1. Introduction
Breast cancer (BC) is the world’s leading cause of death in women after lung cancer, with approximately 2,261,419 new cases and 684,996 new deaths in 2020 [
1]. In the United States, 281,550 new cases were diagnosed with breast cancer, and 43,600 deaths were reported in the females during 2021 [
2]. Breast cancer is a type of cancer that originates from breast tissue, most generally from the internal layer of the milk conduit or the lobules that provide milk to the milk conduit. Cancer cells arise from natural cells due to modification or mutation of deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). These modifications or mutations may occur spontaneously as a result of the increase in entropy, or they may be triggered by other factors. For example, electromagnetic radiation (X-rays, microwaves, ultraviolet-rays, gamma-rays, et cetera), nuclear radiation, bacteria, viruses, fungi, parasites, chemicals in the air, heat, food, water, free radicals, mechanical cell-level injury, evolution, and aging of DNA and RNA [
3]. In general, benign and malignant are two classes of tumors. Although benign is not life-threatening and cancerous, it may boost the chances of breast cancer risk. In contrast, malignant is more alarming and cancerous tumors. A study performed breast cancer detection and reported 20% of women died due to malignant tumors [
4].
These studies emphasize the diagnosis of tumors, and recently, it is a trending biomedical issue. The researchers are employing data mining (DM) and machine learning (ML) technologies for breast cancer prediction [
5]. Classifier-based prediction models on DM and ML can limit the diagnosis errors and enhance the efficiency of a cancer diagnosis. DM is an extensive combination of different approaches to discover hidden knowledge and information from large-scale datasets that are difficult to analyze directly. It has been broadly used in the implementation of the prediction system for various diseases, such as heart disease [
6], lung cancer [
7], and thyroid cancer [
8]. DM and ML techniques have been embedded for diagnosing breast cancer with computer-aided systems [
9], and fuzzy-genetics [
10]. The results of these studies successfully classify the features into two types of tumors by the evaluation of classifier and predicting the incoming tumor based on previous data.
In the literature, a research study proved that breast cancer prediction with machine learning classifiers in the early phases does not just increase the survival chances but can control the diffusion of cancerous cells in the body [
11]. For instance, a study used the support vector machine (SVM) based method for breast cancer diagnosis and achieved practical results in prediction [
12]. Similarly, Furey et al. [
13] also employed SVM for cancer tissue classification with a linear kernel and attained a 93.4% accuracy. Later, this work was extended by Zheng et al. (2014) by delivering a K-SVM hybrid model for Wisconsin Diagnostic Breast Cancer (WDBC) dataset classification and acquiring 97% accuracy [
14]. Meanwhile, some other researchers worked on different classifiers, such as Seddik et al. (2015), who proposed a method based on tumor variables for a binary logistic model to diagnose breast cancer WDBC data and secure good results [
15]. Likewise, Mert et al. used a k-nearest neighbor (KNN) classifier to predict breast cancer by designing a feature reduction method with independent component analysis. It distributed the features with reduced one feature (1C) and 30 features and computed the performance, and attained 91% accuracy [
16].
Apart from these advantageous accuracies with different classifiers and methods, these studies mentioned above have not considered the data exploratory techniques, which enable the data mining techniques to be more robust to acquire efficient performance. Due to the absence of such essential techniques, various studies [
16,
17,
18,
19] face the accuracy limitation of ML classifiers. Meanwhile, the confusion matrices misdiagnosed the malignant and benign classes in those studies due to the incorrect prediction of true negative and false negative matrices. Another defect was found in those previous studies that used criteria to assess the feature training with nonlinear classification. However, the performance of model execution time increases rapidly with the number of features [
20]. As a result, the prediction model becomes slower, affecting the diagnosis accuracy. In contrast, the model’s accuracy and time complexity are critical issues for the data analyst and physician. These problems, as mentioned above, and findings motivated us to pursue a new study for breast cancer diagnosis by proposing data mining techniques with different machine learning models.
