy to risk-type information and are allowed to use it (i.e., the case of full disclosure), then the symmetric information model applies with each type receiving full insurance at the risk-type-specific actuarially fair rate.Footnote 15 Each person is charged his/her risk-type-specific actuarially fair rate and so chooses full coverage insurance. In Figure 1 this is demonstrated with each L-type receiving contract A and utility level UL1, while each H-type receives contract B and utility level UH1.Footnote 16

Rothschild–Stiglitz separating equilibrium.
With full insurance being purchased at the risk-type-specific actuarially fair rate, income levels are state independent, but different of course for each risk type. Letting u(.) denote an individual's elementary von Neumann–Morgenstern utility function, we can characterize these two contracts according to the following:


Thus, in the scenario of regulatory adverse selection, contract offers A for L-types and B for H-types cannot be implemented at zero expected profits for firms since H-types prefer contract A to B. Rothschild and StiglitzFootnote 17 show that for this scenario and provided that the proportion of high-risk types exceeds some critical level, there is a Nash equilibrium in pure strategies. The equilibrium involves firms offering a menu of contracts (two in this case). One contract involves full-coverage insurance at the H-type actuarially fair rate (contract B in Figure 1), while the other involves partial-coverage insurance at the L-type actuarially fair rate (contract C in Figure 1), with each type selecting the contract “designed” for him/her. Note that in Figure 1, the utility level for each H-type (L-type) is indicated by the indifference curve UH1 (UL2), respectively. Contract C that is purchased by the L-types is characterized by unit price p L , but involves only partial coverage. In fact, the coverage level is that fraction rS (S for separating contract) such that the H-types are just indifferent between contract C “designed” for L-types and contract B “designed” for H-types. Thus, we can characterize contract C according to:

Thus, in this scenario, a regulation that creates private information will lead to L-types receiving less insurance coverage than they would under full disclosure. Since H-types do not gain any utility from the ban, the efficiency implications clearly favour no regulation. Moreover, there is no favourable redistribution resulting from regulation and so economic arguments unambiguously support that no regulation banning the use of classification be implemented.Footnote 18
A second important implication of the Rothschild–Stiglitz model is that if the proportion of H-types in the market falls below some critical level, then there is no pure strategy Nash equilibrium. In Figure 1, if the proportion of H-types is high enough that the actuarially fair pooled odds line lies below the indifference curve for L-types that passes through the separating contract C, such as line EP1, then the separating pair of contracts {B,C} will represent the pure strategy Nash equilibrium, and will also be the Wilson foresight (E2) equilibrium. However, if the fraction of high-risk types in the population is small enough that the pooling line cuts the indifference curve UL2, as does EP2 in Figure 1, then there will be actuarially fair pooling contracts that the L-types prefer to contract C (i.e., any contract on the line EP2 that is on a higher indifference curve than UL2). This scenario is repeated in Figure 2. Note in particular that of all the possible pooling contracts that would generate zero expected profits for firms, contract D in Figure 2 is most preferred by low-risk types and so seems a “natural possibility” for an equilibrium. However, this scenario leads to the famous nonexistence result of Rothschild–Stiglitz. Although details are left out here, the nonexistence of a pure strategy Nash equilibrium occurs in this situation because firms are induced to make “unsettling” contract offers (relative to contract D) that, once other firms react to avoid making expected losses due to such “unsettling” offers (i.e., by withdrawing contract D), the unsettling offer(s) would also make expected losses. WilsonFootnote 19 explored the possibility of firms anticipating such a “market dynamic” and avoiding making such unsettling offers that earn expected losses once other firms react accordingly in the first place. Under this non-Nash (nonmyopic) foresight equilibrium concept, rather than nonexistence of equilibrium in the case of a relatively small fraction of H-types in the population, the outcome of the market is a pooling contract in which both risk types purchase the contract that is actuarially fair in a pooled sense. With this foresight assumption, contract D in Figure 2 does in fact become the equilibrium, which is referred to as the Wilson E2 equilibrium.Footnote 20 Since the level of coverage offered in contact D is the amount L-types most prefer when insurance is priced at the pooled actuarially fair rate and since this rate is greater than the L-types risk-type-specific actuarially fair rate, they prefer less than full coverage. Formally, contract D is described below, where p A =q H p H +q L p L is the average loss probability in the population:

where r*=argmax {V L (r)=(1−p L )u(W0−rp A d)+p L u(W0−rp A d+rd−d)}.

Wilson anticipatory (E2) pooling equilibrium.
In the Wilson E2 equilibrium, H-types do receive higher utility than in the full information setting, although L-types prefer the full information contract (A), so regulatory adverse selection creates winners and losers. One can also see that there is an efficiency cost associated with this pooling equilibrium that is not present when the full information contracts persist since with contract D not all risk is transferred from risk-averse consumers to risk-neutral firms. This sets up the possibility that introducing lump sum taxes and subsidies to deal with the adverse distributional effects of the symmetric information outcome may lead to a first-best outcome that Pareto dominates the Wilson pooling equilibrium. I return to this issue later in the paper, but for now I compare the two equilibria directly using the expected welfare framework and consider conditions under which we might expect one or the other to generate higher welfare. From the earlier discussion relating welfare to the expected utility of a person behind the veil of ignorance from which a person does not know his/her risk type, the welfare comparison hinges on whether the premium risk associated with the wedge in the cost of insurance (i.e., (p H −p L )d) is of greater or lesser importance than the risk-bearing cost associated with less than full insurance (i.e., due to r*<1). Assuming risk type is independent of income, the direction of redistribution resulting from a switch from the full information contracts (A, B in Figure 1 or 2) to the Wilson pooling contract (D) is in the “correct” direction in a welfare targeting sense. That is, the individuals with lower utility (i.e., the H-types) benefit at the cost of the individuals with higher utility (i.e., the L-types). Moreover, the L-types have higher income net of their insurance premiums under the full information scenario than do H-types. Thus, a ban on genetic information essentially transfers purchasing power from individuals with lower marginal utility of net income (L-types) to those with higher marginal utility (H-types). Therefore, expected welfare may be enhanced by banning risk classification.
However, it is also possible that such a regulation may lead to a worsening of welfare. Thus, it is important to determine under what scenarios which result will follow, and the simplest way to compare these is to consider the relative positions of the Lorenz curves for the various distributions of income (net of insurance premiums) that are induced by the various contracts. Note that utilitarian welfare comparisons of these contracts also correspond to expected utility comparisons from the point of view of a person who does not know what risk type he/she will be but does know that, once risk type is revealed to individuals, adverse selection will occur if insurers are not allowed to use this information for rate-making purposes.
The Lorenz curve traces out the percentage of total income of the population earned by the k% poorest (those with least income) as k ranges from 0 to 100 (although generally it is recorded as the fraction 0 to 1). If all individuals receive the same income level, then the Lorenz curve is the 45° line as noted in Figure 3 (perfect equality). A useful property of the Lorenz curve is that its slope at a given position k0 is equal to the level of the income of the person at that point in the distribution (i.e., the k0th poorest person's income) divided by mean income for the population. Since pricing is always actuarially fair, mean income of the population is always W0−p A d. Thus, it is easy to draw the Lorenz curve induced if contracts A and B are offered (i.e., the symmetric information case). Fraction q H are high risks and receive net income W0−p H d, while fraction q L are low risks and receive net income W0−p L d, where W0−p H d<W0−p L d. The relevant Lorenz curve in Figure 3 is labelled AB.

