A Compact Bat Algorithm for Unequal Clustering in Wireless Sensor Networks




1
Fujian Provincial Key Laboratory of Big Data Mining and Applications, Fujian University of Technology, Fuzhou, Fujian 350118, China
2
Intelligent Information Processing Research Center, Fujian University of Technology, Fuzhou, Fujian 350118, China
3
Department of Information Technology, Haiphong Private University, Haiphong 180000, Vietnam
4
College of Computer Science and Engineering, Shandong University of Science and Technology, Qingdao 266510, China
5
College of Informatics, Chaoyang University of Science and Technology, Taichung 413, Taiwan
*
Authors to whom correspondence should be addressed.
Appl. Sci. 2019, 9(10), 1973; https://doi.org/10.3390/app9101973
Submission received: 6 April 2019
/
Revised: 2 May 2019
/
Accepted: 7 May 2019
/
Published: 14 May 2019
(This article belongs to the Section Computing and Artificial Intelligence)
Abstract
:Everyday, a large number of complex scientific and industrial problems involve finding an optimal solution in a large solution space. A challenging task for several optimizations is not only the combinatorial operation but also the constraints of available devices. This paper proposes a novel optimization algorithm, namely the compact bat algorithm (cBA), to use for the class of optimization problems involving devices which have limited hardware resources. A real-valued prototype vector is used for the probabilistic operations to generate each candidate for the solution of the optimization of the cBA. The proposed cBA is extensively evaluated on several continuous multimodal functions as well as the unequal clustering of wireless sensor network (uWSN) problems. Experimental results demonstrate that the proposed algorithm achieves an effective way to use limited memory devices and provides competitive results.
1. Introduction
The metaheuristic algorithms have emerged as a potential tool for solving complex optimization problems. The bat algorithm (BA) is a novel metaheuristic search algorithm [1,2], which simulates the behavior of the bat species for searching prey. Preliminary studies show that it is very promising and could outperform existing algorithms [3]. The BA utilizes a population of bats to represent candidate solutions in a search space and optimizes the problem by iteration to move these agents to the best solutions about a given measure of quality. The general steps of this algorithm are described in the next section.
The original BA is able to solve problems with continuous search space, and in addition, several versions of the algorithm are also proposed in the literature to solve problems with continuous and discrete search spaces. The evolved bat algorithm (EBA) is used for numerical optimization and the economic load dispatch problem [4,5]. A hybrid between the BA and the artificial bee colony (ABC) is used for solving numerical optimization problems [6]. Several discrete BAs have been proposed in the literature, in addition to the continuous BAs. A binary BA (BBA) was proposed to solve the feature selection problem [7], and its solution is restricted to a vector of binary positions using a sigmoid function. The BBA algorithm uses a V-shaped transfer function to map velocity values to probability values in order to update the positions [8]. This BBA has been used in several tasks, e.g., it was adopted in [9] as the feature selection part of a fault diagnosis scheme for failures of incipient low-speed rolling element bearings. As another example, a chaotic version of the algorithm, namely CBBA, was used to select points in an analog circuit diagnosis system [10]. A similar BBA algorithm, with a multi V-shaped version of the transfer function, was adopted in order to solve a large scale 0–1 knapsack problem [11]. A discrete version of BA was parallelized (called PBA) for optimizing makespan in job shop scheduling problems [12]. Another discrete BA was used to address the optimal permutation of the flow shop scheduling problem [13] and discrete BA was adopted to solve the symmetric and asymmetric Traveling salesman problem (TSP) [14].
Moreover, rapid growth in the field of integrated circuits (IC) and information technology (IT) has led to the development of inexpensive and tiny-size sensor nodes in a wireless sensor network (WSN). A WSN is composed of a vast number of sensor nodes arranged in an ad hoc fashion to observe and interact with the physical world [15]. The sensors capture the environmental information which is processed and forwarded to the base station (BS) via middle nodes or single hop [16]. A WSN detects and measures (or monitors) a number of physical or environmental conditions such as multimedia [17,18], infrared energy emitted from objects and converted to temperature [19], pollutant levels [20], ultrasound in medical imaging [21], vibrations [22], security and surveillance [23], agriculture [24], and many other such conditions. Usually, a WSN is carried out in areas that are difficult to access and intervention is not possible by people. In a harsh environment, it is difficult or not possible to recharge or replace batteries used in the sensors of a WSN [25]. The energy consumption, memory, and bandwidth are the key factors that influence a good WSN design.
Applications of WSNs have become widely accessible in some fields, e.g., military surveillance, agriculture, disaster management, healthcare monitoring, industry automation, inventory control, and so forth [26,27]. However, WSNs are networks of small, battery-powered, memory-constrained sensor nodes. Sensor nodes in WSN are an example of hardware devices that are limited by conditions due to the cost, storage, and space restriction. The optimization problem with a limited hardware resource becomes a challenging one [25].
Furthermore, in this paper one of our goals is based on a theorem of “no free lunch” which states that there is no metaheuristic algorithm best suited for solving all optimization problems [28]. It means that one algorithm might obtain excellent results on a given set of challenges but underperform on an alternative set of issues. Another goal in this paper is to consider the strength of different algorithms based on the types and properties of the problem.
In this paper, we extend our previous work of the compact bat algorithm (cBA) [2] for the unequal clustering of wireless sensor networks (uWSN) problems. By extending our work we aim to deal with the issues of saving variable memory and selecting parameters according to the unequal clustering problem of WSNs. The reasons for extending our work include an added need to control the probability of sampling for perturbation vector, a set of tests for benchmark functions, a solution to the unequal clustering problem, and an extensive comparison with other compact algorithms in the literature. A real-valued prototype vector is used for the probabilistic operations to generate each candidate for solving the optimization of the cBA. The proposed cBA is extensively evaluated on several continuous multimodal functions as well as the unequal clustering of wireless sensor network (uWSN) problems.
2. Related Work
2.1. Unequal Clustering in Wireless Sensor Network (WSN)
Clustering and unequal clustering techniques have been used for an energy efficient WSN. Clusters in WSNs are carried out by grouping sensor nodes into a partitioned set. One of the nodes in the partitioned set is selected to be a cluster head (CH) that collects information from the cluster member nodes (CNs) [16,29]. Energy consumption of the CHs near the base station (BS) is more than the CHs farther from the BS. This means CHs close to the BS have a heavy traffic load because of intra-cluster traffic from its cluster members, data aggregation, and inter-cluster traffic from other CHs for relaying data to the BS. This disrupts the network connectivity, and the clusters close to the BS cause coverage issues that are called hot spot problems. The unequal clustering technique is one of the most efficient ways to deal with hot spot problems because it can be used for load balancing among the CHs [30].
The purpose of the unequal clustering method is the same as the equal clustering approach with adding functions. The clustered nodes are in WSN for different meanings based on the application demand. Energy saving and preventing hot spot problems are the major objectives. Unequal clustering arranges the clusters according to size with the size reduced closer to the BS. This means that the cluster size is directly proportional to the distance of the CHs from the BS. A smaller cluster near the BS indicates a smaller number of cluster members and less intra-cluster traffic. Therefore, the smaller clusters can concentrate more on inter-cluster traffic, and the cluster head does not drain out of energy as quickly. The more the distance to the BS increases, the more the cluster size increases. If the groups hold a more significant number of member nodes, they will spend more energy on intra-cluster traffic. As the clusters become farther from the BS, they have less inter-cluster traffic and do not need to expend more energy for inter-cluster routing. Unequal clustering forces all the CHs to spend the same amount of energy consumption, and therefore the CHs near the BS and the CHs farther from the BS consume an equal amount of energy.
Additionally, the cluster formation process may generate a two-level hierarchy with higher and lower levels [31,32]. The CH nodes form the upper-level cluster, and the member nodes create the lower level. The sensor nodes periodically transmit their data to the corresponding CH. The CHs aggregate the data and transmit them to the BS either directly or through the intermediate CH nodes. The CH performs data aggregation of all data received from its cluster members and forwards the aggregated data to the BS via a single hop or a multi-hop. The CH contains the information of its cluster members such as node id, location, and energy level. When a node dies or moves to another cluster, the changes are registered immediately and the CH informs the BS and reclustering occurs to maintain the network topology effectively. The number of transmissions and also the total load of the network are significantly reduced.
2.2. Energy Consumption in WSNs Model
Unequal clustering in a WSN with hundreds or thousands of sensor nodes is an efficient way to organize such a vast number of nodes, uniformly distribute load, and prevent hot spot problems [33]. However, the equal clustering approach often has cluster size which is the same throughout the network. Admittedly, in unequal clustering, the cluster size is determined based on the distance to the BS. The cluster size is smaller when the distance to the BS is shorter, and the size increases as the distance to the BS increases.
