Evolutionary Algorithms to Optimize Task Scheduling Problem for the IoT Based Bag-of-Tasks Application in Cloud–Fog Computing Environment


Abstract
:1. Introduction
2. Related Works
2.1. Fog Computing with IoT
- Latency constraints: Fog Computing is often the best candidate when it comes to dealing with strict timing requirements of many IoT systems such as data analyzing, data managing and other latency-restrictive tasks close to end users.
- Network bandwidth constraints: Fog Computing allows data sent and received from the end users to the Cloud to be processed hierarchically so that the trade-off between application demands and available networking and computing resources is considered. This also optimizes data usage, reducing the amount needed to be sent to the Cloud.
- Resource-limited devices: Resource-intensive tasks can be performed by Fog instead of resource-limited devices when they cannot be sent to the Cloud, which reduces these devices’s complexity, maintenance cost, and energy consumption.
- Uninterrupted services with sporadic connectivity to the cloud: A Fog system can function independently to maintain constant services despite having sporadic network connectivity to the Cloud.
- IoT security challenges: A Fog system is capable of the following: (1) acting as proxies for resource-limited devices of which security credentials and software can be managed and updated; (2) performing numerous security protocols on behalf of the resource-limited devices, to make up for the lack of security functionality on these devices; (3) overseeing the security status of devices in close proximity; and (4) using gathered information and context to identify threats promptly.
2.2. Task Scheduling Algorithms for Fog Computing
3. Task Scheduling Problem
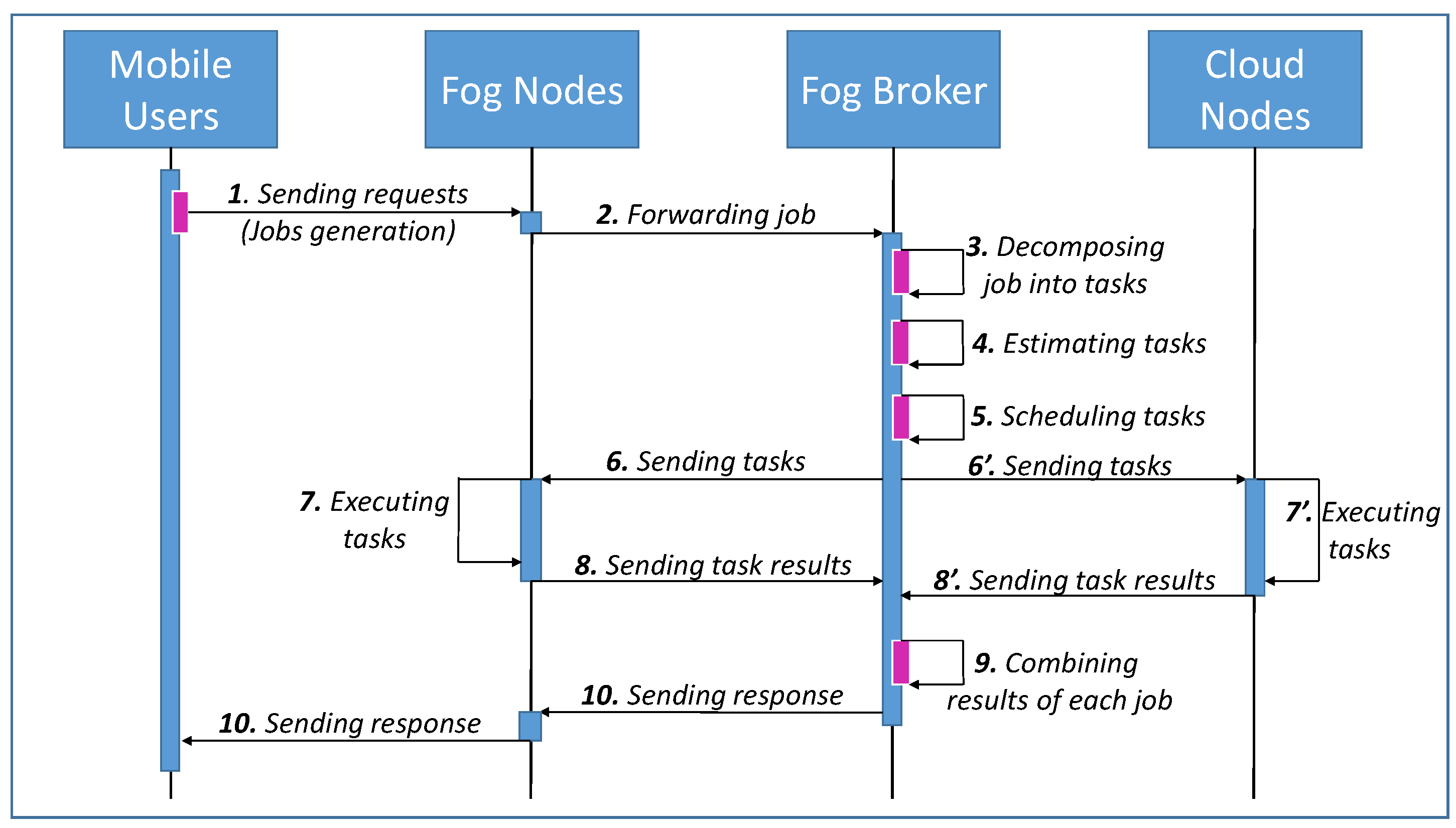
3.1. System Architecture
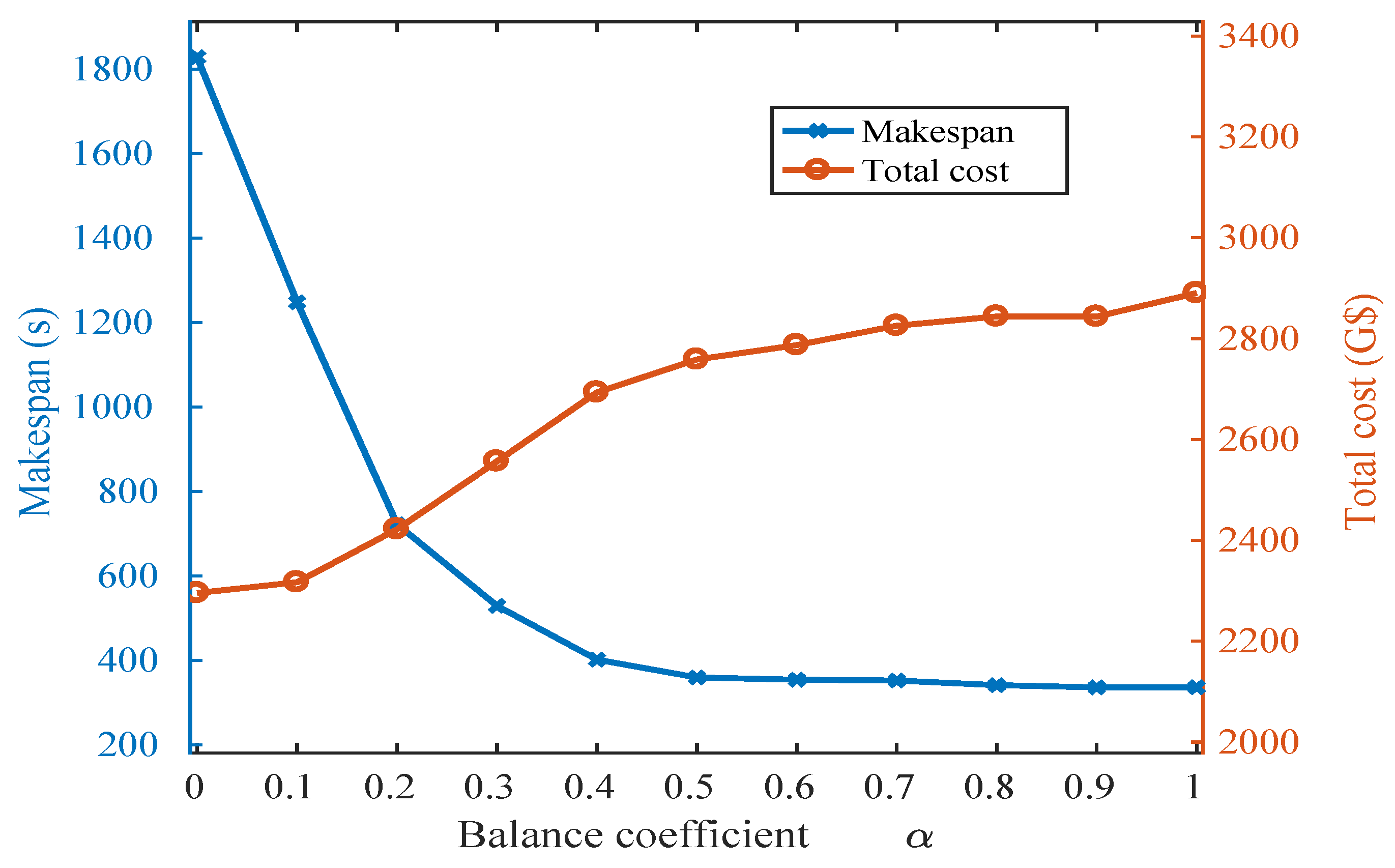
3.2. Problem Formulation
4. Evolutionary Algorithms for Task Scheduling Problem
4.1. Modified Particle Swarm Optimization
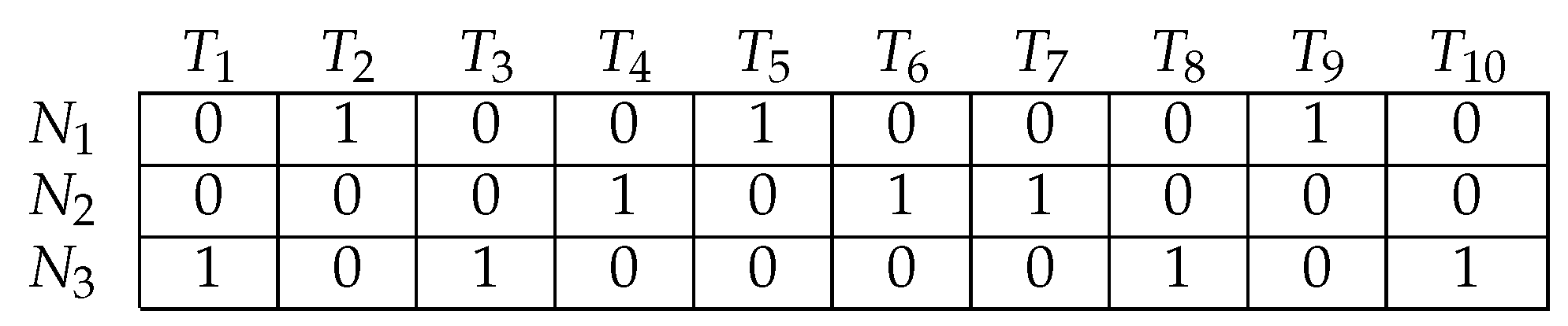
4.1.1. Particle: Position and Velocity
- i.
