 Yan Cai
Yan Cai Dongbo Tu
Dongbo Tu Shuliang Ding2*
Shuliang Ding2*- 1School of Psychology, Jiangxi Normal University, Nanchang, China
- 2School of Computer and Information Engineering, Jiangxi Normal University, Nanchang, China
The design of test Q matrix can directly influence the classification accuracy of a cognitive diagnostic assessment. In this paper, we focus on Q matrix design when attribute hierarchies are known prior to test development. A complete Q matrix design is proposed and theorems are presented to demonstrate that it is a necessary and sufficient condition to guarantee the identifiability of ideal response patterns. A simulation study is also conducted to detect the effects of the proposed design on a family of conjunctive diagnostic models. The results revealed that the proposed Q matrix design is the key condition for guaranteeing classification accuracy. When only one type of item pattern in R matrix is missing from the associated test Q matrix, the related attribute-wise agreement rate will decrease dramatically. When the entire R matrix is missing, both the pattern-wise and attribute-wise agreement rates will decrease sharply. This indicates that the proposed procedures for complete Q matrix design with attribute hierarchies can serve as guidelines for test blueprint development prior to item writing in a cognitive diagnostic assessment.
Introduction
The purpose of a diagnostic assessment is to detect the presence or absence of multiple fine-grained skills based on the observed response data to a set of test questions. Motivated by the No Child Left Behind Act of 2001 (Law, 2002), most developments and applications of diagnostic assessments have occurred in educational contexts, in which the assessments aim to provide students with information regarding whether or not they have mastered each skill in a group of specific skills, which are often generically referred to as attributes. Attributes may function independently (Tatsuoka and Boodoo, 2000), or they can be hierarchically related, meaning the mastery of a certain attribute is a prerequisite to the mastery of another one, therefore dependent (Vosniadou and Brewer, 1992; Kuhn, 2001). The Q matrix, which specifies the attributes measured by each test question, is an important element in a diagnostic assessment, because it is the foundation for a group of statistical models with different assumptions regarding how attributes influence test performance. These models are typically referred to as cognitive diagnostic models (CDMs) or diagnostic classification models (DCM). Such models include the rule space model (RSM; Tatsuoka, 1985), attribute hierarchy methods (AHM; Leighton et al., 2004) and Deterministic Input, Noisy “And” gate (DINA; Junker and Sijtsma, 2001) etc.
The test Q matrix is a linkage between test items and measured attributes, the element qij = 1 or 0 indicates that the jth attribute is or not is measured by the ith item respectively. The design of a Q matrix plays an important role in a cognitive diagnostic assessment, because it can directly influence the classification accuracy of a CDM. When attributes are independent, the Q matrix design has been investigated from both theoretical and empirical aspects in the literature. One common conclusion from previous studies is that it is important for a Q matrix to contain items that only measure a single attribute, implying that it contains an identity matrix as a sub-matrix. Such a Q matrix was first defined as a complete Q matrix by Chiu et al. (2009), and was later shown to be an important condition for guaranteeing model identifiability for a family of restricted latent class models (Chen et al., 2015; Xu and Zhang, 2016; Xu, 2017) and a condition guaranteeing a consistent nonparametric estimator (Wang and Douglas, 2015). The completeness of Q matrix was also empirically shown to increase classification accuracy according to several simulation studies (e.g., DeCarlo, 2011; Madison and Bradshaw, 2015).
When attributes are hierarchically related to each other, there are two different opinions regarding the Q matrix design. On one hand, several studies have assumed that the item-attribute structure does not necessarily follow the specified attribute hierarchy, and have utilized the unstructured/independent Q matrix design (De La Torre et al., 2010; Templin and Bradshaw, 2014; Liu et al., 2016). Such an assumption is convenient when the test Q matrix is developed following test administration or when the item can be assumed to measure the higher level attribute without measuring the lower level attribute. In such case, the complete test Q matrix can be obtained by including items that measure each attribute individually, and the importance of such a design is addressed above.
On the other hand, another group of researchers believe the items represented by the test Q matrix should reflect the specified attribute hierarchy, because they represent the attribute blueprint or cognitive specifications for test construction (e.g., Leighton et al., 2004; Tatsuoka, 2009). The Q matrix design under this assumption implies that if an item measures one attribute then it should also measure all of its prerequisites. In other words, there should be less than or equal to (2K −1) types (K is the number of attributes) of item attribute profiles, where all q-vectors not matching the attribute hierarchy are deleted from the Q-matrix (Tatsuoka, 1990, 2009; Leighton et al., 2004). For example, if attribute A1 is the prerequisite of attribute A2, then the item q-vector (01) should be deleted from the Q-matrix. Hereafter, such a Q matrix is referred to as a restricted Q matrix which does not necessarily contain R matrix. Many real examples of restricted Q matrices can in diagnosis assessments from fraction subtraction (Tatsuoka, 1990; De La Torre, 2011; de la Torre et al., 2016;), mathematicals learning (Tatsuoka, 1990; Leighton and Gierl, 2007), critical reading (Wang and Gierl, 2011), syllogistic reasoning (Leighton et al., 2004) etc. If a diagnostic assessment is developed based on a restricted Q matrix, then a natural question is how to ensure its identity. This was the main motivation for our study.
This paper investigates the completeness of restricted Q matrix when the attribute hierarchy is specified. In restricted Q matrix design, including an identity matrix is not feasible because the items measuring the higher level attributes will also measure those in the lower level when the attributes are dependent. This means that the condition of completeness in unstructured Q matrix design cannot be satisfied, because the Q matrix cannot contain an identity matrix. Therefore, it is important to investigate the completeness condition for restricted Q matrix design to guarantee accurate classification results.
In this paper, we define a complete restricted Q matrix design based on R matrix and discuss its corresponding statistical properties. We demonstrate that the completeness of the restricted Q matrix is a key condition to guarantee classification accuracy when the analysis is combined with a family of conjunctive CDMs. Simulation studies also reveal the importance of R matrix in classification accuracy. The proposed design is easy to implement and can serve as the blueprint for a cognitive diagnostic assessment prior to item writing. The remainder of this paper is organized as follows. Section 2 outlines useful elements in a cognitive diagnostic assessment. Section 3 introduces several important incidence matrices and discusses their corresponding statistical properties. This is followed by the definition of a complete restricted Q matrix and our main theorems regarding its statistical properties in Section The complete restricted Q matrix design. The procedures for constructing a complete Q matrix are introduced in Section The restricted Q matrix design. The importance of such a complete Q matrix design for the classification accuracy of a family of conjunctive models is illustrated through several simulation studies in Section Numerical Examples. Experimental result are limited to the simulation study.
Attribute Hierarchies and Conjunctive CDMs
Attribute Hierarchies
The terminology of attributes was first proposed by Tatsuoka (1990) as “production rules, procedural operations, item types, or more generally any cognitive tasks.” In educational context, this term generally refers to any knowledge or cognitive processing skills required to solve test problems (e.g., Leighton et al., 2004; Tatsuoka, 2009). Attributes can be identified and studied using methods from cognitive psychology, such as item reviews and protocol analysis (Leighton et al., 2004). In a diagnostic assessment, the attribute profile for each subject is denoted by a vector of binary latent variables representing mastery of a finite set of attributes. Suppose there are N examinees and K attributes, we define the ith examinee's attribute profile as , where to indicate the absence or presence of the kth attribute for the ith examinee. The attribute hierarchies refer to situations in which the mastery of a certain attribute is a prerequisite to the mastery of another attribute. Figure 1 presents four types of attribute structures. The linear attribute hierarchy (Figure 1A) requires all attributes to be ordered sequentially, and implies that if attribute 1 is not present, then all following attributes will not be present. The convergent structure (Figure 1B), represents a hierarchy with a convergence branch where two different paths maybe traced from attribute 1 to attribute 3 and 4. Note that in this structure, one attribute can be a prerequisite of multiple different attributes and an attribute can have many different prerequisites. The divergent attribute hierarchy (Figure 1C), refers to different distinct tracks originating from the same single attribute. The independent structure (Figure 1D) can be viewed as a specific case of attribute hierarchy. Note that independence in this sense is not the same as statistical independence. Although no attribute is a prerequisite for another, the indicators of attribute mastery may be correlated.