In this research, four different prediction models were formulated with four machine learning algorithms (SVM, KNN, logistic regression (LR), and ensemble classifier (EC)) to deal with a massive volume of tumor features for the extraction of essential information for the diagnosis of breast cancer. The objective was to explore an accurate and efficient prediction model for tumor classification by using data mining techniques. It proposes four-layered significant data exploratory techniques (DET), including feature distribution, elimination, and constructing a hyperparameter for the practical analysis of Wisconsin Diagnostic Breast Cancer (WDBC) and Breast Cancer Coimbra Dataset (BCCD). These techniques enabled the machine learning predictive models to improve accuracy and enhance diagnostic efficiency. In the absence of these techniques, we observed some literature suffers from accuracy limitations. Although image data are more reasonable for breast cancer detection, we have not considered them in this work due to the targeted WDBC and BCCD datasets to apply the intelligent ML classifiers. It presents a framework by integrating DET and predictive models to explore the implementation method for breast cancer diagnosis. The tumor features can be presented in many details, which produces redundant information. Such features lead to tedious outcomes due to high computation times. As a result, our fundamental goal was not only to investigate the effective predictive model with attainable accuracy but also one with time complexity for the cancer diagnosis. The deliberation of time efficiency will enable our models to extract and mine vital information from a vast dataset by finding correlations and eliminating the features. The results presented satisfactory accuracy for the breast cancer diagnosis with the lowest computation time, which signifies the quality of our study as compared to others. This work will enable a data analyst to apply an intelligent machine learning model to analyze breast cancer data. Likewise, a physician would diagnose breast cancer precisely by the tumor classification. As the dataset is available publicly, we uploaded our code on GitHub (
https://github.com/abdul-rasool/Improved-machine-learning-based-Predictive-Models-for-Breast-Cancer-Diagnosis (accessed on 11 November 2021)) to assist data analysts and physicians in further advancement and apply it in real-time. As summarized, the following are the significant contributions of this study:
We investigated four prediction models (SVM, LR, KNN, and EC) with the WDBC and BCCD breast cancer datasets, which reached the next level of quality by diagnosing the tumor and classifying it into benign and malignant.
It proposes four-layered data exploratory techniques before implementing four ML classifiers as prediction models. These techniques enable the predictive models to acquire peak accuracies for breast cancer diagnosis.
We set up experiments to validate the models’ prediction and classification accuracy with regard to time complexity and deliver comparative analysis with state-of-the-art studies and various evaluation matrices.
The rest of the article is organized as follows:
Section 2 expands on the literature reviews;
Section 3 explains the preliminary part for the introduction of proposed prediction models;
Section 4 introduces the proposed methodology;
Section 5 deals with the evaluation of the results;
Section 6 deliberates the discussion, and
Section 7 provides the conclusion.
2. Related Work
Breast cancer disease causes a massive number of deaths in the world. After the traditional cancer detection methods, the latest technologies enable experts with numerous adaptive methods to discover breast cancer in women. Along with the new technologies, various data science (DS) techniques assist in cancer-based data collection and evaluation to predict this deadly disease. Machine learning algorithms have been successfully applied to cancer-based data analysis among these DS technologies. For example, research [
21] was conducted to prove that these machine learning algorithms can improve diagnostic accuracy. It turns out that a 79.97% diagnostic accuracy was achieved by an expert physician. However, 91.1% correct predictions were attained with machine learning.
In the last couple of decades, machine learning applications in the medical field have gradually increased. However, the data collected from the patients and evaluation by the medical expert are the essential factors for diagnosis. The machine learning classifiers have aided in minimizing human errors and delivered prompt analysis of medical data with greater depth [
22]. There are several machine learning classifiers for data modeling and prediction; in our work, we employed support vector machine (SVM), logistic regression (LR), k-nearest neighbor (KNN), and ensemble classifier (EC) for breast cancer prediction.
In previous studies, SVM was a widely implemented machine learning algorithm in the diagnosis domain of breast cancer due to its highest prediction accuracy. For instance, Furey et al. (2000) presented SVM with a linear kernel for cancer tissue diagnosis and reached acceptable accuracy [
13]. Similarly, Polat et al. (2007) used the least square SVM for breast cancer prediction to eliminate redundant features and secured a 98.53% accuracy. It was suggested that least square SVM assisted in model training with linear equations [
23]. However, his method did not deliver the feature selection process. The author [
24] delivered a distributed database for multi-active features to integrate different technologies. In 2010, Prasad and Jain et al. [
25] proposed a heuristic model for feature subset to train the SVM classifier. It classifies the breast cancer data into two different classes with 91.7% accuracy. However, this accuracy can be adequately improved if the author employs the feature eradication method to get rid of the noise data.