- ii.
4.1.2. Population Initialization
4.1.3. Fitness Function
4.1.4. Personal Best and Global Best
4.1.5. Particle Updating
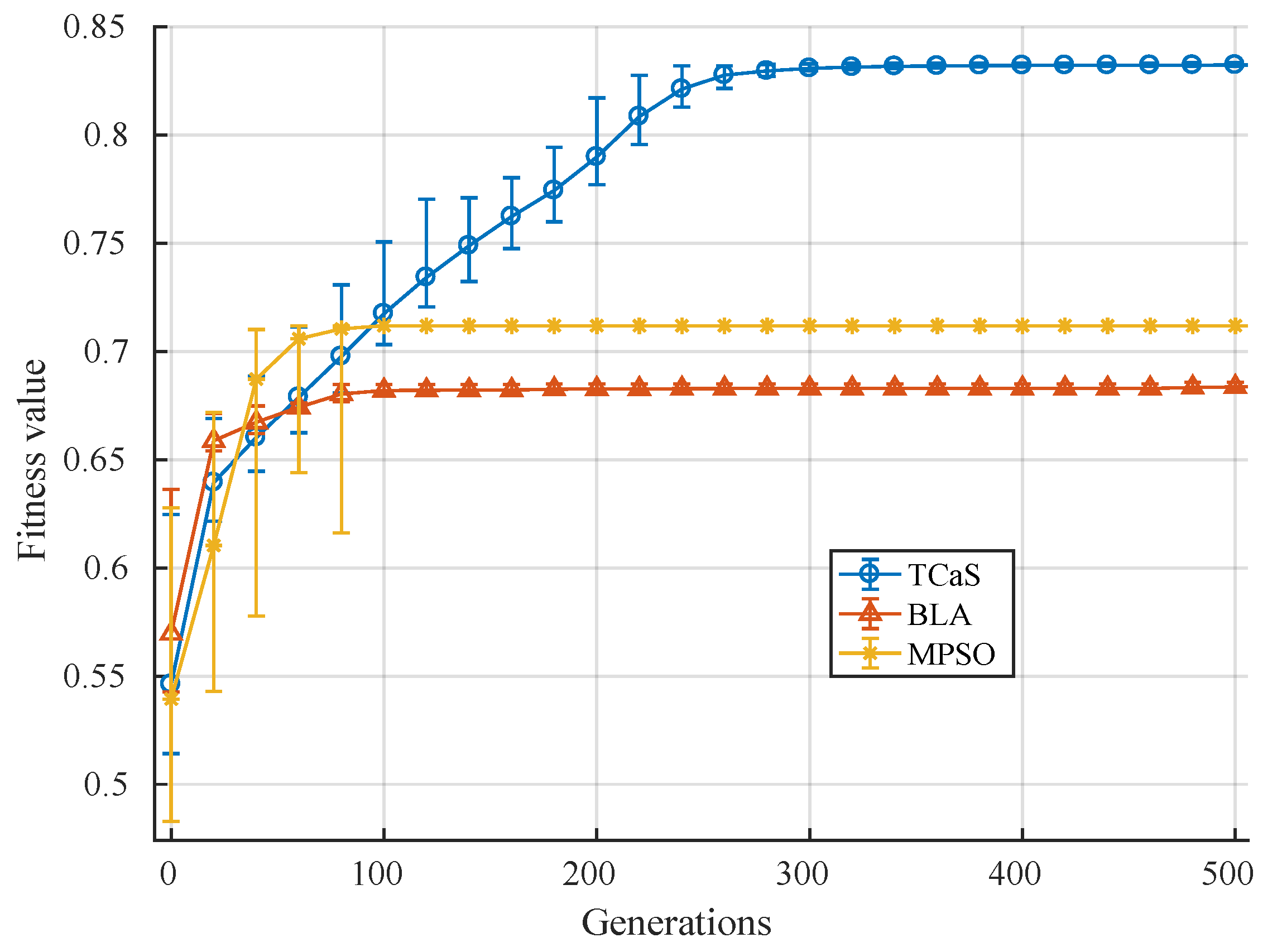
4.2. Proposed Evolutionary Algorithm
4.2.1. Encoding of Chromosomes
4.2.2. Population Initialization
4.2.3. Fitness Function
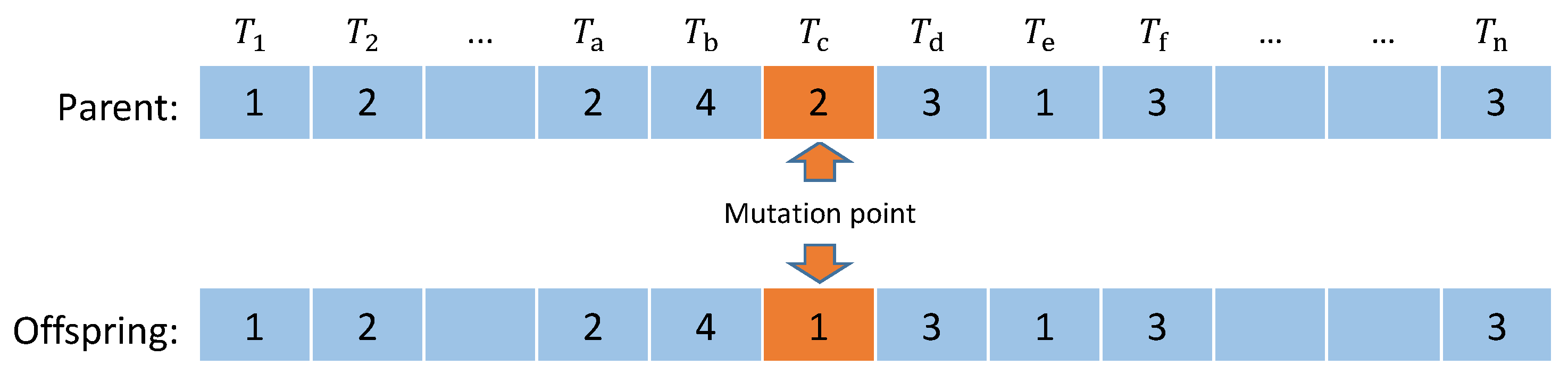
4.2.4. Genetic Operators