The wireless radio transceiver in a WSN depends on the various parameters, e.g., distance and energy consumption. The definition is related to the power consumption and the ranges of the nodes referred to in [16]. The distance between the transmitter and receiver obeyed on the attenuated trans-receiving power decreases exponentially with increasing distance. A threshold separates the free space model and the multipath model.
where , are power loss for free space and multipath models, respectively, and is a threshold of space model. The transmitting l bits for dissipated energy over distance d is formulated as:
where is the power consumption of the node, Tx is for transmitting subscript elec, amp indicate electronic, and amplify for digital coding, modulating, filtering, and spreading signal. The energy consumption for receiving the messages can be expressed as:
WSN assumed implemented N nodes in the two-dimensional area of with k clusters. Let be the distance member node to the CH, and be the distance of the CHs to the BS. The consumed energy of a cluster for a data frame is modelled as:
where − 1 is the averaged member nodes in a cluster. and are the dissipated energy for CH and members. The calculated energy consumptions for cluster members and CHs are as follows:
The total consumed energy for a WSN could be formulated from the energy process and power transceiver as:
where is the power consumption of the microcontroller. It does not affect the optimizing processes. Thus, the power consumption of optimized is based on only the distance for clustering optimization.
3. Compact Bat Algorithm
The compact approach reproduces the operations of the population-based algorithms by building a probabilistic model for a population solution. The optimal process considers the actual population as a virtual community by encoding its probabilistic representation. The compact BA is constructed based on the framework of the BA. Before analyzing and designing the compact for BA, we review the bat-inspired algorithm in the following subsection.
3.1. Bat-Inspired Algorithm
A recent new population-based algorithm, BA [1] has drawn inspiration from the bat’s echolocation of the species called the microbats for searching prey. The updated solutions of BA are constructed based on three primary characteristics including echolocation, frequency, and loudness. Bats use echolocation to locate the prey, background frequency to send out the variable wavelength, and loudness to search the victim. Solutions for the BA are generated by adjusting parameters, e.g., frequencies, loudness, and pulse emission rates of the bats, according to the evaluation of the objective function. Formulas for updating the positions and velocities of BA in d-dimensional search space are as follows:
where is the frequency for adjusting velocity change, min and max the minimum and maximum frequency of the bats emitting the pulse, respectively, and is a generated vector randomly based on the distributed Gaussian ∈ [0, 1]. A frequency assigned initially for each bat in a uniform range ∈ [min, max]. BA updates the vectors of the bat locations and velocity x, and v in search space of d-dimensional.
where the superscript of is the current iteration, and is the global best solution. Generating new location of the bats in exploiting phase strategy is formulated as:
where is a random variable in the range , and indicates the weight for the loudness of the bats at the current generation. The loudness of bats is defined as:
where α is a variable constant. The symbol denotes the rate of the pulse emission and ∈ [0, 1]. The pulse emission rate is calculated as:
where is the constant variable. In the process, this rate is considered as the control to switch the global and local search. If a random number is greater than , a local search with a random walk is triggered.
3.2. Compact Bat Algorithm
The intention of the compact algorithm is to mimic the operations of the based-population algorithm of BA in a version with a much smaller stored variable memory. The actual population of solutions of the BA is transformed into the compact algorithm by constructing a distributed data structure, namely the perturbation vector (PV). PV is the probabilistic model for a population of solutions.
where and are two parameters of standard deviation and mean of vector PV, and t is the current time. The values of and are arranged within the probability density functions (PDF) [34] and are truncated in [−1, 1]. The amplitude of PDF is normalized by keeping its area equal to 1 because by obtaining approximately sufficient in well it is the uniform distribution with a full shape.
A real-valued prototype vector is used to maintain sampling probabilistic for randomly generating components of a candidate solution. This vector operation is distributed-based on the estimated distribution algorithm (EDA) [35]. Because a few new generating candidates are stored in the memory, it is not all of the population of solutions stored in memory. The likelihood is that the estimated distribution would trend, driving new candidate forward to the fitness function. Candidate solutions are generated probabilistically from the vector, and the components in the better solution are used to make small changes to the probabilities within the vector. A candidate solution corresponding to the location of the virtual bats is generated by .
where is the probability distribution of that formulated a truncated Gaussian PDF associated with the and . A new candidate solution is generated by being iteratively biased toward a promising area of an optimal solution. We can obtain each component of the probability vector by learning the previous generations. The is the error function found in [36]. PDF corresponds to the cumulative distribution function (CDF) by constructing Chebyshev polynomials [37]. The codomain of is arranged from 0 to 1. The can describe the real-valued random variable x with a given probability distribution, and the obtained value can be less than or equal to
CDFs also can specify the distribution of multivariate random variables. Thus, the relationship of PDF and CDF can be defined as . PV performs the sampling design variable by generating a random number in a range of (0, 1). This corresponds to obtaining this variable by computing the inverse function of set to inverse (CDF).
To find the better individual in the process of the compact algorithm, a comparison of the two design variables is conducted. The two variable agents of the bats are two sampled individuals who performed from PV. The “winner” indicates the vector with the fitness scores that are higher than other members, and the “loser” is shown according to the individual lower fitness evaluation. The two returned variables, and , are from objective function evaluation that compare a new candidate with the previous global best. For updating PV, are considered based on the following rules. If the mean value of is regarded to 1, the update rule for each of its elements is as given in the equation below:
where denotes virtual population. With respect to values, the update rule of each element is given as:
In general, a probabilistic model for compact BA is employed to represent the bat solution set where neither the location nor the velocities are stored, however, a newly generated candidate is stored. Thus, modest memory space is required, and it is well suited for the limited hardware resources in WSNs.
A parameter is used as a weight to control the probability of sampling of in PDF as Equation (15) between left [−1, ] that is and right [, 1] that is . The extended version Equation (15) of PDF for sampling approach is applied in this paper. The generating new candidates of the bats are employed by sampling from such as when r < ω then it generates the coefficient for otherwise for . The details for compact BA are as follows:
Step 1 Initialization: and of the probabilistic model vector PV.
Step 2 Initialize parameters: the pulse rate , the loudness i, and are set to random; search range definition of pulse frequency .
Step 3 Generate the global best solution by means of perturbation vector PV; assign min to fitness ().
Step 4 Generate the local best solution from .
Step 5 Update velocities vt and locations according to updating rule of the standard BA algorithm, Equations (8)–(10); if (), select a local solution around selected best solution as Equation (11); assign the function value new to fitness
Step 6 Compare and , let one be the winner, and the other one is the loser according to Equation (16).
Step 7 Update according to Equations (17) and (18).
Step 8 A new solution is accepted if the solution improves ( less than ), and not too loud ( less than ) then update global best to and assign function to .
Step 9 If the termination condition is not met, go to step 4.
Step 10 Output the global best solution .
4. Experiments with Numerical Problems
To validate the quality performance of the proposed algorithm, we select ten optimal numerical problems [38] to prove the accuracy and rate of the cBA. The cBA measurements are compared with the original bat algorithm (oBA) with respect to solution quality. The two techniques used to verify the performance of the proposed cBA include similarity measure and time complexity analysis. The similarity measure uses a probability cosine with an adopted Pearson’s correlation coefficient that considers the measured ratio (r) for two result solutions. The time complexity analysis uses the number of related variables employed in the optimization process. All the selected test functions for the outcomes of the experiment averaged over 25 runs. Minimized outcomes of optimization are calculated for all functions. Let X = {x1, x2, …, xn} be the n-population size real-value vector. The related initial data of test functions, i.e., range boundaries, max iteration, and dimension are listed in Table 1.
Initial setting of parameters for the two algorithms of cBA and oBA are set such as loudness of A is set to 0.25, pulse rate is set to 0.5, virtual population size is set to 40, dimension is set to 30, minimum/maximum frequency (, ) are set to initial boundaries of the lowest and highest of range functions, maxiteration is set to 5000, and the number runs is set to 25. The final result is obtained by taking the average of the outcomes from all runs. The obtained results of cBA are compared with the oBA.
A comparison of the quality of performance and running time for the optimization problems of the cBA with oBA methods are shown in Table 2. Data in the oBA and the cBA columns in Table 2 represents the averaged outcomes of 25 runs for the original bat algorithm and the compact bat algorithm, respectively. Rate deviation (RD) is a rated deviation that represents the percentage of the deviation on the primary bat algorithm outcomes for the cBA, respectively. Clearly, almost all cases of benchmark functions for optimizing in both cBA and oBC have a small percentage of deviation. It shows that the accuracy of the cBA is as good as that of the oBA. The average percentage of deviation for ten test-function evaluations is only 3%. However, the average time consumption of cBA is 24% faster than that of oBA.
