1. Introduction
The U.S. election, 2020 was a significant global event, as the Republican Party’s Donald Trump was striving to secure his second term while Joe Biden of the Democratic Party expected to turn it around. The pre-election polls assessed the U.S. public’s sentiments to evaluate the likelihoods for each candidate. The BBC poll suggested that Joe Biden was ahead of Donald Trump and marked the elections’ battleground [
1]. However, among these states, the margin of victory was very close, and it could have swung in favor of either candidate. Other two-way and four-way online polls such as 270 to win and
Real clear politics showed the narrow dominance of Joe Biden. The nationwide polls such as
Ipsos/Reuters [
2],
CNBC,
Yahoo News [
3],
NBC/WSJ [
4],
Fox News [
5],
CNN/WSJ [
6],
ABC/Washington Post [
7], and others reported public sentiment in favor of Joe Biden. However, since U.S. elections are decided by the Electoral College rather than on casted votes, predicting elections on public sentiment is not straightforward. It might reflect the public opinion in one sense; however, it could sway in favor of any candidate with such a narrow margin. The 2020 U.S. election took place on 3 November 2020; the final results of the election declared Joe Biden victorious with 51.3%, while Donald Trump bagged 46.9% votes. The 2020 U.S. election was the first election after 1992 in which the incumbent president was unable to retain his seat. The election of 2020 also witnessed one of the highest voter turnouts since 1900, in which both candidates received more than 74 million votes [
8].
The elections were held during the COVID-19 pandemic in the U.S.; therefore, strict SOPs and stay-at-home instructions were enforced. The pandemic affected and altered the elections campaigns and schedules and resulted in long queues at election booths due to reduced numbers of workers willing to work during a pandemic. This paved the way for mail-in voting and casting of the vote through postage. Donald Trump criticized the mail-in poll by stating that it raised the chances of fraud and rigging. Since many votes were cast by postage, the compilation of the results witnessed a delay. The delay in the result announcement allowed Donald Trump to issue several statements about rigging and stealing the mandate of the people of the U.S. However, the delay in result also happened during the U.S. election in 2000, which took 36 days, and Al Gore lost with a narrow margin. After the elections, Trump refused to have a peaceful transition of power, stating that the only way he could have potentially lost the elections was through fraud. The case of the election of 2000 was contested in the U.S. Supreme Court, where the court initially ruled for a recounting of votes in the disputed Florida state. Later, the decision was withheld to avoid inconsistent standards of counting in different U.S states. Immediately after the 2020 election, Donald Trump threatened lawsuits and dubbed the election as fraudulent. However, his legal battle suffered initial blows when Attorney General William Barr turned it down by saying, “To date, we have not seen fraud on a scale that could have effected a different outcome in the election”. The federal court of Pennsylvania also ruled against him, to quote the Judge, “Charges of unfairness are serious. But calling an election unfair does not make it so. Charges require specific allegations and then proof. We have neither here”. Nevertheless, the margin of victory in the 2020 elections was much more prominent compared to 2000.
Social media platforms such as Twitter, Instagram, and Facebook are common ways of expressing sentiments. People share news, discuss political events and comment about certain global happenings. Therefore, social media is used in political campaigns, promoting social and development works, and expressing sentiments about elections. One of the earliest cases of social media usage for a political campaign was during the U.S. election 2008. Barack Obama utilized Twitter for his political campaign to significant effect. One of the recent examples is the U.S. elections of 2016, where the victory of Donald Trump over Hillary Clinton shocked everyone. The pre-election polls suggested Hillary’s dominance over his counterpart with 91.5% in her favor (Real Clear Politics, 2017; Business Insider, 2016). After Trump’s victory, several investigations reveal the role social media played in the elections. Even Trump dubbed it a critical tool that played a pivotal role in his victory (CBS, 2016). Several works on the sentiment analysis of U.S. elections have already been carried out: of the 2012 U.S. election, employing the Naive Bayes Classifier using Unigram features [
9], the 2016 U.S. election, employing the lexicon approach [
10], the 2016 U.S. elections using Sentistrenght [
11] and other elections, such as Indian elections [
12,
13], Iranian elections [
14], Singaporean elections [
15], and Colombian elections [
16]. These works provide insights into social media sentiments as well as their correspondence with the actual election results; further details are provided in
Section 2. Similarly, social media analysis of the 2020 U.S. election can also potentially unveil several hidden sentiments about both candidates. The study can become yet more critical since the shadows of rigging are cast on the elections. The sentiment analysis becomes more interesting since votes were cast via postal services.
The sentiment analysis of elections also has limitations; for example, it is hard to recognize sarcasm trivially. In some cases, the negative sentiments are classified as positive due to their writing styles. Generally speaking, Twitter is a much better place for sentiment analysis as compared to Facebook [
17]. In this sense, some people on social media might not be serious in really expressing their actual feelings. Therefore, their sentiments do not reflect the true picture. Moreover, social media might not represent complete sentiment in elections, since all voters are not present. While social media might not represent everyone completely, it provides a sample space of people’s opinions. Also, some people might not want to reveal their views due to privacy issues, so even if they are on social media, they might not express their true opinion [
18]. Nevertheless, despite all these limitations, social media sentiment analysis provides the nearest approximation of public sentiment. To detect sarcasm, we used bigram along with term frequency and inverse document frequency (TF-IDF). Bigram is effective for sarcasm detection since it takes into account words surrounding a specific term considering the context along with the single word itself; further details are provided in
Section 3.2.
This research investigates pre- and post-election sentiments for both candidates in each state. Outliers are well known in fundamental data mining tasks to find extreme values laying outside the trends followed by other data samples [
19,
20]. Since the U.S. has flip and closely contested states, finding the outliers is significant for data analysis. Moreover, we analyzed public sentiment and compared it with the election results state-wise. To the best of our knowledge, we have not seen any comprehensive analysis of the 2020 U.S. election that covered pre- and post-election scenarios and compared them with previous U.S. elections. To summarize, the contributions of the work are:
- 1.
We formulated a dataset for the 2020 U.S. election before, during, and after elections using Tweepy API. We created a unique dataset comprising pre and post-election tweets;
- 2.
In this work, we employed sentiment analysis over the Twitter dataset and compared it with the the 2020 U.S. election results;
- 3.
The state with strong and weak sentiments for Donald Trump and Joe Biden were analyzed. We identified outliners and analyzed swing states;
- 4.
We analyzed pre- and post-election sentiments and investigated sentiment drift before, during, and after elections;
- 5.
We assessed the shift of opinions in states with narrow margins and flip states;
- 6.
We compared the the 2020 U.S. election sentiments with the U.S. election 2016 and identified the mutations in various states;
- 7.
We highlighted the critical agenda and issues based on which voters cast their votes.
The remainder of this paper is organized as follows.
Section 2 discusses state of art and existing work in this field.
Section 3 discusses proposed techniques and algorithms used for sentiment analysis.
Section 4 presents the results of simulations performed over the Twitter dataset. Finally,
Section 6 illustrates the conclusion of the work.
2. Related Work
Sentiment analysis is defined as a process that automates the mining of attitudes, opinions, views, and emotions from text, speech, tweets, and database sources through Natural Language Processing (NLP) [
21]. Sentiment analysis involves classifying opinions in text into three main categories, i.e., “positive” or “negative” or “neutral” [
22]. Sentiment information can be extracted using various ways, including speaker recognition [
23], physical activity recognition [
24], philological signals [
25], human facial features [
26], and textual information expressed over social media. Sentiment analysis is employed in numerous fields for opinion mining, such as focusing on multi-level single and multi-word aspects to manifest several domains in Twitter datasets [
27], in recommendation systems [
28], being employed for business intelligence [
29], for finding public opinion about a particular rule before presentation (“eRuleMaking”) [
30], in comments analysis [
31], News Sentiment Analysis [
32], movie reviews analysis [
33], for analysing the sensitivity of particular content before publishing or advertising [
34], or to determine public opinion before elections in different countries. Elections are a significant component for any democratic country which involves the expression of opinion using a vote. People also express their opinions on social media regarding elections. For example, this was seen in the U.S. regarding the presidential election in 2020 [
35,
36], in India [
12,
13,
37], in Australia [
38], in the 2013 Pakistani elections and 2014 Indian elections [
39], in Nigeria [
40], in the Punjab Legislative Assembly [
41], in Indonesia [
42], in the 2013 Pakistan elections 2013 [
43], in Indonesia [
44], in Iran [
14], in the Colombian election in 2014 [
16] and in the Singaporean election in 2011 [
15]. Researchers use several techniques and approaches for text classification task in sentiment analysis [
45]. In particular, three main types of conventional approaches for the text classification are used in sentiment analysis, named: lexicon-based approaches, machine learning approaches and the fusion of the prior-mentioned two approaches, named hybrid approaches [
27].