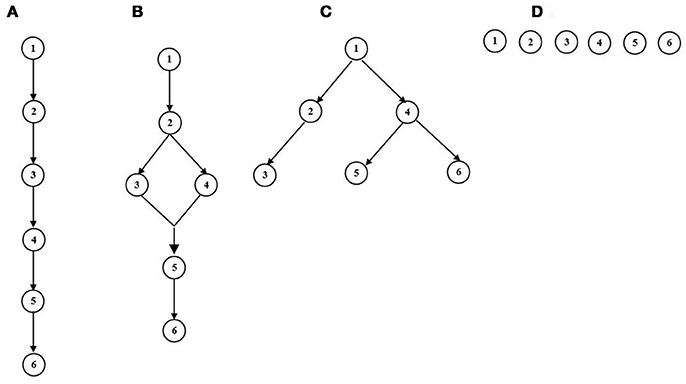
Figure 1. Four types of Attribute Structures. (A) Linear. (B) Convergent. (C) Divergent. (D) Independent.
Conjunctive Cognitive Diagnostic Models
A rich development of CDMs has occurred over the past decade. Traditional categories for CDMs are based on different assumptions regarding how attributes influence test performance. Most recently, several general models based on different link functions (e.g., Davier, 2008; Henson et al., 2009; De La Torre, 2011) have been developed to include many reduced CDMs. In this study, we focus on the restricted Q matrix design and combine with a conjunctive CDM to perform classification. Conjunctive CDMs assume that all attributes required by an item must be mastered to have high chance to provide the correct answer, which is a reasonable model for classification under certain attribute hierarchies. The combination of Q matrix and CDMs can be found in the application of a math test. For example, researchers have suggested that mathematical concepts are not independent segments, and there are learning sequences within the curriculum that fit the schema-constructing process of learners, which implies certain hierarchical attribute structures (Clements and Sarama, 2004). Usually, in math test, such a set of hierarchical skills are all required to perform well on given item (e.g., Tatsuoka, 1990), and an incorrect answer is highly likely to be provided even if a student is missing only one of the required attributes.
The rule space model (RSM; Tatsuoka, 1985) and attribute hierarchy methods (AHM; Leighton et al., 2004), as well as a family of restricted latent class models, including Deterministic Input, Noisy “And” gate model (DINA; Junker and Sijtsma, 2001), Noisy Input, Deterministic “And” gate model (NIDA; Maris, 1999), and Reparameterized Unified Model (Reduced RUM; Hartz and Roussos, 2008) have conjunctive assumptions. All these conjunctive models rely on the ideal response pattern, which indicates whether or not a subject with a specific attribute profile has mastered all the required attributes for each item, to determine the specific model structure. If we define the column as the item and the row as the attribute in the Q matrix, the ideal response pattern resulting from an attribute pattern α = (α1, α2, ⋯, αK)′ to a K × J Q matrix with elements qkj can be defined as
where .
The RSM and AHM perform classification based on the distance between their observed response pattern and the ideal response pattern. The RSM model first maps the observed and ideal response patterns into a two-dimensional space, then considers the points corresponding to the ideal response patterns as the kernels for each class. The remaining points corresponding to the observed response patterns are clustered into classes. The AHM model first treats each observed response pattern as a deviation from the ideal response patterns, then calculates the probabilities of deviations between the observed response pattern and each of the ideal response patterns. Finally, it classifies the examinee with the attribute profile that resulted in the largest deviation probability. Conjunctive restricted latent class models, such as the DINA, NIDA and reduced RUM models, define the probability of a correct response under the conjunctive assumption, but allow for slips and guesses in a manner that distinguishes the models from one another. For example, the DINA model is the simplest conjunctive model, where the item response function is entirely determined by ηj(Q, α). Therefore, there are only two types of correct response probabilities for each item under the DINA model in the item response function:
In contrast to the DINA model, the slipping and guessing parameters for the NIDA model are defined based on attribute levels. DefineHj = {k|qkj = 1}. Then, for the NIDA model,
The reduced RUM model can be generalized from the NIDA model with an item response function defined as
Preparations for Q Matrix Design
In this section, five types of matrices are introduced to describe three types of relationships: item vs. attribute, attribute vs. attribute, and examinee vs. attribute. The statistical properties associated with these matrices are discussed to provide a foundation for the proposed Q matrix in the next section. For ease of presentation, we assume that there are K attributes associated with J items and define columns as items and rows as attributes for the incidence matrix describing the relationships between items and attributes.
The Incidence Q Matrix and Test Q Matrix
The incidence Q matrix is defined as a K×(2K−1) matrix that contains items that probe all combinations of attributes when they are independent (Leighton et al., 2004). For example, when K = 4, the incidence Q matrix documents a total of 15(= 24−1) possible item types, excluding the type with all elements equal to zero. The test Q matrix is a K×J matrix, indicating which item measures which attribute in the designed test. Here, J is the number of test questions and it can be less than, equal to, or greater than 2K−1.
The Reachability Matrix
The reachability matrix (R matrix; Tatsuoka, 1986) is a K×K matrix that represents the direct and indirect relationships between attributes. The jth element of the ith row in the matrix represents whether attribute i is a direct or indirect prerequisite for attribute j. Therefore, the ith row of the R matrix specifies all the attributes, including the ith attribute, for which the ith attribute is a direct or indirect prerequisite. Based on the study by Tatsuoka (1986, 2009), the R matrix can be calculated from (A + I)n, where n is the integer required for R to reach invariance, A is the adjacency matrix, which is a K×K binary matrix that specifies the direct relationships between attributes, and I is an identity matrix. The R matrix for the divergent attribute hierarchy is presented in Figure 2.
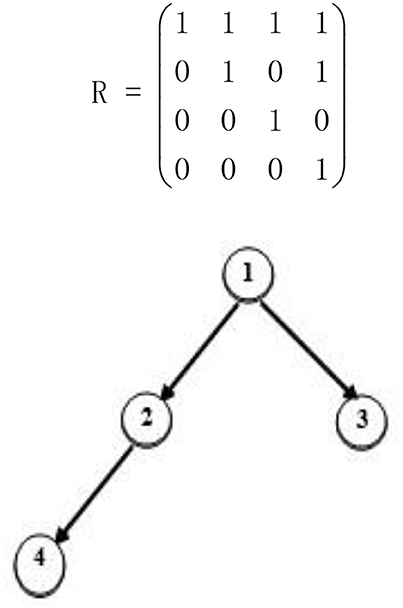
Figure 2. A divergent attribute hierarchy.
For this R matrix, row one indicates that attribute 1 is a prerequisite to all attributes and row two indicates that attribute 2 is a prerequisite for attribute 2 and 4. The rest of the matrix can be interpreted in the same manner. Let rij denote the (i, j) elements in the R matrix, where the jth column of the R matrix is denoted . It is clear that
for k = 1, 2, ⋯ , K. To simplify our notation, we always label the attributes from the lowest level to the highest level utilizing an ascending sequence ranging from 1 to K. Therefore, the R matrix is an upper-triangular matrix in our scheme.
Reduced Q Matrix
The Reduced Q matrix (Leighton et al., 2004), denoted Qr, is obtained by removing the items (columns) that do not satisfy the specified hierarchical structure from the incidence Q matrix. In other words, the Qr matrix contains all possible item types under the specified hierarchical structure. The Qr matrix for Figure 2 can be written as follows:
Note that there were 24−1 = 15 columns in the incidence Q matrix when the attributes were independent. By removing the seven columns that represented the seven item types not satisfying the attribute hierarchy in Figure 2, we can derive the above Qr matrix.
The Permissible Attribute Profile Matrix
The previously presented matrices defined two types of relationships: relationships between attributes and the relationships between items and attributes. The next type of matrix defines the relationships between examinees and attributes. We first define a permissible attribute pattern as an attribute pattern that satisfies the specified attribute hierarchy. The permissible attribute profile matrix M is a matrix that is formed with all permissible attribute patterns as columns. The M matrix can be obtained by adding a column vector of zeros to the Qr matrix. Specifically, , where . The M matrix defined based on Figure 2 is
Note that although the M matrix can be constructed from the Qr matrix, these two matrices represent different explanations. Each column of the M matrix represents a permissible attribute pattern, whereas each column of the Qr matrix represents an item that satisfies the specified attribute hierarchy (correspondingly, a permissible item type). M defines a permissible attribute profile space. We utilize the notation α ∈ M to indicate that α belongs to one of the column vectors of M.