Lorenz curve analysis of risk classification.
Now suppose that, due to regulation banning the use of risk-rating, conditions of asymmetric information apply and the fraction of high-risk types in the population is sufficiently high that the separating contracts apply (i.e., L-types receive only partial coverage as described by contract C, while H-types continue to receive contract B). It follows that L-types who incur a loss receive less income than do H-types who, with contract B, receive the same income regardless of their loss state since they are fully covered by insurance. Thus, the first segment of the Lorenz curve reflects those L-types who incur a loss and these individuals make up q L p L of the population. The next poorest group of individuals are the H-types and the Lorenz curve for this group rises at the same rate as for the first segment of the AB Lorenz curve. The final (richest) group are the L-types who do not incur a loss, representing q L (1−p L ) of the population, and their incomes are higher than under contract A since they do not incur a loss and spend less money on insurance by purchasing only partial coverage. Thus, the last segment of the Lorenz curve in this scenario, labelled CA, rises at a rate that exceeds the last segment for AB. However, every Lorenz curve ends up at the upper right-hand corner (by definition) and so the Lorenz curve induced by asymmetric information under the separating contracts will be everywhere below that for the one induced by the symmetric information scenario. From this it is clear that expected welfare is higher under symmetric information, although this result is rather obvious from the description of the contracts.
Now consider the Lorenz curve induced by asymmetric information for the scenario in which the fraction of high risks is not sufficiently high to support the separating contracts of A and B as a Nash equilibrium. Under the assumption of Wilson foresight (E2 equilibrium), the outcome is a single pooling contract described by contract D in Figure 2. So income varies only as a result of whether one incurs a loss and not by risk type. Let W1(r*) and W2(r*) represent the income levels attained by individuals from contract D in the no-loss and loss states, respectively. The fraction of the population that incurs a loss is q H p H +q L p L and these individuals receive net income W2(r*)=W0−r*p A d−(1−r*)d, while the rest do not incur a loss and receive income W1(r*)=W 0 −r*p A d where, of course, W2(r*)⩽W1(r*) for 0⩽r*⩽1. So if r*=1, it follows that the Lorenz curve would lie on the line of complete equality and so dominate the Lorenz curve for symmetric information. However, except in the case of infinite risk aversion, r* will be less than one and so the strong inequality for net income will apply (i.e., W2(r*)<W1(r*)), and so the first segment of the Lorenz curve, induced by contract D will rise at a rate less than one according to the income levels of individuals who do incur a loss. This group is fraction q L p L +q H p H of the population. The remaining individuals do not incur a loss and receive income W0−r*p A d>W0−p A d>W0−r*p A d−(1−r*)d. If r* is sufficiently high, the poorest group under contract D receive more income than do the poorest group, who are the H-types, in the symmetric information scenario (i.e., W2(r*)>W0−p H d or r*>(1−p H )/(1−p A )) and the result will be that the first segment of the Lorenz curve will dominate under a regulation banning the use of private information. Moreover, for r* sufficiently close to 1 there will be overall Lorenz dominance. This case is illustrated in Figure 3 and reflects the possibility that a regulation that does not allow firms to use risk-rating can improve social welfare and would be preferred ex ante by persons who do not yet know their eventual risk type. Alternatively, of course, if r* is sufficiently small, the reverse Lorenz ordering would apply.
Three reservations about the above possibility need to be emphasized. Firstly, the above analysis does not allow for ex post redistribution for the separating contracts available under symmetric information and so does not imply that contract D would be welfare superior to contracts A and B when tax/subsidy between contracts is considered. The result of Crocker and Snow,Footnote 21 that more information for insurers about their clients risk type always improves the efficiency frontier (i.e., leads to a potential Pareto improvement) as long as the information can be gathered costlessly and insureds are assumed already to know their respective risk types, still applies here. Second, a regulation requiring full coverage to be purchased at the pooled actuarially fair rate would in fact generate a Lorenz curve that lies precisely on the line of complete equality and so would generate the highest possible welfare that is feasible. Third, r* may of course be sufficiently less than one so that the symmetric information scenario (contracts A and B) leads to Lorenz dominance over the asymmetric information scenario (contract D). We expand upon the third issue below.
The value of r* depends on all parameters of the problem including p A , and so one must be careful in using the inequality r*>(1−p H )/(1−p A ) to intuitively demarcate those cases in which regulatory adverse selection is likely to be welfare enhancing. Also, suppose the above condition on r* is satisfied but that the Lorenz curve for D, although starting above that for AB, intersects it at some point. In this case, the Lorenz ordering is ambiguous, although we can at least say that D provides greater equality among the poorest in the population.Footnote 22 Thus, knowing the relative values W2(r*) and W0−p H d in combination with the relative sizes of the population parameters {p L , p H , q L , q H } can provide substantial guidance in knowing whether regulatory adverse selection improves or worsens expected welfare. It is also useful to carry out certain comparative statics exercises, as developed below.
In order to understand better the circumstances under which we expect the Lorenz curves to be configured as in Figure 3, it is useful to compare explicitly ex ante expected utility for the two information scenarios. First, consider the expressions for ex ante utility or expected welfare under each scenario. Under symmetric information contracts A and B apply and so upon substituting for q L =1−q H , we obtain ex ante expected utility or expected welfare under full disclosure equal to

Note that under contract D (asymmetric information with pooling) income in the bad state is less than income in the good state, but income is independent of risk type. The probability of being in the bad state is p H for H-types and p L for L-types, and since the ex ante probabilities of being each of these types is q H and q L , respectively, this leads to an ex ante probability of being in the loss state equal to p A =q H p H +q L p L . Thus, the ex ante probability of being in the no-loss state is (1−p A ) and ex ante expected utility or expected welfare from contract D (i.e., under regulatory adverse selection with a pooling outcome) is