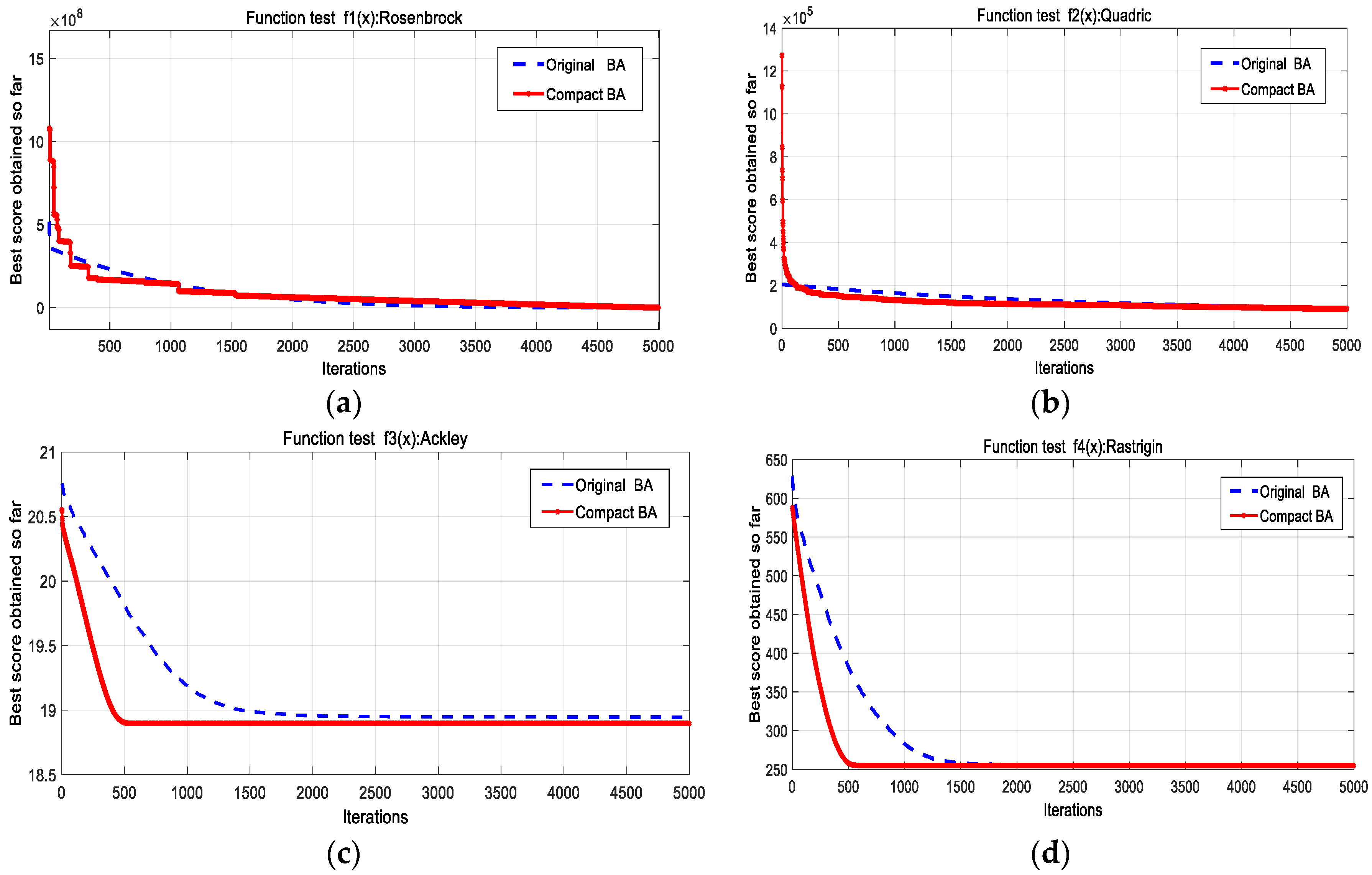
Figure 1 shows the curves of cBA and oBA with the average obtained minimum for four first test functions. It should be noted that all of these cases of test benchmark functions for cBA (red lines) are equal to or faster than oBA in convergence.
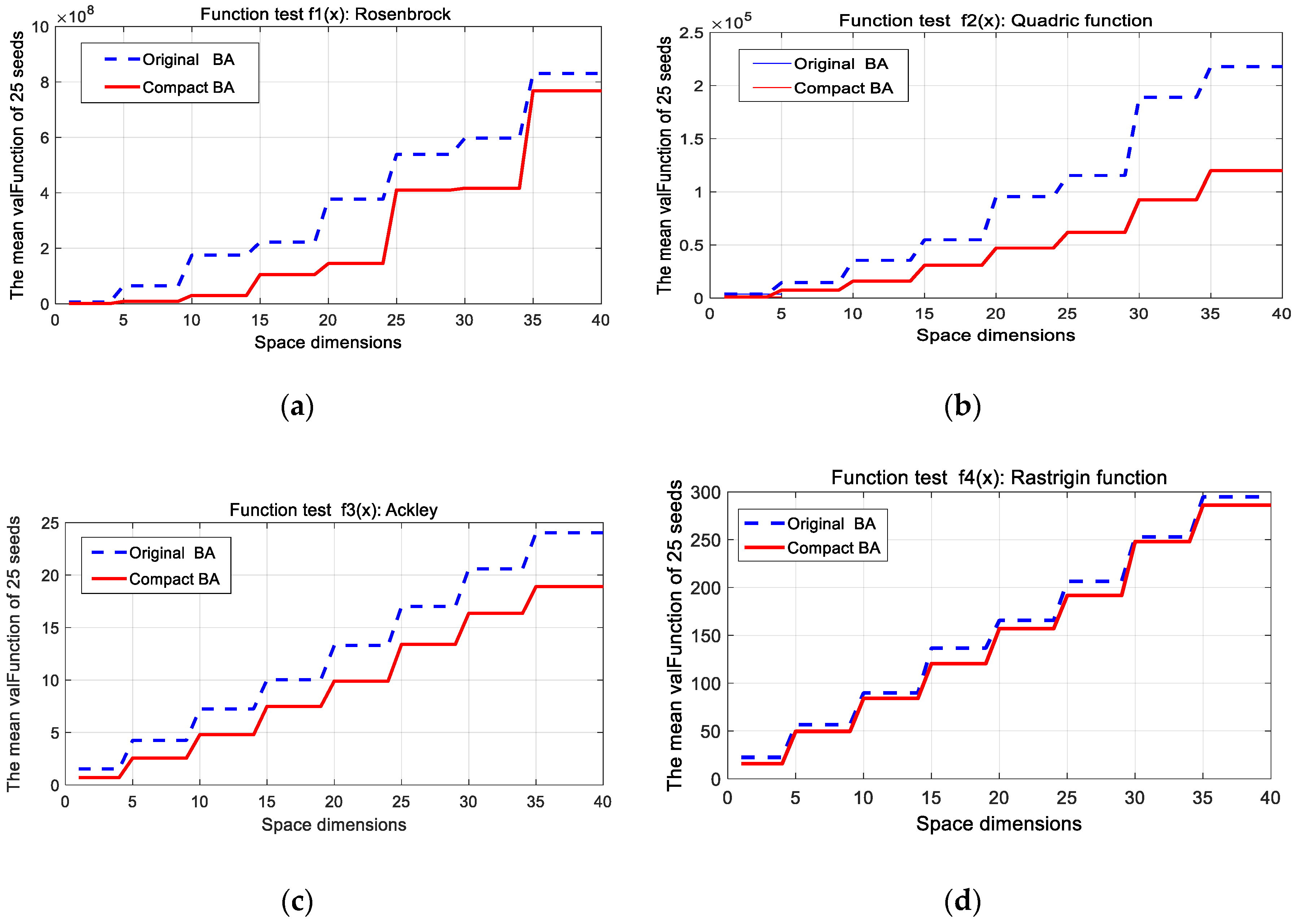
To verify the effect of population sizes on the performance of the algorithms, we used variety N for testing. Figure 2 compares the performance quality of running with different population sizes for test functions between cBA and oBA. Doubtless, most cases for testing functions in the cBA are faster than and uniform in convergence that applied for BA. The convergence of most cases of test functions for employing in cBA is not affected very much by the variety population size. Because it is a virtual population the mean value of results did not fluctuate and was more stable than that of oBA.
Table 3 shows the comparison of the proposed cBA with the oBA in terms of the occupied memory variables for implementing computations in running optimization. The number of variables of the two algorithms is counted for through the number of the equations used in operations optimization. Observations from Table 3 would clearly show that the number of variables of cBA use is smaller than the oBA with the same condition of computation, e.g., iterations. There are four number equations for oBA, e.g., (8)–(11) and eight equations for cBA, e.g., (8)–(11), and (15)–(18).
However, the real population or population size of oBA is N, whereas, cBA is only one. With the same number of iterations and the running time T, the stored slots of variables for oBA and cBA are 4 × T × N × iteration, and 8 × T × iteration, respectively, where T and N are the counting run time and the number of population, respectively. It is observed that the number of occupied slots in oBA is higher (N/2 times) than in cBA.