Propositions
In this subsection, several propositions that serve as foundations for the main theorems in the next section are introduced.
Proposition 1
Each column of the R matrix represents an item that satisfies the specified hierarchical structure.
Proposition 1 is a restatement of Lemma 2 from the paper by Yang et al. (2008). Its proof is presented in the Appendix (Supplementary Material). This proposition implies that the R matrix can still be reviewed as an incidence matrix that denotes the relationships between items and attributes, although it was originally defined as the relationships between attributes. Leighton et al. (2004) stated that “the R matrix is used to create a subset of items that is conditioned on the structure of the attribute hierarchy.”
The next proposition reveals the relationships between the R matrix and Qr matrix.
Proposition 2
The R matrix is a sub-matrix of the Qr matrix. That is to say, the R matrix corresponding to a specified attribute hierarchy can be obtained by removing certain columns from the Qr matrix.
Proof. Proposition 2 can be easily proved by Proposition 1 and the definition of the Qr matrix from Section The incidence Q matrix and test Q matrix.
The next proposition depends on the definition of Boolean operations (Davey and Priestley, 1990; Tatsuoka, 1991), where the multiplications and additions are defined as follows:
We further define the addition and multiplication of two vectors by performing element-wise addition and multiplication of the corresponding elements in the vectors. For example,
Hereafter, the additions and multiplications for any vectors in different incidence matrices (R, Qr, and M) follow the above definitions and rules.
Proposition 3
Let S represent a hierarchical structure for K attributes, where R = (r1, ⋯ , rK) is the corresponding reachability matrix and ri, i = 1, 2, ⋯ , K represents the ith column of the R matrix. Suppose that with bi ∈ {0, 1} is a column of the Qr matrix. Then, .
Proposition 3 is a restatement of Theorem 1 from the paper by Yang et al. (2008). Its proof is presented in the Appendix (Supplementary Material). Let qr = (1, 0, 1, 0)′ be the third column of Qr for the attribute hierarchy specified in Figure 2. Then,
The above proposition and example indicate that any column of Qr, denoted qr, can be written as a positive linear combination of one or more (≥1) columns from the corresponding R matrix, (note that we reorder these columns from 1 to l, not necessarily corresponding to their positions in the R matrix. Specifically, qr+ri=qr, i = 1, 2, ⋯ , l, meaning any attributes measured by ri are a subset of the attributes measured by qr, which can be written as
.
The Complete Restricted Q Matrix Design
From our review in Section Attribute Hierarchies and Conjunctive CDMs, we determined that ideal response patterns play an important role in conjunctive CDM frameworks. It is important for the designed Q matrix to identify different ideal response patterns. Any two different attribute patterns α1 ≠ α2 will result in different ideal response patterns η(Q, α1) ≠ η(Q, α2). To achieve this goal, we define a complete Q matrix and theoretically demonstrate that this is a necessary and sufficient condition to guarantee the identifiability of an ideal response pattern. Completeness is discussed for the case of a restricted Q matrix design and we formally introduce the definition of a restricted Q matrix design below.
Definition 1. A restricted Q matrix is defined such that any item in it satisfies the specified attribute hierarchy. In other words, each column of the Q matrix is one of the columns of the Qr matrix.
For the divergent attribute hierarchy specified in Figure 2, according Definition 1, Q1 is a restricted Q matrix and Q2 is an unrestricted Q matrix because items two through four violate the specified attribute structure.
Completeness
Definition 2. A restricted Q matrix, denoted Qc, is said to be complete if it satisfies the following condition:
Condition (I). The R matrix is a sub-matrix of the Q matrix, where the restricted Q matrix takes the following form:
where Qrest is formed from the columns Qr.
Remark 1. Definition 2 is equivalent to Definition 1 in the paper by Xu and Zhang (2016) when attributes are independent.
Continuing the example from Figure 2, under the restricted Q matrix design, the Q1 matrix defined above is complete, where the Q3 matrix defined below is incomplete because the fourth column of the corresponding R matrix (1, 1, 0, 1)′ is not contained in Q3. If Q3 is utilized as the test Q matrix, then the examinee with the attribute profile α1 = (1, 1, 0, 1)′ cannot be distinguished from the examinee with the attribute profile α2 = (1, 1, 0, 0)′ because the two have the same ideal response pattern (1, 1, 0, 1, 0).
Properties of R Matrix
In this section, we provide various properties to prove the completeness of Q matrix defined above.
Lemma 1. Suppose that rj(j = 1, ⋯ , K) is the jth column vector of the R matrix. Then, it holds thatrj◦R = rj.
Lemma 1 implies that the ideal response pattern of an individual with a knowledge state rj in R matrix is still rj. This result can be easily obtained from the definition of α◦Q. According to the definition of an R matrix, the following Lemmas 2 and 3 can also be easily obtained.
Lemma 2. Suppose that rj is the jth column vector of the R matrix and that it contains at least two non-zero entries. Then, it satisfies
(1) rjj = 1, and there exists some i satisfying rij = 1, where attribute i is a prerequisite of attribute j.
(2) All the prerequisites of the attribute i are the prerequisites of attribute j.
(3) All the entries in the rj−ri vector are nonnegative. In this paper, ri ≤ rj is utilized to represent this type of relationship.
Lemma 3. Suppose that attribute i is the only direct prerequisite of attribute j. Then, ri ≤ rj and , which indicates that ri and rj only differ in their jth entry and rij = 0, rjj = 1.
Denote and let denote an altered matrix where the jth column of the R matrix is replaced by some q column vector from the matrix.
Lemma 3. Suppose that attribute i is the only direct prerequisite of attribute j. Then, ri and rj satisfy .
According to Lemma 1, it holds thatrj◦R = rj,ri◦R = ri. Because R and only differ in the jth column and ri and rj only differ in the jth entry according to Lemma 2, and could at most differ in the jth entry, which is determined by ri◦q and rj◦q, respectively. According to the definition of α◦Q, ri◦q = rj◦q = 0 is satisfied, which proves Lemma 3.
Lemma 4. Suppose that there at least two direct prerequisites of attribute j, denoted i1, i2, ⋯ , ik(k ≥ 2). Then, a vector p can be obtained by , which satisfies .
According Lemma 2, for any l, it holds that ril ≤ rj. Therefore, p ≤ rj. The relationships between attribute j and all its prerequisites are reflected in ril for all l, meaning they are also reflected in p and . This indicates that p only differs fromrj in the jth entry. According to Lemma 3, it can concluded that . Together, Lemmas 3 and 4 imply that for any rj, one could find another knowledge state α such that their ideal response patterns to are the same. Additionally, α ≤ rj, and α and rj only differ in their jth entry (i.e., aj = 0, rjj = 1).
Main Theorems
In this section, we provide theorems to prove that the complete restricted Q matrix defined above can identify any pair of different attribute profiles based on an ideal response pattern.
Theorem 1
For any two different attributes profiles α1, α2 ∈ M, η(R, α1) ≠ η(R, α2), where η(R, α) = α◦R.
Theorem 1 implies that the R matrix can be viewed as a complete Q matrix itself. As discussed in Proposition 1, we indicate that any column of the R matrix can be treated as a reasonable item type under the specified attribute hierarchy. This theorem also reveals the importance of including the R matrix in a restricted Q matrix because it is a sufficient condition to identify two distinct ideal response patterns. The next theorem demonstrates that including the R matrix in the restricted Q matrix design is not only a sufficient condition, but also a necessary condition for the identifiability of an ideal response pattern.
Theorem 2
Denote the restricted Q matrix design as Qc. For any two different permissible attribute profiles, if and only if Qc is complete. That is to say, the R matrix is a sub-matrix of Qc.
