1. Introduction
Zero-day intrusion detection is a serious challenge as hundreds of thousands of new intrusions are detected every day and the damage caused by these intrusions is becoming increasingly harmful [
1,
2] and could result in compromising business continuity. Computer attacks are becoming more complicated and lead to challenges in detecting the intrusion correctly [
3].
Intrusion detection systems (IDS) detect suspicious activities and known threats and generate alerts. Intrusions could be identified as any activity that causes damage to an information system [
4]. IDS could be software or hardware systems capable of identifying any such malicious activities in computer systems. The goal of intrusion detection systems is to monitor the computer system to detect abnormal behavior, which could not be detected by a conventional packet filter. It is very vital to achieve a high degree of cyber resilience against the malicious activities and to identify unauthorised access to a computer system by analysing the network packets for signs of malicious activity.
IDSs use two broad methodologies for intrusion detection: The Signature-based Intrusion Detection System (SIDS) and Anomaly-based Intrusion Detection System (AIDS). SIDS, also called Knowledge-Based Detection or Misuse Detection, is a process where a signature identifier is determined about a known malware so that malware can be detected in the future [
5]. If that specific signature is identified again, the traffic can be identified as being malware. SIDS usually gives an excellent detection accuracy, particularly for previously known intrusions.
Since SIDS can be as effective as the update of the signature database, three issues arise. Firstly, it is easy to trick signature-based systems through the polymorphic behavior of malware. This method fails the similarity test as it does not match with any signature stored in the IDS database, giving the attacker a chance to gain access to the computer system. Secondly, the higher the number of signatures in the database, the longer it takes to analyses and process the huge volume of data. Thirdly and most importantly, SIDS has difficulty in detecting zero-day malware as the signature is not stored in the database [
6].
AIDS systems have overcome the limitation of SIDS and are being used to identify malicious attacks on computer systems. The assumption for this technique is that the profile of a malicious activity differs from typical user behavior activities [
7]. AIDS creates a statistical model describing the normal user activity and any abnormal activity that deviates from the normal model is detected. The design idea behind AIDS is to profile and represent the normal and expected standard behavior profile through monitoring activities and then definining anomalous activities by their degree of deviation from the normal profile. AIDS uses features such as the number of emails sent by a user, the number of failed logins tries for a user, and the degree of processor use for a host in a given timeframe in learning the normal behaviors. Anomaly detection techniques have the ability of strong generalizability and to detect new attacks, while its drawbacks could be in the form of large false alarm rates due to the changing cyber-attack landscape.
The behaviors of alien users are deemed different to the standard activities and are categorized as intrusions. AIDS includes two phases: Thee training phase and testing phase. In the training phase, the normal traffic profile is learned from the data that represent normal behavior, and then the testing is done on a data set that is not seen by the model during the training phase.
AIDS could be classified into several sub-classes based on the learning methods, for instance, statistical based, knowledge based, and machine learning based [
8].
The key advantage of AIDS is its ability to identify zero-day attacks as it does not have to rely on the signature database to detect an attack. AIDS triggers an alert signal when the examined behavior differs from the usual activity [
9]. Furthermore, AIDS has various benefits: Firstly, it has the capability to discover internal malicious activities. If an intruder starts transacting on a stolen account, which could be misidentified as the normal user’s activity, then it generates an alarm. Secondly, it is very difficult for a cybercriminal to learn what a normal user’s behavior is without producing alerts, as the system is constructed from customized profiles [
4].
Traditional IDSs have limitations: Inability to differentiate new malicious attacks, the need to be updated, low accuracy, and high false alarms. AIDS also has shortcomings such as a high number of false alarms [
10]. To overcome those limitations, an innovative IDS model is proposed with the integration of SIDS and AIDS in order to achieve accuracy and to reduce the false alarm. Well known intrusions could be detected by SIDS and new attacks could be detected by AIDS.
In this paper, the signature intrusion detection system is built, based on the C5.0 Decision tree classifier, and the Anomaly intrusion detection system is built, based on one-class Support Vector Machine (SVM). The target is to understand how the intrusion detection system accuracy can be enhanced by utilising the ensemble stacking technique. While the traditional intrusion detection system concentrates on how the performance of a one classifier can be enhanced, this research studies how diverse machine learning techniques can be integrated to enhance intrusion detection accuracy. In this research, two machine learning techniques, namely the decision tree c5 and one class SVM classifier, were chosen to build the intrusion detection system. The decision tree c5 and one class SVM classifier have been evaluated independently and in combination by using stacking ensemble, which is tested as well.
Our paper makes the following contributions:
Proposes a novel intelligent framework to identify well-known intrusions and zero-day attacks with high detection accuracy and low false-alarm rates.
Develops a stacked hybrid IDS based on SIDS and AIDS to harness their respective strengths for better detection.
Evaluates Hybrid Intrsuion Detection System (HIDS) on the Network Security Laboratory-Knowledge Discovery in Databases (NSL-KDD) and Australian Defence Force Academy (ADFA) datasets benchmark datasets in terms of accuracy and F-measure, and studies and validates its superior performance.
The rest of the paper is organized as follows:
Section 2 reviews a few related works.