- Parental selection: In the crossover process, each individual in the population is considered to be the first parent, and the second parent was selected by the roulette wheel technique.
- Greedy selection strategy: Each crossover operation produces one offspring, which is preserved to form the next-generation population if it is better than first parent and discarded otherwise.
5. Performance Evaluation
5.1. Experimental Settings
5.2. Experimental Results
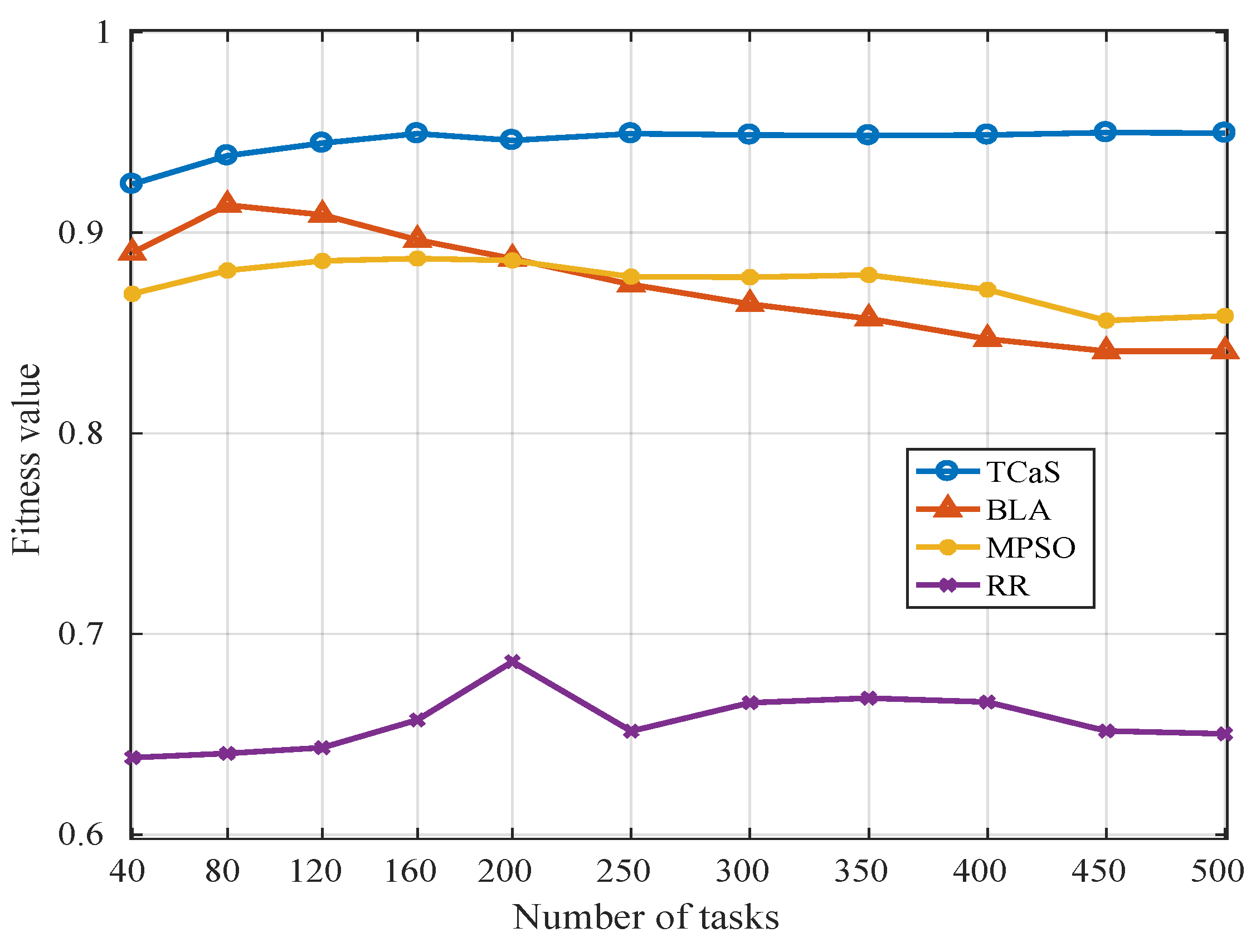
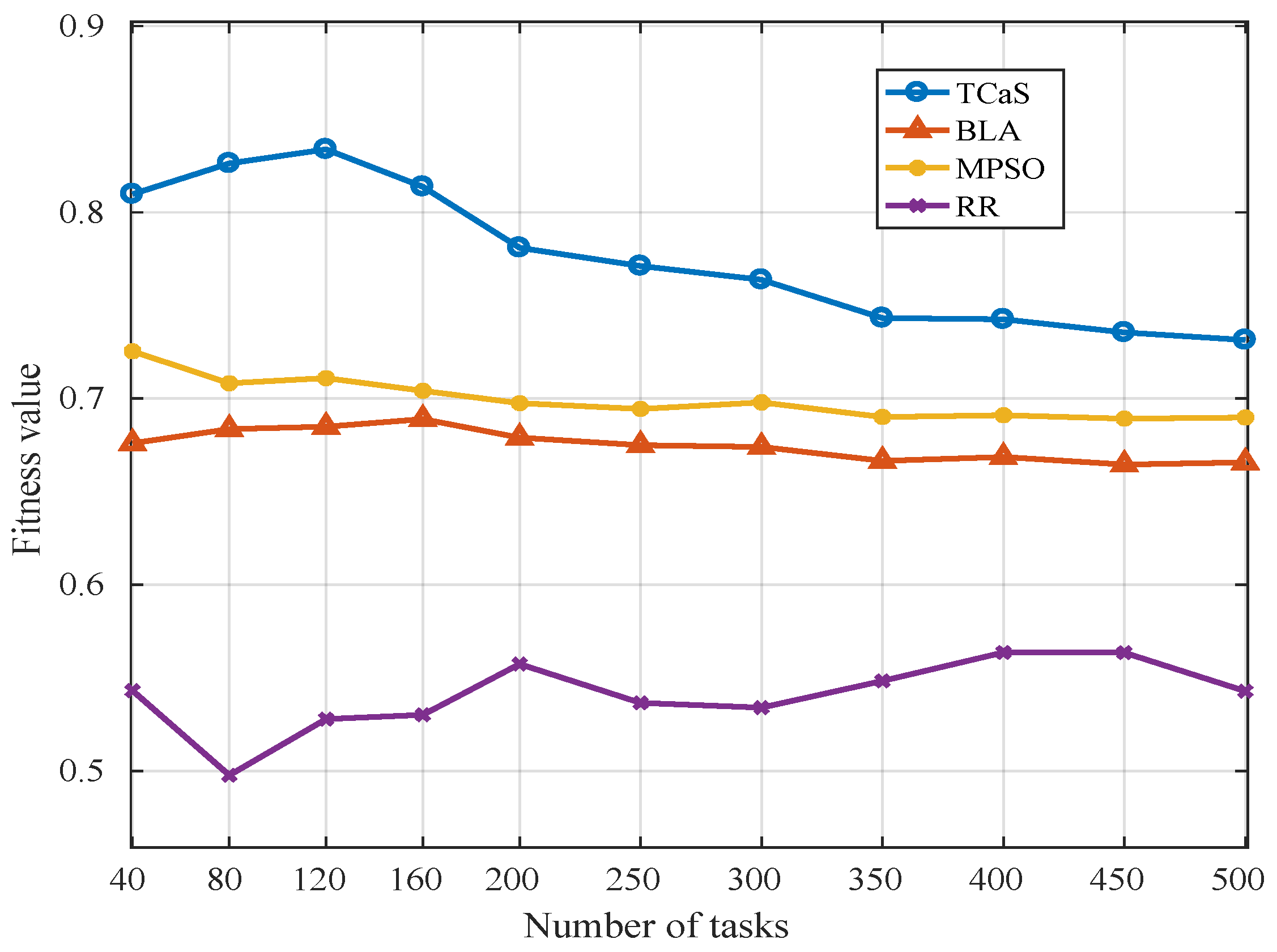
5.2.1. Scenario 1: Task Scheduling in Fog Environment
5.2.2. Scenario 2: Task Scheduling in Cloud–Fog Environment
6. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are. Cisco White Paper. 2015. Available online: https://www.cisco.com/c/dam/en_us/solutions/trends/iot/docs/computing-overview.pdf (accessed on 25 November 2018).