When limiting to restricted Q matrix design, proposition 9 in the paper by Heller et al. (2015) is equivalent to the sufficiency of theorem 2. However it does not proof the necessity of identifiability, theorem 2 proved it. When attributes are independent, the R matrix becomes a K × K identity matrix and Theorem 2 follows from Lemma 1 in the paper by Chiu et al. (2009), which indicates that a complete restricted Q matrix must include an identity matrix. The completeness of the Q matrix is a very important condition for model identifiability, particularly for the family of conjunctive CDMs, where ideal response patterns play an important role in the model structure. The results regarding model identifiability for the DINA model (Xu and Zhang, 2016) can be easily generalized for attribute hierarchies by replacing the condition (C1) with the proposed Condition (I). In fact, when item parameters are known for the DINA model, the completeness of the Q matrix is equivalent to model identifiability.
The Restricted Q Matrix Design
Previous sections illustrated the importance of the R matrix in restricted Q matrix design. In general, a complete restricted Q matrix can be constructed by first creating an R matrix based on specified attribute hierarchy and then selecting a number of columns from the Qr matrix as additional item types for the Q matrix. However, it is difficult to derive the corresponding Qr matrix by removing columns that do not satisfy the specified attribute hierarchy from the incidence Q matrix when K is large. In this section, we introduce the augment algorithm proposed by Ding et al. (2008) and Yang et al. (2008), which can derive a Qr matrix from the corresponding R matrix. The convergence of this algorithm was proved by Proposition 3 in this paper and Theorem 3 in the paper by Yang et al. (2008).
The Augment Algorithm for Deriving a Qr Matrix
The augment algorithm for deriving a Qr matrix from the corresponding R matrix is presented below.
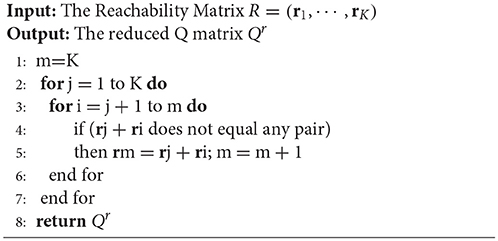
Algorithm 1 Augment Algorithm
Here, we provide an example to demonstrate how to construct a Qr matrix based on the attribute hierarchy in Figure 2. This process is illustrated in Figure 3. We first obtain the R matrix for this divergent structure, which forms the first four columns of the Qr matrix. Then, Boolean addition is applied between the first column and each of the remaining three columns. No new item types are produced during this procedure. Then, Boolean addition is applied between the second column and each of the remaining two columns. A new item type (1, 1, 1, 0)′ results from (1, 1, 0, 0)′+(1, 0, 1, 0)′, so we add this item type as a fifth column in the Qr matrix. Next, we apply Boolean addition between the third column and the fourth and fifth columns. This results in another new item type (1, 1, 1, 1)′, which is added as a sixth column in the Qr matrix. Finally, we determine that no new item types can be created by applying Boolean addition between the fourth column and the fifth and sixth columns. Therefore, we terminate the searching algorithm.
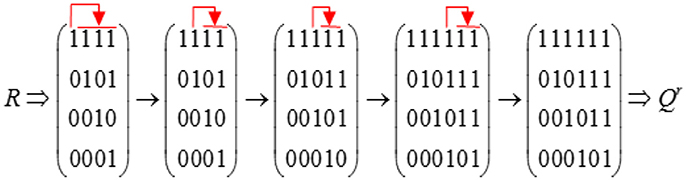
Figure 3. Example of constructing the Qr matrix based on the Augment Algorithm.
Procedures to Construct a Complete Test Q Matrix
If a conjunctive model is utilized to analyze data, we provide some suggestions regarding how to perform complete restricted Q matrix design prior to item creation. Suppose that there are K attributes associated with the blueprint for a test with J (≥K) items.
1. Create an R matrix from the corresponding attribute hierarchy.
2. Generate a Qr matrix by utilizing the augment algorithm.
3. Include the R matrix as the first K columns of the test Q matrix, then randomly select the remaining J–K (if > 0) columns from the columns of the Qr matrix (this step can be modified to select columns from the Qr matrix that satisfy the blueprint requirement).
Note that another important feature for Q matrix design is the number of items measuring the same attribute. This feature can be important in terms of model identifiability (Chen et al., 2015; Xu and Zhang, 2016; Xu, 2017). In future studies, we will investigate how to incorporate this feature into restricted Q matrix design.
Numerical Examples
Several numerical examples utilizing five conjunctive CDMs, namely the rule space model (RSM), attribute hierarchical model (AHM), and three conjunctive models (the DINA, NIDA, and reduced RUM model), are presented to demonstrate the important role of the R matrix in complete Q matrix construction and its impact on classification accuracy. These CDMs all depend on ideal response patterns for classification. In each of the following examples, four types of attribute structures, namely linear, convergent, divergent, and independent, involving the K = 6 attributes presented in Figure 1 are considered. The R matrices corresponding to the four structures are provided in the Appendix (Supplementary Material).
Simulation Conditions
Three types of Q matrix design are considered for each of the models. In the first type, the test Q matrix is generated by first including all item types in the corresponding R matrix, except one that is assumed to be missing, and then randomly selecting item types from the remaining columns of the corresponding Qr matrix. The second type of test Q matrix design is created by randomly choosing columns from, which is an extreme condition where we assume that the test Q matrix does not contain the entire R matrix. Note that only two types of structure, namely independent and divergent, are considered in this case because there will be no available item types for convergent or linear structures after removing the entire R matrix. The type of design, which is the proposed Q matrix design, is created by first including the entire R matrix and then randomly selecting columns from the corresponding Qr matrix to fill in the rest of items. The purpose of this test is to compare the classification accuracies of the three types of Q matrix design.
In each of the experimental conditions, to obtain more stable experimental results and decrease the impact of random errors, a sample size of N = 1,000 examinees is simulated. Because an attribute profile is a discrete variable, the examinee profiles were simulated based on a uniform distribution formed from all permissible attribute patterns in the different attribute hierarchies. The test length was fixed to 30 items across all conditions. For RSM and AHM, student response vectors were generated based on their ideal response patterns in such a manner that the probability for 1 → 0 and 0 → 1 in each of the ideal response patterns was 0.05. The minimum Mahalanobis distance method and Bayes decision rule proposed by Tatsuoka (2009) were utilized to estimate the attribute profiles for the RSM. For the AHM, the A method proposed by Leighton et al. (2004), was utilized to perform classification. For the three restricted latent class models, we first simulated the item parameters and then generated student responses based on the corresponding item response functions. Specifically, for the DINA model, the slipping parameters sj and guessing parameters gj were drawn from a uniform distribution ranging from 0.1 to 0.4, which means both the slipping and guessing parameters fall within the interval between 0.1 and 0.4, which represents average item quality. For the NIDA model, the guessing and slipping parameters for each attribute were simulated. The test Q matrices and examinee attribute profiles were kept constant across the 50 simulations under each experiment condition. The classification accuracies were calculated in terms of pattern-wise agreement rate (PAR) and attribute-wise agreement rate (AAR) to reflect the agreement between estimated attribute profiles and known true attribute profiles based on the average results of the 50 simulations. These two indexes are defined as
Results
The classification results for the five models when one column of the R matrix is missing from the test Q matrix are listed in Tables 1–5. One can observe consistent results for the five models. When only one column of the R matrix is missing from the test Q matrix, there is a relatively large decrease in the AAR of certain attributes, specifically those that are directly associated with the missing item type. For example, in the linear structure, if the item type (1, 1, 0, 0, 0, 0)′, which measures both attribute one and attribute two, is missing, then the two attribute patterns (1, 1, 0, 0, 0, 0)′ and (1, 0, 0, 0, 0, 0)′ will result in the same ideal response pattern. This leads to a decrease in the AAR for attribute two in this case because attribute two cannot be separated from attribute one during the classification procedure. Another observation is that the overall recovery of attribute patterns, which is represented by PAR, decreases across all conditions when one of the item types is missing from the test Q matrix. To better observe the trends in classification accuracy, we documented the average decreases in AAR and PAR across the six attributes and six missing item types when compared to the classification results from the test Q matrix containing all the item types in the R matrix in Figures 4, 5. The results reveal that the influence of a missing item on classification results are varies under different hierarchical structures. The linear structure has the largest average decrease in AAR across all five models, followed by the independent, convergent, and divergent structures. The trend is similar for PAR, with the exception of the convergent structure producing a larger decrease in PAR than the independent structure in most cases. Furthermore, the influence of a missing item on classification accuracy varies across the different models. The AHM showed the largest decrease in AAR and PAR for each structure, followed by the DINA model. The RSM and NIDA model provided similar performances. The reduced RUM showed the smallest decrease in AAR and PAR across all structures.