Section 3 describes the detailed description of the proposed hybrid intrusion detection. Experimental results are presented in
Section 4.
Section 5 concludes the paper with a brief discussion and summary.
2. Related Work
There are many IDSs in the literature to identify abnormal activities, but most of these IDSs produce a large number of false positives and low detection accuracy. However, many hybrid IDSs have been proposed to overcome the drawbacks of SIDS and AIDS. Sumaiya et al. proposed an intrusion detection model by applying the chi square attribute extraction and multiclass support vector machine [
11]. Syarif et al. used boosting, stacking, and bagging ensemble techniques for IDS to enhance the intrusion detection rate and to reduce false alarms [
12]. They used four diverse machine learning techniques: Naïve Bayes, artificial neural networks, decision tree, genetic algorithms, rule induction, and k-nearest neighbor as the foundation classifiers for the ensemble methods. They highlighted that their proposed method has an accuracy of 99% in finding known attacks, but could only identify zero-day attacks at around 60% accuracy rates.
Kim et al. [
13] presented a HIDS technique that hierarchically combines SIDS and AIDS models. Signature detection is developed based on the J48 decision tree classifier. Then, various one-class support vector machines models are built for the split subsets, which can reduce the profiling capability.
Muniyandi et al. [
14] proposed an anomaly detection method that employs “K-Means + C4.5”, for classifying anomalous and normal activities in a computer system. The K-Means clustering method is employed to divide the training data into k number of clusters by using the Euclidean distance similarity. The Hybrid method beats the individual method in terms of accuracy, but it causes high false alarms.
Al-Yaseena et al. [
15] proposed a multi-level hybrid IDS which employs SVM and extreme learning machine to enhance the detection efficiency for known and unknown attacks. The system performed well on the KDD Cup 1999 dataset in terms of the false alarm rate, which was 1.87%.
Koc et al. proposed the Hidden Naïve Bayes (HNB) model for IDS issues such as dimensionality, correlated features, and big data stream [
16]. The results showed that this method achieved an overall performance that was comparable to the Naïve Bayes model. Sivatha et al. proposed a lightweight IDS to classify abnormal activities in the network using wrapper based feature selection techniques that create good intrusion detection rates by adding the neural ensemble decision tree classifier [
17].
M. Alazab proposed a methodology to extract features statically and dynamically from malware such as the Windows Application Programming Interface (API) calls and create a malware behavior profile by extracting malware API calls throughout execution [
18].
Table 1 shows the IDS techniques and datasets covered by different intrusion detection system survey papers. Khraisat et al. presented a survey of current intrusion detection systems, which was a wide-ranging review of ID technqiues, and the datasets usually employed for evaluation purposes [
4]. Several intrusion detection system techniques that have been developed to improve the detection rate. However, such technques may have difficulty increating and updating the signarture of new malware and in yielding high false alarms or poor detection rates.
Ghanem et al. proposed a hybrid detection approach for large datasets using detectors generated based on different machine learning techniques. Anomaly detectors were developed based on self and non-self-training data to obtain self-detectors [
25]. K-means that clustering is used to decrease the volume of the training dataset by removing the redundant detector. The key role of AIDS is to create normal profiles of attacks. If the patterns are general in nature, then it is unable to identify several intrusions, which results in a poor detection rate. If the profiles are very specific, then it can identify different intrusions, but several normal behaviors could be classified as attacks. However, none of the previous works have attempted to strike a balance between accuracy and false positives. Recent studies focus on decreasing the false positive rate of AIDS by proposing a hybrid IDS. While earlier studies only integrate the results of both detection models, but in the proposed technique, the intrusion detection systems are hierarchically combined to improve accuracy. This allows the AIDS to improve its normal profiling capability with the use of the signature detection model. The details of the proposed Hybrid IDS are described in
Section 3.
