1. Introduction
Optimal long-term hydropower scheduling (LTHS) essentially aims at finding a production target for each individual power plant in each time stage of the planning period, so that the optimal objective is reached and all relevant physical and legislative constraints are met. The objective is typically to minimize system costs in system studies or to maximize profit for a single hydropower producer. Computing accurate production targets is of crucial importance in LTHS decision support tools, e.g., used for price forecasting, detailed operational planning and expansion planning.
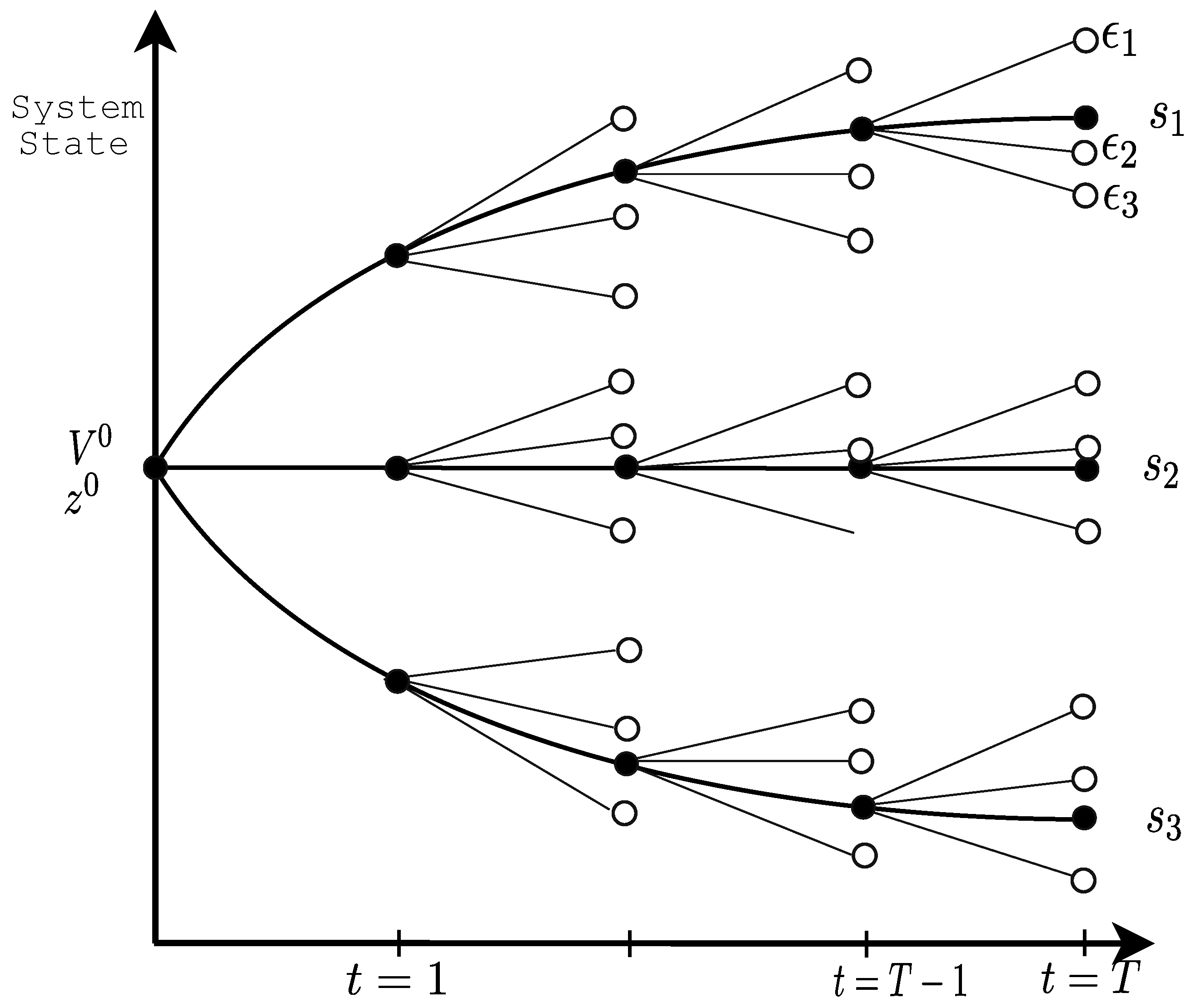
The LTHS problem can be formulated as an optimization problem with three characteristic properties. Firstly, it is dynamic in time due to the ability to store water in hydro reservoirs. That is, there is a link between reservoir discharge decisions taken in a given time stage and the future cost of operating the system. Secondly, the problem is stochastic, since important variables, such as future inflow to reservoirs, wind power production, demand, etc., are not precisely known for the future. Finally, hydro systems normally comprise multiple reservoirs possibly allocated in multiple water courses. The scheduling period needs to be long enough to reflect the storage capability of the reservoirs and the time resolution fine enough to capture the basic hydro system constraints. Consequently, the problem can often be characterized as large scale in terms of the number of state variables (reservoirs), stochastic variables and time stages.