The 2020 U.S. election is controversial since allegations of rigging and result manipulations surround it. The sentiment analysis reveals several hidden aspects of public opinion for different parties and candidates and would unleash similar sentiments for a given state. In the literature, various aspects of elections are analyzed using sentiment analysis. U.S. elections are one of the most observed international events, as they affect and influence different countries’ policy-making approaches and economies. Sentiment analyses are published in several works for previous elections. In [
9], the author proposed a system providing analysis of public sentiment toward presidential candidates in the 2012 U.S. election by using the Naive Bayes classifier for sentiment analysis on unigram features. They calculated features from tweets tokenization to preserve the punctuation and extract intact URLs for the significance of sentiment. Their system obtained 59% accuracy in classification for four categories of sentiment. Their system was not strictly motivated for global accuracy as they obtained results for four categories on a specific range. In another research work [
11], the author proposed a model for the analysis of political homophily among Twitter users during the 2016 American presidential election. They defined six user classes regarding their sentiment towards Donald Trump and Hillary Clinton. The research reported that if there are reciprocal connections, multiplexed connections, or similar speeches, then the homophily level increases. They used the SentiStrength tool that works on a lexicon-based approach using the dictionary method to perform sentiment analysis. Further, they applied the LDA algorithm to find the hot topic of each user and then aggregated those words to catch the most repeated words. In the mentioned paper [
46], during the U.S. presidential elections that took place in November 2016, the author explored the elements of the political discussion that took place on Twitter. They focused on specific user attributes such as frequently mentioned and highlighted terms, the number of followers and friends, etc. For this purpose, a model based on user behavior was developed to identify the basic characteristics of the political negotiation of Twitter and to test several hypotheses. Further, they used the SentiStrength tool to score the sentiments, and they fed their data into the SQL database for exploratory analysis by focusing on retweets and # tags for feature extraction. The obtained results disclosed that the sentiment of the tweets was negative for the top election candidates. In another work [
10], the author considered the 2016 U.S. presidential election by analyzing tweets using the lexicon-based approach to regulate the fundamental objects of public sentiments. They discovered the subjectivity measures and positive/negative polarity for understanding the user opinion in the mentioned paper. They used APIs for text preprocessing and proposed an algorithm to calculate the subjectivity measures and polarity scores. In addition, the type of sentiment comparison was made, and the most regularly used words in the tweets were the main effect in plotting a word cloud.
In another research work [
47], the author proposed an approach to check shared correlation by comparing the calculated sentiment of tweets with the polling data. For this purpose, they used a lexicon and the Naive Bayes algorithm to quantify and classify all the political tweets collected before the election by considering automatically and manually labeled tweets for this calculation. They came up with a high correlation of 94% with the moving average smoothing technique by concentrating on the tweets 43 days before the election. In another research paper [
48], the author considered the tweets of the 2016 U.S. presidential election. They developed a sentiment algorithm that involved some significant functions to scan the tweets for multiple hashtags, noticed the main discussion topics, assigned a particular value to each word, and identified negation words. Furthermore, they also focused on finding the geographical location effects on each candidate’s popularity and the state population ratio and analyzed the most prevalent issues in tweets. They compared their results with the Electoral Collage and found that the sentiments of tweets coincide with the actual outcome by 66.7%. In another research work [
