On the Performance of One-Stage and Two-Stage Object Detectors in Autonomous Vehicles Using Camera Data



Abstract
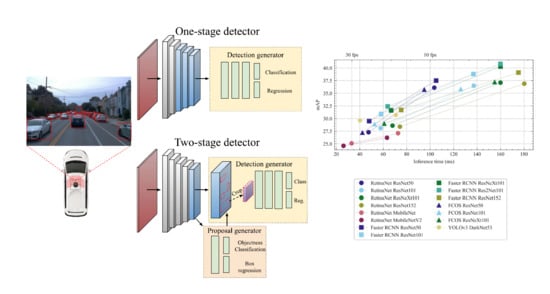
:
1. Introduction
- A review of the main deep learning meta-architectures and feature extractors for 2D object detection.
- An evaluation of Faster R-CNN, RetinaNet, YOLO and FCOS architectures over several performance metrics in the context of autonomous vehicles.
- An exhaustive analysis of the influence of different backbone networks and image resolutions in the speed/accuracy trade-off of the models.
2. Related Work
2.1. Two-Stage Detectors
2.2. One-Stage Detectors
2.3. Object Detection in Autonomous Vehicles
3. Materials and Methods
3.1. Waymo Open Dataset
3.2. Deep Learning Meta-Architectures
3.2.1. Faster R-CNN
3.2.2. RetinaNet
3.2.3. YOLOv3
3.2.4. FCOS
3.3. Feature Extractors
3.3.1. ResNet, ResNeXt, and Res2Net
3.3.2. DarkNet
3.3.3. MobileNet
3.4. Training Procedure and Other Implementation Details
4. Results and Discussion
4.1. Evaluation Metrics
4.2. Precision and Efficiency Analysis
4.2.1. COCO Precision Metrics
4.2.2. Waymo Precision Metrics
4.3. Effectiveness of Transfer Learning
4.4. Other Useful Metrics
5. Conclusions and Future Work
- The most accurate detection models were obtained using high-resolution images and do not reach real-time speed. Therefore, in this context, it is necessary to sacrifice some accuracy by using smaller input images to improve the inference rate.
- Faster R-CNN using Res2Net-101 obtains the best speed/accuracy trade-off but needs lower resolution images to achieve real-time inference speed.
- Two-stage Faster R-CNN models can achieve speeds comparable to one-stage detectors with higher detection accuracy.
- The anchor-free FCOS detector is a slightly faster one-stage alternative to RetinaNet, with similar precision and lower memory usage.
- RetinaNet MobileNet is the only model reaching 30 FPS, but with low precision. YOLOv3 or FCOS ResNet-50 at 25 FPS are more convenient options for on-board applications, although not as accurate as Faster R-CNN.
- Increasing the image resolution significantly degrades the computational efficiency of RetinaNet models with ResNet backbones, hence becoming impractical for this application.
- One-stage models fail to achieve good results over the minority class in this problem. Faster R-CNN models proved to be more robust to the presence of imbalanced data.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FPN | Feature Pyramid Network |
| FPS | Frames per second |
| IoU | Intersection over Union |
| NMS | Non-Maximum Supression |
| R-CNN | Regions with CNN |
| ReLU | Rectified Linear Unit |
| RoI | Region of Interest |
| RPN | Region Proposal Network |
| SSD | Single Shot Detector |
References
- Lara-Benítez, P.; Carranza-García, M.; García-Gutiérrez, J.; Riquelme, J. Asynchronous dual-pipeline deep learning framework for online data stream classification. Integr. Comput. Aided Eng. 2020, 27, 101–119. [Google Scholar] [CrossRef]
- Van Brummelen, J.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- Geng, K.; Dong, G.; Yin, G.; Hu, J. Deep dual-modal traffic objects instance segmentation method using camera and lidar data for autonomous driving. Remote Sens. 2020, 12, 1–22. [Google Scholar] [CrossRef]
- Real-time gun detection in CCTV: An open problem. Neural Netw. 2020, 132, 297–308. [CrossRef] [PubMed]
- Carranza-García, M.; García-Gutiérrez, J.; Riquelme, J.C. A Framework for Evaluating Land Use and Land Cover Classification Using Convolutional Neural Networks. Remote Sens. 2019, 11, 274. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Zhao, F.; Liu, Z.; Hao, H. Can autonomous vehicle reduce greenhouse gas emissions? A country-level evaluation. Energy Policy 2019, 132, 462–473. [Google Scholar] [CrossRef]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8437–8445. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Liu, Z.; Deng, W. Anchor generation optimization and region of interest assignment for vehicle detection. Sensors (Switzerland) 2019, 19, 1089. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Volume 9905 LNCS, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft COCO: Common objects in context. In Proceedings of the ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Volume 8693 LNCS, pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 2443–2451. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2017, arXiv:1611.05431. [Google Scholar]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P.H.S. Res2Net: A New Multi-scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up Object Detection by Grouping Extreme and Center Points. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar] [CrossRef] [Green Version]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–24 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Scale, H. PandaSet: Public Large-Scale Dataset for Autonomous Driving. 2019. Available online: https://scale.com/open-datasets/pandaset (accessed on 30 October 2020).