Similarly, Zheng et al. (2014) proposed a hybrid model combining K-mean and SVM classifiers. This model objective was to diagnose the tumor features from the Wisconsin Diagnostic Breast Cancer (WDBC) dataset by employing the feature selection and extraction method. A K-mean classifier was employed to identify the benign and malignant tumor patterns. The generated patterns are computed and considered as new patterns for the training of the SVM model. Then, SVM is executed for the prediction of incoming tumors. The employment of their hybrid model improved the accuracy to 97%. However, the data exploratory techniques are the fundamental tasks for the data preparation, which have not been adequately addressed to train the proposed model [
14].
Apart from the SVM, Lim and Sohn et al. (2013) performed logistic regression (LR) with optimal parameters on the Wisconsin Original Breast Cancer (WOBC) and WDBC datasets. It achieved 97.8% sufficient accuracy for the WOBC dataset and 93.8% accuracy for the WDBC dataset with optimized feature sets [
26]. Similarly, Seddik et al. (2015) presented a binary logistic model for the diagnosis of breast cancer data based on variables with tumor image characteristics. The proposed model classifies the WDBC data into malignant and benign and accomplished the 98% average classification accuracy. This regression model found that area, texture, concavity, and symmetry are significant WDBC features [
15].
Previous literature reviews found numerous studies based on the SVM model for breast cancer detection; however, few were based on others. For example, A. Mert et al. (2015) delivered a feature reduction method with independent component analysis to predict breast cancer. It utilized the k-nearest neighbor (KNN) classifier to categorize the WDBC features efficiently with a reduced one feature (1C) and 30 features. It computed the performance with different matrices and attained 91% accuracy [
16]. Later, this study was further improved by Rajaguru et al. (2019), who tackled the breast cancer prediction challenge by implementing the KNN and decision tree (DT) machine learning algorithms to classify the WDBC features. It used a traditional principal component analysis (PCA) feature selection method for the feature categorization and found that KNN outperformed the DT [
18]. In another study conducted by Yang and Xu et al. (2019), KNN achieved 96.4% accuracy with the same feature selection method (PCA) [
27]. Recently, work has involved considering KNN efficiency by the k values and many distance functions of KNN to find its effectiveness with two different breast cancer datasets. It involves the three different types of the experiment: KNN without feature selection, with linear SVM, and with Chi-square-based features. It indicated that the third technique, Chi-square-based feature selection, succeeded in accomplishing the highest accuracy on both datasets with Manhattan or Canberra distance functions [
19].
As for the fourth prediction model, named ensemble classifier (EC) with the voting technique, few studies consider this approach for breast cancer prediction. For instance, M. Abdar et al. (2020) proposed an ensemble method by vote/voting classifier to detect benign tumors from malignant breast cancer. It established a two-layer voting classifier for two or three different machine learning algorithms. The results of these voting techniques disclosed the adequate performance of the simple classification algorithm [
5]. From these studies, we got the motivation to conduct experiments based on voting classifiers with different machine learning techniques. However, none of the above approaches has utilized the feature correlation and elimination for the given breast cancer dataset to the best of our knowledge. These studies conducted experiments to classify the cancer features, which is still a challenging issue. Recently, in Nature Cancer, a study presented an approach to classify cancer into normal and tumor tissues [
28]. Meanwhile, many studies have utilized the SVM classifier for breast cancer prediction, while a few of them used only one classifier in experiments. However, there is still a demand to explore the efficient classifier for breast cancer prediction with more effective methods [
5,
14,
15,
18]. This study performed four different prediction models with sufficient data mining exploratory techniques to diagnose breast cancer.
4. Proposed Methodology
The proposed methodology, including data information, model architecture, ML models, and their assessment criteria, will be discussed in this section.
4.1. Novel Framework
In this work, we provide a solution to tackle the problems below for the breast cancer dataset, which we found from [
16,
17,
18,
19].
How are the data exploratory techniques (DET) be used most efficiently utilized with the prediction models for breast cancer detection?
How can the breast cancer features help the ML models detect cancer more precisely and more scalable?