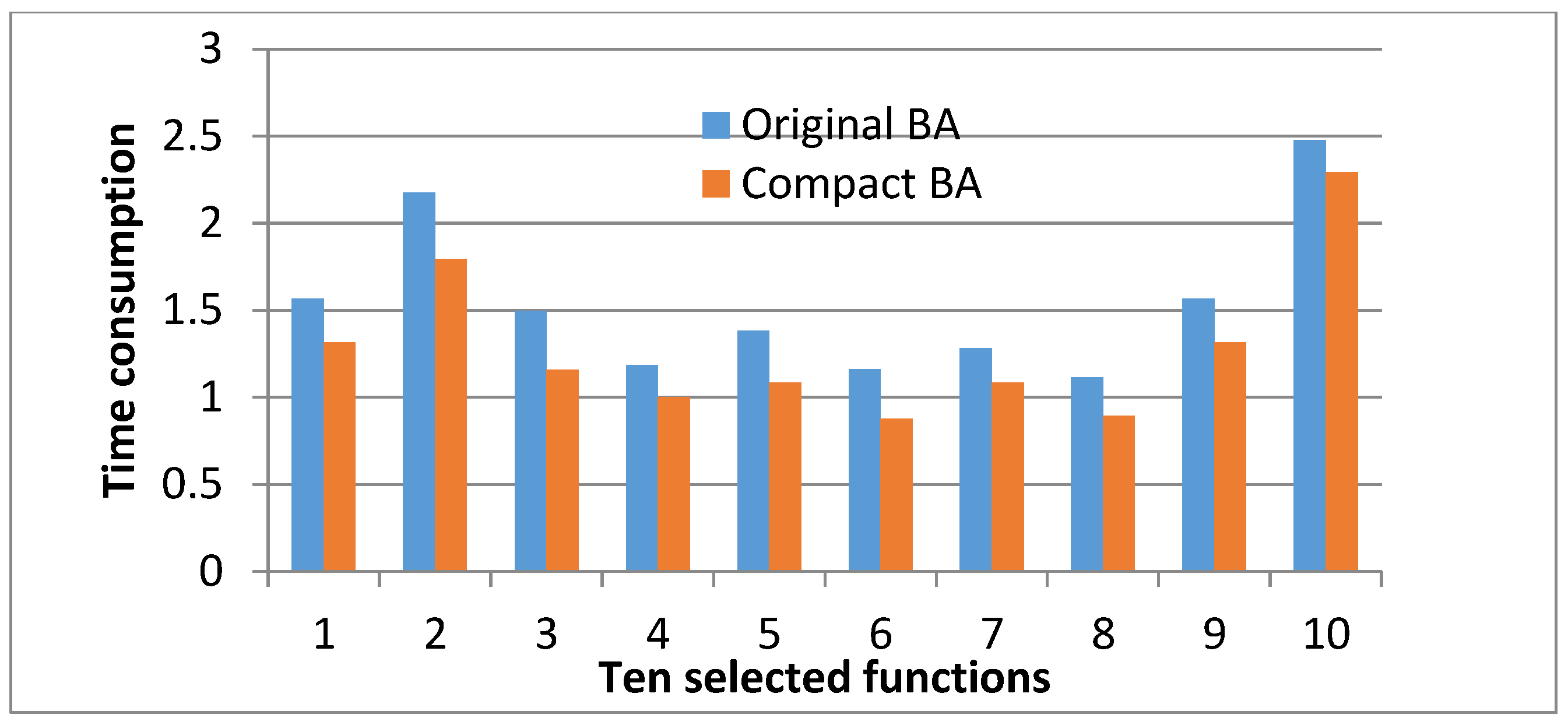
Figure 3 illustrates a comparison of executing times of the cBA with oBA over 25 runs for ten benchmark functions. Clearly, all cases of testing duties of cBA are smaller than those obtained for oBA. The average consuming time of cBA for tests is 24% faster than oBA. The reason for the rapid result is that some of the memory-stored parameters for cBA are smaller than oBA.
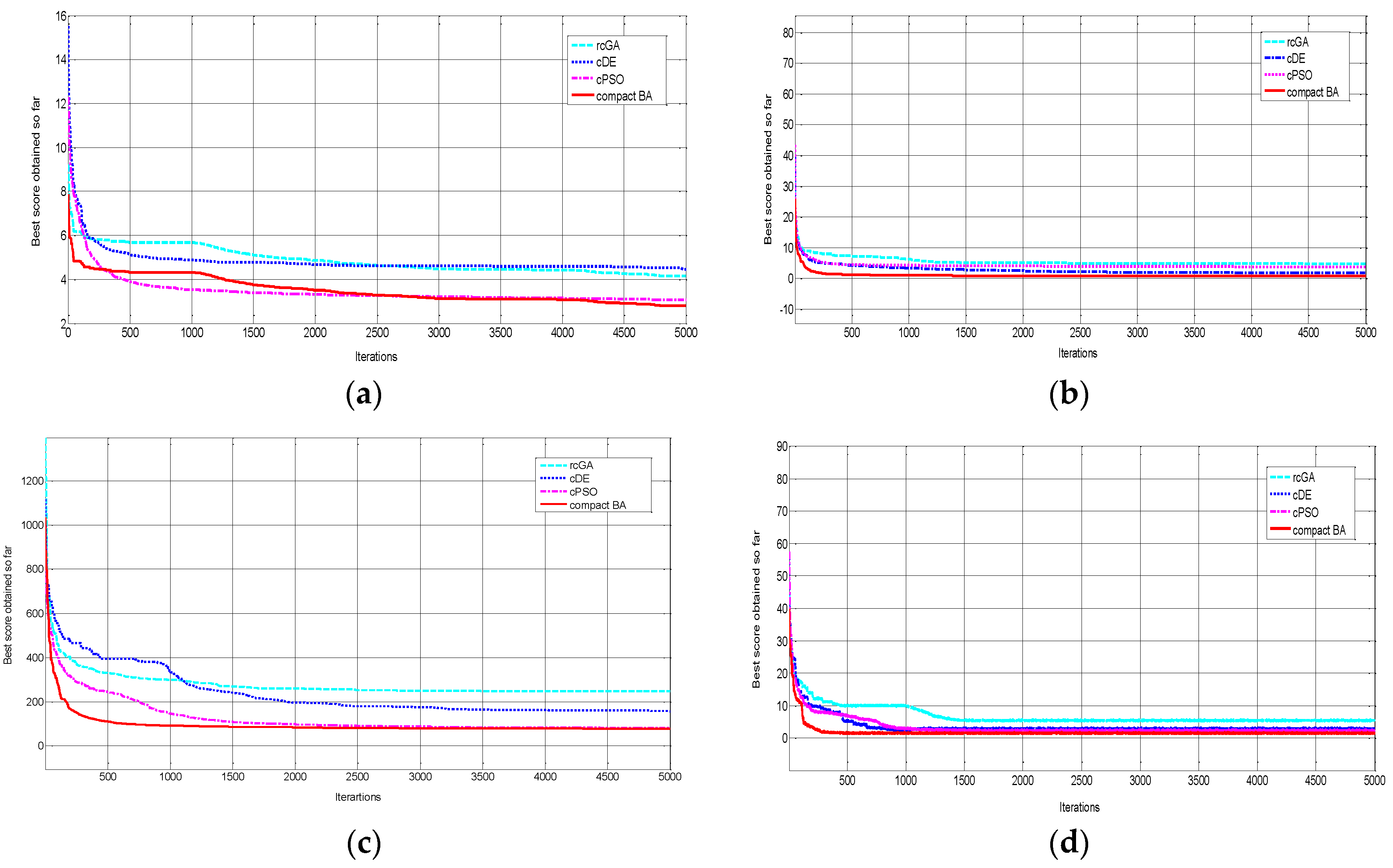
Table 4 depicts the comparison the outcomes of the proposed algorithm with the other compact algorithms such as compact Particle swarm optimization (cPSO) [39], compact Differential evolution (cDE) [40], and real compact Genetic algorithm (rcGA) [41] for 10 test functions. Apparently, cBA outperforms its competitors regarding convergence. The best results among them for each function is highlighted in rows. The performance of the compared ratio r is set for each pair of comparisons of cBA with the cPSO, cDE, and rcGA, respectively. The symbols of “+”, “−” and “~” represent “better”, “worse”, and “approximation” of the deviation of the outcomes, respectively. If the averaged outcomes obtained for 25 runs of the optimized function of cBA is better than the cPSO, cDE, and rcGA, then r is the set symbol “+”. The same method with the symbols “~” and “−” for the worse and approximation are applied to the cases, respectively. It would be seen that most of the highlighted cases of testing functions belong to the proposed cBA. Table 4 shows that the proposed approach outperforms the other methods. According to Figure 4, the curve of the cBA displays comparatively better convergence behavior on the selected test functions.
5. Experiments for Clustering in WSNs Problem
In designing and deploying sensor networks, a core demand is prolonging the lifetime of the network. A crucial factor for extending WSN lifetime is reduction of the energy consumption of the entire network. The power consumption of WSNs is affected directly by the clustering criterion problem. Furthermore, the cause of the hot spot problem in a WSN with multi-hop communications is unbalanced energy consumption. The higher energy consumption nodes are closer to the base station (BS) because of the heavy traffic flows. In this section, cBA is applied to optimize the design of the WSN by balancing the load between the CHs. We utilize adjustable parameter of loudness of BA for supporting and preventing unbalanced energy consumption. The loudness Ai of the BA can vary and alter responds to distances in clustering criterion for unequal clustering in WSN. The optimized total communication distances from the cluster members to the CHs and the CHs to the BS in the WSNs can provide the energy savings [42]. The sequence of experimental steps consists of modeling objective function, setting up a mapping solution model, describing proper agent representation, optimizing CHs, and comparing results.
5.1. Objective Function
The objective function is modelled with not only minimizing the optimized total communication distances from the cluster members to the CHs and the CHs to the BS but also by balancing energy consumption between the CHs and group members. Referring to Equation (3), the CHs is selected based on energy residual.
In Equation (6), we use only the optimizable component that was independent of parameters related to the microcontroller and the supply voltage distances. Consequently, Eframe is the most affected factor of the energy loss depending on the distance of the clustering in WSN. Therefore, the consuming energy of the network is based on the distances in the clusters. Sensor nodes are clustered by using entire distances, namely , where k is the given clusters.