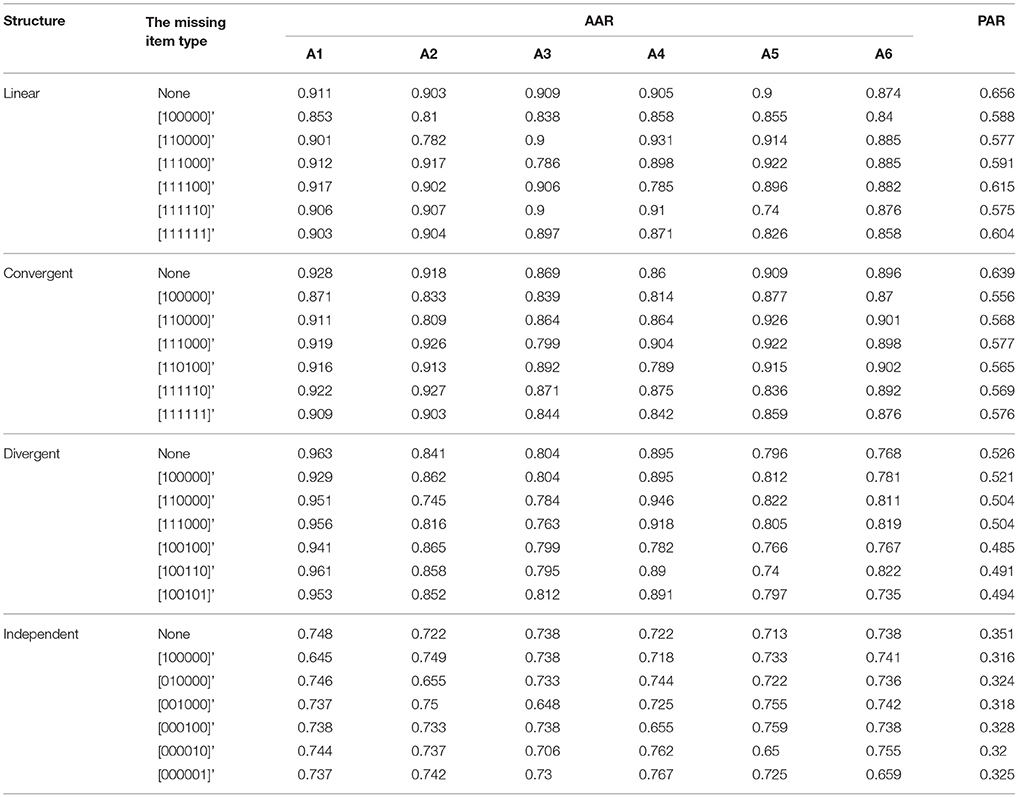
Table 1. The classification result for RSM when one column of R matrix missing in the test Q matrix.
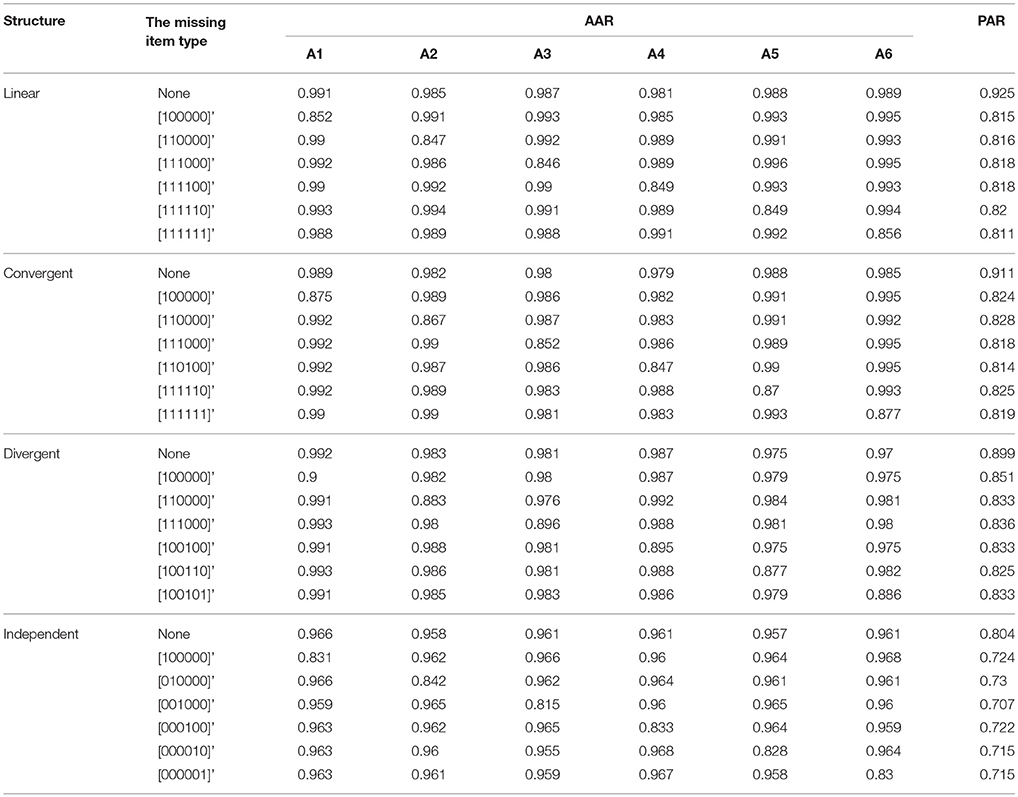
Table 2. The classification result for AHM when one column of R matrix missing in the test Q matrix.
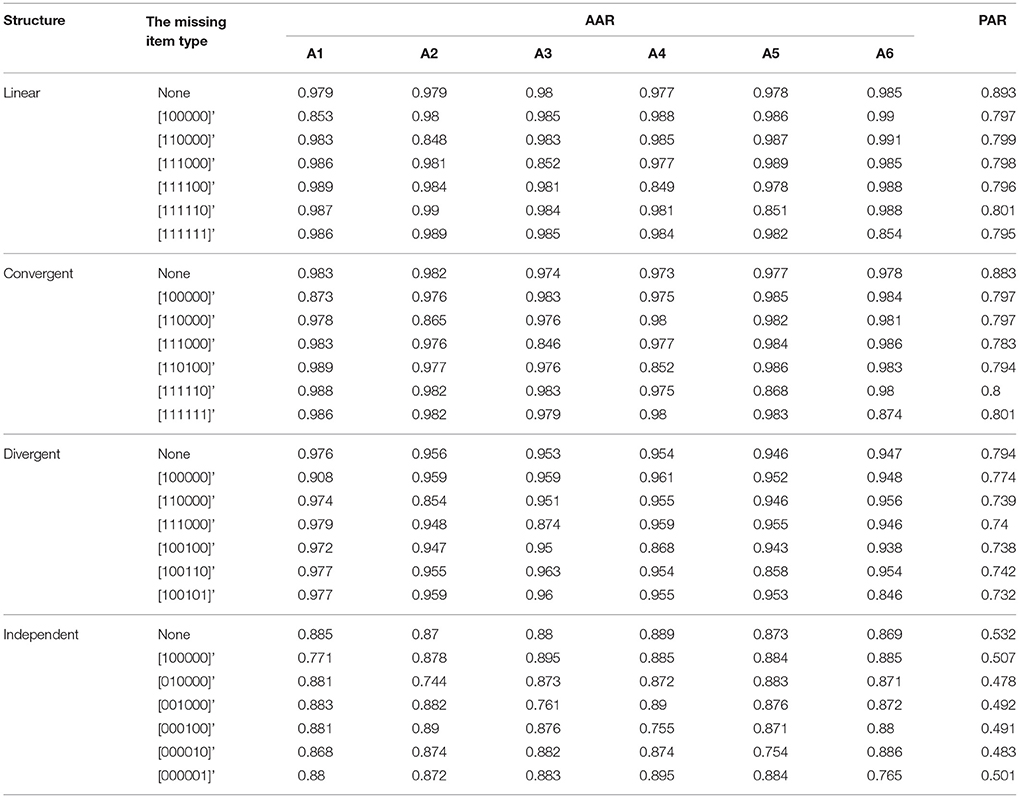
Table 3. The classification result for DINA when one column of R matrix missing in the test Q matrix.