3. Hybrid Intrusion Detection System
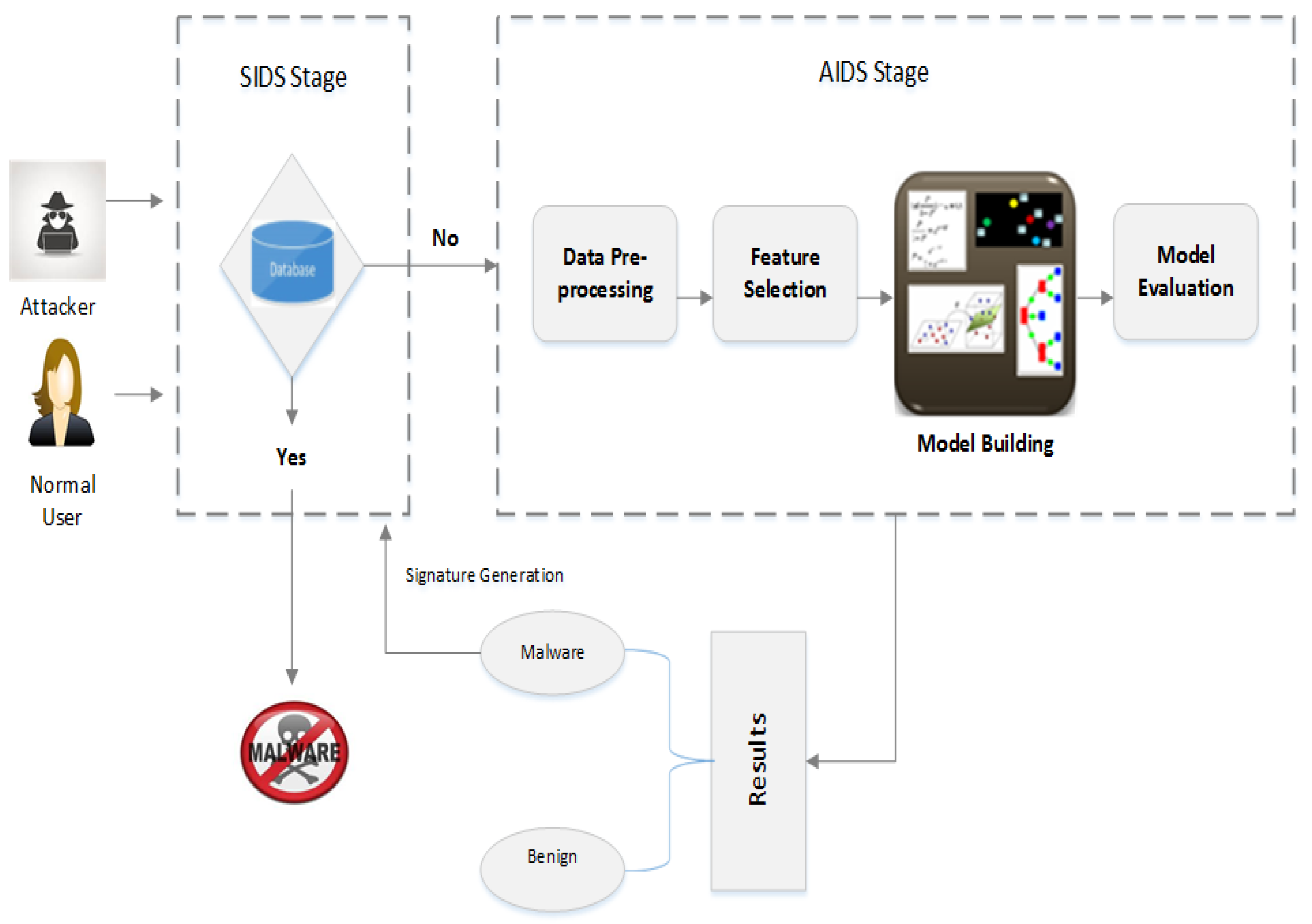
Hybrid IDS is developed to overcome the disadvantages of SIDS and AIDS as it integrates SIDS and AIDS to detect both unknown and known attacks. In our approach, we used AIDS to identify unseen intrusions, while SIDS is used to identify well-known attacks. Our system is based on three stages process:
Our hybrid IDS (HIDS) ultimately combines the C5 classifier (in the first stage) and One Class Support Vector Machine (in the second stage). The central idea of this novel approach was to combine the advantages of both SIDS and AIDS to build an efficient IDS. The Hybrid IDS has two phases; the SIDS phase and AIDS phase are shown in
Figure 1.
Our intrusion detection techniques included online and offline, which means detection intrusion later and online stages, which means detection intrusions in real-time. In the offline stage, the C5 classifier learning method was used to update the signature database. This stage deals with the stored signature and passes it through some processes to decide if it is an attack or not. In the online stage, the initial detection model was created using a one-class SVM. The online IDS deals with the network in real-time. This stage analyses the network traffic to decide if it is an intrusion or not.
AIDS profiles normal user activities and raises a malicious alarm when the difference between a given observation at an instant and the recorded value of the profile exceeds a predefined threshold. User profiles are created from the records generated from user activities and are marked as benign. AIDS feedbacks malicious records to SIDS to be saved in the signature database. The principle reason for storing the intrusion data in the signature database is to mitigate against known intrusions. The performance of the proposed HIDS and its components (SIDS and AIDS) are evaluated by conducting experiments separately. In the following, the two phases of the proposed detection system are elaborated.
3.1. Stage 1: SIDS Based C5
SIDS is used in the first stage as it provides high accuracy in detecting well known intrusions and generates low false alarms. As a result, false positives are low as all known signatures for malicious samples are kept in the database. Therefore, attacks can be detected with high accuracy while reducing false positives.
In SIDS, the C5 classifier is used in this stage to detect well-known intrusions. In our previous work, C5 was analyzed and contrasted with other machine learning techniques [
26]. The results revealed that C5 performs very well in terms of the detection rate and false alarm rate. The C5 algorithm is an improved version of the commonly used C4.5 classifier which was developed by Quinlan [
27], based on decision tree [
26]. It incorporates variable misclassification costs, handles missing data, can handle large numbers of input fields, and builds the model very fast. It takes a set of known data as the input and builds a decision tree from that data. In C5, the decision tree is built in a top-down fashion. The first attribute and its values are at the top of the tree and the next branch leads to either an attribute or outcome. C5 decision trees are created in view of a number of features and a set of training stages, and then the tree could be categorized by using a subsequent set to distinguish other samples.