Another factor that affected the fitness function is calculated as follows:
where is the number of nodes in a network, and are the distances of member nodes to the CH and the CHs to the BS, respectively.
Modelling for objective function suggests dense clusters with set of nodes which have sufficient energy to perform the CH tasks. The objective function for equal clustering in WSN is defined as follows:
where is weight of the objective function. The vector of bats x is represented by mapping from the distances of with the indexed . Both types of distances are considered the intra-cluster distance and the distance between the CHs and the BS. The intra-cluster distances are distances of member nodes and its CH.
5.2. Model Solution Representation
A WSN is assumed to be a graph G with n nodes randomly distributed in the desired area. There are N nodes (N is set to 100, 200, …) in a network spread out in a distributed two-dimensional space of where M equals 100, 200. The nodes of the WSN circulate in a two-dimensional area and are deployed as follows: (1) a model solution is constructed with spatial coordinates of nodes that can obtain distances to the BS and attribute links between the nodes, (2) clusters are figured out randomly with k clusters, and (3) the distance of the cluster member to the CH and the CHs to the BS are calculated for optimization of the network layout. Table 5 shows an example of the position of randomly distributed nodes in two-dimensional coordinates of a network zone. Each node can communicate with others by r transmission ranging. Node i can receive the signal of node j if node i is in the transmission range of node j. Table 6 indicates the attribution of the existing CHs in the sensor networks.
In the following experiment, we consider two scenarios of equal clustering and unequal clustering in a WSN to create an optimization network. The equal clustering has cluster radii which are the same size. However, the group size of unequal clustering close to the BS is smaller than those that are farther from the BS. The uneven cluster sizes occur because the traffic relay load of the CHs near the base station is heavier than the CHs farther away from the BS.
5.3. Equal Clustering Formation
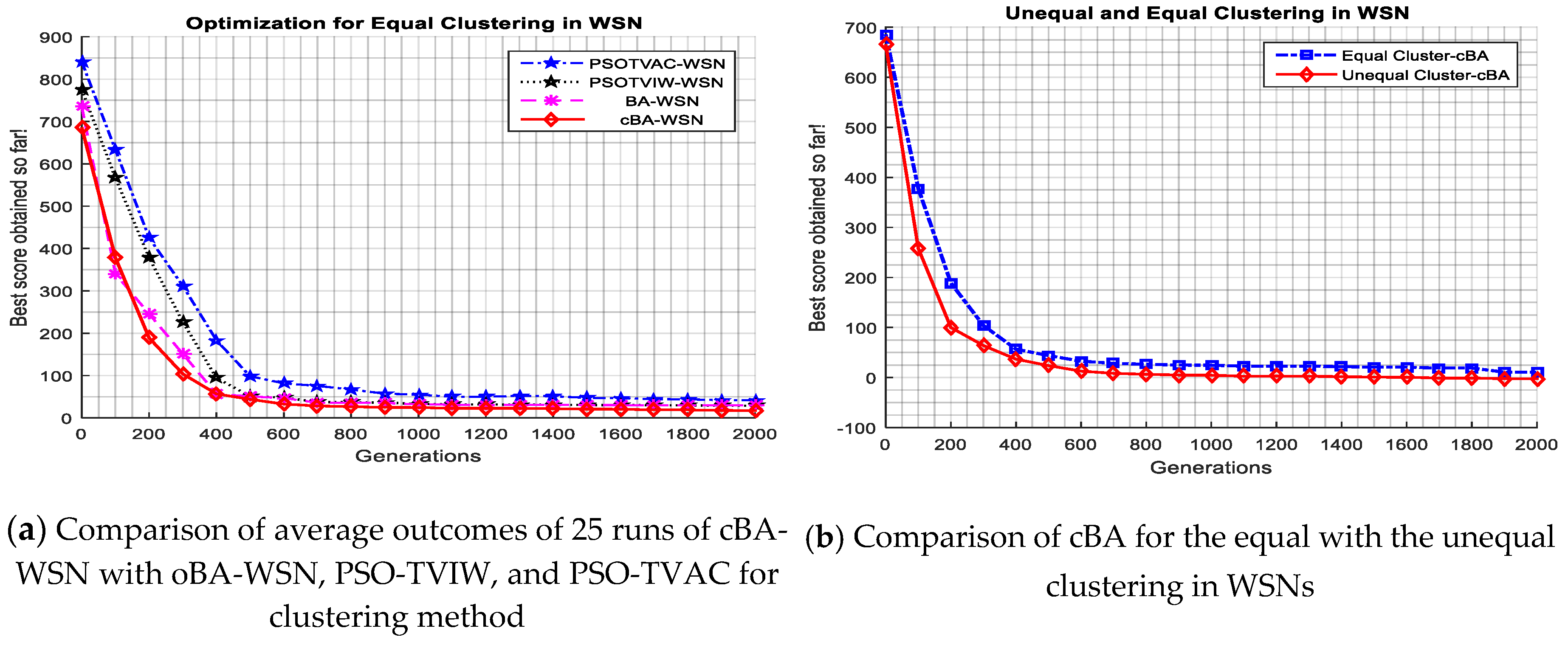
The optimization problem is dealt with by minimizing the objective function in Equation (22). The initial setting for the oBA and the cBA is the same condition in the WSN (denoted as oBA-WSN and cBA-WSN), e.g., a maximum iteration is set to 2000, the number of runs is set to 25. (Readers refer to parameters setting of the loudness, frequencies, and virtual population in Section 4). The initial energy parameters of the sensor net are flowing: l = 1024 bit, Ej = 0:5 J, Emp = 0:0013 pJ/bit/m4, Efs = 10 pJ/bit/m2, EDA = 5 nJ/bit/signal, Eelec = 50 nJ/bit [31]. The experimental results of the proposed cBA are compared with the cases of PSO: the time-varying inertia weight (PSO-TVIW), and time-varying acceleration coefficients (PSO-TVAC) in [43] and the oBA [44] with respect to solution quality and time running. The result averages the outcomes from all runs.
Table 7 compares the performance quality and running time for optimizing the clustering formation in WSNs for four methods of the , , , and the . Clearly, the average value of cBA for the objective function are faster than those obtained by other approaches of PSO. The applied cBA for optimizing the clustering formation is not as different as convergence using oBA. But, the total time consumption of the cBA method is fastest at only 2.445 min taken because the working variable memory is smallest.
Figure 5a indicates four curves of the , , and methods for clustering formation for WSN. It is evident that cBA-WSN is as good as BA-WSN and faster than those of and methods in convergence.
5.4. Unequal Clustering Formation
This unequal clustering scenario is studied to deal with the hot spot problem in WSN. The partitioned clusters in the network of uneven clustering have different sizes. The groups close to the BS are smaller than those clusters far from the BS. The clusters closer to the BS are the hotter clusters because the traffic relay load of the cluster heads near the BS is heavier than those CHs farther away from the BS [45]. To avoid this hot spot problem, we determine that the adjustable parameters are not only related to the objective function but also related to the optimization algorithm. For the objective function of constructing unequal clusters, each CH needs to adjust its equal cluster distances:
where is the distance from node CHj to the BS, and is the ratio adjusting parameter. The calculation for is defined as follows:
where and are the maximum and minimum distance of the CHs in the network to the BS, is the maximum value of competition radius, α is a weighted factor whose value is in (0, 1), and is the residual energy of CHj. Clustering optimized formation is done by performing the optimal objective function in Equation (22) with the assistant of different distances Equations (23) and (24).
Figure 5b compares two performance qualities in two scenarios of equal clustering and hot spot problems. Visibly, the average fitness values of the cBA method with a hot spot issue in the case of adjusting cluster size for the unequal clustering formation is faster than the regular case in convergence.