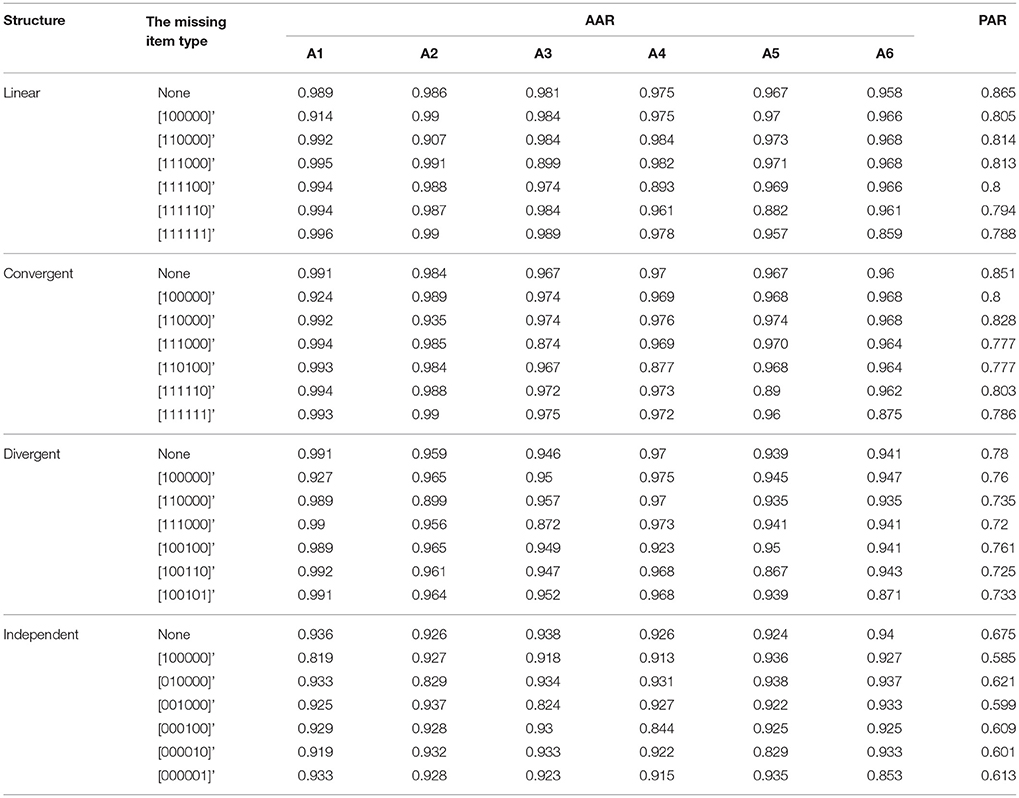
Table 4. The classification result for NIDA when one column of R matrix missing in the test Q matrix.
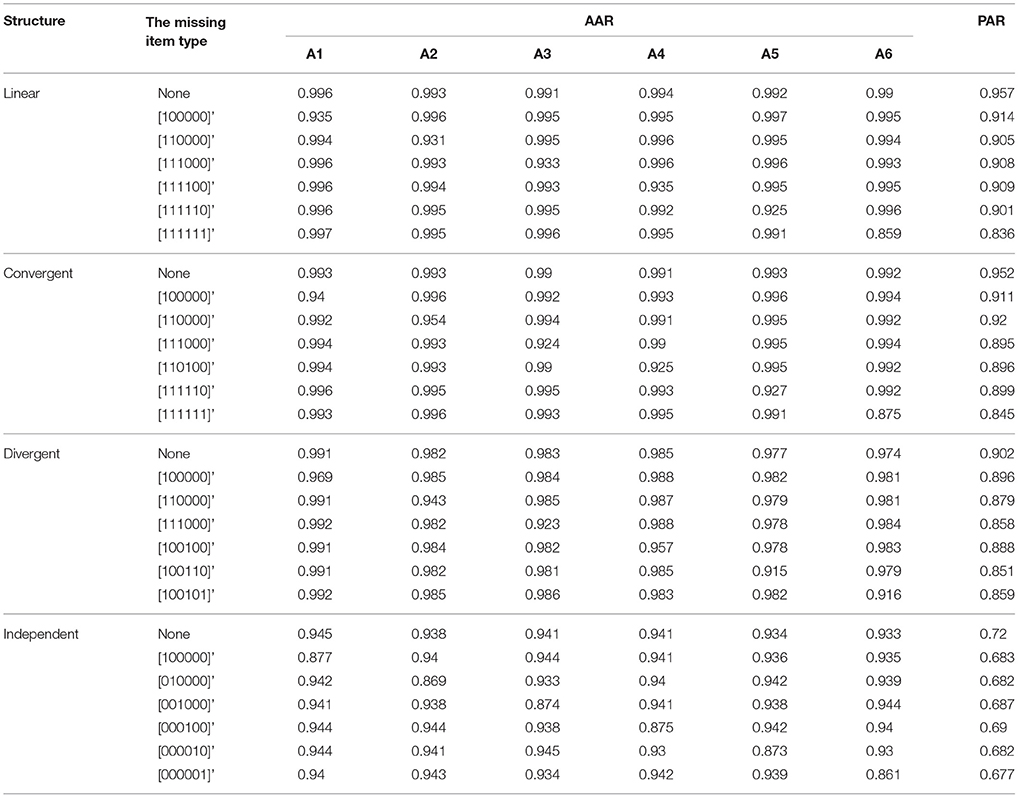
Table 5. The classification result for Reduced RUM when one column of R matrix missing in the test Q matrix.
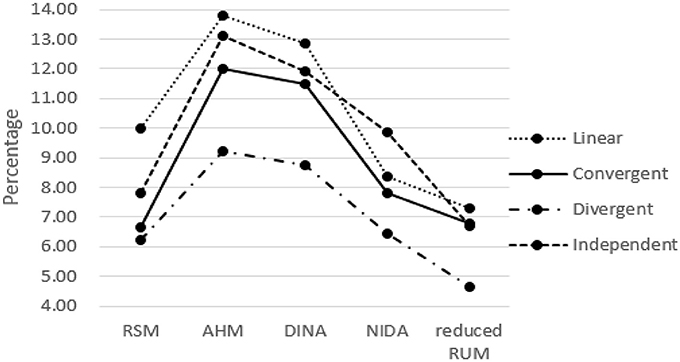
Figure 4. The Average Decrease of AAR when only one item type is missing.
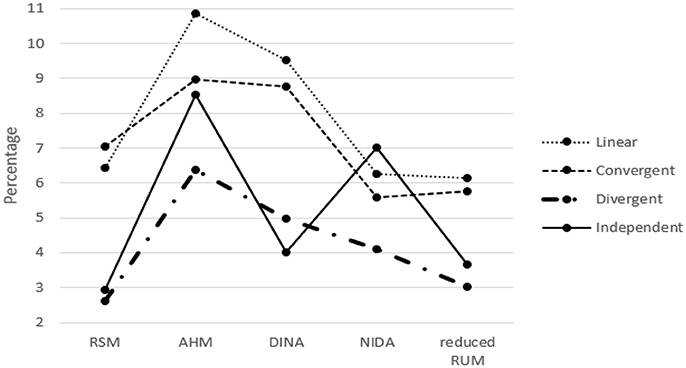
Figure 5. The Average Decrease of PAR when only one item type is missing.
The classification results of the five models when the entire R matrix is missing from the test Q matrix are listed in Table 6. One can observe a more obvious decrease in AAR and PAR in this extreme case. Specifically, when the entire R matrix is missing from the test Q matrix, compared to the results from the test Q matrix including the entire R matrix, the average decreases in AAR were at least 14.12% for DINA, 13.95% for AHM, 10% for RSM and NIDA, and 7.42% for reduced RUM. Regarding the attribute patterns, the decrease in PAR varied from 16.2 to 44.8% across the five models.