To solve these problems, a solution is proposed, illustrated in
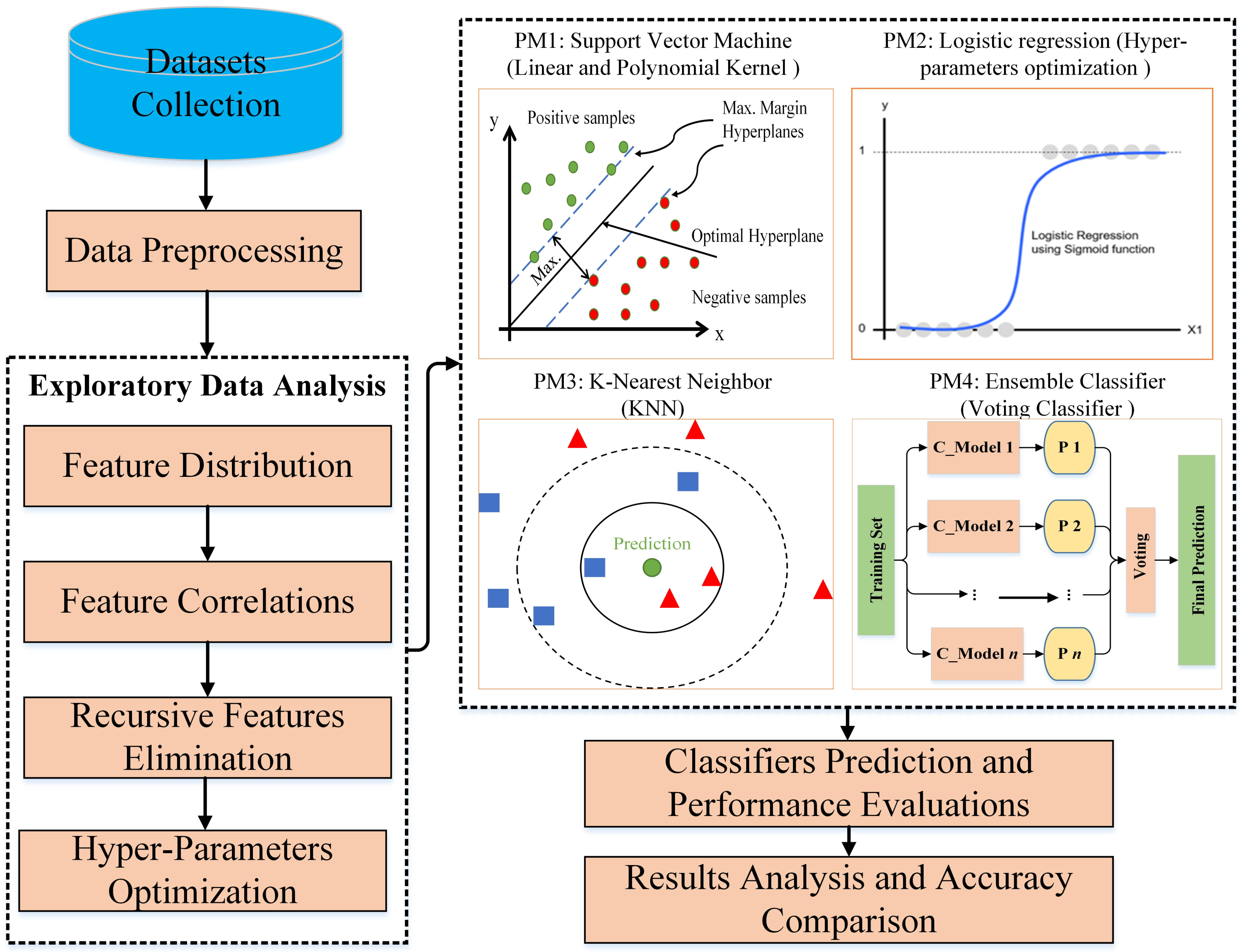
Figure 1. This solution has nine significant different steps. The outlines of this methodology are as follows:
- 1.
WDBC and BCCD datasets are downloaded from the machine learning repository.
- 2.
Execute the fundamental preprocessing tasks for individual data.
- 3.
Categorize the data into malignant and benign in WDBC and present and absent in BCCD.
- 4.
Distribute the features into positive, negative, and random (unrelated) by calculating their correlation with each other.
- 5.
Detect less significant features then eliminate such recursive features for effective results.
- 6.
After exploratory data analysis, distribute the dataset into training and testing datasets.
- 7.