where r* is the value of r that maximizes the L-types utility given the various parameters involved. There is a critical value of q H , call it q H c, possibly small but positive, such that for any q H <q H c ex ante expected utility or expected welfare is unambiguously higher under asymmetric information (contract D) than under symmetric information (contracts A and B). This result is stated below. The proof is provided in Appendix A.Footnote 23
Proposition 1:
-
There exists some q H c>0, possibly small, such that for any q H <q H c, it follows that EUD>EUAB.
Proposition 1 indicates that at least for populations where the fraction of high-risk types is sufficiently small, regulatory adverse selection under a pooling contract will generate higher expected welfare than full disclosure (i.e., symmetric information). The intuition for this result can be understood from the following thought experiment. Suppose we begin from a position with q H =0 (i.e., there are no high-risk types in the population) and allow q H to increase a little, call this amount Δq H , which implies an equivalent reduction in q L . In the pooling contract, due to the envelope theorem, the effect on the coverage level (r*) is of second-order importance. This follows because at q H =0, the unit price p A is the same as the actuarially fair price for low-risk types (p L ) and, since r* is chosen so that expected utility of the low-risk type is maximized, we have r*=1 at q H =0 (and also dEUD/dr=dV L (r)/dr=0). Thus, since income is effectively the same in both states of the world, the impact of an increase of Δq H when q H =0 is that the effect on expected utility under pooling is just the effect of an increase in the cost of insurance of amount Δq H (p H −p L )d evaluated at the marginal utility associated with income level W=W 0 −p L d. On the other hand, the effect of an increase in q H under symmetric information (contracts A and B) is to generate a lottery that shifts the probability weight by amount Δq H from income level W=W0−p L d to income level W=W0−p H d. This implies a reduction in expected income of the same amount Δq H (p H −p L )d, which is the same as under asymmetric information (contract D). But the marginal utility weighting for this income change shifts by a discrete amount according to the reduction in income levels from W0−p L d to W0−p H d and so the cost of the increase in q H in this case is evaluated at the marginal utility associated with income level W0−p H d, which is less by a discrete (noninfinitesimal) amount relative to W0−p L d (i.e., the cost of Δq H >0 is evaluated at a higher marginal utility level in the symmetric information scenario).
Of course, it is not clear a priori just how small q H must be for asymmetric information (regulatory adverse selection) to generate higher expected welfare than the full information contracts. However, the result does suggest at least that regulatory adverse selection is more likely to be welfare enhancing in situations where the fraction of the population that is high risk is relatively small. An example of such a scenario in which banning information by insurers is currently hotly debated is that of genetic test results. Since relatively few people have significant information resulting from genetic tests, banning their use by insurers may indeed be a candidate for welfare improving regulation. Alternatively, banning gender as a rating tool for life insurance or annuities may well not be advisable since in that case q H ≈0.5. In any case, the ambiguity over whether equilibrium under asymmetric or symmetric information generates higher expected welfare requires a case-by-case analysis as argued and carried out for some specific examples in Hoy et al.,Footnote 24 Hoy and RuseFootnote 25 and Hoy and Witt.Footnote 26 A further theoretical result which supports the above intuition is developed below.
Notice that any combination of changes to the parameters p H and q H that leaves p A unchanged will leave r* unchanged and so EUD unchanged as well. Therefore, if we find that changing p H and q H simultaneously such that p A is unchanged has a definitive effect on EUAB, then we can ascertain further some of the types of scenarios that are more likely to lead to asymmetric information (regulatory adverse selection) being preferable to the outcomes (contracts A and B) that occur under symmetric information, and vice versa of course. It turns out that a decrease in q H accompanied by a complementary increase in p H that leaves p A unchanged (i.e., keeping q H p H =k for some constant k) will reduce EUAB while leaving EUD constant. This result is stated formally with proof provided in the appendix.
Proposition 2:
-
Any increase in p H that is accompanied by a decrease in q H such that p H q H remains constant will reduce EUAB while having no effect on EUD.
Note that this proposition is complementary to Proposition 1 since again lower values of q H , in this case accompanied by higher values of p H , will lead to the asymmetric information contracts becoming relatively more favourable compared to the symmetric information contracts. Thus, if one were to establish some set of parameter values that lead to higher welfare being generated by the asymmetric information contract D than the symmetric information contracts of A and B, then changes in p H and q H as noted in Proposition 2 will enhance that relationship.
So, let us take stock of what the analysis thus far can tell us about when a government restriction on insurers using categorical information to risk-rate insurance contracts will lead to higher expected welfare compared to a full disclosure law. We see that if the proportion of high-risk types exceeds that which supports the separating contracts (B and C) of Rothschild and Stiglitz as a Nash equilibrium, then it is clear that the full information scenario (contracts B and A) delivers higher expected welfare, and so government should not induce regulatory adverse selection by bans on risk-rating. However, if the proportion of high-risk types is below this threshold, then no clear-cut ranking is evident a priori and one has to consider each case on its own merits. We do know, however, that if q H is “sufficiently small”, expected welfare will be enhanced by regulations that induce adverse selection. Of course, in general the result depends on the entire set of parameters. Given a set of parameters and a value of r* (i.e., coverage level under pooling), one can trace out the relevant Lorenz curves to get some idea of the welfare comparison. It is important to restate that such conclusions rely on the Wilson foresight equilibrium concept reflecting a reasonable description of the insurance market. If one does one's analysis with a description of firm behaviour that supports the Rothschild–Stiglitz separating pair of contracts (B and C) as a description of equilibrium even when the fraction of high-risk types is “small”, such as the anticipatory equilibrium concept of Riley,Footnote 27 then of course one will have a very different view of policy advice and always suggest full disclosure of information as a welfare-enhancing policy.
Another important caveat to the above results is that I have not considered tax/subsidy policies as an alternative. Crocker and SnowFootnote 28 show that a social planner can always achieve a potential Pareto improvement (i.e., extend the Pareto frontier) by using any costless categorical information to construct a set of contracts that obey self-selection constraints and also generate zero expected profits. The resulting contracts in their case are the same as those described by MiyazakiFootnote 29 and Spence.Footnote 30 Their result applies to imperfect information about risk class membership as well as to perfect information.Footnote 31 Interestingly, governments have been willing to regulate firms by not allowing them to use relevant information for risk-rating, but I know of no examples of tax/subsidy policies of the Crocker–Snow variety for dealing with the distributional problems of premium risk while allowing firms to make full use of risk-rating. One reason for this may be that it is not a trivial exercise for governments to determine the appropriate tax/subsidy parameters. This may especially be the case when information about the relevant parameters changes over time, as is likely in cases such as the development of genetic information. The advantage of banning classification, at least for some range of parameter values, is that such a regulation can be expected to increase expected welfare without having to know with too much precision how these parameters are changing over time. Alternatively, the fact that governments have eschewed tax/subsidy policies of the Crocker–Snow variety in favour of banning certain types of categorical information may simply be an example of government failure.
An alternative government policy, that of full compulsory insurance with each person paying the population weighted average actuarially fair price (p A ), will lead to the highest feasible level of utilitarian welfare regardless of equilibrium concept adopted or set of market parameters considered. This contract is F in Figure 4. Although this is the first-best policy for the Rothschild–Stiglitz model, the real world is obviously more complicated and so a policy that restricts individual choice as much as would compulsory insurance regulation may not be suitable in a real-world setting while the insight gained from price regulation applied to such a simple model may still be warranted.Footnote 32 Nonetheless, the welfare-enhancing implications of compulsory, publicly provided health insurance as a means of averting adverse selection costs may well explain much of the popularity of such schemes. Besides the equity-enhancing implications of not charging individual prices based on observed variables related to health risk, such programs are often financed through progressive taxes that further enhance equity.Footnote 33 On the other hand, people may have different preferences over health-care packages and related costs of insurance and so choosing an appropriate, fixed level or type of health insurance to be made compulsory is not a trivial exercise. This may explain why public health insurance plans often leave certain types of medical treatments (such as physiotherapy and drugs) for the private market to cover.Footnote 34 These sorts of complications may explain the preference of governments for adopting price regulation to enhance equity rather than simply taking over private insurance markets.