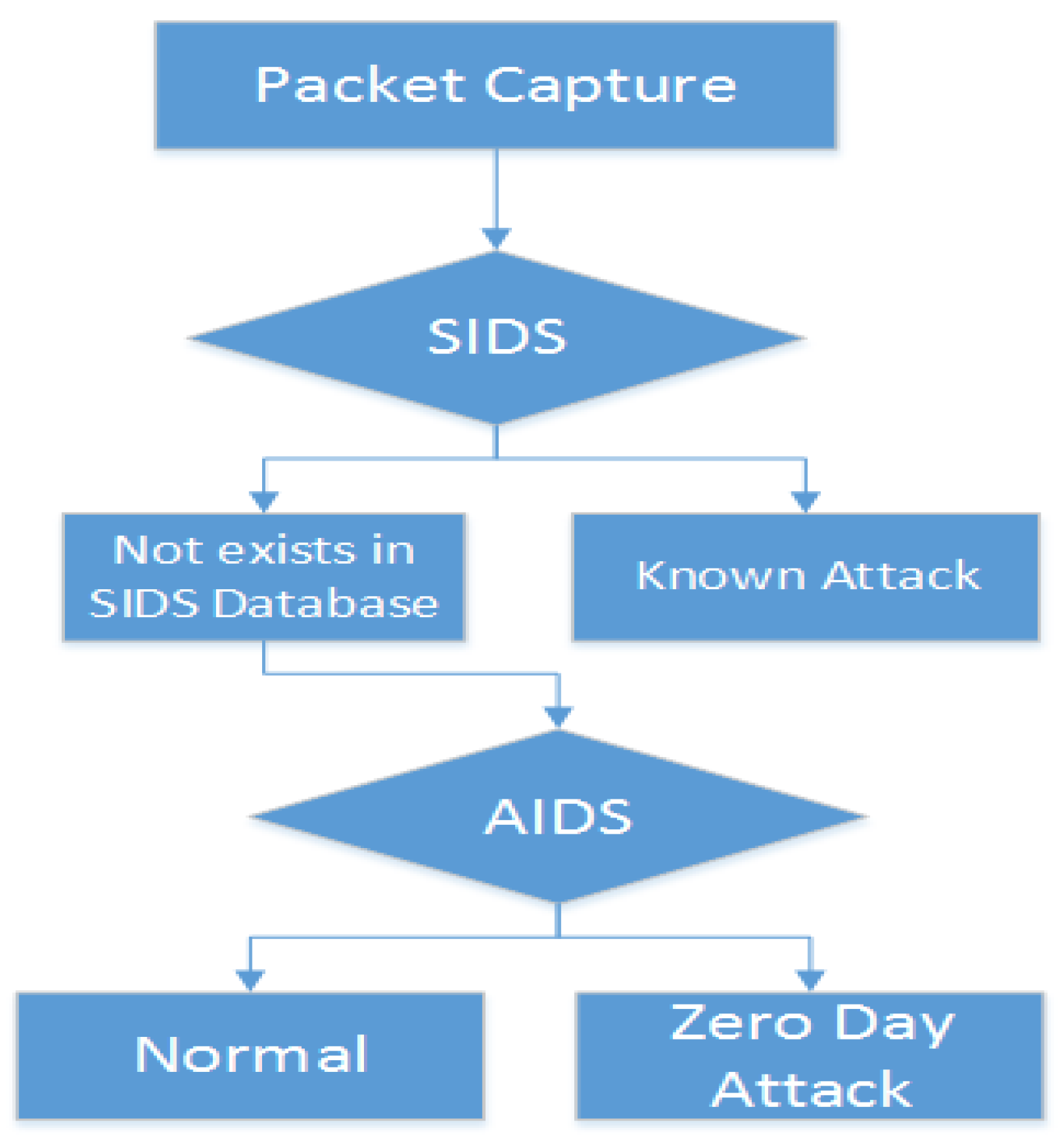
We have used the C5 classifier for SIDS, as shown in
Figure 2. Unknown samples are handled through pattern matching in order to determine whether they represent normal or abnormal activities. If the unknown sample is found in the signature database, then it triggers an alarm that it is a malware. If no match is found, it will go to AIDS, which is the second stage of the framework, as shown in
Figure 2.
The first stage of the proposed framework results in one of two possible outcomes: Known attacks and unknown samples. At the second stage, the unknown samples (branching out at ‘Not Exists’ in the figure) are then presented to AIDS for further training and analysis to overcome the shortcoming of SIDS.