Implementation of four predictive models (SVM, LR, KNN, and EC) on the datasets.
- 8.
After the models’ execution, the classifier’s prediction is achieved with different matrices to evaluate the performance of the models, such as confusion matrices.
- 9.
Finally, analyze the results and compare each model’s accuracy and previous research studies.
4.2. Data Exploratory Techniques (DET)
DE techniques, or DET, are the processes that help understand the nature of the dataset, which will identify the outliers or correlated variables that are more accessible. Our research applied feature distribution, correlation coefficient, and recursive feature elimination as our data exploratory techniques.
Feature Distribution: First, the distribution of each feature was observed to find how these features are different from each other, i.e., benign and malignant in the WDBC dataset and the presence and absence of breast cancer in the BCCD dataset. The distribution was carried out by plotting the distribution plot for each feature. The data were separated by using binary code: benign (B) = 0, malignant (M) = 1, and absence = 0, presence = 1. Then, the distribution of each feature was plotted between 0 and 1.
Feature Correlation: Next, the Pearson Correlation Coefficient (r) [
31] calculates the correlation coefficient between each of the two features. Then, the relationship between two features can be determined by categorizing them into three groups: positively correlated features, negatively correlated features, and uncorrelated features. The features will positively correlate (
r = +1) if the variables move in the same direction. In contrast, if these features move in the opposite direction, they will negatively correlate (
r = −1).
Recursive features elimination (RFE): RFE is one of the essential processes of machine learning. Since the dataset has many features, selecting the number of features that give the most optimal prediction result is important for improving model performance. Using fewer features that provide better understanding is the gist of doing RFE. It will recur the loop until it can find the optimal number of features. In this study, RFE was utilized to reduce the features from 30 to 15. It was conducted by a built-in function, selector.fit(x,y), of sklearn. The attributes support_, and ranking_ were passed to the ranking position of i − th feature and mask the selected features. RFE works by searching for a subset of features by starting with all features in the training dataset and successfully removing features until the desired number remains. This is achieved by fitting the given machine learning algorithm used in the core of the model, ranking features according to their relevance, discarding the least important features, and re-fitting the model. This process is repeated until a predetermined number of features is retained.
Hyperparameter Optimization: Hyperparameters optimization is a process of machine learning used for tuning a set of optimal parameters. The values of these parameters are used to control the learning process. There are many approaches for hyperparameters optimization, such as grid search, random search, Bayesian optimization, gradient-based optimization, and evolutionary and population-based optimization. In this study, we used grid search optimization due to its effective results for optimization. It applies the brute-force method to generate candidates from the grid of parameter values specified with the parameter. The grid search goal is to get the highest cross-validation metric scores. In our case, we utilized scikit − learn based GridSearch K-fold CV due to the disease prediction datasets. In all prediction models, GridSearch CV was adopted to evaluate the hyperparameters. GridSearchCV uses a different combination of specified hyperparameters and their values to perform the analysis. We utilized estimator, param_grid, scoring, verbose, and njobs parameters to calculate each combination’s performance.
4.3. Predictive Models
In this study, four ML classifiers were utilized as predictive models (PM) to diagnose Y-variable in the data as malignant or benign in the WDBC dataset and as the presence or absence of breast cancer in the BCCD dataset. The data were distributed into training and test sets. In experiments, we conducted this distribution by setting an integer value for the random_state. To tune the hyperparameter, this value can be any value, but split_size should be a particular value. In our scenario, we considered 20% testing sets and 80% training sets. The models were constructed on the training dataset, and then a test dataset was used to evaluate the model’s performance. We chose SVM due to its highest accuracy in the previous literature, and LR had the best performance by tuning the hyperparameter. Likewise, KNN was selected due to effective results with input features. Meanwhile, we experimented with the ensemble-based classifier using voting techniques to assess its performance and compared it with other classifiers. The precise details of these models are given below:
PM1—SVM: The first model applied SVM as a predictive model. SVM is one of the robust supervised machine learning algorithms used to solve classification and regression tasks [
32]. The idea of SVM is to find an optimal hyperplane that gives the maximum margin of each data class (0 and 1 in this case). The SVM approach aims to solve this quadratic problem by finding a hyperplane in the high dimensional space and the classifier in the original space, as shown in (5) [
33].
where
is called the kernel function.