Illustration of effects of compulsory full insurance.
Extensions to the basic model
Up to this point, I have taken for granted that insurers can offer exclusive contracts and so offering a menu of contracts with differing levels of coverage at different unit prices can be an effective way of selecting different risk types. Such models are appropriate in the context where the insurable loss is of a fixed and identifiable size (e.g., the value of an automobile or cost of health treatments). In considering life insurance, however, there is no obvious objective and observable value for loss of life. If, at a given price, one individual wishes to purchase more life insurance coverage than another, this does not necessarily signal that the higher demand person has higher mortality risk. Moreover, life insurance needs of people are likely to vary over their lifetimes, so individuals will be reticent to agree to buy all present and future life insurance needs from a single provider since that would give the firm future monopoly power over the individual. Thus, it is perhaps not surprising that life insurance providers tend not to follow a policy of exclusivity of coverage, and so nonlinear pricing as a means of dealing with adverse selection is not viable.Footnote 35 Cawley and PhilipsonFootnote 36 even find modest quantity discounts rather than convex price schedules in the life insurance market. Such a pricing policy quite possibly reflects some administrative costs that are fixed for any sized contract (i.e., independent of level of coverage chosen). Moreover, it is quite possible that presently there is not a significant amount of hidden information in the life insurance market, although this would certainly not be the case in the presence of regulations that restrict the use of risk classification in setting prices.
So, we need to consider what differences arise in policy prescriptions in an insurance market where linear pricing occurs. First, we explore the implications of linear pricing for a model with the same basic assumptions as the Rothschild–Stiglitz model. If we impose linear pricing on such a model, then the contracts offered under symmetric information continue to be contracts A and B. Each risk type faces a linear price implying constraint EL for low-risk types and EH for high-risk types with the result that L-types choose contract A and H-types choose contract B just as in Figure 1 (see Figure 5). Suppose insurers are not allowed to charge different prices for different risk types and cannot observe the quantities that insureds purchase. The separating pair of contracts B and C in Figure 1 will no longer lead to effective self-selection since H-types will simply purchase several policies of type C and so such contracts will generate expected losses. So consider what would happen if insurers offered insurance coverage at the pooled fair odds price (EP in Figure 5) with no quantity restriction. Suppose L-types prefer to purchase some positive quantity along this price line, as indicated by contract L p in Figure 5, rather than no insurance at all (point E). At this price, H-types will want to purchase a greater amount of insurance than L-types, as indicated by contract H p . The result would be that insurers earn an expected loss since the expected cost of these contracts is not the population-weighted expected cost of claims from different types but rather the demand-weighted expected cost of claims, which is referred to in the literature as the average clientele risk.