3.2. Stage 2: AIDS Based One-Class SVM
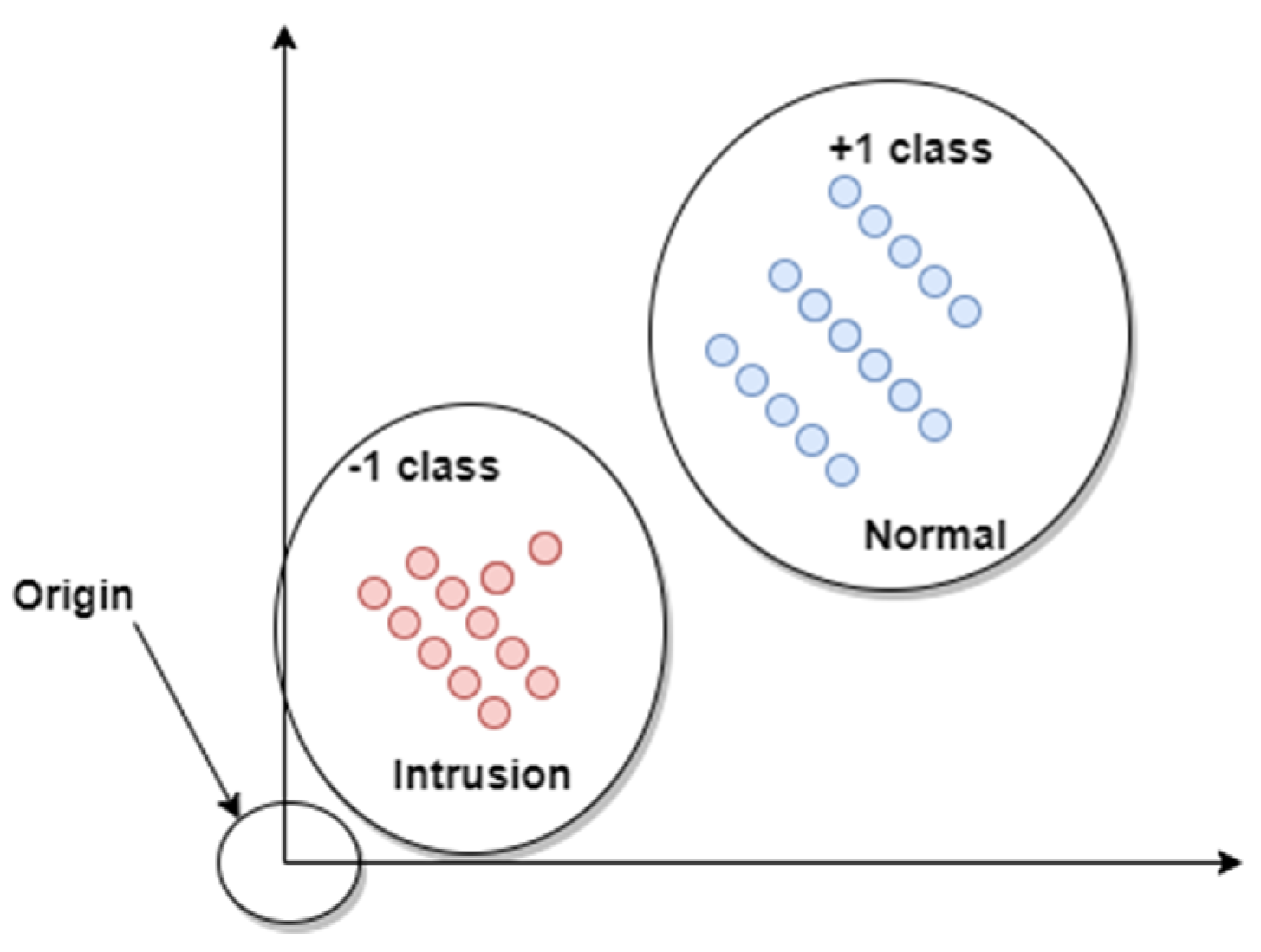
To successfully identify new intrusions, the result of the SIDS phase should be used as input data in the AIDS stage to detect new intrusions. AIDS should be built based on the normal activity of a user, which could have been used during the training stage. Then, intrusions are detected based on the measured state of the user profile, which is compared to the normal profile (determined based on the model), if it varies more than the described threshold, then it is marked as a malicious. The one class SVM learning model is used to identify normal behavior, as the One-class SVM (OCSVM), which learns the attributes of benign samples without using any information from the other class. One-class SVM was suggested by Schölkopf et al. [
28] to predict the support of a high-dimensional distribution by modifying the SVM method to the one-class problem. It involves the first feature processing through a kernel and then employs relaxation parameters to separate the test point of a class from the rest of the datasets or origin [
29], as illustrated in
Figure 3. Relaxation parameters techniques are iterative approaches for solving large sparse linear systems. It is also used to solve linear least-squares and nonlinear equations problems. Relaxation parameters help SVM to control the compromise between the reaching of a low detection rate on the training stage and a low detection rate on the testing stage, which is the capacity to identify and classify unknown malwares.
The OCSVM classifier transforms instances into a large dimensional attribute space (via a kernel) and locates the suitable location of the boundary hyperplane, which splits the training data. The OCSVM is a normal binary-class SVM where all the training data are based on the first class. Thus, we consider those profiles to be abnormal, which are close to the origin of coordinates in a feature space. The establishment of the hyperplane needs to follow the categorization rule:
where
is the normal vector and
is a bias term. The OCSVM adjusts the hyperplane to find a linear classifier by optimising the rule
. This classification rule can be used to assign a label to a test example
x.
is classified as an intrusion if the
result is less than zero, or else it is classified as normal. As presented in
Figure 3, the result of
f(
x) can clarify the classification condition: Positive is considered to in the normal class, negative is in the intrusion class.