In this work, SVM is applied to predict whether the data are located in class 0 or 1 based on several features and then calculates its performance. SVM has many kernel functions. For the linear dataset, it is called linear kernel SVM. For nonlinear, there are many types, such as polynomial kernel SVM, radial kernel SVM, and hyperbolic tangent SVM. In this research, two different kinds of SVM kernels, the linear and polynomial kernel, were applied.
PM2—LR: Our second model applied LR to predict the outcomes. LR is one of the most widespread machine learning techniques. It is mainly used to predict a binary variable with a large number of independent variables. It is efficient to forecast the probability of being 0 or 1 based on predictors [
34,
35,
36]. It can be expressed as (6):
where
X is a vector that contains
independent predictor variables;
is the conditional probability of experiencing the event
given the independent variable vector
X; and
is a random error term. We can express
as (7):
where
is the model’s parameters vector.
This study applied LR to predict whether the data are located in class 0 or 1 and then calculated the performance. LR is like an upgraded version of linear regression. However, by using linear regression to predict binary classification, some predictions will have values more than one or less than 0. A sigmoid function is employed in LR to normalize the prediction to be between 0 and 1.
PM3—KNN: The third model applied KNN as a predictive model. The KNN algorithm used in our problem considered the output a target class. The problem was solved or classified by the majority vote of its neighbors, where the value of K was taken as a small and real-valued positive integer [
37,
38]. There are different methods for calculating the distance: Manhattan, Euclidean, Cosine, etc [
39]. However, this study applies to Euclidean distance only. Let
be the centroid and
be the data point. The Euclidean distance can be calculated by (8):
From
Figure 1 (the part of PM3), there are two types of data: square and triangle; each type is referred to as a datum. The circle in the middle is the prediction. K represents a numerical value for the nearest neighbors of the output. Given K = 3, the model will find the nearest three data points to the output in the small circle. It contains two triangles and one square, so the output will be a triangle because it has more than a circle. If K = 5, the model comprises three squares and two triangles. Therefore, the prediction result of K = 5 is square. Hence, this technique will be applied to predict whether an instance is malignant or benign in the WDBC dataset and the presence or absence of breast cancer in the BCCD dataset.
PM4—EC: The fourth model applies the ensemble classifier method as a predictive model. It aims to maximize the precision and recall value to detect all malignant tumors in the WDBC dataset and detect all cancer presence in the BCCD dataset. Our research applied an ensemble classifier to optimize the logistic regression model [
40,
41]. Ensemble classifiers have many types, i.e., bagging, boosting, and voting [
42]. The kind that will be used in this research is the voting classifier. A voting classifier combines various machine learning algorithms such as SVM, LR, or KNN. Then, we ran them on the same dataset to get the prediction result of each model. Finally, it will take a majority vote to make a final prediction. For example, the voting classifier trained three algorithms; algorithm 1 resulted in “1”; algorithm 2 resulted in “0”; and algorithm 3 resulted in “0”. The final result will be “0” because two of them are “0” and only one is another option.
4.4. Experimental Setup
This work was implemented in Jupiter Notebook with the Python language. We processed the following key steps that can assist the data analyst or physician in implementing this work for the breast cancer prediction in real-time:
- 1.
Import the related Python libraries such as pandas, NumPy, and sklearn and execute the preprocessing steps to drop out the missing values.
- 2.
Process and execute the four-layered data exploratory techniques on each dataset.
- 3.
Definitions and calling of all related functions, such as the confusion matrix, the precision–recall curve, the ROC curve, the learning curve, and cross-validation metrics, and assess the models’ performance.
- 4.
Implement the proposed prediction models:
Starting with SVM, first, it needs to define variables and the number of test and training sets (in this case is 80% and 20%, respectively). Then, define the output results and run the model using Linear and Polynomial SVM. The results would be shown in cross-validation metrics.
The following model is LR; after defining the variables and splitting the data, two methods were applied to find the best hyperparameter. The first one was to use GridSearchCV, and the second one was to use Recursive Feature Elimination (RFE). Then, plot the confusion matrix, ROC curve, and learning, and find cross-validation metrics were used for both methods.
The 3rd prediction model was KNN; we used GridSearchCV to find the best hyperparameter to run KNN and showed the confusion matrix and cross-validation metrics.
The final model is EC; it applied LR with EC and the voting classifier for this work. The execution steps are similar to the previous ones. The results are shown in the confusion matrix, learning curve, and cross-validation metrics.