Contract design under nonexclusivity.
Thus, insurers need to increase the price of insurance to cover this higher expected cost of claims. Depending on the fraction of each risk type in the population and their relative demand (price) elasticities, an equilibrium price can be determined.Footnote 37 Although it is possible with a discrete distribution of risk types that the resulting equilibrium will only include sales to high-risk types at price EH, the so-called adverse selection death spiral, let us assume that the resulting equilibrium does include positive insurance purchases by low-risk types. This case is illustrated by price line EP′ and contracts Lp′ and Hp′ in Figure 5. Now consider the welfare implications of banning insurers from using risk-type-specific pricing. Rather than contract A for L-types and B for H-types, these individuals receive contracts Lp′ and Hp′, respectively. The channels through which adverse selection costs arise are through (i) an increase in the average price, (ii) over-insurance of H-types, and (iii) under-insurance of L-types. Although the over- and under-insurance results are in a sense “voluntary” choices of individuals, these choices create externalities that reduce welfare in a way that is different than under conditions of exclusivity of provision (i.e., in comparison of contracts {A,B} vs. D in Figure 2 for the standard Rothschild–Stiglitz model). Note in particular that in the loss state of the world, H-types receive more income than do L-types in either of their loss or no-loss states. Thus, in comparison to the symmetric information contracts of A and B, the effect of regulatory adverse selection does not involve transfers of income which are unambiguously from lower to higher marginal utility of income situations as was the case for the Rothschild–Stiglitz model. This can seriously compromise the possibility of regulatory adverse selection leading to an increase in expected welfare. Nonetheless, as shown in Hoy and PolbornFootnote 38 and Ni,Footnote 39 it is possible that a welfare improvement will result from such price regulation. However, a cap on insurance purchases in conjunction with a ban on the use of categorical variables for risk-rating may enhance the possibility of regulatory adverse selection leading to an increase in expected welfare. This issue is explored more fully in Polborn et al.Footnote 40 where a proposition similar to Proposition 1 in this paper is developed in the presence of such a cap.Footnote 41
It is also important to consider the implications of a regulation that bans risk classification by insurers on the incentives of initially uninformed individuals to obtain such information.Footnote 42 Due to space limitations, this issue is only touched upon here. It turns out that if individuals have different benefits and costs of the information outside of the insurance market effects, then one can arrive at a variety of conclusions concerning the implications of regulatory adverse selection. In particular, a ban may improve or worsen expected welfare and may lead either to too few or too many people becoming informed from a social welfare perspective. Perhaps, the most interesting result is that if not too many people become informed, then regulatory adverse selection may lead to higher expected welfare. The rationale for this result is the same as in a static model with all individuals informed of their risk status at the outset. Enforced pooling offers a sort of insurance against premium risk to those who are uninformed, but have sufficient desire to become informed. However, in this scenario too many people will become informed and so a tax on the test would improve welfare.Footnote 43
Further considerations
The canonical models of RSW, and related models of life insurance used in this paper provide some useful guidance as to when a regulation restricting the use of risk classification by insurers can lead to a welfare improvement. In this section, I briefly consider some real-world issues not captured by those models. To begin, as already noted, the RSW model uses state independent preferences, an assumption that is implausible in the context of the life insurance market.Footnote 44 Not only is the “insurable loss” likely to be a very subjective matter, depending on family relationships and subjective preferences regarding the amount of money an insured wants to bequeath, but such circumstances are likely to change over an individual's lifetime. This has significant implications on the analysis of contracting possibilities. For example, the option of guaranteed renewability of life insurance is often argued to be a means for individuals to avoid the negative welfare effects of premium risk. “Locking-in” early in life with an insurance contract guarantees future premium levels (i.e., provides insurance against premium risk).Footnote 45 Although such contracting possibilities may well mitigate the need for government action to reduce the negative impact of premium risk, renewable life insurance contracts that provide insurance against premium risk come at a cost. That is, implicit insurance against premium risk is effectively bundled with an amount of insurance that may well be greater than currently demanded. Thus, a ban on risk classification may improve social welfare in such an environment.Footnote 46
Models such as the RSW model, which implicitly assumes homogeneous preferences over the loss, will also miss certain important elements of markets such as health insurance. If relevant health-care treatments that people would want to adopt vary across individuals then using models with homogeneous individuals may well lead to misleading conclusions. The resulting demand for insurance will reflect not just risk type but demand type as well.Footnote 47 In such circumstances, the best policy may be to have some limited amount of coverage that insurers must offer under conditions of regulatory adverse selection while supplementary coverage may be obtained only under full disclosure. This will eliminate over-insurance by low demand but high-risk types, although there will be residual premium risk faced by high demand types.
I have also ignored the effect of allowing for individuals to adopt certain products or lifestyle choices that affect their risk levels. Although some models investigating the effects of regulatory adverse selection have included endogenous selection of risk level, more research is needed on this issue.Footnote 48 For example, it is an open question whether characteristics reflecting individuals' choices should be used for risk-rating purposes even when immutable characteristics may not. In fact, even creating a dichotomy between immutable and behavioural characteristics is methodologically, and philosophically, problematic. Variables that appear to be the result of “choice” may to at least some extent be driven by “immutable type”. Recent advances in genetics, for example, have illustrated that decisions such as smoking may in fact be significantly influenced by one's genes. So assessing a higher insurance price on smokers may be only in part a tax on a choice-based activity but also in part a tax on an immutable characteristic.
Another important consideration is that many people receive health and life insurance through their employer and this at least reduces their reliance on individual policies.Footnote 49 Of course, this is not to say that risk-rating of individuals is not an issue in such cases, but rather that one needs to understand the incentives for using categorical information in the context of employer-provided insurance. Design considerations for options offered through group insurance may be quite different from what one would expect to arise in an individual policy setting.Footnote 50
Most economic models of competitive insurance markets, including the RSW model and the life insurance model used by Hoy and Polborn,Footnote 51 assume that firms are perfectly competitive and risk neutral, thus implicitly implying that there are no efficiency issues concerning enforced risk pooling from the supply side of the market. In other words, the zero expected profit condition means risk-neutral firms should be indifferent over legislative options since they will end up in the same position. However, such a conclusion requires that all the firms “follow the rules”, whatever those may be. Since insurance companies do seem very much concerned about the regulatory environment in which they operate, I believe more thought and modelling on this score would be productive. Perhaps, the competitive model is not a good one for insurance markets and modelling insurance as a homogeneous good may be inappropriate.Footnote 52
Besides considering market-oriented concerns of firms and consumers in ways not captured by standard economic models of insurance markets, social analysts are also motivated by nonwelfaristic concerns. This is especially evident in the context of risk-rating using genetic information, a practice often referred to as genetic discrimination. In the policy arena, at least, such nonwelfaristic considerations will attract attention, even if they are not persuasive to economists.Footnote 53 However, as argued in Hoy and Ruse,Footnote 54 applying the insights from economic analysis concerning what type of equilibrium concept may apply under asymmetric information critically affects the extent and type of discrimination that one would perceive under the alternative regulatory regimes of full disclosure versus regulatory adverse selection. Therefore, economists may well wish to enter such debates.
Conclusions