The one class SVM intrusion detection system can be expressed as mapping the data into a feature vector H using a suitable kernel function, and then attempts to isolate the mapped vectors from the origin with a determined margin (see
Figure 3).
In stage 2 of the one class SVM, let
be the training examples belonging to one class X, where X is a compact subset of
. Let
Φ: X → H be a kernel map that transforms the training examples to another space. Then, to separate the data set from the origin, one needs to solve the following quadratic programming problem:
which is subject to
If w and ρ are solved in this problem, then the decision function
will be normal for most instances
comprised in the training data set.
The basic idea of OCSVM training is to build the OCSVM intrusion detection system that is able to detect the intrusions. Initially, both the training set and the test set are pre-processed to acquire the vector sets based on their unlikely data types. The training vector set at that point is employed to train the OCSVM intrusion detection system and the OCSVM detector is then used on the test vector set. If the return value result for the intrusion system OCSVM function
f(
x) is less than zero, an intrusion is detected, otherwise it is normal. This entire stage technique is shown in a flowchart in
Figure 4.
3.3. Stage 3: HIDS Based Stacking Ensemble of C5 and One-Class SVM
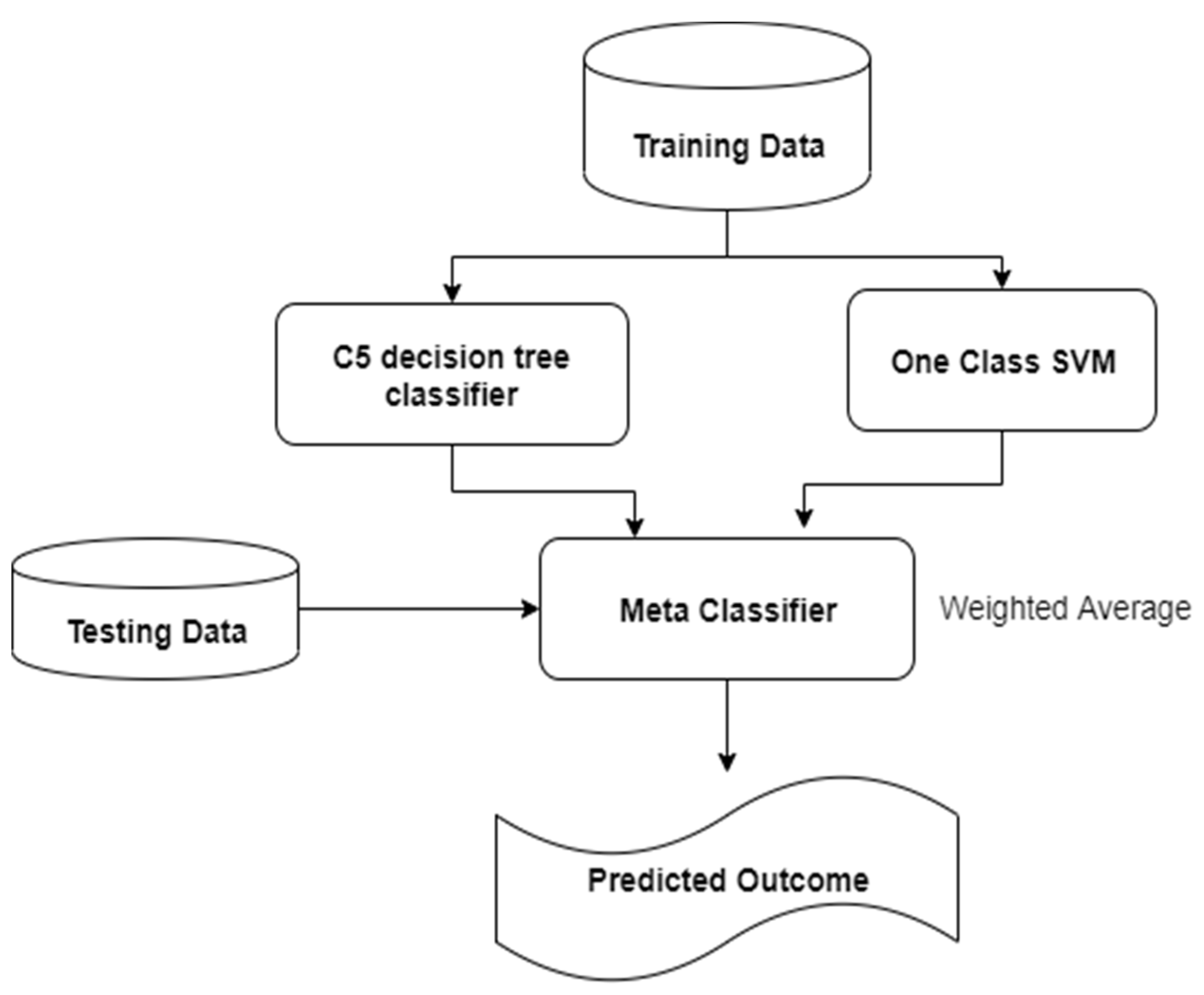
SIDS and AIDS have complementary strengths and weaknesses, so we developed a hybrid method using an ensemble of both techniques. In machine learning, ensemble techniques use many learning algorithms to accurately predict the outcome. In other words, different classifier models are trained on the same target and then their results are combined. In the first stage, a set of base level classifiers C1, C2, …, Cn are created. In the second stage, a meta-level classifier is built by uniting the base level classifier.