49], the author investigated a problem related to spatio-temporal sentiment analysis through a major project in the field of data science. They adopted a semi-supervised approach to observe the exact political disposition and LDA algorithm to find politics-related keywords. They used an unsupervised method, word2vec, to set the selected words into a tight semantic margin. They used a compass classification model that uses a linear classifier such as an SVM, which works as two classifiers for classifying tweets, first classifying a particular tweet into non-political or political and the second to observe the political aligning. The main objective of their work was to keep track of arbitrary temporal intervals based on geo-tagged tweets collected for the U.S. presidential election. By combining data management and machine learning techniques, they achieved satisfactory results, and their approach was also capable of influencing other social issues such as health indicators.
In another work [
50], the author proposed the study of the U.S. presidential election held on 3 November 2020 by releasing a dataset consisting of 1.2 billion tweets by tracking all the events and political trends from 2019 and onwards. Their main focus was on the Democratic primaries, Republican and presidential contenders’ real-time tracking. They used a dataset that focused on presidential elections, vice-presidential candidates, presidential candidates, and the wave of transition to the Biden ministry from the Trump ministry. In the mentioned paper [
51], the author worked on the dataset provided by Kaggle, which was updated on 18 November 2020, to find sentimental tweets for both top presidential candidates by considering two case studies. Their objectives included the evaluation of location-based tweets and the on-ground opinion of the public regarding the election results. They compared two models: Firstly, VADER (Valence Aware Dictionary for Sentiment Reasoning) depicts emotional severity by portraying the linguistic aspects. Secondly, exploratory data analysis assists in grasping the content of data. In particular, they acquired all the spatial features from the user location using OpenCage API. They then conducted sentiment analysis using VADER that worked for the polarity and severity of emotion used in the text. Finally, they found that positive/negative sentiments were outweighed by neutral sentiments. The author addressed the possible challenges of sentiment analysis for dynamic events in elections in [
52], such as a fast-paced change in the datasets, candidate dependence, identifying user’s political preferences, content-related challenges, e.g., hashtags, sarcasm, and links. They also considered interpretation-related challenges such as sentiment versus emotion analysis, vote versus engagement counting, trustworthiness-related challenges, and the importance of location.
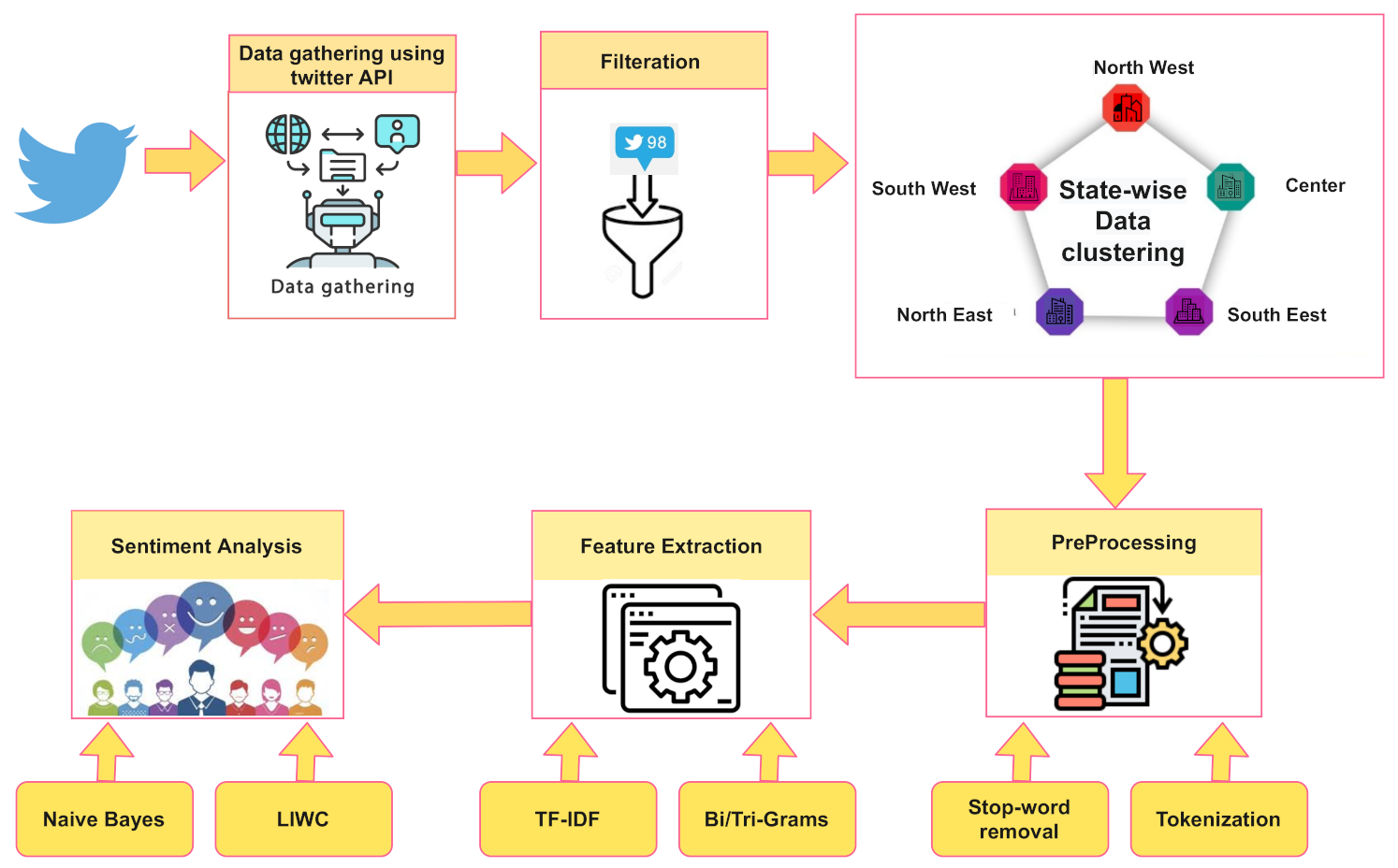
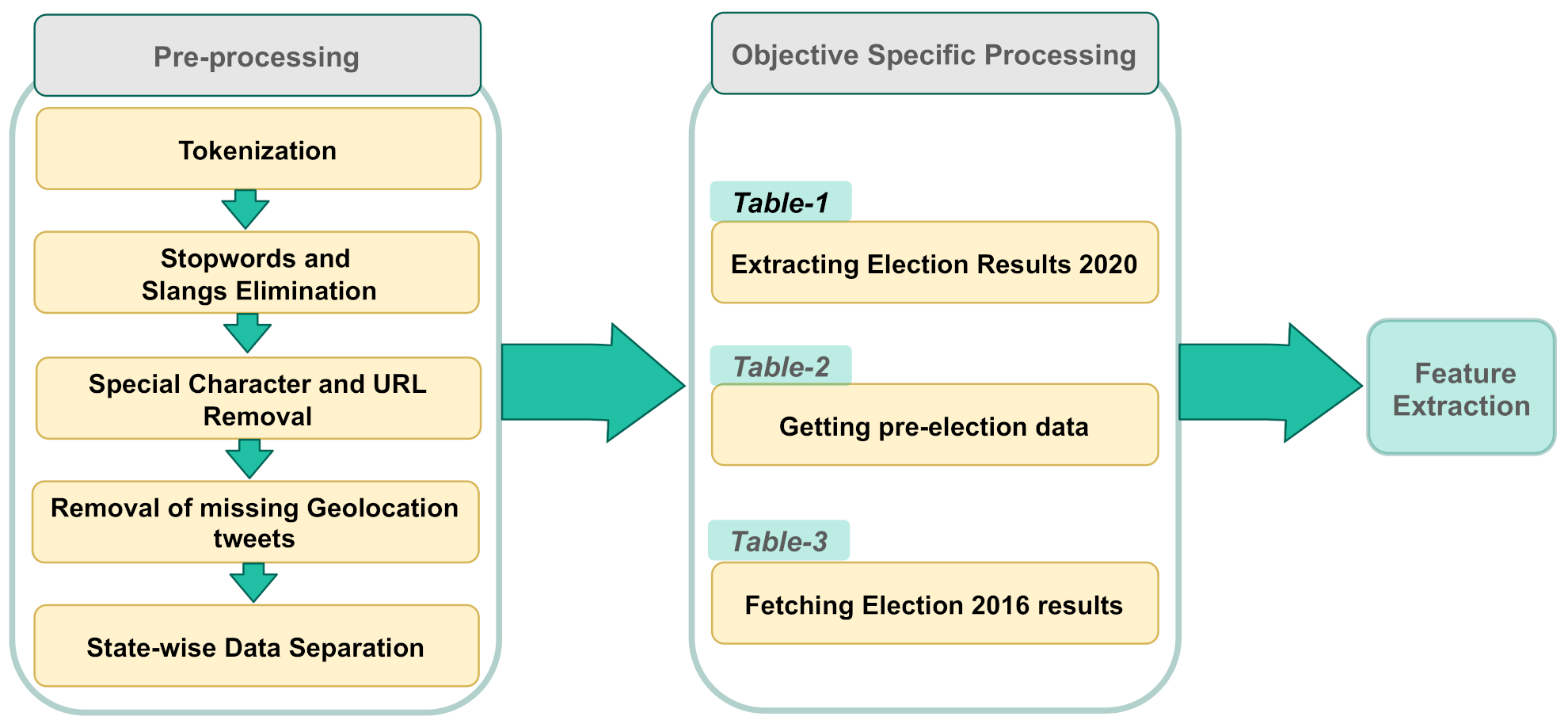
4. Results
The following section describes the results of the sentiment analysis.
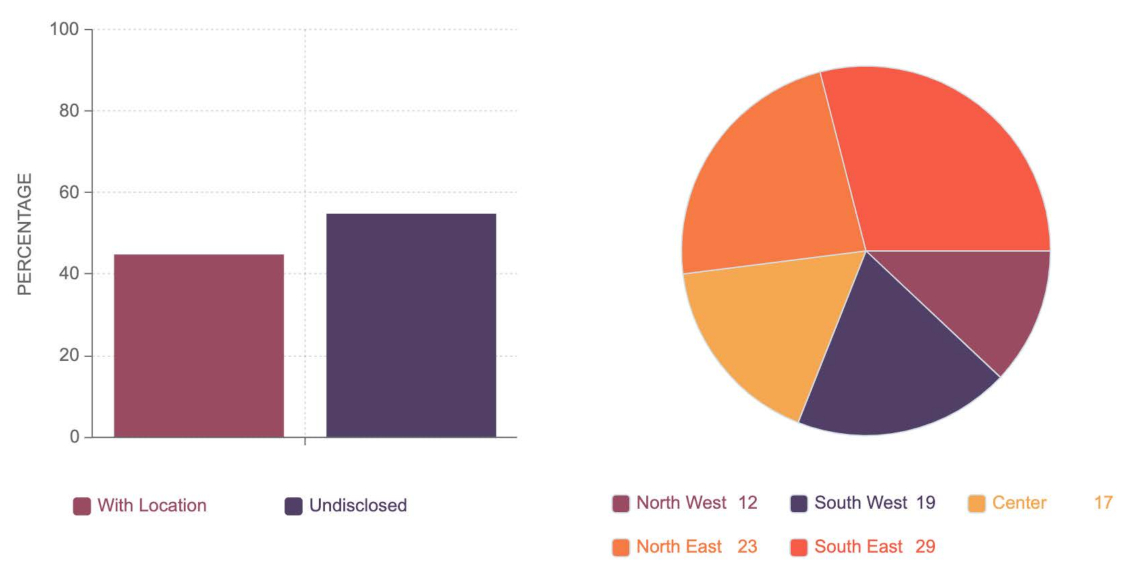
Figure 4 shows the breakdown of tweets with and without the location. The tweets were divided into five zones; north west (Idaho, Montana, Oregon, Washington, and Wyoming), South West (Arizona, Colorado, California, Nevada, New Mexico, and Utah), center ( Iowa, Kansas, Minnesota, Missouri, Nebraska, North Dakota, Oklahoma, and Texas), south east (Arkansas, Alabama, Florida, Georgia, Louisiana, Mississippi, North Carolina, South Carolina, and Tennessee) and all remaining states in north east.
Figure 4 shows the percentage of tweets collected from these zones. It can be noted that these zones may not precisely resemble the geographic zones but are organized for ease of analysis. Among the remaining 18432811 tweets, only 6614906 lay in the period around elections and were utilized for positive and negative sentiment analysis in
Section 4.1. The remaining 11817905 tweets were employed for retrospective analysis in
Section 4.2.