- Stiles, J.R.; Bartol, T.M.; Salpeter, E.E.; Salpeter, M.M. Monte Carlo Simulation of Neuro- Transmitter Release Using MCell, a General Simulator of Cellular Physiological Processes. In Computational Neuroscience; Bower, J.M., Ed.; Springer: Boston, MA, USA, 1998. [Google Scholar]
- Smallen, S.; Casanova, H.; Berman, F. Applying Scheduling and Tuning to On-line Parallel Tomography. In Proceedings of the Proceedings of the 2001 ACM/IEEE conference on Supercomputing, Denver, CO, USA, 10–16 November 2001. [Google Scholar]
- Bitam, S.; Zeadally, S.; Mellouk, A. Fog computing job scheduling optimization based on bees swarm. Enterp. Inf. Syst. 2017, 12, 373–397. [Google Scholar] [CrossRef]
- Peter, N. Fog computing and its real time applications. Int. J. Emerg. Technol. Adv. Eng. 2015, 5, 266–269. [Google Scholar]
- Chiang, M.; Zhang, T. Fog and IoT: An overview of research opportunities. IEEE Internet Things J. 2016, 3, 854–864. [Google Scholar] [CrossRef]
- Shi, Y.; Ding, G.; Wang, H.; Roman, H.E.; Lu, S. The fog computing service for healthcare. In Proceedings of the 2015 2nd International Symposium on Future Information and Communication Technologies for Ubiquitous HealthCare (Ubi-HealthTech), IEEE, Beijing, China, 28–30 May 2015; pp. 1–5. [Google Scholar]
- Yi, S.; Li, C.; Li, Q. A survey of fog computing: Concepts, applications and issues. In Proceedings of the 2015 Workshop on Mobile Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 37–42. [Google Scholar]
- Suárez-Albela, M.; Fernández-Caramés, T.; Fraga-Lamas, P.; Castedo, L. A practical evaluation of a high-security energy-efficient gateway for IoT fog computing applications. Sensors 2017, 17, 1978. [Google Scholar] [CrossRef] [PubMed]
- Bonomi, F.; Milito, R.; Natarajan, P.; Zhu, J. Fog computing: A platform for internet of things and analytics. In Big Data and Internet of Things: A Roadmap for Smart Environments; Springer: Berlin, Germany, 2014; pp. 169–186. [Google Scholar]
- Yousefpour, A.; Ishigaki, G.; Jue, J.P. Fog computing: Towards minimizing delay in the internet of things. In Proceedings of the 2017 IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 25–30 June 2017; pp. 17–24. [Google Scholar]
- Lee, K.; Kim, D.; Ha, D.; Rajput, U.; Oh, H. On security and privacy issues of fog computing supported Internet of Things environment. In Proceedings of the 2015 6th International Conference on the Network of the Future (NOF), Montreal, QC, Canada, 30 September–2 October 2015; pp. 1–3. [Google Scholar]
- Hong, K.; Lillethun, D.; Ramachandran, U.; Ottenwälder, B.; Koldehofe, B. Mobile fog: A programming model for large-scale applications on the internet of things. In Proceedings of the Second ACM SIGCOMM Workshop on Mobile Cloud Computing, Hong Kong, China, 16 August 2013; pp. 15–20. [Google Scholar]
- Mahmud, R.; Kotagiri, R.; Buyya, R. Fog computing: A taxonomy, survey and future directions. In Internet of Everything; Springer: Singapore, 2018; pp. 103–130. [Google Scholar]
- Binh, H.T.T.; Anh, T.T.; Son, D.B.; Duc, P.A.; Nguyen, B.M. An Evolutionary Algorithm for Solving Task Scheduling Problem in Cloud–Fog Computing Environment. In Proceedings of the SOICT 9th Symposium on Information and Communication Technology, Da Nang City, Vietnam, 6–7 December 2018; pp. 397–404. [Google Scholar]
- Gu, L.; Zeng, D.; Guo, S.; Barnawi, A.; Xiang, Y. Cost efficient resource management in fog computing supported medical cyber-physical system. IEEE Trans. Emerg. Top. Comput. 2017, 5, 108–119. [Google Scholar] [CrossRef]
- Deng, R.; Lu, R.; Lai, C.; Luan, T.H.; Liang, H. Optimal workload allocation in fog-cloud computing toward balanced delay and power consumption. IEEE Internet Things J. 2016, 3, 1171–1181. [Google Scholar] [CrossRef]
- Guo, X.; Singh, R.; Zhao, T.; Niu, Z. An index based task assignment policy for achieving optimal power-delay tradeoff in edge cloud systems. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 1–7. [Google Scholar]