The experimental environment and fundamental packages for implementing proposed prediction models and DE techniques are presented in
Table 2.
6. Discussion
Our results evaluations mostly analyzed our findings by considering the F1 score. As in real-world classification problems, large imbalanced class distributions happened in datasets. We find some observations with significant differences between the classes in the feature distribution results. For example, the concavity mean in Supplementary Note 01 had a significant difference between the distribution of benign and malignant classes. The resampling techniques, i.e., oversampling, undersampling, and cross-validation, were adopted to balance such features. The oversampling technique duplicates the minority classes, but it creates an overfitting issue for machine learning algorithms. In contrast, the undersampling technique deletes the majority classes that discard the potential data. These disadvantages can decrease machine learning accuracy for particular problems such as fraud detection, face recognition, disease detection, etc. Therefore, we omit the oversampling and undersampling techniques in our study due to the cancer detection problem. However, the author [
46] suggested the cross-validation technique as a dominant technique to overcome the imbalanced class distribution. Cross-validation utilizes different portions of the data to test and train a model. This study employed the cross-validation technique using the k-fold and GridSearchCV with prediction models to balance the benign and malignant features in the training and testing dataset. The cross-validation matrices, including F1 score, precision, and recall, were compared due to the efficient use of crucial values of TP, TN, FP, and FN to deal with actual and predicted classes. The proper definitions of these metrics are given in
Section 3.2.
In the polynomial SVM implementation, we secured a 99.3% F1 score, which means our proposed prediction model successfully identified the tumor and classified the cancer features as malignant. Thus, a higher F1 score means a higher diagnostic efficiency of tumors. In
Table 7, this study’s F1 score and accuracy are compared with previous studies that utilized the same dataset (WDBC). These predictive models with data mining techniques would assist the data analyst in detecting the cancerous mass by analyzing the cancerous data. Similarly,
Figure 8 illustrates the performance comparison of models and methods with the cross-validation techniques. As the time complexity is also a significant issue for the ML models,
Table 6 presents each model’s execution time with minimum but maximum accuracy. Hence, from the above analysis, our contribution with these proposed prediction models and techniques can be efficiently helpful for the cancer domain to acquire highly satisfying results for breast cancer diagnosis.
In this study, the objective was completed for detecting breast cancer with the highest accuracy of machine learning models. However, we were unable to provide the precise reason for malignant features, which needs a domain expert. It should be noted that the BCCD dataset did not yield effective results with our prediction models except for SVM; thus, we ignored those results in this study. We provided the sources/links of the datasets in the “Data Description” subsection. As these datasets belong to American patients, the results may not be similar and effective with the Asian patients’ data. This is one of the limitations of this study, which could be extended in the future by a different dataset with neural network implementation.
7. Conclusions
An accurate and timely diagnosis of various diseases, i.e., breast cancer, is still a major problem for proper treatment in the healthcare field. The precise analysis of cancer features is still a time-consuming and challenging task due to the availability of massive data and the lack of DM techniques with appropriate ML classifiers. In this study, four-layered essential data exploratory techniques were proposed with four different machine learning predictive models, including SVM, LR, KNN, and ensemble classifier, to detect breast cancer tumors and classify them into benign and malignant tumors. One of the primary objectives of this study was the implementation of DE techniques before the execution of ML classifiers on the WDBC and BCCD datasets. These mining techniques enabled us to improve the prediction model’s performance with a maximum F1 score and an accuracy score higher than before. The significant finding demonstrated that the first prediction model (with an SVM polynomial kernel) had acquired the highest accuracy (99.3%). Meanwhile, logistic regression with recursive features elimination also secured 98.06% accuracy, which shows that DE techniques effectively detect higher accuracy. Our outcomes depict the competence of our prediction models for breast cancer diagnosis and provide adequate results by utilizing a short time for training the model. These sophisticated models, techniques, and results would help the physician and data analyst to apply a more intelligent classifier to diagnose breast cancer features.
As the image data relating to breast cancer are available, we will use deep learning models to detect breast cancer with novel data augmentation strategies and data exploratory techniques to handle the data scarcity and diversity. In the future, we will conduct experiments on the datasets from other countries and try to answer whether or not the different area patient’s data affect the model’s performance.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