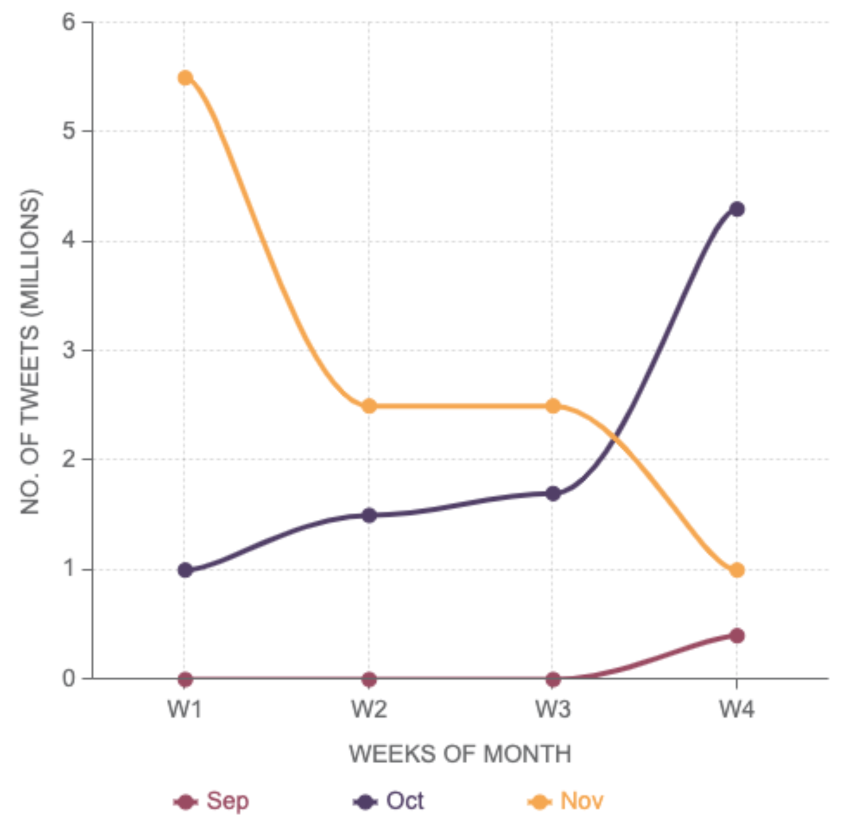
Figure 5 depicts the total number of tweets in different weeks of September, October, and November. It can be noticed that most of the tweets are in the window of mid-October to mid of November. To examine the statistical distribution of data among diverse age and gender groups,
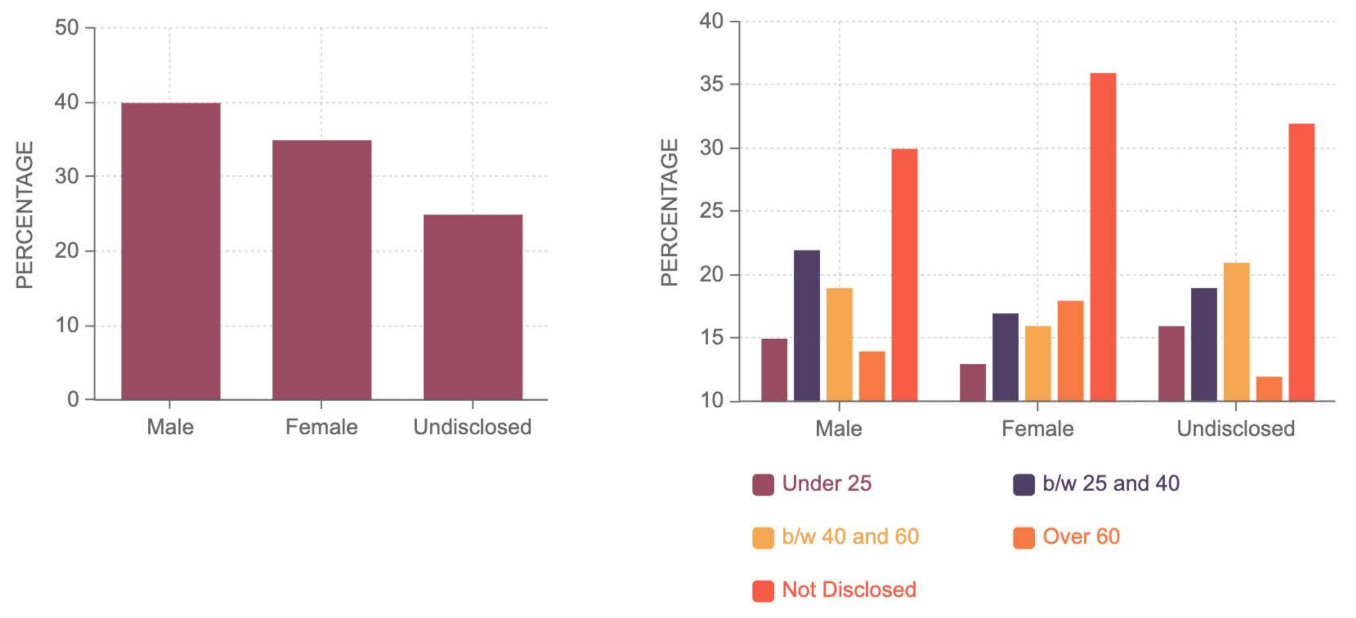
Figure 6 provides further insights into data distribution characteristics. It could be observed that the most dominant gender is male with 40%, followed by 35% females. Finally, 25% of the users have either did not disclose their gender or could not be determined directly. It is also interesting to note that most male users are in the age range of 25 and 60. In females, the most dominant users are over 60; however, over-60 users are not very prominent in males. It can also be noted that the female users who do not disclose their age group are higher than males.
The remainder of the section is divided into multiple subsections;
Section 4.1 analyzes Twitter sentiment against actual election results. This subsection also identifies extreme positive and negative sentiment for the given candidates and outlier states where election results do not match Twitter sentiments.
Section 4.2 inspects shifts in Twitter sentiment before and after elections; negative and positive transitions are highlighted for each candidate.
Section 4.3 collates Twitter sentiments between the elections in 2016 and 2020 and identifies sentiment variations after and before Trump’s tenure.
Section 4.4 further explains on outlier states and discusses positive and negative sentiment highlighted in
Section 4.1. The last section,
Section 4.5, analyzes Twitter sentiments during and before elections regarding issues and agendas and identifies which issues earned more attention during the election period.
4.1. Twitter Sentiments and Election Results
For election results analysis, 18,432,811 tweets with locations were considered; only 6,614,906 lay in the period around elections and were employed for positive and negative sentiment analysis for all fifty states, performed for contesting candidates Joe Biden and Donald Trump. The remaining 11,817,905 tweets were used for retrospective analysis, shown in
Section 4.2.
Table 1 shows the average value of public sentiment obtained two days before, during the elections, in the result compilation phase, and two days after the results. The results are compared with the actual results of the elections. The populations according to the 2019 census in millions is given in the
Pop. column of
Table 1 [
56]. Since the number of tweets (shown in column
Tot. Tweets) in a certain state in the recording period are much less than the population, they indicate a sample space for certain sentiments against a given set of hashtags. However, a similar sample set is used for both candidates; therefore, the percentage represents a sufficient indication of public sentiments. The U.S. election results are taken from the BBC website and are given in
Elec. (
T) and
Elec. (
B) for Donald Trump (T) and Joe Biden (B), respectively. In most cases, the public sentiment results coincide with the actual election results; however, there are four states where the Twitter sentiment and the actual results are inconsistent. The outliers Arizona, Wisconsin, Georgia, and Pennsylvania are highlighted in black. Further analysis of the
Table 1 is as follows:
West Virginia, Oklahoma, North Dakota, Montana, Kentucky, Arkansas, and Alabama have the highest positive sentiments for Donald Trump, indicated in green. On the other hand, California, Maine, and New York have the highest positive sentiment for Joe Biden;
In contrast, California, Delaware, Hawaii, Illinois, Maryland, and Massachusetts have the highest negative sentiment for Donald Trump, indicated in red. On the other hand, Arkansas, Idaho, Iowa, Kansas, and Kentucky have the most negative sentiment for Joe Biden;
Finally, some states have extreme positivity for one candidate and extreme negativity for the contestant. Arkansas and Kentucky have the highest positive sentiment for Donald Trump and the highest negative sentiment for Joe Biden. California has the highest negative sentiment for Donald Trump and the highest positive sentiment for Joe Biden.
Further analysis into outlier states and states with extremely positive and negative sentiments, are analyzed in
Section 4.4.