While many ensemble methods have been proposed in the literature, it is a difficult task to find a suitable ensemble configuration to detect zero-day attacks. There are three popular ensemble methods: Bootstrap aggregating, boosting, and stacking. Bootstrap aggregating, known as bagging, employs the simplest way of combining predictions that belong to the same class. For example, if we had four bagged decision trees that made the following class predictions for an input sample: Malware, normal, malware and malware, we would take the most frequent class and predict malware. Boosting steadily creates an ensemble via preparing each new model, utilizing the misclassified training instance that past models misclassified. An example of boosting is the AdaBoost algorithm, which uses a boosting technique. Stacking, also known as stacked generalization, is a technique that combines the other models’ predictions.
In stacking, predictions of base learners (stage one) are used as input for the meta-learner (stage two). Stacking is a parallel integration of classifiers in which all the classifiers are implemen-ed parallel to eatchother and learning takes place at the meta-level. In this paper, two models, namely C5 and OCSVM, are built and then the predictions of the primary models are combined, as shown in
Figure 5.
The focus is on how to enhance IDS accuracy by employing the stacking approach. Meanwhile, the current conventional data mining approaches focus on how to enhance the performance of a single model. Our work focuses on how different classifiers can be combined to improve the overall performance of IDS. It was also observed that this approach yields better accuracy in the area of intrusion detection, as illustrated in the following section.
4. Model Evaluation
The NSL-KDD and ADFA datasets are used to evaluate the proposed hybrid IDS. The experiments have been performed using C5 and LIBSVM, library for Support Vector Machines, implementation of the support vector machine with default parameters. Details of the datasets are presented below.
4.1. Datasets
4.1.1. ADFA Dataset
Creech and Hu [
29] built the ADFA Linux (ADFA-LD) cyber security benchmarks datasets for assessment of IDSs. Ubuntu Linux version 11.04 was used as the operating system to collect this dataset. Ubuntu Linux configuration offers several functions including the sharing of files, a database movement system, network settings, and a web server.
File transfer protocol, secure web server, secure shell protocol, and MySQL database are activated based on default ports. Personal Home Page (PHP) was used as a server scripting language and to make the Web pages dynamic and interactive. Apache was installed to enable web-based services. Apache acted as a middleman between the server and user computer.
The ADFA-LD is freely accessible on the Internet and can be found in Reference [
29].
Table 2 shows ADFA-LD features and their types.
The ADFA Windows Dataset (ADFA-WD) offers a modern Windows dataset for HIDS evaluation.
Table 3 presents various system calls in AFDA-LD and AFDA-WD.
Table 4 defines each attack in details in the ADFA-LD dataset.
4.1.2. NSL-KDD Dataset
The KDD 1999 data set has been examined by Tavallaee et al. [
30] and found a number of weaknesses. A few problems were noted, relating to synthesizing the network and attack data (after sampling the actual traffic) because of privacy issue, an unidentified packet loss caused by network traffic, and unclear attack definitions. Tavallaee et al. also completed statistical evaluations and revealed a high number of redundant records resulting in bias in the dataset. Hence, high bias can cause IDS to be inaccurate in terms of high false alarms. Therefore, machine learning techniques have restricted flexibility to learn the true behavior of normal and abnormal activities from the dataset. They proposed a new data set, NSL-KDD, which contains marked records of the overall KDD data set and does not encounter the previously mentioned inadequacies.
Table 5 shows the list of attacks presented in NSL-KDD dataset. This dataset has been widely used as a public dataset for the validation of IDS.
4.2. Evaluation Metrics
Table 6 shows the confusion matrix for a two-class classifier that would commonly be used in an IDS. Each column of the matrix represents the instances in a predicted class, while each row represents the instances in an actual class.
Usually, the evaluation of the IDS is assessed based on the Confusion matrix measurement as follows:
True Positive Rate (TPR): It measures the quantitative relation between the attacks and the overall attacks number.
TPR is 1 when all intrusions are correctly identified, and that is extremely rare for an IDS.
TPR is also called the Detection Rate (DR) and is defined as:
False Positive Rate (FPR): It measures the quantitative relation between the normal cases that are detected as attacks and the overall number of normal cases.
FPR is calculated as:
False Negative Rate (FNR): FNR shows that the intrusion detection system could not classify the intrusion and has classified it as normal. The
FNR is calculated as:
Classification rate (CR) or Accuracy: The
CR is the total accuracy of the IDS in classifying both normal and intrusion attacks and is calculated as:
Precision (P):
P is the percentage of total true positives (
TP) instances divided by total number of true positives (
TP) and false positives (
FP) instances:
Recall (R): Refers to the percentage of total relevant results correctly classified, true positives (
TP), divided by the total true positives and false negatives (
FN) instances:
F-measure (FM): The
FM is the mean of the precision and recall. F-Measure is favored when only one accuracy metric is needed as an evaluation measurement:
4.3. Experimental Results
The effectiveness of our proposed model is evaluated with other machine learning techniques that use the same datasets mentioned earlier.