- Ningning, S.; Chao, G.; Xingshuo, A.; Qiang, Z. Fog computing dynamic load balancing mechanism based on graph repartitioning. China Commun. 2016, 13, 156–164. [Google Scholar] [CrossRef]
- Oueis, J.; Strinati, E.C.; Barbarossa, S. The fog balancing: Load distribution for small cell cloud computing. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference (VTC Spring), Glasgow, UK, 11–14 May 2015; pp. 1–6. [Google Scholar]
- Abdi, S.; Motamedi, S.A.; Sharifian, S. Task scheduling using modified PSO algorithm in cloud computing environment. In Proceedings of the International Conference on Machine Learning, Electrical and Mechanical Engineering, Dubai, UAE, 8–9 January 2014; pp. 8–9. [Google Scholar]
- He, J.; Cheng, P.; Shi, L.; Chen, J.; Sun, Y. Time synchronization in WSNs: A maximum-value-based consensus approach. IEEE Trans. Autom. Control 2014, 59, 660–675. [Google Scholar] [CrossRef]
- Li, D.; Sun, X. Nonlinear Integer Programming; Springer Science & Business Media: Berlin, Germany, 2006; Volume 84. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Naval Res. Logist. (NRL) 2005, 52, 7–21. [Google Scholar] [CrossRef] [Green Version]
- Izakian, H.; Tork Ladani, B.; ZamanifarAjith, A. A Novel Particle Swarm Optimization Approach for Grid Job Scheduling; Springer: Berlin/Heidelberg, Germany, 2009; Volume 31, pp. 100–109. [Google Scholar]
- Gupta, H.; Dastjerdi, A.V.; Ghosh, S.K.; Buyya, R. iFogSim: A Toolkit for Modeling and Simulation of Resource Management Techniques in Internet of Things. Edge Fog Comput. Environ. 2017, 47, 1275–1296. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Cloud Computing | Fog Computing |
|---|---|---|
| Latency | High | Low |
| Response time of the system | Low | High |
| Architecture | Centralized | Distributed |
| Communication with devices | From a distance via Internet, Multiple hops | Directly from the edge via Various protocols and standards, One hop |
| Data processing | Far from the source of information in long-term time | Close to the source of information in short-term time |
| Computing capabilities | Higher (Cloud Computing does not provide any reduction in data while sending or transforming data) | Lower (Fog Computing reduces the amount of data sent to Cloud computing.) |
| Server nodes | Few nodes with scalable storage and computing power | Very large nodes with limited storage and computing power |
| Security | Less secure, Undefined | More secure, Can be defined |
| Working environment | Warehouse-size building with air conditioning systems | Outdoor (e.g., Streets, gardens) or indoor (e.g., Restaurants) |
| Location of server nodes | Within the Internet | At the edge of the local network |
| Article | Ideas | Improvement Criteria | Limitation |
|---|---|---|---|
| Huynh Thi Thanh Binh (2018) [15] | genetic algorithm | execution time, processing cost | small dataset |
| Bitam et al. (2017) [4] | bee life algorithm | execution time, memory | small dataset, only in Fog environment |
| Gu et al. (2017) [16] | two-phase linear programming-based heuristic | communication cost, apply for cellular network | no computational offloading capability |
| Deng et al. (2016) [17] | nonlinear integers, Hungarian method | power consumption, delay | suitable for centralized infrastructure, not easy to apply to Fog computing |
| Guo et al. (2016) [18] | Markov decision problems | power consumption, delay | a continuous-time queueing system |
| Ningning et al. (2016) [19] | graph partitioning, a minimum spanning tree | execution time | complexity when the number of user requests increases |
| Queis et al. (2015) [20] | heuristic | user satisfaction, task latency, power consumption | complexity when the number of user requests increases |
| Abdi et al. (2014) [21] | particle swarm optimization | completion of task | in Cloud environment |