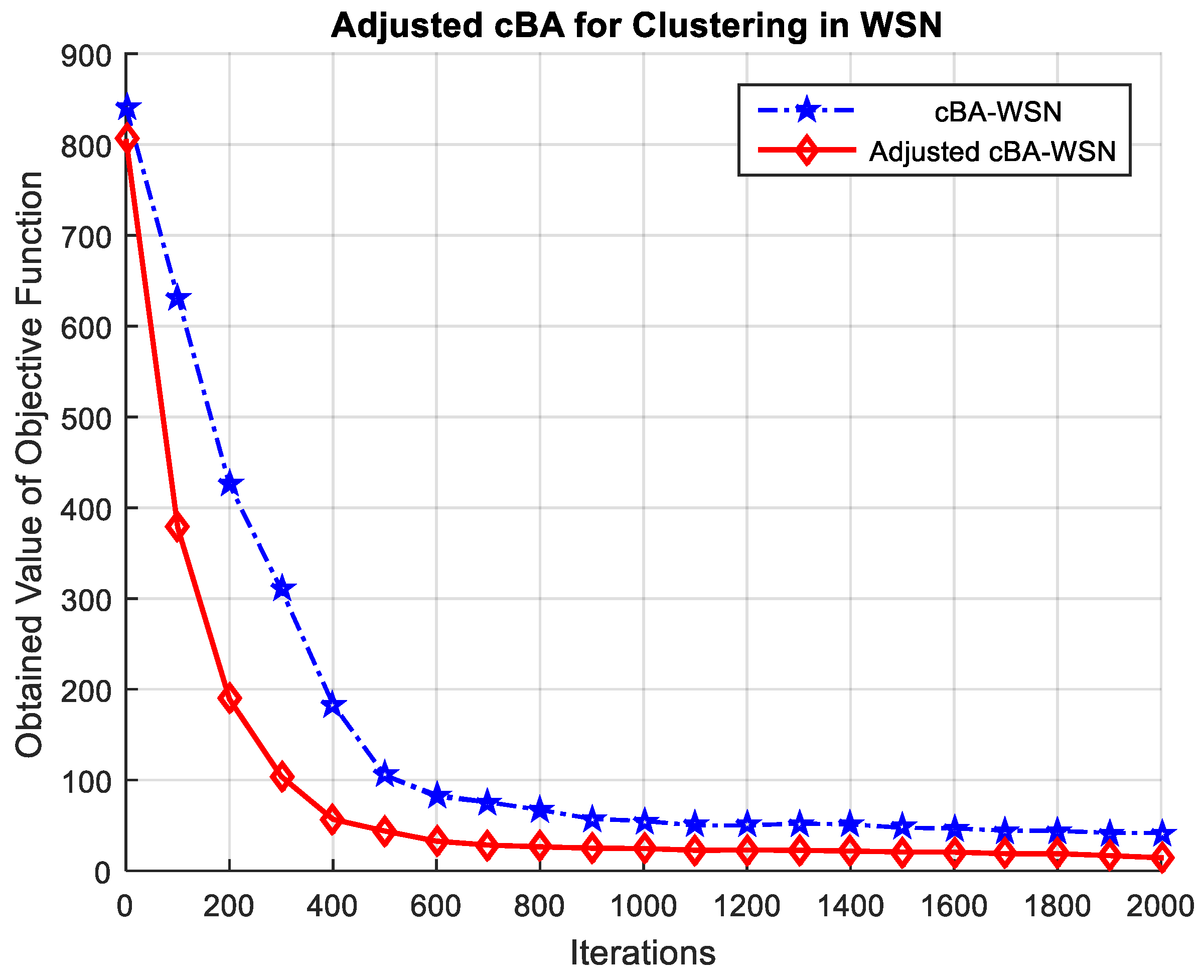
For the optimization algorithm, we assigned the variable of loudness Ai for BA as in Equation (12) to correspond to the radius of the changing cluster size by bias iteration. We expressed mathematically the time-varying loudness of the BA as follows:
where is the number of the maximum iteration; is the current time steps, and are constants set to 0.5 and 0.25, respectively. The time varying loudness is mathematically represented in Equation (25) for cBA with a hot spot problem in WSN.
Figure 6 compares the performance qualities in two cases of the selected parameter of the loudness for cBA with an adjusted cluster size with no selected altered loudness setting. Visibly, the average fitness values for the cBA method in the case of adjusting Ai for the unequal clustering formation is better than the regular case in convergence to remove the hot spot problem.
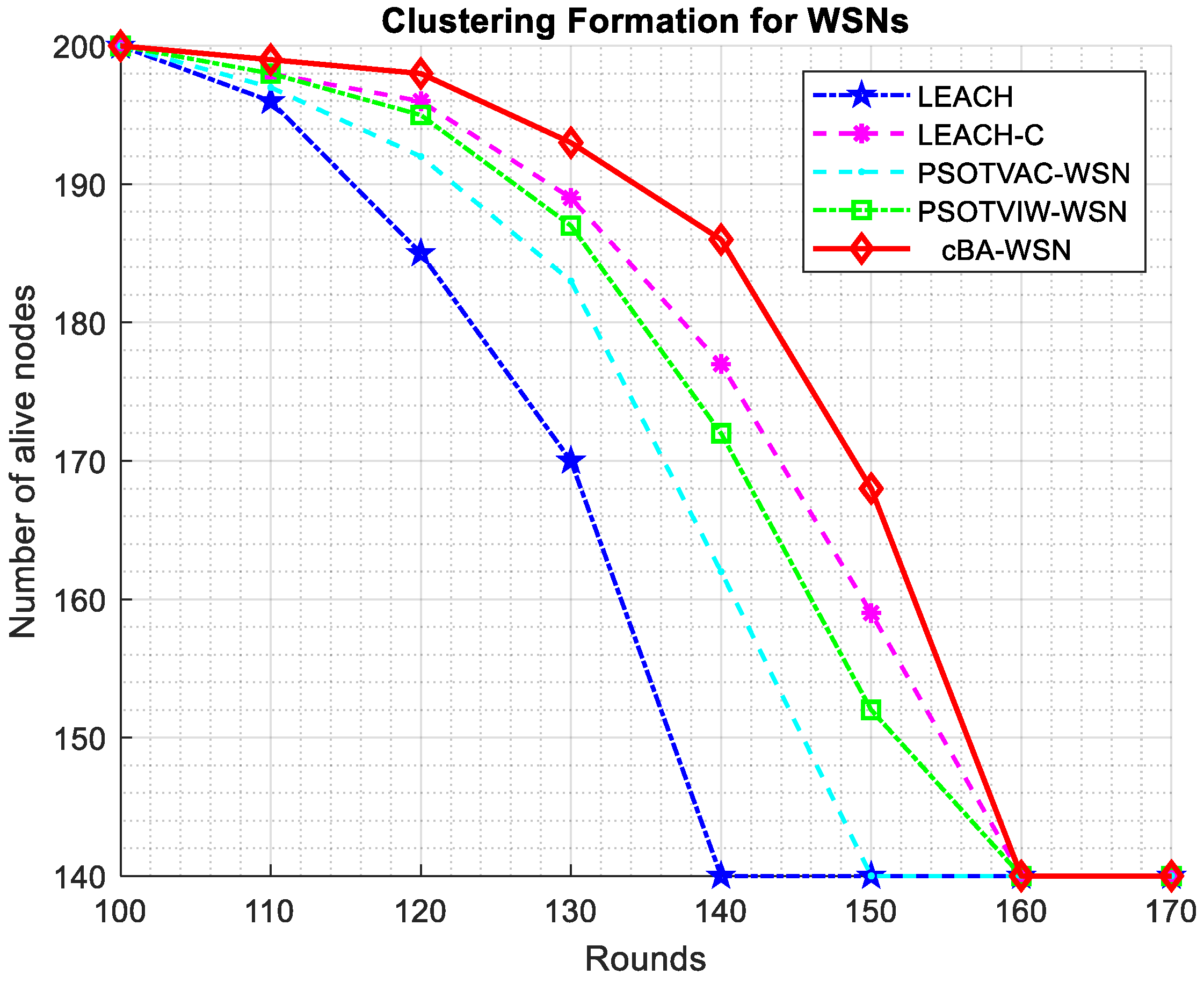
Figure 7 shows a comparison of the advanced cBA-WSN with other methods, e.g., PSO-TVAC, PSO-TVIW, the low-energy adaptive clustering hierarchy (LEACH) [22], and LEACH-centralized (LEACH-C) [23] approaches regarding the number of nodes alive. LEACH is a clustering protocol that selects sensor nodes randomly as CHs based on probability as a “threshold” parameter. LEACH-C is another version based on LEACH with a base station (BS) and uses a specific method to select the CH and divide the nodes to clusters which can offer more optimization, and therefore it means the lifetime of the network is longer than LEACH. On the basis of observations, it is clear that the number of alive nodes of the proposed cBA-WSN is the longest. This means that the results of the proposed cBA-WSN for the testing functions and clustering problem in WSN is better than the other methods in the comparisons.
6. Conclusions
This paper presented a new optimization algorithm using the compact bat algorithm (cBA) for the uneven clustering problem in wireless sensor networks (WSN). A probabilistic model was used to generate a new candidate solution in space search using the cBA which has been promising so far. The candidate solution was found by studying explicit probabilistic models of promising existing solutions and sampling the built models. The probability density functions (PDF) and cumulative distribution functions (CDF) thoroughly are used to construct the operations of selecting and optimizing behaviors. The probabilistic model is used as a valid alternative optimization strategy for available devices with even limited hardware sources. Experimental results demonstrate that the proposed algorithm achieves the effective way of using limited memory devices, and provides competitive results.
Author Contributions
Conceptualization, T.-T.N. and T.-K.D.; methodology, T.-T.N.; software T.-K.D.; validation T.-K.D., T.-T.N. and J.-S.P.; formal analysis T.-T.N.; investigation, J.-S.P.; resources J.-S.P.; data curation T.-K.D.; writing—original draft preparation T.-T.N.; writing—review and editing J.-S.P.; visualization T.-T.N.; supervision J.-S.P. project administration T.-T.N.; funding acquisition J.-S.P.