By way of summarizing this paper, let me return to the central question of this paper, which is: “What do the canonical models of insurance markets provide us by way of guidance in evaluating government legislation that restricts the use of immutable characteristics by insurers in risk-rating premiums?” More specifically, does regulatory adverse selection improve or worsen expected welfare in the sense of Harsanyi'sFootnote 55 veil of ignorance inspired welfare approach?Footnote 56 As did others, I have argued that such a policy may provide a sort of insurance against premium risk but will create adverse selection costs and so these two competing forces will determine the overall effect on expected welfare. Suppose insurance contracts include the characteristic of exclusivity of provision and that the fraction of high-risk types in the population exceeds the critical level for which the separating pair of contracts with no cross-subsidization supports a Nash equilibrium in the Rothschild–Stiglitz model. In this scenario, regulatory adverse selection unambiguously reduces expected welfare and so governments should not restrict use of risk classification. On the other hand, if the fraction of high-risk types is sufficiently small that a pooling equilibrium of the Wilson foresight-type pertains (and this is the “correct” equilibrium concept to describe the insurance market), then expected welfare may well be enhanced by banning risk classification. Although this is certainly not the case for all possible configurations of parameters, we do know that this will at least be guaranteed to be the case as long as the fraction of high-risk types in the population is “small enough”. To determine just how small is “small enough” requires some empirical/simulation analysis, but we can at least presume that regulatory adverse selection is more likely to be welfare enhancing when directed at classificatory variables such as genetic test results compared to gender or age. In the case of insurance markets characterized by linear pricing (i.e., markets that are not characterized by exclusivity of provision in contracting), analogous results apply but a welfare gain from enforced pooling of different risk types is not as likely if high-risk types are not restricted from over-insuring.
Throughout the paper some of the many real-world factors that are not adequately taken into account by existing models of insurance market behaviour have been noted. These may have profound effects on designing the appropriate policy regarding risk classification in insurance markets and so provide fertile ground for further research on the effect that government policy can have on the incentives for acquisition, and the implications, of additional information about individuals' risk status. This is particularly important in light of the development of new testing technologies and treatments in the field of medicine.
Notes
For interesting discussions of these issues, see, on genetic discrimination, the papers of Knoppers et al. (2004); Lemmens (2000); MacDonald (2000), and, on gender discrimination, see Woodfield (1994, 2000).
For example, Abel (1986); Brugiavini (1993); Hoy and Polborn (2000) and Villeneuve (2000, 2003).
The importance of (asymmetric) information is, of course, important in all areas of economics, as demonstrated by works such as Drèze (1960); Hirshleifer (1971); Mirlees (1971); Akerlof (1978); Arrow (1978); Rothschild and Stiglitz (1997); Boadway (1997); and Stiglitz (2000). Of particular relevance to the topic of this paper is the line of research typified by Rochet (1989); Cremer and Pestieau (1996); and Boadway et al. (2004).
Sen (1970, Theorem 1, pp. 10–18) demonstrates that distributional comparisons of utility vectors would be essentially toothless without such strong measurability assumptions on the utility function.
Doing so also helps avoid any confusion with the efficiency-based notion of welfare (i.e., that of a potential Pareto improvement).
For an analysis of breakdowns in the link between Harsanyi's theorem and traditional utilitarianism when individuals have different beliefs over states of the world, such as when some people are optimistic or pessimistic relative to “true” beliefs, see Hylland and Zeckhauser (1979); Mongin (1995); Blackorby et al. (2000) and Gilboa et al. (2004). See also Tabarrok (1994) for a contractarian analysis.
Ibid.
These include strategies in noncompetitive environments and multi-period frameworks. See the excellent surveys by Dionne et al. (2000) and Crocker and Snow (2000).
As is typical in these models, administrative costs are assumed to be zero, insurers are assumed to be risk neutral and the market is perfectly competitive.
For a detailed explanation of this graph, see Rothschild and Stiglitz (1976) or Dionne et al. (2000).
See note 17.
Since the utilitarian welfare function satisfies the Pareto principle and asymmetric information in this case creates a Pareto-worsening of the distribution of utilities, social welfare is reduced by regulation that bans risk classification.
Wilson's pooling equilibrium allows for cross-subsidization between risk types, but requires that each contract offered earns non-negative expected profits. Miyazaki (1977) and Spence (1978) extend this concept to allow for firms to offer sets of contracts, some of which generate negative expected profits, as long as together they earn non-negative expected profits. For a more elaborate discussion, see Hoy (1982) and Dionne et al. (2000) – contract C1 being the Wilson E2 equilibrium in Figure 4a in the latter.
If the Lorenz curve for D cuts that for AB once from above, one may be able to appeal to the principle of diminishing transfers (see Shorrocks and Foster, 1987; Davies and Hoy, 1994), which can sometimes refine the Lorenz ordering in such cases in favour of curve D.
This proof follows a similar strategy, and generates a similar result, as that for a model of life insurance in Proposition 5 of Polborn et al. (2006).
Crocker and Snow (1985) also show that in scenarios where a Nash equilibrium does not exist, a tax-subsidy system applied to firms' contract offers, based only on the price of the contract, may lead to existence of a Nash equilibrium and be welfare enhancing. The tax-subsidy system entails redistribution from low risks to high risks and so also is in the “appropriate” direction (i.e., increases utilitarian social welfare).
This point is made more clearly when the linear pricing model of the life insurance market, with different demand types, is discussed later in this section. In such a model, there is no obvious quantity of insurance that a person will want to buy.
See Dahlby (1981) for a model on the effects of combining compulsory, publicly provided insurance with supplementary private insurance.
Pauly et al. (2003, p. 4) note that term life insurance providers do not seek information about total life insurance holdings of their clients and so do not try to induce different risk types to self-select contracts based on a price-quantity constrained menu of contracts.
See Villeneuve (2000, 2003) and Hoy and Polborn (2000) for details.
The cap is not a blanket restriction on the amount of insurance a person can buy but rather refers to an amount that a person can buy without being required to reveal information about risk type. An example of such a provision is in place regarding certain genetic tests in the U.K. life insurance market, where the cap is currently set at £500,000.
Papers that have addressed the incentive of individuals to acquire risk status information include Doherty and Thistle (1996); Ligon and Thistle (1996); Doherty and Posey (1998); and Crocker and Snow (1992). See Dionne et al. (2000) and Crocker and Snow (2000) for reviews of this literature. However, existing models focus on the Rothschild–Stiglitz separating equilibrium concept and also assume the cost of obtaining information is either zero or the same for all individuals.
See the working paper version of this paper, Hoy (2005), for details on this issue.
Early models of insurance purchasing decisions with state dependent preferences were developed by Cook and Graham (1977) and Dehez and Drèze (1982). Models of life insurance or annuity demand under conditions of adverse selection include Abel (1986); Brugiavini (1993); Villeneuve (2003); Hoy and Polborn (2000).
For models of renewable life insurance, see Pauly et al. (1995, 1998) and Hendel and Lizzeri (2003).
See Polborn et al. (2006) for details on this possibility.
See Smart (2000) and Wambach (2000) for analyses of heterogeneous preferences regarding risk aversion in the RS model. They show how this leads to substantial changes in the results generated by the model.
See, for example, Bond and Crocker (1991); Hoy (1989); Doherty and Posey (1998); and Strohmenger and Wambach (2000).
In the U.S., for example, approximately 90 per cent of privately purchased health insurance is through employment. In other countries, health insurance that is supplementary to state-provided insurance is often provided through employment, as is some life insurance.
See, for example, Crocker and Moran (2003). For a summary and critical review on the relationship between group health insurance and portability, see Gruber (1998).
Other issues regarding firms' preferences for alternative regulatory regimes are discussed in more detail in Hoy and Ruse (2005).
For more on the broader (nonwelfaristic) perspective of categorical discrimination, see Kitcher (1996); Hoy and Lambert (2000); Bossert and Fleurbaey (2002); and Hoy and Ruse (2005).
Recall that this social welfare function is, when conditions are relevant, the same as an individual's expected utility before she knows her risk type.
References
Abel, A. (1986) ‘Capital accumulation and uncertain lifetimes with adverse selection’, Econometrica 54: 1079–1097.
Akerlof, G.A. (1978) ‘The economics of ‘Tagging’ as applied to the optimal income tax, welfare programs, and manpower training’, American Economic Review 68: 8–19.
Arrow, K.J. (1978) ‘Risk allocation and information: Some recent theoretical developments’, The Geneva Papers on Risk and Insurance 8(26): 5–19.
Atkinson, A.B. (1970) ‘On the measurement of inequality’, Journal of Economic Theory 2: 244–263.
Blackorby, C., Donaldson, D. and Mongin, P. (2000) Social aggregation without the expected utility hypothesis, discussion paper, Department of Economics, University of British Columbia.
Boadway, R.W. (1997) ‘Public economics and the theory of public policy’, The Canadian Journal of Economics 30: 753–772.
Boadway, R.W., Leite-Monteiro, M., Marchand, M.G. and Pestiea, P. (2004) Social insurance and redistribution with moral hazard and adverse selection, CEPR discussion paper no. 4253, London.
Bond, E.W. and Crocker, K.J. (1991) ‘Smoking, skydiving and knitting: The endogenous categorization of risks in insurance markets with asymmetric information’, Journal of Political Economy 99: 177–200.
Bossert, W. and Fleurbaey, M. (2002) ‘Equitable insurance premium schemes’, Social Choice and Welfare 19: 113–125.
Brugiavini, A. (1993) ‘Uncertainty resolution and the timing of annuity purchases’, Journal of Public Economics 50: 31–62.
Cawley, J. and Philipson, T. (1999) ‘An empirical examination of information barriers to trade in insurance’, American Economic Review 89(4): 827–846.
Cook, P.J. and Graham, D.A. (1977) ‘The demand for insurance and protection: The case of irreplaceable commodities’, Quarterly Journal of Economics 91: 143–156.
Cremer, H. and Pestieau, P. (1996) ‘Redistributive taxation and social insurance’, Interntaional Tax and Public Finance 3: 281–295.
Crocker, K.J. and Moran, J.R. (2003) ‘Contracting with limited commitment: Evidence from employment-based health insurance contracts’, Rand Journal of Economics 34(4): 694–718.