Numerous solution strategies have been applied to the LTHS problem; see e.g., [
1] for a thorough review on solution methods for the optimal operation of multi-reservoir systems. Stochastic dynamic programming (SDP) has proven to be well suited for systems with relatively few reservoirs, but will suffer from the curse of dimensionality when considering realistic multi-reservoir systems. In spite of this shortcoming, models based on SDP are widely used by power market participants, e.g., in the Nordic power market. Such operative models have been documented by several authors; see, e.g., [
2,
3]. These models are based on some kind of reservoir aggregation and depend on heuristics to address the multi-reservoir aspect in a realistic manner.
In order to avoid the dimensionality problem of the SDP algorithm, an approach known as stochastic dual dynamic programming (SDDP) was presented in [
4]. Currently, SDDP seems to be the state-of-the-art method for solving the LTHS problem in regions where hydropower is the dominant technology for producing electric power; see e.g., [
5,
6]. Unlike the case with SDP, there is no need to fully discretize the state space with the SDDP algorithm. SDDP is a sampling-based variant of multi-stage Benders decomposition, where an outer approximation of a convex future cost function is constructed iteratively for each time stage by adding Benders cuts. Thus, the overall optimization problem is decomposed into small linear programming (LP) problems that can be solved independently. The problem decomposition makes the SDDP algorithm well suited for parallel processing. However, the algorithm is not embarrassingly parallel due to the intuitive stage-wise synchronization of parallel workers.
A recent study in [
7] presented several successful strategies for efficiently running the SDDP algorithm applied to the LTHS problem in parallel. In particular, strategies for dynamic load balancing, asynchronous grouping of Benders cuts, reduced amount of communication and customization of the communication topology to multi-core-based processors were presented. In this work, we go a step further in the search for an efficient large-scale parallelization of the SDDP algorithm. To the knowledge of the authors, parallel implementations of the SDDP algorithm applied to the LTHS problem have (at least) synchronization points between stages in both the forward and backward iterations. In this work, the presence of the stage-wise synchronization points in the backward iteration is challenged by partially relaxing it.
This paper is outlined as follows. First, a basic mathematical description of the LTHS problem and the SDDP algorithm is provided in
Section 2. Subsequently, the proposed parallel processing scheme is outlined in
Section 3. This scheme is tested in a case study in
Section 4, before the conclusions are drawn in
Section 5.
3. Parallel Processing
In the following, the parallel SDDP scheme used in this work is elaborated. We use a master process to designate the decomposed LP problems to a set of slave processes. In the SDDP scheme outlined in the previous section, the forward iteration is performed along
forward samples. For each time stage in the backward iteration, the
backward realizations are considered for each of the
states obtained from the previous forward iteration. Thus, it is clear that the backward iteration is more computationally demanding, as it needs to solve
as many LP problems as in the forward iteration. In other parallel implementations of SDDP applied to the LTHS problem, there seems to be (at least) two types of synchronization points; between stages in both the forward and backward iterations; see e.g., [
7,
12]. In this work, the presence of the synchronization points between stages in the backward iteration is challenged.
3.1. Forward Iteration
The forward iteration has to be completed before the backward cycle starts, so we get a synchronization point in between the two cycles. Furthermore, for each stage in the forward iteration along a sampled inflow scenario s, the LP problem corresponding to that stage is solved, and the resulting state variables (reservoir levels) are passed on to the next time stage to be evaluated along sample s. All of the LP problems formulated in each stage can be solved in parallel. However, due to the time-sequential coupling along scenario samples in the forward iteration, one cannot expect speedup in the forward iteration if the number of slave processors is greater than the number of forward scenarios .