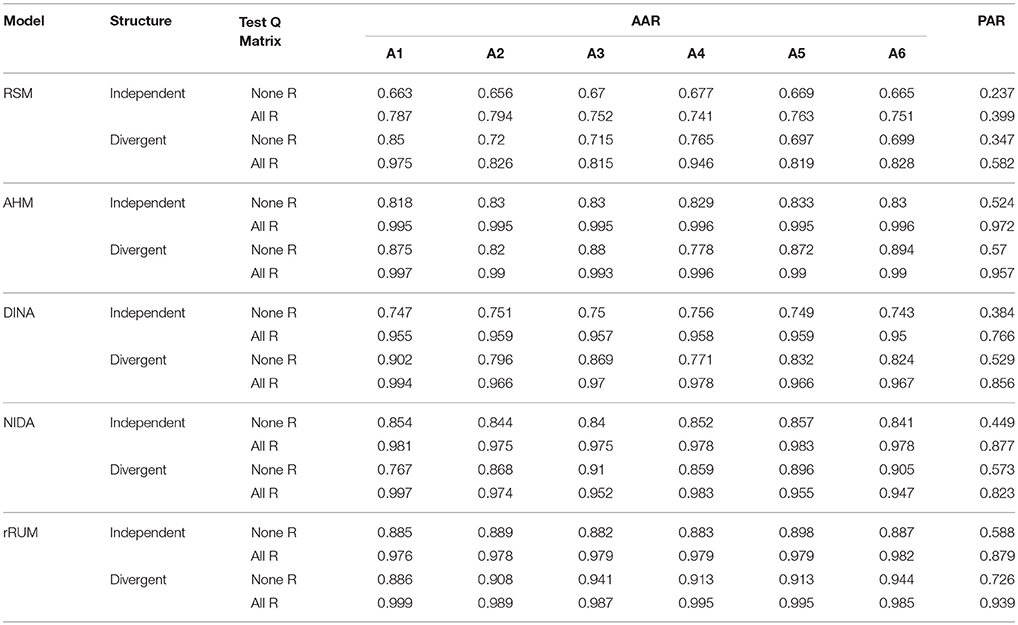
Table 6. Classification rates for five conjunctive models when test Q matrix does not contain the entire R matrix.
Additionally, to analyze the effects of the R matrix on classification, we also performed statistical significance testing based on PAR values to compute effect sizes. These results are provided in the Supplementary Material to avoid extending this article further.
Discussion
The effectiveness of applying Q-matrix-based CDMs to diagnostic assessments mainly depends on their statistical properties. One of the properties is statistical identifiability, which is the feasibility of recovering model parameters based on observed data. Identifiability is a prerequisite for model parameter estimation, which includes student class membership estimation. One of the sufficient and necessary conditions to guarantee identifiability when certain types of CDMs are utilized is the completeness of the Q matrix (Xu and Zhang, 2016; Xu, 2017). When attributes are independent, the concept of completeness of a Q matrix was first proposed by Chiu et al. (2009). Completeness means that a Q matrix can distinguish two different attribute vectors based on an ideal response pattern. The results of the above study indicate that the Q matrix must include an identity matrix to guarantee the separation of different ideal response patterns. This means that the diagnostic test must include items that only measure a single attribute to guarantee good classification results. However, in a situation where attributes are hieratically related to each other, where a certain attribute is a prerequisite for other attributes, including items that only measure a single attribute may not be feasible.
Identifiability is also discussed in the framework of knowledge space theory (KST) (Heller et al., 2015, 2016, 2017). There are two main differences between the above studies and our study: (1) our study focuses on cognitive diagnosis theory, whereas the above studies focused on KST; (2) our study is based on restricted Q matrix design. In many application studies (e.g., Tatsuoka, 1990, 2009; Leighton et al., 2004; Gierl, 2007, 2008; Wang and Gierl, 2011), Q matrix design was restricted. To address this concern, under the framework of CDMs, this study focused on identifiability based on unrestricted Q matrix design, where the test Q matrix represents a special attribute hierarchy structure (such as divergent, convergent, or linear structures) and if an item measures one attribute, then it should also measures all of its prerequisite attributes. Additionally, a simpler operational procedure for constructing an identifiable Q matrix was provided in a step-by-step manner to aid practitioners.
Based on the studies by Ding et al. (2008, 2012, 2016), we formally define a complete Q matrix design in a more general framework when an attribute hierarchy exits. The proposed complete Q matrix design can be easily constructed from an R matrix, which reflects the direct and indirect relationships between attributes. When attributes are independent, the proposed design is equivalent to that presented by Chiu et al. (2009). Such a Q matrix is an important condition for guaranteeing accurate classification results when combined with an attribute profile estimation approach utilizing conjunctive assumptions, such as the RSM, AHM, and a family of conjunctive restricted latent class models. The complete restricted Q matrix design is equivalent to the model identifiability condition for the DINA model when item parameters are known, which follows from the logic outlined by Xu and Zhang (2016).
Because completeness is only one of the important conditions for the identifiability of a Q-matrix-based CDM, a very important future research direction is to study additional conditions related to Q matrix design and discuss additional model identifiability conditions. Our current work only indicates that including one R matrix in the design can guarantee the identifiability of an ideal response pattern, which is one of the model identifiability conditions. Additional conditions must be investigated to guarantee the identifiability of attribute profiles and item parameters.
Another limitation of this study is that we only focused on conjunctive CDMs, which are naturally appropriate for the hierarchical attribute assumption. The impact of an ideal response pattern on classification accuracy is larger for conjunctive models than for compensatory models. We expect that completeness is not sufficient to guarantee good classification results in a compensatory model. It would be worth to investigating Q matrix design when utilizing general models, such as the log-linear cognitive diagnostic model (LCDM; Henson et al., 2009), the generalized deterministic input, noisy, “and” gate (G-DINA; De La Torre, 2011) model, and other general diagnostic models. Liu et al. (2016) conducted a simulation study to investigate three different Q matrix designs by utilizing the hierarchical log-liner model (Templin and Bradshaw, 2014). However, their Q matrix design seems to be a mixed structure, which contains both items that satisfy the specified attribute hierarchy and items that do not satisfy the specified hierarchy. In the future, it is worth investigating mixed-type Q matrix design.
The third limitation of this study is that it mainly focused one factor (i.e., attribute hierarchy) that affected identifiability. However, there are many other factors, such as the completeness and accuracy of the test Q matrix, number of attributes, examinees, items, item quality, and distribution of examinees, which may affect identifiability. To avoid excessive complexity, the test Q matrix was assumed to be correct to avoid the effects of an incorrect test Q matrix. The number of items and attributes were fixed as 30 and six, respectively, which are popular choices in real-world applications. Additionally, the sample size was fixed as 1,000. We expect that the effect size observed in simulations would decrease as the sample size decreases. However, in this study, because our tests were intended to measure six attributes and there are 26 = 64 types of attribute profiles or categories, even when a large sample size of N = 1,000 was generated, there were only approximately 19 participants in each category, which is a marginal number for correctly evaluating categories. Furthermore, the distributions of items and examinee parameters were fixed and followed a common distribution to avoid the effects of item quality and population size. In the future, if a smaller number of attributes is measured, a smaller sample size may be investigated. Other factors may also be investigated to produce more general results.
Author Contributions
YC and SD design of the study, data analysis, paper writing, and revision. DT data analysis and interpretation of data.
Funding
This work was supported by the National Natural Science Foundation of China (31660278, 31760288, 31360237, 31160203, and 30860084).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2018.01413/full#supplementary-material
References
Chen, Y., Liu, J., Xu, G., and Ying, Z. (2015). Statistical analysis of q-matrix based diagnostic classification models. J. Am. Statist. Assoc. 110, 850–866. doi: 10.1080/01621459.2014.934827
Chiu, C.-Y., Douglas, J. A., and Li, X. (2009). Cluster analysis for cognitive diagnosis: Theory and applications. Psychometrika 74, 633–665. doi: 10.1007/s11336-009-9125-0
Clements, D. H., and Sarama, J. (2004). Learning trajectories in mathematics education. Math. Think. Learn. 6, 81–89. doi: 10.1207/s15327833mtl0602_1
Davey, B., and Priestley, H. (1990). Introduction to Lattices and Order. Cambridge: Cambridge university. Press.