Funding
This work was supported by the Natural Science Foundation of Fujian Province under Grant No. 2018J01638.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yang, X.S. A New Metaheuristic Bat-Inspired Algorithm. In Studies in Computational Intelligence; González, J., Pelta, D., Cruz, C., Terrazas, G., Krasnogor, N., Eds.; Springer: Heidelberg, Germany, 2010; Volume 284, pp. 65–74. [Google Scholar]
- Dao, T.K.; Pan, J.S.; Nguyen, T.T.; Chu, S.C.; Shieh, C.S. Compact Bat Algorithm. In Advances in Intelligent Systems and Computing; Pan, J.-S., Snasel, V., Corchado, E.S., Abraham, A., Wang, S.-L., Eds.; Springer International Publishing: Heidelberg, Germany, 2014; Volume 298, pp. 57–68. [Google Scholar]
- Yang, X. Bat Algorithm: Literature Review and Applications. Int. J. Bio-Inspired Comput. 2013, 5, 1–10. [Google Scholar] [CrossRef]
- Dao, T.; Pan, T.; Nguyen, T.; Chu, S. Evolved Bat Algorithm for Solving the Economic Load Dispatch Problem. Adv. Intell. Syst. Comput. 2015, 329, 109–119. [Google Scholar]
- Tsai, P.W.; Pan, J.S.; Liao, B.Y.; Tsai, M.J.; Istanda, V. Bat algorithm inspired algorithm for solving numerical optimization problems. Appl. Mech. Mater. 2012, 148, 134–137. [Google Scholar] [CrossRef]
- Nguyen, T.-T.; Pan, J.-S.; Dao, T.-K.; Kuo, M.-Y.; Horng, M.-F. Hybrid Bat Algorithm with Artificial Bee Colony; Springer: Heidelberg, Germany, 2014; Volume 298. [Google Scholar]
- Nakamura, R.Y.M.; Pereira, L.A.M.; Rodrigues, D.; Costa, K.A.P.; Papa, J.P.; Yang, X.-S. Binary bat Algorithm for Feature Selection. In Swarm Intelligence and Bio-Inspired Computation; Elsevier: Amsterdam, The Netherlands, 2013; pp. 225–237. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Yang, X.-S. Binary bat algorithm. Neural Comput. Appl. 2014, 25, 663–681. [Google Scholar] [CrossRef]
- Kang, M.; Kim, J.; Kim, J.-M. Reliable fault diagnosis for incipient low-speed bearings using fault feature analysis based on a binary bat algorithm. Inf. Sci. 2015, 294, 423–438. [Google Scholar] [CrossRef] [Green Version]
- Zhao, D.; He, Y. Chaotic binary bat algorithm for analog test point selection. Analog Integr. Circuits Signal Process. 2015, 84, 201–214. [Google Scholar]
- Rizk-Allah, R.M.; Hassanien, A.E. New binary bat algorithm for solving 0–1 knapsack problem. Complex Intell. Syst. 2018, 4, 31–53. [Google Scholar] [CrossRef]
- Dao, T.-K.; Pan, T.-S.; Nguyen, T.-T.; Pan, J.-S. Parallel bat algorithm for optimizing makespan in job shop scheduling problems. J. Intell. Manuf. 2018, 29, 451–462. [Google Scholar] [CrossRef]
- Luo, Q.; Zhou, Y.; Xie, J.; Ma, M.; Li, L. Discrete bat algorithm for optimal problem of permutation flow shop scheduling. Sci. World J. 2014, 2014, 15. [Google Scholar] [CrossRef] [PubMed]
- Osaba, E.; Yang, X.-S.; Diaz, F.; Lopez-Garcia, P.; Carballedo, R. An improved discrete bat algorithm for symmetric and asymmetric traveling salesman problems. Eng. Appl. Artif. Intell. 2016, 48, 59–71. [Google Scholar] [CrossRef]
- Estrin, D.; Heidemann, J.; Kumar, S.; Rey, M. Next Century Challenges: Scalable Coordination in Sensor Networks. In Proceedings of the 5th annual ACM/IEEE International Conference on Mobile Computing and Networking, Seattle, WA, USA, 18–19 August 1999; Volume 4, pp. 263–270. [Google Scholar]
- Nguyen, T.-T.; Dao, T.-K.; Horng, M.-F.; Shieh, C.-S. An Energy-based Cluster Head Selection Algorithm to Support Long-lifetime in Wireless Sensor Networks. J. Netw. Intell. 2016, 1, 23–37. [Google Scholar]
- Liu, W.; Vijayanagar, K.R.; Kim, J. Low-complexity distributed multiple description coding for wireless video sensor networks. IET Wirel. Sens. Syst. 2013, 3, 205–215. [Google Scholar] [CrossRef]
- Almalkawi, I.T.; Zapata, M.G.; Al-Karaki, J.N.; Morillo-Pozo, J. Wireless multimedia sensor networks: Current trends and future directions. Sensors 2010, 10, 6662–6717. [Google Scholar] [CrossRef] [PubMed]
- Djedjiga, A.A.; Abdeldjalil, O. Monitoring crack growth using thermography. C. R. Mec. 2008, 336, 677–683. [Google Scholar]
- Broday, D.M. Wireless distributed environmental sensor networks for air pollution measurement—The promise and the current reality. Sensors 2017, 17, 2263. [Google Scholar] [CrossRef] [PubMed]
- Meriem, D.; Abdeldjalil, O.; Hadj, B.; Adrian, B.; Denis, K. Discrete Wavelet for Multifractal Texture Classification: Application to Medical Ultrasound Imaging. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 637–640. [Google Scholar]
- Medina-García, J.; Sánchez-Rodríguez, T.; Galán, J.; Delgado, A.; Gómez-Bravo, F.; Jiménez, R. A wireless sensor system for real-time monitoring and fault detection of motor arrays. Sensors 2017, 17, 469. [Google Scholar] [CrossRef]
- Fernandez-Lozano, J.J.; Martín-Guzmán, M.; Martín-Ávila, J.; García-Cerezo, A. A wireless sensor network for urban traffic characterization and trend monitoring. Sensors 2015, 15, 26143–26169. [Google Scholar] [CrossRef]
- Garcia-Sanchez, A.-J.; Garcia-Sanchez, F.; Garcia-Haro, J. Wireless sensor network deployment for integrating video-surveillance and data-monitoring in precision agriculture over distributed crops. Comput. Electron. Agric. 2011, 75, 288–303. [Google Scholar] [CrossRef]
- Akyildiz, I.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef]
- García-hernández, C.F.; Ibargüengoytia-gonzález, P.H.; García-hernández, J.; Pérez-díaz, J.a. Wireless Sensor Networks and Applications: A Survey. J. Comput. Sci. 2007, 7, 264–273. [Google Scholar]
- Pan, J.-S.; Kong, L.; Sung, T.-W.; Tsai, P.-W.; Snášel, V. A Clustering Scheme for Wireless Sensor Networks Based on Genetic Algorithm and Dominating Set. J. Int. Technol. 2018, 19, 1111–1118. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evolut. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Abbasi, A.A.; Younis, M. A survey on clustering algorithms for wireless sensor networks. Comput. Commun. 2007, 30, 2826–2841. [Google Scholar] [CrossRef]
- Xia, H.; Zhang, R.H.; Yu, J.; Pan, Z.K. Energy-Efficient Routing Algorithm Based on Unequal Clustering and Connected Graph in Wireless Sensor Networks. Int. J. Wirel. Inf. Netw. 2016, 23, 141–150. [Google Scholar] [CrossRef]
- Heinzelman, W.B.; Chandrakasan, A.P.; Balakrishnan, H. An application-specific protocol architecture for wireless microsensor networks. IEEE Trans. Wirel. Commun. 2002, 1, 660–670. [Google Scholar] [CrossRef] [Green Version]
- Heinzelman, W.B. Application-Specific Protocol Architectures for Wireless Networks; Massachusetts Institute of Technology: Cambridge, MA, USA, 2000. [Google Scholar]
- Nguyen, T.-T.; Shieh, C.-S.; Dao, T.-K.; Wu, J.-S.; Hu, W.-C. Prolonging of the Network Lifetime of WSN Using Fuzzy Clustering Topology. In Proceedings of the 2013 2nd International Conference on Robot, Vision and Signal Processing, RVSP, Kitakyushu, Japan, 10–12 December 2013. [Google Scholar]
- Billingsley, P. Probability and Measure, 3th ed.; Wiley: Hoboken, NJ, USA, 1995. [Google Scholar]
- Larranaga, P.; Lozano, J.A. Estimation of Distribution Algorithms—A New Tool for Evolutionary Computation; Springer Science & Business Media: Heidelberg, Germany, 2002; Volume 2. [Google Scholar]
- Bronshtein, I.N.; Semendyayev, K.A.; Musiol, G.; Mühlig, H. Handbook of Mathematics, 6th ed.; Van Nostrand Reinhold: New York, NY, USA, 2015. [Google Scholar]
- Ghosh, S.K. Handbook of Mathematics; No. 3; Van Nostrand Reinhold: New York, NY, USA, 1989; Volume 18. [Google Scholar]
- Yao, X.; Liu, Y.; Lin, G. Evolutionary programming made faster. IEEE Trans. Evol. Comput. 1999, 3, 82–102. [Google Scholar] [Green Version]
- Neri, F.; Mininno, E.; Iacca, G. Compact particle swarm optimization. Inf. Sci. 2013, 239, 96–121. [Google Scholar] [CrossRef]
- Mininno, E.; Neri, F.; Cupertino, F.; Naso, D. Compact differential evolution. IEEE Trans. Evol. Comput. 2011, 15, 32–54. [Google Scholar] [CrossRef]
- Harik, G.R.; Lobo, F.G.; Goldberg, D.E. The compact genetic algorithm. IEEE Trans. Evol. Comput. 1999, 3, 287–297. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–105. [Google Scholar] [CrossRef]
- Ratnaweera, A.; Halgamuge, S.K.; Watson, H.C. Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients. IEEE Trans. Evol. Comput. 2004, 8, 240–255. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.-T.; Shieh, C.-S.; Horng, M.-F.; Ngo, T.-G.; Dao, T.-K. Unequal Clustering Formation Based on Bat Algorithm forWireless Sensor Networks. In Knowledge and Systems Engineering: Proceedings of the Sixth International Conference KSE 2014; Nguyen, V.-H., Le, A.-C., Huynh, V.-N., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 667–678. [Google Scholar]
- Pan, J.-S.; Kong, L.; Sung, T.-W.; Tsai, P.-W.; Snášel, V. α-Fraction First Strategy for Hierarchical Model in Wireless Sensor Networks. J. Internet Technol. 2018, 19, 1717–1726. [Google Scholar]
Figure 1.