- Caesar, H.; Bankiti, V.; Lang, A.; Vora, S.; Liong, V.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Arcos-Garcia, A.; Álvarez García, J.A.; Soria-Morillo, L.M. Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Towards Reaching Human Performance in Pedestrian Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 973–986. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C. Tensorflow Object Detection API. 2020. Available online: https://github.com/tensorflow/models/tree/master/research/object_detection (accessed on 13 November 2020).
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Shen, C.; van den Hengel, A. Wider or Deeper: Revisiting the ResNet Model for Visual Recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 14 December 2020).
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2018, arXiv:1706.02677. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. arXiv 2017, arXiv:1609.04836. [Google Scholar]
- Casado-García, Á.; Heras, J. Ensemble Methods for Object Detection. In Proceedings of the ECAI, Santiago de Compostela, Spain, 31 August–2 September 2020. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Total | |||||
|---|---|---|---|---|---|---|---|
| Images | 74,420 | (75%) | 24,770 | (25%) | 99,190 | ||
| Objects | Vehicle | 589,583 | (87.9%) | 256,076 | (91.7%) | 845,659 | (89.0%) |
| Pedestrian | 77,569 | (11.5%) | 21,678 | (7.8%) | 99,247 | (10.5%) | |
| Cyclist | 3842 | (0.6%) | 1332 | (0.5%) | 5174 | (0.5%) | |
| Total Objects | 670,994 | (71%) | 279,086 | (29%) | 950,080 | ||
| Feature Extractor | Faster R-CNN | RetinaNet | YOLOv3 | FCOS |
|---|---|---|---|---|
| FPN ResNet-50 | ✓ | ✓ | ✓ | |
| FPN ResNet-101 | ✓ | ✓ | ✓ | |
| FPN ResNet-152 | ✓ | ✓ | ||
| FPN ResNeXt-101 | ✓ | ✓ | ✓ | |
| FPN Res2Net-101 | ✓ | |||
| FPN MobileNet V1 | ✓ | |||
| FPNLite MobileNet V2 | ✓ | |||
| DarkNet-53 | ✓ |
| Output Size | ResNet-50 | ResNet-101 | ResNet-152 | ResNeXt-101-32x4d | DarkNet-53 | MobileNet | MobileNetV2 |
|---|---|---|---|---|---|---|---|
| , 64, stride 2 | , 32, stride 1 | , 32, stride 2 | |||||
| , 64, stride 2 | |||||||
| max pool, stride 2 | |||||||
| , 128, stride 2 | |||||||
| , 256, stride 2 | |||||||
| , 512, stride 2 | |||||||
| , 1024, stride 2 | |||||||
| FLOPS () | |||||||
| Parameters () | |||||||
| Architecture | Feature Extractor | Computational Time (ms) | Mean Average Precision | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Training | Inference | AP | AP | AP | AP | AP | AP | ||
| RetinaNet | FPN ResNet50 | 166.31 | 103.50 | 36.1 | 58.1 | 37.1 | 7.8 | 39.8 | 65.9 |
| RetinaNet | FPN ResNet101 | 236.69 | 137.20 | 36.5 | 58.7 | 37.4 | 7.9 | 39.9 | 66.3 |