4.2. Pre- and Post-Election Twitter Sentiments Analysis
Elections exhibit a shift in the public’s opinion due to the influence of news, election campaigns, and live debates. The sentiment drift is a subtle phenomenon, as it may have numerous intricate dimensions. This subsection inspects public opinion changes considering tweets during the first week of October and tweets two days before, during, and two days after the results announcement. The average sentiment of one week exactly one month before the election, i.e., 3 October to 10 October 2020, is employed as a pre-election sentiment value. In contrast, the method for post-election is similar to that described in
Section 4.1. The primary goal was to determine the shift in public sentiment before and after or during the elections. Among 18,432,811 available tweets with locations, 6,614,906 were used for post-election analysis, while 4,329,302 were employed for pre-election analysis.
Table 2 provides positive and negative sentiments for each state before and after the election. All the states with a drift of more than five are highlighted in different color codes;
Table 2 shows green and red color codes for increasing and decreasing sentiments in a certain state. It is interesting to remark that eight states have an opposing drift for Trump that decreased in positive sentiment and increased in negative sentiment, i.e., Alabama, Arizona, Florida, Kansas, Maine, Maryland, Massachusetts, and Michigan. Despite the opposing drift, Trump managed to win five states, including Alabama, Arizona, Kansas, Maine, and Michigan.
In terms of the opposing drift positive sentiment in these states, this was much higher for Trump than for Biden. Four states had favoring drift for Trump, including Arkansas, Connecticut, Mississippi, and Nebraska. Notwithstanding favoring drift, Donald Trump lost Connecticut, since Biden had much higher positive sentiment; in other words, Connecticut still selected Biden despite positive sentiments for Trump. Similarly, seven states had an opposing drift for Joe Biden, including Alabama, Arkansas, Illinois, Iowa, Kansas, New York, and Kentucky. Despite having an opposite drift, Joe Biden secured Illinois and New York due to high positive sentiments. Florida was the only state favoring sentiment drift for Joe Biden, but it is an interesting case study. Despite having positive sentiment during the election, favoring drift for Joe Biden, and opposing drift for Trump, Joe Biden lost Florida.
4.3. Comparison of Sentiment Drift during Election of 2016 and 2020
Donald Trump won the election of 2016 by securing 304 electoral votes against 227 electoral votes by Hillary Clinton. The natural extension of sentimental drift analysis is to compare sentiment from the election of 2016. The research provides a state-by-state sentiment analysis of the election of 2016 [
48]. Although this research uses a scale of 100 to define positive and negative sentiment, the work considered for the election of 2016 does not use the same scale. However, since, for both candidates, we use the same scale, this does not make a difference in terms of drift analysis. The increase in drift from both positive and negative sentiment scoring more than fifteen and more are highlighted in green, while the negative drift scoring ten or more is highlighted in red. The results of the state-wise analysis are shown in