Crocker, K.J. and Snow, A. (1985) ‘A simple tax structure for competitive equilibrium and redistribution in insurance markets with asymmetric information’, The Southern Economic Journal 51: 1142–1150.
Crocker, K.J. and Snow, A. (1986) ‘The efficiency effects of categorical discrimination in the insurance industry’, The Journal of Political Economy 94: 321–344.
Crocker, K.J. and Snow, A. (1992) ‘The social value of hidden information in adverse selection economies’, Journal of Public Economics 48: 317–347.
Crocker, K.J. and Snow, A. (2000) ‘The theory of risk classification’, in G. Dionne (ed) Handbook of Insurance, Boston, Dordrecht, and London: Kluwer Academic Publishers, pp. 245–276.
Dahlby, B.G. (1981) ‘Adverse selection and Pareto improvements through compulsory insurance’, Public Choice 37: 547–558.
Davies, J.B. and Hoy, M. (1994) ‘The normative significance of using third-degree stochastic dominance in comparing income distributions’, Journal of Economic Theory 64: 520–530.
Davies, J.B. and Hoy, M. (2003) Equity effects of public financing of health insurance, unpublished mimeo.
Dehez, P. and Drèze, J.H. (1982) ‘State-dependent utility, the demand for insurance and the value of safety’, in J. Drèze (ed) Essays on Economic Decisions Under Uncertainty, London: Cambridge University Press, pp 23–70.
Dionne, G., Doherty, N. and Fombaron, N. (2000) ‘Adverse selection in insurance markets’, in G. Dionne (ed) Handbook of Insurance, Boston, Dordrecht, and London: Kluwer Academic Publishers, pp. 185–243.
Doherty, N.A. and Posey, L.L. (1998) ‘On the value of a checkup: Adverse selection, moral hazard and the value of information’, The Journal of Risk and Insurance 65(2): 189–211.
Doherty, N.A. and Thistle, P. (1996) ‘Adverse selection with endogenous information in insurance markets’, Journal of Public Economics 632: 83–102.
Drèze, J.H. (1960) ‘Le paradoxe de l’information’, Economie Appliquée 13: 71–80 (reprinted in Essays on Economic Decisions Under Uncertainty, New York: Cambridge University Press, 1987).
Gilboa, I., Samet, D. and Schmeidler, D. (2004) ‘Utilitarian aggregation of beliefs and tastes’, Journal of Political Economy 112: 932–938.
Gruber, J. (1998) Health insurance and the labor market, NBER working paper no. 6762, pp. 86.
Harsanyi, J.C. (1953) ‘Cardinal utility in welfare economics and in the theory of risk taking’, Journal of Political Economy 61: 434–435.
Harsanyi, J.C. (1955) ‘Cardinal welfare, individualistic ethics, and interpersonal comparisons of utility’, Journal of Political Economy 63: 309–321.
Hendel, I. and Lizzeri, A. (2003) ‘The role of commitment in dynamic contracts: Evidence from life insurance’, Quarterly Journal of Economics 118(1): 299–327.
Hirshleifer, J. (1971) ‘The private and social value of information and the reward to inventive activity’, American Economic Review 61: 561–574.
Hoy, M. (1982) ‘Categorizing risk in the insurance industry’, Quarterly Journal of Economics 97(2): 321–336.
Hoy, M. (1984) ‘The impact of imperfectly categorizing risk on income inequality and social welfare’, Canadian Journal of Economics 17(3): 557–568.
Hoy, M. (1989) ‘The value of screening mechanisms under alternative insurance possibilities’, Journal of Public Economics 39: 177–206.
Hoy, M. (2005) Risk classification and social welfare, discussion paper no. 2005-8, Department of Economics, University of Guelph.
Hoy, M. and Lambert, P.J. (2000) ‘Genetic screening and price discrimination in insurance markets’, The Geneva Papers on Risk and Insurance Theory 25: 103–130.
Hoy, M., Orsi, F., Eisinger, F. and Moatti, J.P. (2003) ‘The impact of genetic testing on health care insurance’, The Geneva Papers on Risk and Insurance: Issues and Practice 28(2): 203–221.
Hoy, M. and Polborn, M. (2000) ‘The value of genetic information in the life insurance market’, Journal of Public Economics 78: 235–252.
Hoy, M. and Ruse, M. (2005) ‘Regulating genetic information in insurance markets’, Risk Management and Insurance Review 8(2): 211–237.
Hoy, M. and Witt, J. (2005) Welfare effects of banning genetic information in the life insurance market: The case of BRCA1/2 genes, discussion paper no. 2005-5, Department of Economics, University of Guelph.
Hylland, A. and Zeckhauser, R.J. (1979) ‘The impossibility of Bayesian group decision making with separate aggregation of beliefs and values’, Econometrica 47: 1321–1336.
Kitcher, P. (1996) The Lives to Come: The Genetic Revolution and Human Possibilities, New York: Simon and Schuster.
Knoppers, B., Godard, B. and Joly, Y. (2004) ‘Life insurance and genetics: A comparative, international overview”, in M. Rothstein (ed) Genetics and Life Insurance: Medical Underwriting and Social Policy, Cambridge, MA: MIT Press.
Lemmens, T. (2000) ‘Selective justice, genetic discrimination, and insurance: Should we single out genes in our laws?’, McGill Law Journal 45(2): 347–412.
Ligon, J.A. and Thistle, P.D. (1996) ‘Consumer risk perceptions and information in insurance markets with adverse selection’, The Geneva Papers on Risk and Insurance Theory 21: 191–200.
Macdonald, A. (2000) ‘Human genetics and insurance issues”, in I. Torrance (ed) Bio-ethics for the New Millenium, Edinburgh: St. Andrews Press.
Mirlees, J.A. (1971) ‘An exploration in the theory of optimum income taxation’, Review of Economic Studies 38: 175–208.
Mongin, P. (1995) ‘Consistent Bayesian aggregation’, Journal of Economic Theory 66: 313–336.
Miyazaki, H. (1977) ‘The rat race and internal labor markets’, Bell Journal of Economics 8: 394–418.
Ni, X. (2001) The value of the genetic test of Huntington's disease in life insurance markets, Master's Research Project, unpublished, University of Guelph.
Pauly, M.V., Kunreuther, H. and Hirth, R. (1995) ‘Guaranteed renewability in insurance’, Journal of Risk and Uncertainty 10(2): 143–156.
Pauly, M.V., Nickel, A. and Kunreuther, H. (1998) ‘Guaranteed renewability with group insurance’, Journal of Risk and Uncertainty 16(3): 211–221.
Pauly, M.V., Withers, K.H., Subramanian-Viswana, K., Lemaire, J. and Hershey, J.C. (2003) Price elasticity of demand for term life insurance and adverse selection, NBER working paper no. 9925, Cambridge, MA.
Polborn, M., Hoy, M. and Sadanand, A. (2006) ‘Advantageous effects of regulatory adverse selection in the insurance market’, Economic Journal 116: 327–354.
Rea, S.A. (1992) ‘Insurance classifications and social welfare’, in G. Dionne (ed) Contributions to Insurance Economics, Boston, Dordrecht and London: Kluwer Academic Publishers, pp. 377–396.
Riley, J.G. (1979) ‘Informational equilibria’, Econometrica 47: 331–359.
Riley, J.G. (1983) ‘Adverse selection and statistical discrimination: Further comments’, Journal of Public Economics 20: 131–137.
Rochet, J.-C. (1989) ‘Incentives, redistribution and social insurance’, The Geneva Papers of Risk and Insurance Theory 16: 143–165.
Rothschild, M. and Stiglitz, J. (1976) ‘Equilibrium in competitive insurance markets: An essay on the economics of imperfect information’, Quarterly Journal of Economics 90(4): 630–649.
Rothschild, M. and Stiglitz, J. (1997) ‘Competition and insurance twenty years later’, The Geneva Papers on Risk and Insurance Theory 22: 73–79.
Sen, A.K. (1970) Collective Choice and Social Welfare, San Francisco, CA: Holden-Day Inc.
Shorrocks, A.F. and Foster, J.E. (1987) ‘Transfer sensitive inequality measures’, Review of Economic Studies 54(3): 485–497.
Smart, M. (2000) ‘Competitive insurance markets with two unobservables’, International Economic Review 41: 153–169.
Spence, M. (1978) ‘Product differentiation and performance in insurance markets’, Journal of Public Economics 10: 427–447.
Stiglitz, J.E. (2000) ‘The contributions of the economics of information to twentieth century economics’, Quarterly Journal of Economics 115(4): 1441–1478.
Strohmenger, R. and Wambach, A. (2000) ‘Adverse selection and categorical discrimination in the health insurance markets: The effects of genetic tests’, Journal of Health Economics 19: 197–218.
Tabarrok, A. (1994) ‘Genetic testing: An economic and Contractarian analysis’, Journal of Health Economics 13: 75–81.
Villeneuve, B. (2000) ‘Life insurance’, in G. Dionne (ed) Handbook of Insurance, Boston, Dordrecht and London: Kluwer Academic Publishers, pp. 901–931.
Villeneuve, B. (2003) ‘Mandatory pensions and the intensity of adverse selection in life insurance markets’, Journal of Risk and Insurance 70: 527–548.
Wagstaff, A., van Doorslaer, E., van der Burg, H., Calonge, S., Christiansen, T., Citoni, G., Gerdtham, U.G., Gerfin, M., Gross, L., Hakinnen, U., Johnson, P., John, J., Klavus, J., Lachaud, C., Lauritsen, J., Leu, R., Nolan, B., Peran, E., Pereira, J., Propper, C., Puffer, F., Rochaix, L., Rodriguez, M., Schellhorn, M. and Winkelhake, O. (1999) ‘Equity in the finance of health care: Some further international comparisons’, Journal of Health Economics 18(3): 263–290.
Wambach, A. (2000) ‘Introducing heterogeneity in the Rothschild–Stiglitz model’, Journal of Risk and Insurance 67: 579–592.
Wilson, C. (1977) ‘A model of insurance with incomplete information’, Journal of Economic Theory 16: 167–207.
Woodfield, A.E. (1994) ‘Insurance pricing and anti-discrimination legislation’, Agenda 1(2): 197–204.
Woodfield, A.E. (2000) ‘Preventing insurance markets from separating into gender-dominated-price-coverage combinations’, New Zealand Economic Papers 34(2): 243–268.
Acknowledgements
I thank all the participants of this seminar for stimulating discussion of this topic and especially Reimund Schwarze for his comments and superb organizational work. Mattias Polborn, Ray Rees, and two referees also provided very useful comments. For financial support while working on this paper, I owe a debt of gratitude to SSHRC and the Research School of Social Sciences (Economics Program) of the Australian National University.
Author information
Authors and Affiliations
Additional information
Prepared for the 11th Joint Seminar of the European Association of Law and Economics (EALE) and the Geneva Association (GA), June 2005, Berlin, Germany.
For example, Rea (1992); Dionne et al. (2000); and Crocker and Snow (2000).
Appendix A
Appendix A
Proof of Proposition 1:
-
Since at the value q H =0 it follows that EUAB=EUD, the proposition is proved if it can be shown that dEUD/dq H >dEUAB/dq H . From Equation (4), it follows that:
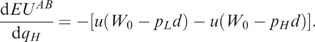
First substituting q L =1−q H and noting dp A /dq H =(p H −p L ), we have from Equation (5) that
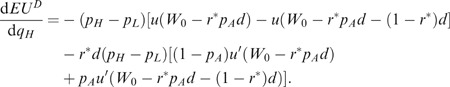
Evaluating these two derivatives at q H =0, noting that the level of q H has no effect on dEUAB/dq H and that (W 0 −r*p A d)=(W 0 −r*p A d−(1−r*)d) at q H =0 (since r*=1), it follows that the first term of dEUD/dq H becomes zero and we obtain