| RetinaNet | FPN ResNeXt101 | 405.26 | 159.93 | 37.1 | 59.5 | 38.7 | 7.8 | 40.8 | 68.0 |
| RetinaNet | FPN ResNet152 | 530.60 | 195.00 | 36.9 | 59.1 | 37.7 | 8.1 | 40.0 | 66.7 |
| RetinaNet | FPN MobileNet | 130.20 | 72.63 | 27.0 | 43.2 | 29.1 | 1.1 | 23.8 | 59.2 |
| RetinaNet | FPNLite MobileNetV2 | 118.30 | 63.20 | 25.0 | 38.6 | 24.1 | 0.8 | 21.0 | 56.9 |
| Faster RCNN | FPN ResNet50 | 176.11 | 105.09 | 37.5 | 60.5 | 39.4 | 10.3 | 40.0 | 67.0 |
| Faster RCNN | FPN ResNet101 | 248.21 | 136.95 | 38.8 | 62.0 | 41.2 | 11.1 | 41.2 | 69.0 |
| Faster RCNN | FPN ResNeXt101 | 418.33 | 159.93 | 40.3 | 63.9 | 42.6 | 12.4 | 42.2 | 70.6 |
| Faster RCNN | FPN Res2Net101 | 334.74 | 159.89 | 40.8 | 64.4 | 43.2 | 12.3 | 44.0 | 70.7 |
| Faster RCNN | FPN ResNet152 | 520.30 | 185.00 | 39.1 | 62.3 | 41.5 | 11.2 | 41.3 | 69.2 |
| FCOS | FPN ResNet50 | 168.12 | 95.00 | 35.7 | 57.9 | 37.2 | 8.1 | 38.6 | 65.3 |
| FCOS | FPN ResNet101 | 234.58 | 126.11 | 35.8 | 58.0 | 37.4 | 8.3 | 38.9 | 65.6 |
| FCOS | FPN ResNeXt101 | 340.23 | 155.00 | 37.2 | 59.7 | 37.5 | 8.6 | 39.5 | 66.4 |
| YOLOv3 | DarkNet-53 | 180.52 | 70.81 | 30.7 | 54.9 | 31.1 | 10.3 | 37.0 | 49.2 |
| Architecture | Feature Extractor | Computational Time (ms) | Mean Average Precision | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Training | Inference | AP | AP | AP | AP | AP | AP | ||
| RetinaNet | FPN ResNet50 | 75.62 | 47.47 | 27.3 | 44.4 | 28.0 | 1.0 | 24.8 | 64.2 |
| RetinaNet | FPN ResNet101 | 111.36 | 57.74 | 28.1 | 45.6 | 29.0 | 1.1 | 25.6 | 65.7 |
| RetinaNet | FPN ResNeXt101 | 156.57 | 67.91 | 28.6 | 46.4 | 29.1 | 1.2 | 26.0 | 66.7 |
| RetinaNet | FPN ResNet152 | 220.20 | 74.20 | 28.4 | 46.2 | 28.9 | 1.2 | 26.0 | 66.2 |
| RetinaNet | FPN MobileNet | 56.20 | 33.02 | 25.1 | 39.4 | 24.3 | 1.3 | 20.0 | 57.3 |
| RetinaNet | FPNLite MobileNetV2 | 50.21 | 26.12 | 24.6 | 38.2 | 23.6 | 1.1 | 18.0 | 55.8 |
| Faster RCNN | FPN ResNet50 | 86.23 | 48.00 | 29.5 | 47.9 | 30.6 | 2.8 | 29.6 | 65.3 |
| Faster RCNN | FPN ResNet101 | 119.52 | 58.10 | 30.9 | 49.9 | 32.3 | 3.2 | 31.2 | 66.0 |
| Faster RCNN | FPN ResNeXt101 | 161.86 | 66.81 | 31.6 | 50.9 | 33.0 | 3.4 | 32.0 | 67.0 |
| Faster RCNN | FPN Res2Net101 | 151.30 | 63.78 | 32.4 | 51.7 | 34.2 | 3.6 | 33.2 | 68.3 |
| Faster RCNN | FPN ResNet152 | 210.20 | 75.30 | 31.7 | 51.2 | 33.3 | 3.4 | 31.5 | 67.1 |
| FCOS | FPN ResNet50 | 75.14 | 42.25 | 27.2 | 45.3 | 27.2 | 2.2 | 24.7 | 62.1 |
| FCOS | FPN ResNet101 | 103.50 | 52.59 | 28.9 | 47.1 | 29.7 | 2.7 | 26.5 | 64.6 |
| FCOS | FPN ResNeXt101 | 145.23 | 60.87 | 29.0 | 47.8 | 29.4 | 3.0 | 26.6 | 64.3 |
| YOLOv3 | DarkNet-53 | 82.56 | 40.19 | 29.6 | 53.1 | 29.2 | 5.5 | 30.2 | 58.4 |