Table 3.
The states with an increase in positive sentiment for Joe Biden from the 2016 election and 2020 election were Colorado, Connecticut, Delaware, Florida, Georgia, Hawaii, Maine, Minnesota, New Hampshire, New Jersey, New York, and Washington. Joe Biden was able to secure victory in all these states. There was an increase in Arkansas, while there was a decrease in negative sentiment for Joe Biden in Maine. In the 2020 elections, Biden was able to win Maine and lost Arkansas, which corroborates with the sentiment analysis results. On the other hand, Donald Trump gained positive sentiment in Alabama, Idaho, Iowa, Kentucky, Louisiana, Mississippi, Montana, Nebraska, North Dakota, Okhalama, and West Virginia. Donald Trump was able to win all states where there was an increase in positive sentiment. There were eleven states where Donald Trump raised negative sentiment; California, Delaware, Hawaii, Illinois, Maine, Maryland, Massachusetts, Rhode Island, South Carolina, Virginia, and Washington. Donald Trump was able to succeed in South Carolina and Virginia and lost the remaining nine states. The only state where there was a reduction in negative sentiment is Hawaii, and Donald Trump lost it.
4.4. Analysis of Outlier and Extreme Sentiments
Table 1 in
Section 4.1 shows four outlier states; Arizona, Wisconsin, Georgia, and Pennsylvania. In all four states, the election results were different to the sentiments expressed on Twitter. This subsection analyzes the sentiment in further detail by considering an increase or decrease in both positive and negative sentiments weekly between the last week of September to the third week of November 2020.
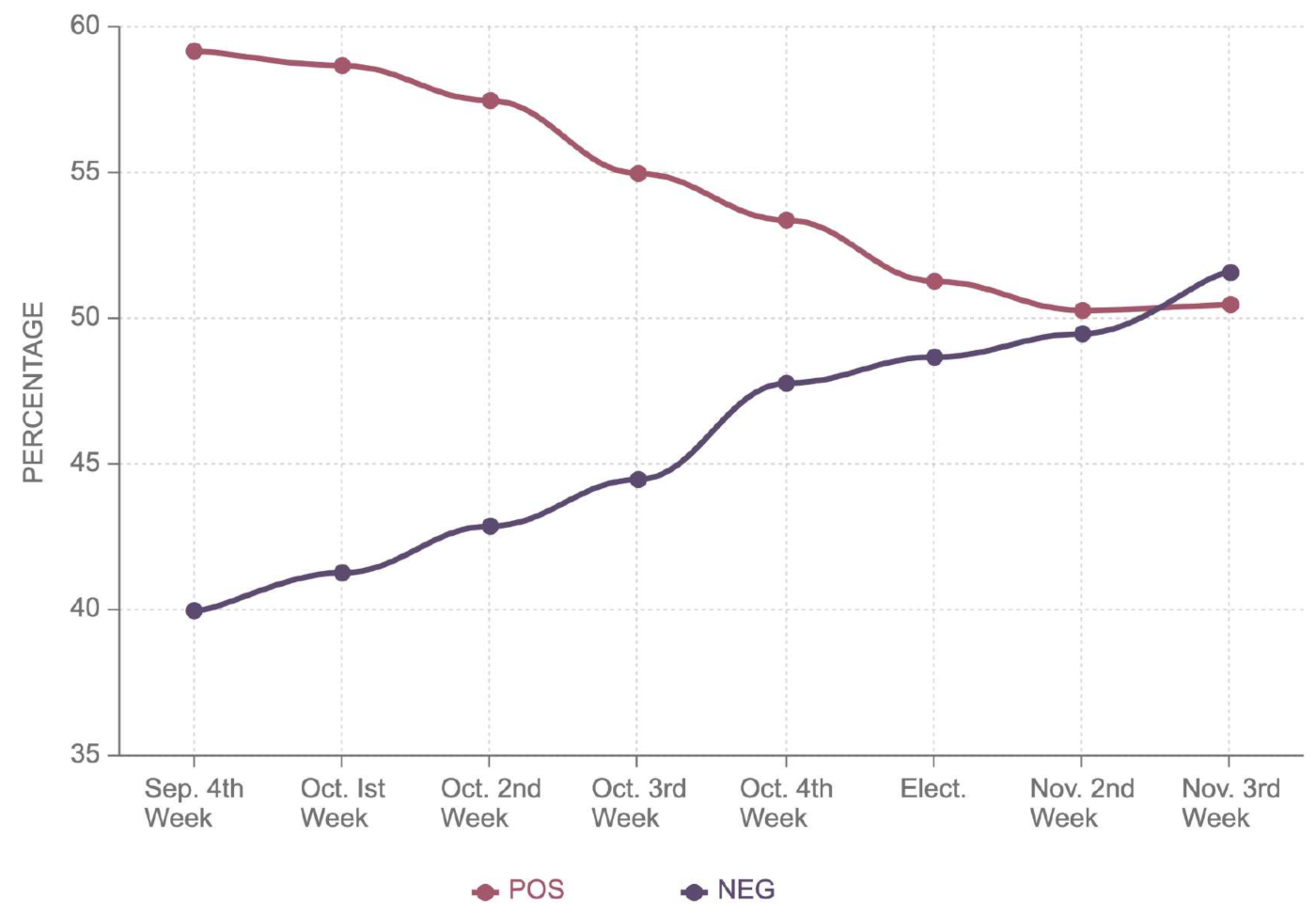
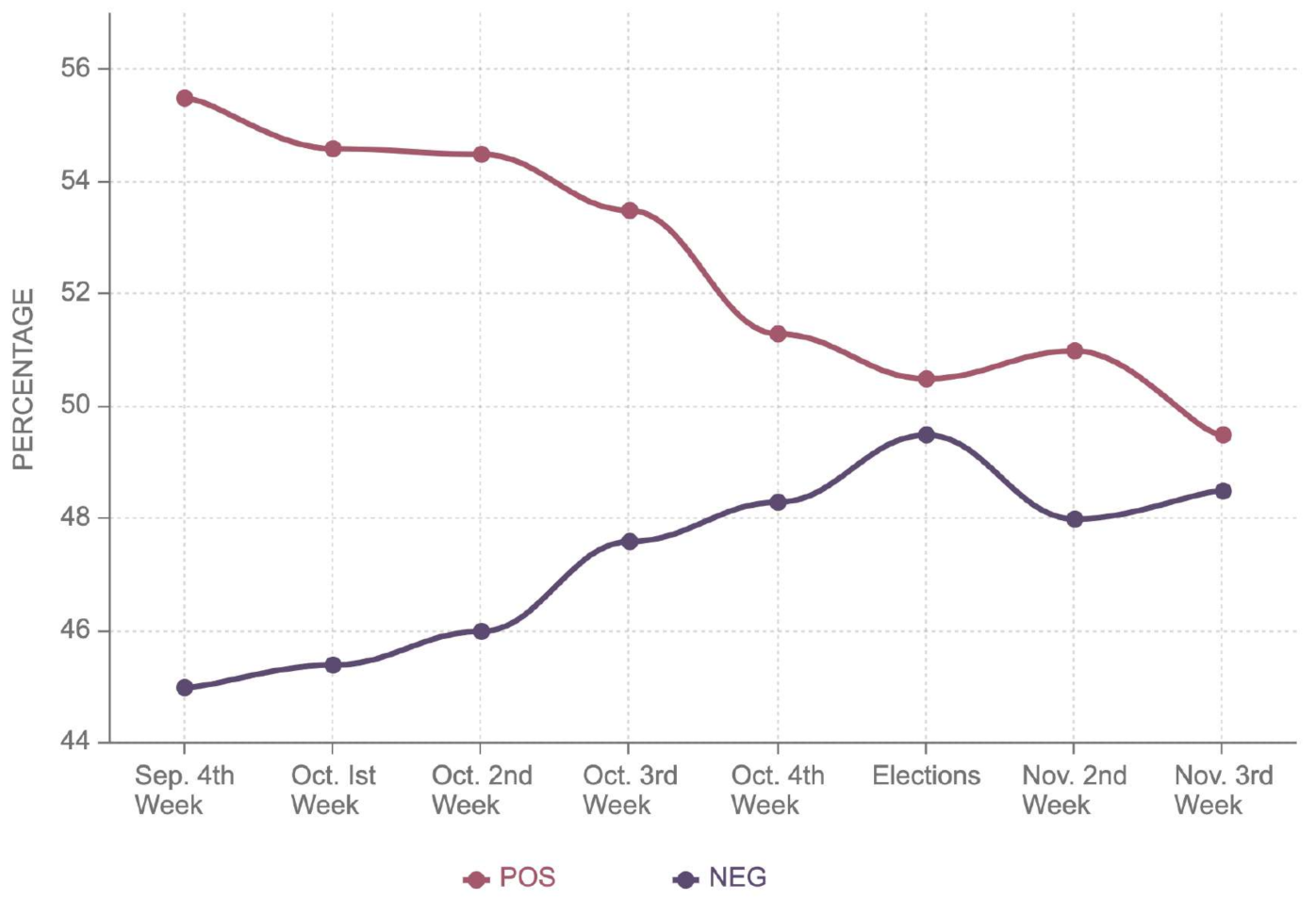
Figure 7 shows a 10% decrease in positive and a 12% increase in negative sentiment. During the elections, it stood as 51.3% positive and 48.7% negative for Donald Trump.
It can be observed that post-election, the negative sentiment further decreased to 52%, surpassing positive sentiment. On the contrary,
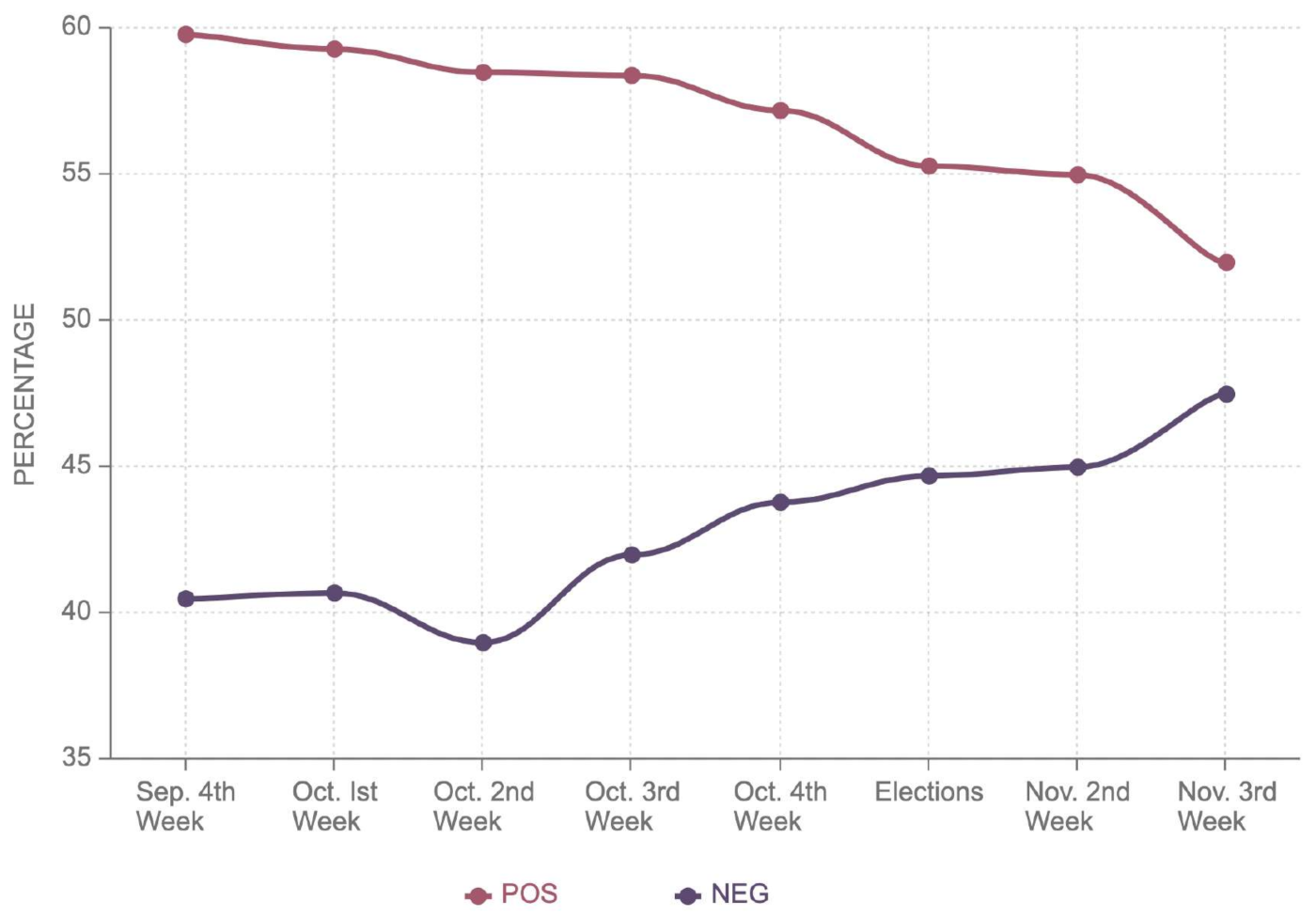
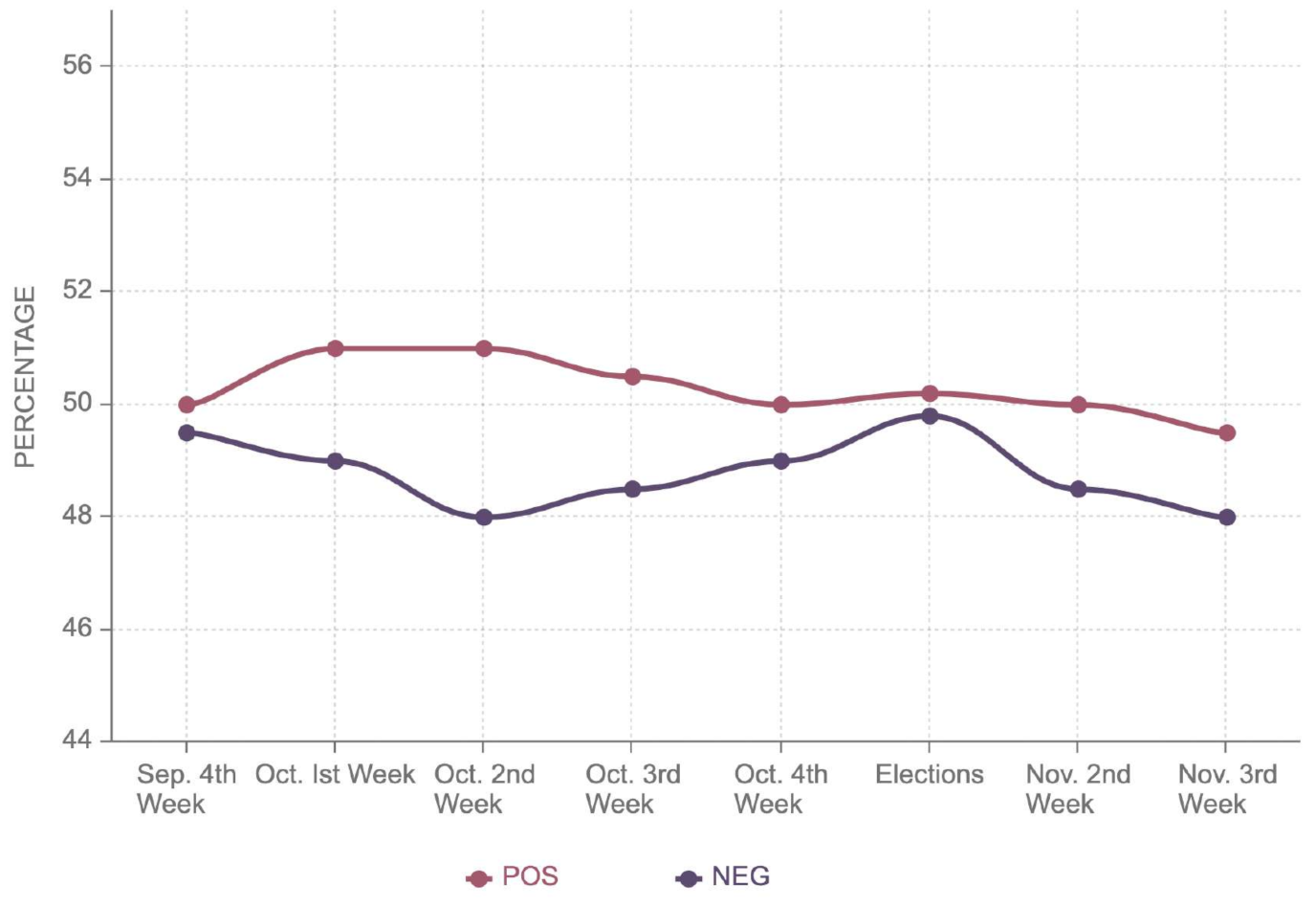
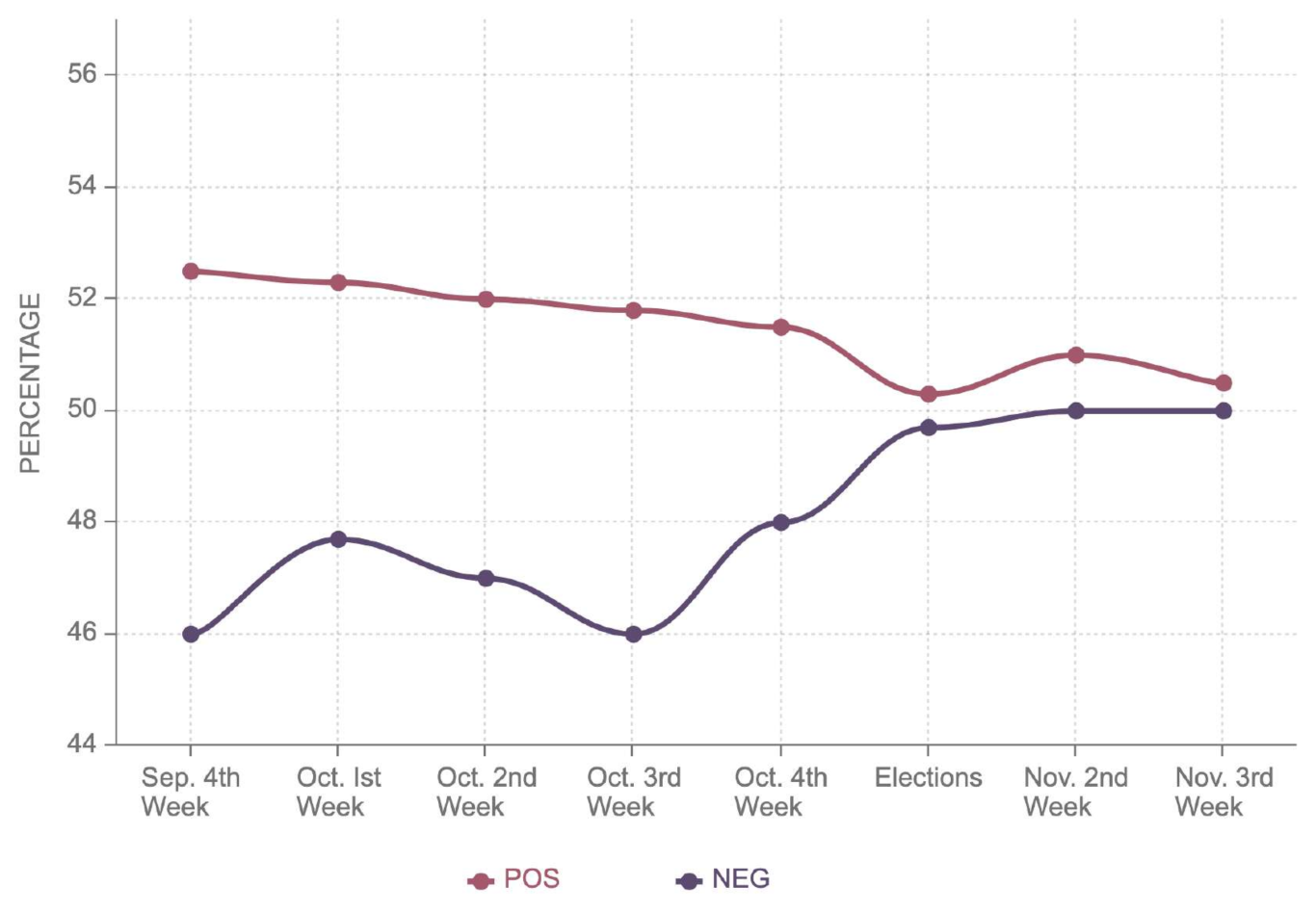
Figure 8 shows that the negative sentiment for Joe Biden decreased from 49.4% to 49%, while the positive sentiment remained almost around 50%. This explains the marginal victory of Joe Biden with 49.4% as compared to 49.1% by Donald Trump. Joe Biden bagged 49.5% of the electoral votes, securing a narrow victory against Trump, who had 49.3% in Georgia. This state is the outlier considering Donald Trump had more positive sentiment, 55.3%, as opposed to 54.5% for Joe Biden. Similarly, he also had less negative sentiment, 44.7%, as compared to Joe Biden’s 45.5%. It can be noted in
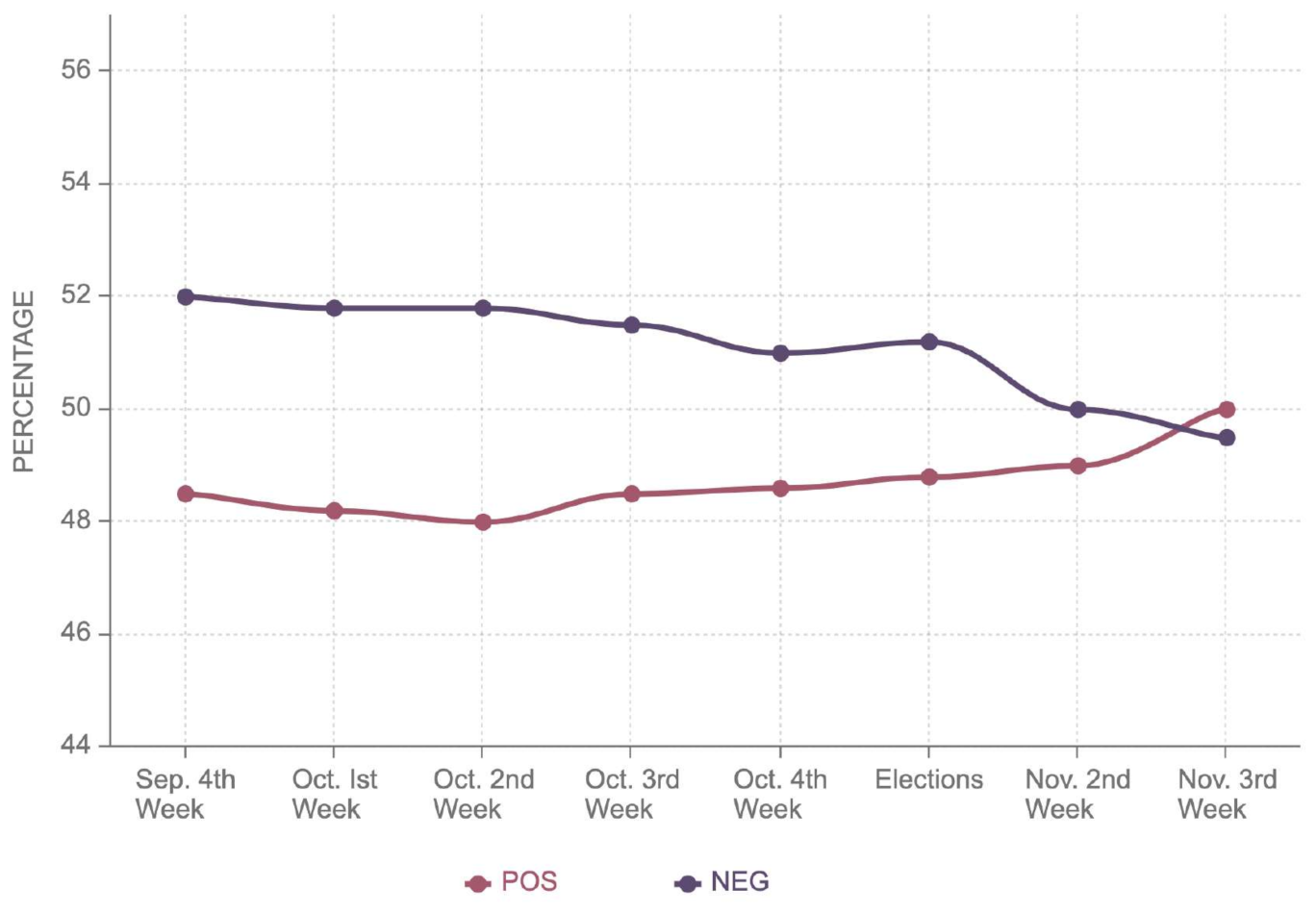
Figure 9 that Biden’s negative sentiment in Georgia decreased steadily, reaching 45.5% two weeks after the election; on the other hand, Trump’s negative sentiment grew to 47%, as shown in
Figure 10. Likewise, the positive sentiment of Donald Trump declined by 3% following the election, while positive sentiment for Biden improved by 1%. This illustrates the outcome of the election, even though sentiments were different from the election outcomes.