Convergence comparison of two algorithms of cBA and oBA for four first test functions. (a): Rosenbrock function; (b): Quadric function; (c): Ackley function; (d): Rastrigin function.
Figure 1.
Convergence comparison of two algorithms of cBA and oBA for four first test functions. (a): Rosenbrock function; (b): Quadric function; (c): Ackley function; (d): Rastrigin function.

Figure 2.
Comparison of two curves with affected variety of the population size in BA and compact BA for four first test functions. (a): Rosenbrock function; (b): Quadric function; (c): Ackley function; (d): Rastrigin function.
Figure 2.
Comparison of two curves with affected variety of the population size in BA and compact BA for four first test functions. (a): Rosenbrock function; (b): Quadric function; (c): Ackley function; (d): Rastrigin function.

Figure 3.
Comparison of running times of cBA with cBA for ten test functions.

Figure 4.
Comparison of four compact algorithms of rcGA, cDE, cPSO, and cBA for the selected testing functions: (a) is f1, (b) is f2, (c) is f5 and (d) is f7.
Figure 4.
Comparison of four compact algorithms of rcGA, cDE, cPSO, and cBA for the selected testing functions: (a) is f1, (b) is f2, (c) is f5 and (d) is f7.

Figure 5.
Two scenarios of clustering and unequal clustering methods in WSNs.

Figure 6.
Comparison of converging curves of the cBA-WSN (with adjusted cluster size for BAs with altered loudness) and the cBA-WSN (with no adjusted).
Figure 6.
Comparison of converging curves of the cBA-WSN (with adjusted cluster size for BAs with altered loudness) and the cBA-WSN (with no adjusted).

Figure 7.
Comparison of advanced cBA-WSN for the number of nodes alive for a WSNs with PSO-TVAC, PSO-TVIW, LEACH, and LEACH-C approaches.
Figure 7.
Comparison of advanced cBA-WSN for the number of nodes alive for a WSNs with PSO-TVAC, PSO-TVIW, LEACH, and LEACH-C approaches.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Ten selected benchmark functions of testing.
| Name | Test Functions | Range | Dimension | Iteration |
|---|---|---|---|---|
| Rosenbrock | ±100 | 30 | 5000 | |
| Quadric | ±100 | 30 | 5000 | |
| Ackley | ±32 | 30 | 5000 | |
| Rastrigin | ±5.12 | 30 | 5000 | |
| Griewangk | ±100 | 30 | 5000 | |
| Spherical | ±100 | 30 | 5000 | |
| Quartic Noisy | ±1.28 | 30 | 5000 | |
| Schwefel | ±100 | 30 | 5000 | |
| Langermann | ±5.12 | 30 | 5000 | |
| Shubert | ±32 | 30 | 5000 |
Table 2.
Comparison evaluation and speed of the cBA and oBA regarding the quality performance.
| Test Functions | Evaluation Results | Accuracy % | Time Consumption (minutes) | Speed % | ||
|---|---|---|---|---|---|---|
| RD | Comparison | |||||
| 8.87 | 3% | 1.5659 | 1.3141 | 19% | ||
| 3.79 | 3.63 | 4% | 2.1764 | 1.7936 | 21% | |
| 1.92 | 1.91 | 1% | 1.498 | 1.1598 | 29% | |
| 2.09 | 2.05 | 2% | 1.1847 | 1.0021 | 18% | |
| 6.23 | 6.12 | 2% | 1.3823 | 1.0845 | 27% | |
| 7.64 | 7.40 | 3% | 1.1616 | 0.8768 | 32% | |
| 1.12 | 1.10 | 2% | 1.2823 | 1.0845 | 18% | |
| 6.25 | 6.00 | 4% | 1.1147 | 0.8921 | 25% | |
| 8.75 | 8.77 | 1% | 1.5659 | 1.3141 | 19% | |
| 1.50 | 1.70 | 2% | 2.4764 | 2.3936 | 17% | |
| Average | 1.15 | 1.11 | 3% | 1.4207 | 1.1509 | 24% |
Table 3.
Comparison of the number of variables for occupied memory slots in the cBA and oBA.
| Algorithms | Number of Solutions | Occupied Slots | Used Equations |
|---|---|---|---|
| oBA | N | 4 × N | (8), (9), (10), (11) |
| cBA | 1 | 8 | (8), (9), (10), (11), (15), (16), (17), (18) |
Table 4.
Comparison of the outcomes of the proposed method with the other compact algorithms such as rcGA [39], cDE [40], and cPSO [39] for 10 test functions.
| Functions | cBA | cPSO | r | cDE | r | rcGA | r |
|---|---|---|---|---|---|---|---|
| 8.97 | 9.20 | + | 9.20 | + | 9.00 | ~ | |
| 3.73 | 3.69 | − | 3.73 | ~ | 3.79 | + | |
| 1.92 | 1.91 | − | 1.92 | + | 1.95 | + | |
| 2.05 | 2.06 | ~ | 2.06 | ~ | 2.09 | + | |
| 6.11 | 6.12 | + | 6.23 | + | 6.23 | + | |
| 7.64 | 7.57 | − | 7.54 | − | 7.64 | − | |
| 1.12 | 1.19 | + | 1.13 | + | 1.10 | + | |
| 6.25 | 6.50 | + | 6.29 | + | 6.27 | + | |
| 8.75 | 1.21 | + | 7.64 | − | 8.75 | ~ | |
| 1.50 | 6.57 | − | 1.81 | + | 3.18 | + | |
| AVG | 9.07 | 9.21 | + | 9.20 | + | 9.10 | + |
| Summary | r is ‘+’, means cBA is winner | 6+ 1~ 4− | 7+ 2~ 2− | 8+ 2~ 1− | |||
Table 5.
A sample of representative positions of the sensor nodes.
| Index | Nodei | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | .. | n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | 05 | 55 | 85 | 101 | 72 | 60 | 45 | 40 | 50 | 75 | 45 | 20 | .. | 10 |
| y | 01 | 5 | 10 | 30 | 15 | 20 | 45 | 60 | 85 | 90 | 95 | 80 | .. | 80 |
Table 6.
The attribution of existing cluster heads (CHs) if flag = 1 and node is set to cluster head (CH). Otherwise node is set to member node (SN).
Table 6.
The attribution of existing cluster heads (CHs) if flag = 1 and node is set to cluster head (CH). Otherwise node is set to member node (SN).
| Index | Nodei | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | .. | n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cluster head | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | .. | 0 | |
Table 7.
The comparison of averaged outcomes and computation time of cBA-WSN with other methods, e.g., oBA-WSN [44], PSO-TVAC [43] and PSO-TVIW [43] for equal clustering formation.
| Methods | Pop. Size | Iterations/a Run | Min | Max | Mean | Standard Deviation | Running Time (m) |
|---|---|---|---|---|---|---|---|
| [43] | 20 | 2000 | 5.72 | 8.41 | 2.57 | 2.87 | 3.01 |
| [43] | 20 | 2000 | 6.80 | 6.35 | 2.25 | 2.83 | 3.10 |
| oBA-WSN [44] | 20 | 2000 | 6.93 | 7.57 | 2.03 | 2.69 | 3.26 |
| The proposed cBA-WSN | 1 | 2000 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Nguyen, T.-T.; Pan, J.-S.; Dao, T.-K. A Compact Bat Algorithm for Unequal Clustering in Wireless Sensor Networks. Appl. Sci. 2019, 9, 1973. https://doi.org/10.3390/app9101973
AMA Style
Nguyen T-T, Pan J-S, Dao T-K. A Compact Bat Algorithm for Unequal Clustering in Wireless Sensor Networks. Applied Sciences. 2019; 9(10):1973. https://doi.org/10.3390/app9101973
Chicago/Turabian StyleNguyen, Trong-The, Jeng-Shyang Pan, and Thi-Kien Dao. 2019. "A Compact Bat Algorithm for Unequal Clustering in Wireless Sensor Networks" Applied Sciences 9, no. 10: 1973. https://doi.org/10.3390/app9101973
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.