| Parameter | Fog Environment | Cloud Environment | Unit |
|---|---|---|---|
| Number of nodes | 10 | 3 | node |
| CPU rate | MIPS | ||
| CPU usage cost | G$/s | ||
| Memory usage cost | G$/MB | ||
| Bandwidth usage cost | G$/MB |
| Property | Value | Unit |
|---|---|---|
| Number of instructions | instructions | |
| Memory required | MB | |
| Input file size | MB | |
| Output file size | MB |
| System | Intel® Core i7-4710MQ, CPU 2.50GHz |
| Memory | 8 GB |
| Simulator | iFogSim |
| Operating system | Windows 10 Professional |
| Parameter | BLA | TCaS | MPSO | |
|---|---|---|---|---|
| Running times | 30 | 30 | 30 | |
| queen | 1 | |||
| drones | 30 | |||
| Population size () | workers | 69 | 100 | 100 |
| Crossover rate | 90% | 90% | ||
| Mutation rate | 1% | 1% | ||
| Number of generations | 500 | 500 | 500 | |
| Number of Tasks | Makespan (s) | Total Cost (G$) | ||||||
|---|---|---|---|---|---|---|---|---|
| TCaS | BLA | MPSO | RR | TCaS | BLA | MPSO | RR | |
| 40 | 191.44* | 207.57 | 215.27 | 456.11 | 733.85 | 730.88 | 740.38 | 755.98 |
| 80 | 394.69 | 416.09 | 445.35 | 963.08 | 1540.23 | 1540.85 | 1553.43 | 1581.82 |
| 120 | 607.71 | 654.92 | 686.20 | 1495.66 | 2363.37 | 2367.59 | 2381.16 | 2418.90 |
| 160 | 819.97 | 917.67 | 932.33 | 1912.08 | 3176.17 | 3183.80 | 3197.01 | 3246.69 |
| 200 | 940.87 | 1067.49 | 1065.94 | 1905.70 | 3755.21 | 3767.37 | 3778.27 | 3835.40 |
| 250 | 1,270.96 | 1490.65 | 1479.84 | 3054.80 | 4988.94 | 5017.17 | 5007.59 | 5079.06 |
| 300 | 1,473.79 | 1765.49 | 1712.76 | 3309.14 | 5832.69 | 5877.41 | 5862.52 | 5935.94 |
| 350 | 1,649.04 | 2010.74 | 1911.27 | 3638.19 | 6607.52 | 6653.37 | 6632.38 | 6738.19 |
| 400 | 1,944.58 | 2421.98 | 2300.51 | 4347.64 | 7738.56 | 7816.04 | 7759.95 | 7875.39 |
| 450 | 2,235.16 | 2840.79 | 2751.29 | 5350.35 | 8845.90 | 8926.57 | 8876.30 | 9016.59 |
| 500 | 2,503.09 | 3174.39 | 3067.26 | 6023.74 | 9902.64 | 9995.97 | 9921.76 | 10,097.75 |
| Number of Tasks | Makespan (s) | Total Cost (G$) | ||||||
|---|---|---|---|---|---|---|---|---|
| TCaS | BLA | MPSO | RR | TCaS | BLA | MPSO | RR | |
| 40 | 114.37* | 185.37 | 157.41 | 313.01 | 861.53 | 811.34 | 811.45 | 859.96 |
| 80 | 232.91 | 368.78 | 352.50 | 965.32 | 1817.90 | 1732.46 | 1689.26 | 1793.53 |
| 120 | 357.42 | 580.29 | 546.70 | 1267.54 | 2779.72 | 2639.79 | 2583.55 | 2687.34 |
| 160 | 515.38 | 776.68 | 763.41 | 1729.19 | 3694.69 | 3543.08 | 3464.33 | 3587.65 |
| 200 | 633.28 | 894.42 | 873.06 | 1521.44 | 4403.63 | 4247.69 | 4134.09 | 4323.92 |
| 250 | 816.59 | 1127.48 | 1112.33 | 2190.21 | 5485.85 | 5349.45 | 5155.44 | 5411.28 |
| 300 | 1052.92 | 1436.58 | 1375.54 | 2861.95 | 6740.36 | 6591.75 | 6405.11 | 6666.58 |
| 350 | 1241.28 | 1628.91 | 1583.82 | 2835.65 | 7666.27 | 7535.36 | 751.25 | 7610.78 |
| 400 | 1486.92 | 1925.29 | 1864.29 | 3139.76 | 8877.14 | 8763.91 | 882.87 | 8792.12 |
| 450 | 1754.18 | 2251.06 | 2168.70 | 3653.46 | 10,124.56 | 10,033.83 | 9682.45 | 10,026.13 |
| 500 | 1994.21 | 2512.40 | 2425.86 | 4633.48 | 11,299.53 | 11,219.18 | 10,823.84 | 11,266.31 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, B.M.; Thi Thanh Binh, H.; The Anh, T.; Bao Son, D. Evolutionary Algorithms to Optimize Task Scheduling Problem for the IoT Based Bag-of-Tasks Application in Cloud–Fog Computing Environment. Appl. Sci. 2019, 9, 1730. https://doi.org/10.3390/app9091730
Nguyen BM, Thi Thanh Binh H, The Anh T, Bao Son D. Evolutionary Algorithms to Optimize Task Scheduling Problem for the IoT Based Bag-of-Tasks Application in Cloud–Fog Computing Environment. Applied Sciences. 2019; 9(9):1730. https://doi.org/10.3390/app9091730
Chicago/Turabian StyleNguyen, Binh Minh, Huynh Thi Thanh Binh, Tran The Anh, and Do Bao Son. 2019. "Evolutionary Algorithms to Optimize Task Scheduling Problem for the IoT Based Bag-of-Tasks Application in Cloud–Fog Computing Environment" Applied Sciences 9, no. 9: 1730. https://doi.org/10.3390/app9091730