Thus, our result that dEUD/dq H >dEUAB/dq H follows if and only if −d(p H −p L )u′(W0−p A d)>−[u(W0−p L d)−u(W0−p H d)] when evaluated at q H =0.
Noting that p A =p L at q H =0 and letting W1=W0−p L d, W2=W0−p H d, so that W1−W2=d(p H −p L ), we have that the above inequality holds if and only if
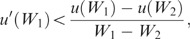
which holds since W1>W2 and u(.) is a strictly concave function.
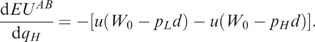
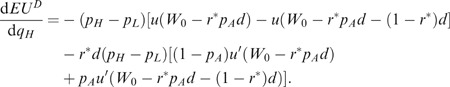

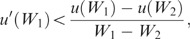
Proof of Proposition 2.
-
It is obvious that EUD is unaffected by changes in q H and p H that leave p A unchanged, and so we just need to show that dEUAB/dq H >0 when p H =k/q H . From Equation (4) we have, given p H =k/q H

which upon substituting back for p H =k/q H gives

Thus, dEUAB/dq H >0 if p H du′(W0−p H d)>u(W0−p L d)−u(W0−p H d).
The above inequality is implied by concavity of u(.) through the following relationship:
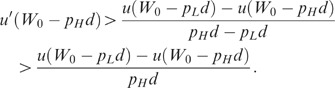


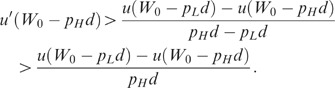
Rights and permissions
About this article
Cite this article
Hoy, M. Risk Classification and Social Welfare. Geneva Pap Risk Insur Issues Pract 31, 245–269 (2006). https://doi.org/10.1057/palgrave.gpp.2510079
Published:
Issue Date:
DOI: https://doi.org/10.1057/palgrave.gpp.2510079