| Architecture | Feature Extractor | Low Resolution | High Resolution | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Difficulty Level 1 | Difficulty Level 2 | Difficulty Level 1 | Difficulty Level 2 | ||||||||||
| Vehicle | Pedest. | Cyclist | Vehicle | Pedest. | Cyclist | Vehicle | Pedest. | Cyclist | Vehicle | Pedest. | Cyclist | ||
| RetinaNet | FPN ResNet50 | 49.5 | 54.9 | 33.9 | 38.7 | 50.1 | 27.7 | 62.3 | 69.5 | 46.6 | 51.3 | 64.8 | 39.3 |
| RetinaNet | FPN ResNet101 | 49.9 | 55.6 | 35.0 | 39.1 | 50.8 | 29.1 | 62.5 | 69.7 | 46.7 | 51.5 | 65.3 | 39.7 |
| RetinaNet | FPN ResNeXt101 | 50.5 | 56.6 | 35.7 | 39.7 | 51.8 | 30.7 | 62.9 | 70.4 | 50.0 | 51.8 | 66.0 | 40.1 |
| RetinaNet | FPN ResNet152 | 50.5 | 56.6 | 36.7 | 39.5 | 51.3 | 28.5 | 62.7 | 69.7 | 46.7 | 51.7 | 65.2 | 39.9 |
| RetinaNet | FPN MobileNet | 46.6 | 45.7 | 27.0 | 34.7 | 32.4 | 22.1 | 49.2 | 47.5 | 33.6 | 37.0 | 34.2 | 28.1 |
| RetinaNet | FPNLite MobileNetV2 | 44.6 | 43.7 | 25.0 | 33.7 | 30.4 | 20.1 | 46.1 | 43.7 | 31.0 | 33.7 | 30.4 | 26.2 |
| Faster RCNN | FPN ResNet50 | 51.2 | 56.8 | 37.7 | 40.2 | 51.6 | 32.2 | 64.3 | 70.2 | 50.6 | 53.2 | 65.8 | 43.0 |
| Faster RCNN | FPN ResNet101 | 55.3 | 60.2 | 42.1 | 43.8 | 54.3 | 35.1 | 65.1 | 71.8 | 53.3 | 54.7 | 67.2 | 45.7 |
| Faster RCNN | FPN ResNeXt101 | 56.3 | 61.3 | 43.7 | 44.7 | 56.3 | 36.2 | 66.2 | 73.0 | 56.3 | 56.0 | 69.5 | 48.6 |
| Faster RCNN | FPN Res2Net101 | 56.6 | 61.7 | 44.8 | 44.9 | 56.8 | 37.8 | 66.6 | 74.4 | 56.3 | 56.3 | 69.9 | 48.9 |
| Faster RCNN | FPN ResNet152 | 56.4 | 61.5 | 43.5 | 44.8 | 56.5 | 36.0 | 65.5 | 71.9 | 53.6 | 54.9 | 67.4 | 45.8 |
| FCOS | FPN ResNet50 | 49.3 | 55.5 | 35.3 | 38.6 | 50.7 | 28.9 | 61.7 | 68.5 | 48.5 | 50.8 | 63.8 | 40.9 |
| FCOS | FPN ResNet101 | 52.1 | 57.3 | 37.1 | 41.2 | 52.4 | 30.5 | 62.3 | 68.6 | 47.2 | 51.4 | 63.9 | 39.8 |
| FCOS | FPN ResNeXt101 | 52.0 | 57.3 | 39.1 | 41.2 | 52.5 | 32.3 | 62.8 | 70.5 | 49.5 | 51.6 | 65.8 | 40.3 |
| YOLOv3 | DarkNet-53 | 53.1 | 65.3 | 44.1 | 42.0 | 60.6 | 36.7 | 49.6 | 68.4 | 48.6 | 41.3 | 63.9 | 41.0 |
| Architecture | Feature Extractor | COCO | High Resolution | Low Resolution | ||||
|---|---|---|---|---|---|---|---|---|
| Ref. AP | AP | FPS | Train Time (h) | AP | FPS | Train Time (h) | ||
| Faster RCNN | FPN Res2Net101 | 43.0 | 40.8 | 6.3 | 16.7 | 32.4 | 15.7 | 7.6 |
| Faster RCNN | FPN ResNeXt101 | 41.2 | 40.3 | 6.3 | 20.9 | 31.6 | 15.0 | 8.1 |
| Faster RCNN | FPN ResNet152 | 40.1 | 39.1 | 5.4 | 26.0 | 31.7 | 13.3 | 10.5 |
| Faster RCNN | FPN ResNet101 | 39.8 | 38.8 | 7.3 | 12.4 | 30.9 | 17.2 | 6.0 |
| Faster RCNN | FPN ResNet50 | 38.4 | 37.5 | 9.5 | 8.8 | 29.5 | 20.8 | 4.3 |
| FCOS | FPN ResNeXt101 | 40.4 | 37.2 | 6.5 | 17.0 | 29.0 | 16.4 | 7.3 |