In terms of sentiments and election result analysis, Pennsylvania shows considerable differences when compared to Georgia and Arizona as shown in
Figure 11 and
Figure 12. The electoral margin between both candidates was 50%, compared to 48.8% in favor of Joe Biden. However, inspecting the sentimental shift after the election does not provide evidence of an electoral lead. The positive sentiment for both candidates stood at around 50%, while the negative sentiment for both candidates was around 48%. If a long-term sentiment trend is observed, Donald Trump had a much higher positive sentiment a month before the election. Nevertheless, there is no trivial method in our analysis to justify the outlier for Pennsylvania.
Wisconsin was another state where a very narrow competition was anticipated. Joe Biden edged the victory by securing 49.4% of the electoral votes against 48.8% of the electoral votes obtained by Donald Trump. However, the sentiment analysis exhibits 2% more positive sentiment of Donald Trump as compared to Joe Biden. Similarly, Trump had 49.7% while Biden has 51.2% negative sentiment. The comparison of
Figure 13 and
Figure 14 reveals that both positive and negative sentiments of Trump and Biden were around 50%. However, it can also be noticed that Biden’s negative sentiment decreased from 52% to 50%; on the contrary, the positive sentiment improved from 48% to 50%. The trends for Trump were entirely opposite to that of Joe Biden. This reflects that despite identical sentiments for both candidates, Biden’s repute in the state improved considerably.
Table 4 shows extreme positive and negative sentiments shown in green and red, respectively. Maine had the highest positive sentiment; however, Maine’s margin of victory was lowest among all states with extreme positive sentiment. California seemed the best stronghold for Joe Biden, since the positive sentiment was comparable to Maine. The margin of victory was highest among all states with extreme positive sentiment.
Table 5 shows sentiments with extreme negative sentiments for Donald Trump. Despite having the highest negative sentiment, Illinois had the lowest margin of elections in all states with extremely negative sentiment.
Table 6 shows extreme positive sentiments: Arkansas had the highest positive sentiment; however, the highest margin of victory was noticed in West Virginia. In most cases, the margin of victory and the sentiment coincided with each other.
4.5. Sentiment Analysis on Policy Matters
The sentiment analysis on policy matters was carried out in states where Trump and Biden won. The sentiment analysis on policy matters was based on keywords used by supporters; we used a predefined dictionary of keywords for each agenda or issue. This revealed which issues were discussed during elections while voting for a particular candidate. In
Table 7, it can be seen that the top five issues for states won by Trump were the economy, coronavirus, Supreme Court appointments, foreign policy, and the health care system. On the other hand, the top five issues for states won by Biden were the economy, Supreme Court appointments, immigration policy, the health care system, and coronavirus, as shown in