In the first instance, for selected classification techniques, the dataset is divided into training and testing subsets for assessment purposes. For the NSL-KDD dataset, the process of training and testing the different stages is outlined in
Table 7.
With the ADFA dataset, we used the widely adopted 10-fold cross-validation scheme for training and testing purpose. In a 10-fold cross-validation, the dataset is split into 10 approximately equal sized non-overlapping subsets. Nine subsets are used for building the classifier in the training stage, while the remaining one subset is used to test the model. The test set is employed to estimate the IDS accuracy. This process is repeated 10 times, each time using a separate fold for testing. In this way, the whole dataset goes through the testing phase in turns, with each sample being tested once. The overall accuracy estimate is the mean of 10 rounds.
The proposed IDS accuracy has been evaluated for all stages; four statistics evaluation measurement have been computed: True positive rate, F-measure, false positive rate, and accuracy.
4.3.1. Stage One: SIDS Results
This experiment was conducted by using NSL-KDD Test+ dataset and ADFA dataset. To evaluate the performance of the proposed technique, the Confusion matrix was used. The Confusion matrix results for the C5 classifier in stage one is shown in
Table 8 for both NSL-KDD Test+ and ADFA.
The detailed accuracy for C5 classifier with the use of NSL-KDD Test+ is shown in
Table 9 and on ADFA dataset shown in
Table 10.
4.3.2. Stage Two: AIDs Results
One-class SVM with an RBF kernel was applied using LIBSVM. Confusion matrix results are shown in
Table 11 for both datasets: NSL-KDD Test+ and ADFA.
The detailed analyses of the accuracy of the One-Class SVM classifier on NSL-KDD Test+ and ADFA datasets are highlighted in
Table 12 and
Table 13, respectively. For AIDS, the detection accuracy is 72.17% with the use of NSL-KDD Test+ dataset and 76.4% for the ADFA dataset.
4.3.3. Stage Three: Combination of the Two Stages
The Confusion matrix of the mixture of both classifiers in Stage three is shown in
Table 14 for both NSL-KDD Test+ and ADFA.
The accuracy of Stage 3 with the use of NSL-KDD Test+ and ADFA datasets is shown in
Table 15 and
Table 16, respectively.
As revealed in
Figure 6, the detection accuracy of the intrusion is 81.5% with the use of NSL-KDD Test+ dataset and 97.3% for the ADFA dataset at Stage one. Meanwhile, the detection accuracy of the intrusion is 72.2% with NSL-KDD Test+ dataset and 76.4% for ADFA dataset at Stage two. At Stage 3, the accuracy rates are improved to 83.2% and 97.4%, respectively, for the both datasets. Results show that our suggested framework yields a superior detection rate and a lower false alarm rate, as compared with the single stage method.
To further analyze performance, our approach is compared with different approaches reported in the literature in terms of the overall accuracy.
Table 17 shows this comparison for the NSL-KDD dataset. Results show that our proposed model, which combines two stages, outperforms other approaches.
According to the results shown in
Figure 6, the accuracy obtained by our proposed algorithm on the KDDTest+ and ADFA datasets are supreme, as compared to the accuracy obtained by different classifiers to obtain the accuracy.
Table 18 shows the accuracy rates for different machine learning techniques, specifically C4.5, Naïve Bayes, Random Forest, multi-layer perception, SVM, CART, and KNN on the NSL-KDD dataset. The results show that our proposed technique, which combined the two stages, achieved the best performance, reaching an accuracy of 83.24%.
5. Conclusions
To create attacks in high volume, cybercriminals began using new techniques, like polymorphism, to change the signature each time and to generate new attacks. Efficient IDSs should be able to detect known and zero-day attacks reliably. In this paper, a novel framework is developed to build an intelligent IDS that overcomes the weaknesses of current IDSs, which means including detection methods for both known and unknown threats. The main contribution of our framework is the integration of the signature and anomaly intrusion detection systems, which takes advantage of the respective strengths of SIDS and AIDS. In the proposed IDS, signature-based IDS is applied to identify previously known intrusions, while an anomaly-based IDS is applied to detect unknown zero-day intrusions. We have effectively created signatures from anomaly IDSs to identify different intrusions to add in signature databases. Additionally, the advantage of the proposed IDS is not only the higher detection rate, but also the enhanced scalability, such as when new intrusions are stored to the signature intrusion database. We used the C5 classifiers to create an intrusion signature, which is capable of generating a rule pattern more rapidly and can detect the intrusions with fewer numbers of signatures. We have shown that an ensemble of the C5 classifier (signature) and one-class SVM (anomaly) can result in a better detection rate when compared with other machine learning techniques in terms of the detection rate, false alarms, true negative, false positive, false negative, recall, precision, specificity, sensitivity, and F-Measure. Compared to the single algorithms, combining multiple algorithms has given much better results. Our Hybrid IDS has shown superior results, as compared to existing techniques. Our future research will be focused on the way in which to apply this technique in order to improve the accuracy of IDSs in detecting different attacks.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}