| RetinaNet | FPN ResNeXt101 | 40.1 | 37.1 | 6.3 | 20.3 | 28.6 | 14.7 | 7.8 |
| RetinaNet | FPN ResNet152 | 39.2 | 36.9 | 5.1 | 26.5 | 28.4 | 13.5 | 11.0 |
| RetinaNet | FPN ResNet101 | 38.9 | 36.5 | 7.3 | 11.8 | 28.1 | 17.3 | 5.6 |
| RetinaNet | FPN ResNet50 | 37.4 | 36.1 | 9.7 | 8.3 | 27.3 | 21.1 | 3.8 |
| FCOS | FPN ResNet101 | 39.2 | 35.8 | 7.9 | 11.7 | 28.9 | 19.0 | 5.2 |
| FCOS | FPN ResNet50 | 36.9 | 35.7 | 10.5 | 8.4 | 27.2 | 23.7 | 3.8 |
| YOLOv3 | DarkNet-53 | 33.4 | 30.7 | 14.1 | 9.0 | 29.6 | 24.9 | 4.1 |
| RetinaNet | FPN MobileNet | 29.1 | 27.0 | 13.8 | 6.5 | 25.1 | 30.3 | 2.8 |
| RetinaNet | FPNLite MobileNetV2 | 28.2 | 25.0 | 15.8 | 5.9 | 24.6 | 38.3 | 2.5 |
| Architecture | Feature Extractor | Parameters | GFlops | Memory (GB) | ||
|---|---|---|---|---|---|---|
| (10 × 106) | Low res. | High res. | Low res. | High res. | ||
| RetinaNet | FPN ResNet50 | 36.15 | 123.08 | 332.78 | 1.21 | 2.87 |
| RetinaNet | FPN ResNet101 | 55.14 | 168.72 | 456.01 | 1.80 | 4.27 |
| RetinaNet | FPN ResNeXt101 | 54.78 | 170.97 | 462.06 | 1.87 | 4.73 |
| RetinaNet | FPN ResNet152 | 70.24 | 203.85 | 520.42 | 2.54 | 5.62 |
| RetinaNet | FPN MobileNet | 10.92 | 72.03 | 105.99 | 0.54 | 1.74 |
| RetinaNet | FPNLite MobileNetV2 | 2.60 | 10.12 | 40.45 | 0.45 | 1.52 |
| Faster RCNN | FPN ResNet50 | 41.13 | 129.56 | 326.01 | 1.34 | 3.67 |
| Faster RCNN | FPN ResNet101 | 60.13 | 175.21 | 449.24 | 1.94 | 4.89 |
| Faster RCNN | FPN ResNeXt101 | 59.76 | 177.46 | 455.29 | 2.11 | 5.55 |
| Faster RCNN | FPN Res2Net101 | 60.78 | 181.53 | 466.26 | 2.06 | 5.01 |
| Faster RCNN | FPN ResNet152 | 76.45 | 210.14 | 514.23 | 2.80 | 6.10 |
| FCOS | FPN ResNet50 | 31.84 | 117.99 | 318.98 | 0.88 | 1.98 |
| FCOS | FPN ResNet101 | 50.78 | 163.63 | 442.22 | 1.41 | 3.30 |
| FCOS | FPN ResNeXt101 | 49.89 | 165.23 | 448.45 | 1.55 | 4.02 |
| YOLOv3 | DarkNet-53 | 61.53 | 116.33 | 316.28 | 1.06 | 2.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carranza-García, M.; Torres-Mateo, J.; Lara-Benítez, P.; García-Gutiérrez, J. On the Performance of One-Stage and Two-Stage Object Detectors in Autonomous Vehicles Using Camera Data. Remote Sens. 2021, 13, 89. https://doi.org/10.3390/rs13010089
Carranza-García M, Torres-Mateo J, Lara-Benítez P, García-Gutiérrez J. On the Performance of One-Stage and Two-Stage Object Detectors in Autonomous Vehicles Using Camera Data. Remote Sensing. 2021; 13(1):89. https://doi.org/10.3390/rs13010089
Chicago/Turabian StyleCarranza-García, Manuel, Jesús Torres-Mateo, Pedro Lara-Benítez, and Jorge García-Gutiérrez. 2021. "On the Performance of One-Stage and Two-Stage Object Detectors in Autonomous Vehicles Using Camera Data" Remote Sensing 13, no. 1: 89. https://doi.org/10.3390/rs13010089