Davier, M. (2008). A general diagnostic model applied to language testing data. Br. J. Math. Statist. Psychol. 61, 287–307. doi: 10.1348/000711007X193957
DeCarlo, L. T. (2011). On the analysis of fraction subtraction data: The DINA model, classification, latent class sizes, and the q-matrix. Appl. Psychol. Measure. 35, 8–26. doi: 10.1177/0146621610377081
De La Torre, J. (2011). The generalized DINA model framework. Psychometrika 76, 179–199. doi: 10.1007/s11336-011-9207-7
De La Torre, J., Hong, Y., and Deng, W. (2010). Factors affecting the item parameter estimation and classification accuracy of the DINA model. J. Educ. Measure. 47, 227–249. doi: 10.1111/j.1745-3984.2010.00110.x
de la Torre, J., and Chiu, C.-Y. (2016). A general method of empirical Q-matrix validation. Psychometrika 81, 253–273. doi: 10.1007/s11336-015-9467-8
Ding, S., Luo, F., Cai, Y., Lin, H., and Wang, X. (2008). Complement to Tatsuoka's Q matrix theory. New Trends Psychometr. 417–424.
Ding, S., Luo, F., Wang, W., and Xiong, J. (2016). Dichotomous and polytomous q matrix theory. Quant. Psychol. Res. 167, 277–289. doi: 10.1007/978-3-319-38759-8_21
Ding, S., Wang, W., and Luo, F. (2012). Extension to Tatsuoka's Q matrix theory. Psychol. Explorat. 32, 417–422. doi: 10.3724/SP.J.1041.2009.00175
Gierl, M. J. (2007). Making diagnostic inferences about cognitive attributes using the rule space model and attribute hierarchy method. J. Educ. Measure. 44, 325–340. doi: 10.1111/j.1745-3984.2007.00042.x
Gierl, M. J. (2008). Using the attribute hierarchy method to identify and interpret cognitive skills that produce group differences. J. Educ. Measure. 4, 565–589. doi: 10.1111/j.1745-3984.2007.00052.x
Hartz, S. M., and Roussos, L. A. (2008). The Fusion Model for Skills Diagnosis: Blending Theory With Practice. Educational Testing Service, Research Report, RR-08-71. Princeton, NJ: Educational Testing Service.
Heller, J., Anselmi, P., Stefanutti, L., and Robusto, E. (2017). A necessary and sufficient condition for unique skill assessment. J. Math. Psychol. 79, 23–28. doi: 10.1016/j.jmp.2017.05.004
Heller, J., Stefanutti, L., Anselmi, P., and Robusto, E. (2015). On the link between cognitive diagnostic models and knowledge space theory. Psychometrika 80, 995–1019. doi: 10.1007/s11336-015-9457-x
Heller, J., Stefanutti, L., Anselmi, P., and Robusto, E. (2016). Erratum to: on the link between cognitive diagnostic models and knowledge space theory. Psychometrika 81, 250–251. doi: 10.1007/s11336-015-9494-5
Henson, R. A., Templin, J. L., and Willse, J. T. (2009). Defining a family of cognitive diagnosis models using log-linear models with latent variables. Psychometrika 74, 191–210. doi: 10.1007/s11336-008-9089-5
Junker, B. W., and Sijtsma, K. (2001). Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Appl. Psychol. Meas. 25, 258–272. doi: 10.1177/01466210122032064
Kuhn, D. (2001). “Why development does (and does not) occur: evidence from the domain of inductive reasoning,” in Mechanisms of Cognitive Development: Behavioral and Neural Perspectives, eds J. L. McClelland and R. Siegler (Mahwah, NJ: Erlbaum), 221–249.
Leighton, J. P., and Gierl, M. J. (2007). Cognitive Diagnostic Assessment for Education: Theory and Practice. Cambridge, UK: Cambridge University Press.
Leighton, J. P., Gierl, M. J., and Hunka, S. M. (2004). The attribute hierarchy method for cognitive assessment: a variation on Tatsuoka's rule-space approach. J. Educ. Meas. 41, 205–237. doi: 10.1111/j.1745-3984.2004.tb01163.x
Liu, R., Huggins-Manley, A. C., and Bradshaw, L. (2016). The impact of q-matrix designs on diagnostic classification accuracy in the presence of attribute hierarchies. Educ. Psychol. Meas. 76, 220–240. doi: 10.1177/0013164416645636
Madison, M. J., and Bradshaw, L. P. (2015). The effects of Q-matrix design on classification accuracy in the log-linear cognitive diagnosis model. Educ. Psychol. Meas. 75, 491–511. doi: 10.1177/0013164414539162
Maris, E. (1999). Estimating multiple classification latent class models. Psychometrika 64, 187–212. doi: 10.1007/BF02294535
Tatsuoka, K. (1990). “Toward an integration of item-response theory and cognitive error diagnosis,” in Monitoring Skills and Knowledge Acquisition eds N. Frederiksen, R. Glaser, A. Lesgold, and Safto, M (Hillsdale, NJ: Erlbaum), 453–488.
Tatsuoka, K. (1991). Boolean Algebra Applied to Determination of the Universal Set of Misconception States (ETS research report No. RR-91-44). Princeton, NJ, Educational Testing Services.
Tatsuoka, K. K. (1985). A probabilistic model for diagnosing misconceptions by the pattern classification approach. J. Educ. Behav. Stat. 10, 55–73. doi: 10.3102/10769986010001055
Tatsuoka, K. K. (2009). Cognitive Assessment: An Introduction to the Rule Space Method. New York, NY; London: Routledge.
Tatsuoka, K. K., and Boodoo, G. M. (2000). “Subgroup differences on the gre quantitative test based on the underlying cognitive processes and knowledge,” in Handbook of Research Design in Mathematics and Science Education eds A. E. Kelly, and R. Lesh (Mahwah, NJ: Erlbaum), 821–857.
Tatsuoka, M. M. (1986). Graph theory and its applications in educational research: a review and integration. Rev. Educ. Res. 56, 291–329. doi: 10.3102/00346543056003291
Templin, J., and Bradshaw, L. (2014). Hierarchical diagnostic classification models: a family of models for estimating and testing attribute hierarchies. Psychometrika 79, 317–339. doi: 10.1007/s11336-013-9362-0
Vosniadou, S., and Brewer, W. F. (1992). Mental models of the earth: a study of conceptual change in childhood. Cogn Psychol. 24, 535–585. doi: 10.1016/0010-0285(92)90018-W
Wang, S., and Douglas, J. (2015). Consistency of nonparametric classification in cognitive diagnosis. Psychometrika 80, 85–100. doi: 10.1007/s11336-013-9372-y
Wang, C., and Gierl, M. J. (2011). Using the attribute hierarchy method to make diagnostic inferences about examinees' cognitive skills in critical reading. J. Educ. Measure. 48, 165–118. doi: 10.1017/CBO9780511611186.009
Xu, G. (2017). Identifiability of restricted latent class models with binary responses. Ann. Statist. 45, 675–707. doi: 10.1214/16-AOS1464
Xu, G., and Zhang, S. (2016). Identifiability of diagnostic classification models. Psychometrika 81, 625–649. doi: 10.1007/s11336-015-9471-z
Keywords: Q matrix, attribute hierarchies, cognitive diagnosis, cognitive diagnostic models, Q matrix design
Citation: Cai Y, Tu D and Ding S (2018) Theorems and Methods of a Complete Q Matrix With Attribute Hierarchies Under Restricted Q-Matrix Design. Front. Psychol. 9:1413. doi: 10.3389/fpsyg.2018.01413
Received: 15 December 2017; Accepted: 19 July 2018;
Published: 08 August 2018.
Edited by:
Pietro Cipresso, Istituto Auxologico Italiano (IRCCS), ItalyReviewed by:
Juergen Heller, Universität Tübingen, GermanyAndrej Košir, University of Ljubljana, Slovenia
Copyright © 2018 Cai, Tu and Ding. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shuliang Ding, ding06026@163.com