Table 8. Interestingly, the economy, coronavirus, Supreme Court appointments, and health care system are common for states won by both candidates. However, immigration policy is among the most discussed issues for Biden’s states, but it is not among the top five in Trump’s states. Nevertheless, the economy, Supreme Court appointments, health care system and coronavirus are the most discussed issues among both. Among these, Supreme Court appointments and coronavirus were newly emerging issues during these elections, while the economy, the health care system, immigration policy, and foreign policy are recurrent issues.
4.6. Accuracy and Performance Evaluation
We chose thirty thousand tweets to create a training and testing dataset. LIWC was employed to label this dataset, followed by manual inspection. Two thousand tweets were discarded to create a balanced dataset of equally positive and negative class labels, yielding a labeled dataset of twenty-eight thousand tweets. This dataset was partitioned into a 60% training and 40% testing dataset. After training the Naive Bayes classifier, the system was tested over the 40% testing dataset. The confusion matrix for the tested test set of tweets and the results are shown in
Table 9. Based on the confusion matrix, the results show the accuracy of 94.58%, with the precision of 93.19% and F1 score of 94.81%, also shown in
Table 10. It should be noticed that in
Table 10, true positive (TP) stands for the actual class being positive and predicted class being positive, and false negative (FN) stands for the actual class being positive while the predicted class is negative. Moreover, false positive (FP) dnotes that the actual class is negative while the predicted class is negative. Finally, for true negative (TN), the actual class is negative while the predicted class is negative.
6. Conclusions
We collected a dataset from Twitter for sentiment analysis of the 2020 U.S. presidential elections. The data were collected before, during, and after the election to measure the public sentiment over social media, and it was compared with the actual election results. The research employed TF-IDF to extract features from the given tweet and used a Naive Bayes classifier to obtain positive or negative sentiment for the given candidate.
In most cases, the public opinion expressed over Twitter coincided with the election results, except four outliers: Arizona, Wisconsin, Georgia, and Pennsylvania. To obtain further insight into outliers, we analyzed sentiment before and after the election. We noticed a sharp decrease in Arizona regarding the positive sentiment of Donald Trump, while Biden’s sentiment remained consistent. Similarly, there was a pattern of increase in the positive sentiment of Biden in Georgia, while Trump’s positive sentiment dropped during the same period. To summarize, for all states where sentiment results did not corroborate with election results, long-term trends before and after the election reveal that there was an increase in the positive sentiment of the winning candidate. At the same time, there was a decrease in positive sentiment for the losing candidate. We conclude that the sentiment analysis results show a similar trend in the presidential elections despite allegations of rigging or election fraud. We also identified that the economy, coronavirus, immigration policy, Supreme Court appointments, and health care systems are important issues on which voters decided to vote for certain parties.



 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}