3.2. Backward Iteration
For each evaluated state in a stage
t in the backward iteration, a Benders cut is created for stage
by averaging contributions from the LP problems solved corresponding to the
realizations of inflow. Each new inflow realization will in practice introduce a modest change in the right-hand side of the LP problem. Thus, the LP problem can normally be solved within a relatively low number of simplex iterations, provided that the previous solution basis is available. In this work, the advantage of warm starting LP problems in the backward iteration was appreciated by letting a designated processor solve all
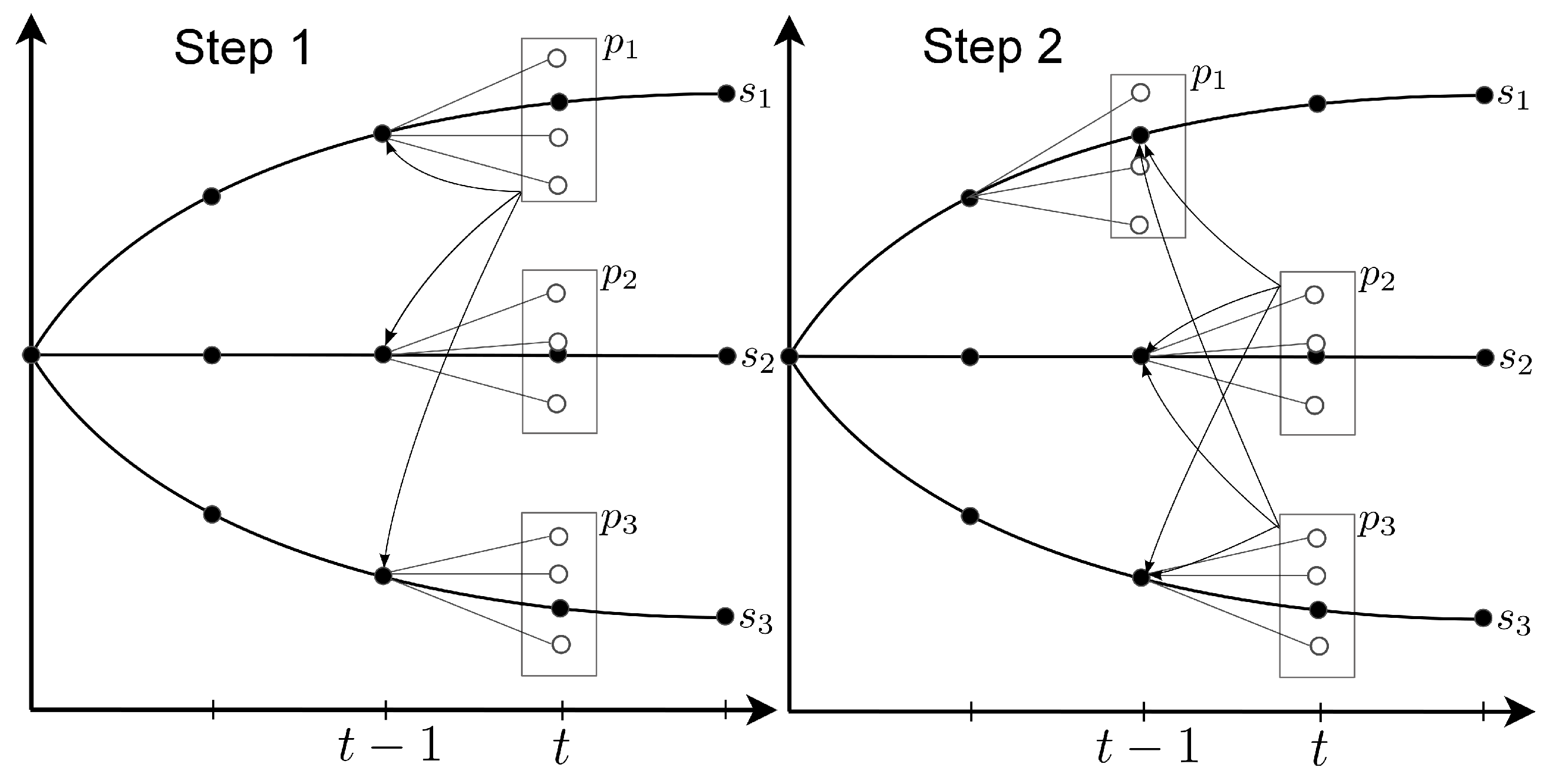
problems originating from a given initial state. This is illustrated in Step 1 in
Figure 2 with processors
. Allowing the
realizations from a given state to be divided between different processors could add flexibility to the parallel processing scheme, but one would lose some of the warm start advantage. We have focused on limiting the communication between processors, and thus, the communication of the warm start basis was not considered.
Figure 2.
Parallel processing scheme used in the backward iteration. Each of the processors solves linear programming (LP) problems and sends one cut to all states at stage , as indicated by black arrows.
Figure 2.
Parallel processing scheme used in the backward iteration. Each of the processors solves linear programming (LP) problems and sends one cut to all states at stage , as indicated by black arrows.
The linear inflow model presented in
Section 2 allows cuts to be shared among different states. This is illustrated in Step 1 in
Figure 2, where the cut created for the state obtained following sample
in stage
is shared with the other states in that stage. Although convenient from an implementation point of view, it is not mathematically necessary to wait for all processors to create a cut for stage
before continuing backwards in time to construct cuts for stage
; see [
13] for a formal treatment of SDDP convergence properties. Each additional cut considered for stage
t gives a better approximation to the future expected cost function
. However, waiting for all cuts to be created forces all processors to be synchronized at each stage in the backward iteration. In the presented work, these stage-wise synchronization points in the backward iteration are relaxed, allowing each processor to wait for
cuts, where
. Let
in
Figure 2 and assume that processor
computes its cut before
and
have finished. After communicating its cut to the master process, process
is then flagged as available and will be assigned a new state at stage
by the master process, as shown in Step 2 in
Figure 2. By setting
, we fully relax the stage-wise synchronization points, and no processor is unused at any time during the backward phase. The cost of not waiting for all cuts may be slower convergence, as more iterations may be needed to converge.
4. Case Study
The SDDP model with the proposed parallel processing scheme was implemented in C++, using the dual simplex algorithm from the COIN-OR linear programming solver library for solving LP problems and the MPI protocol for message passing through the OpenMPI library. All simulations were carried out on a Linux cluster comprising 93 compute nodes, each with 2 × 6 core AMD processors at 2.4 GHz. The cluster operating system is CentOS 5.4.
The hydro system model used in this case study is based on a representation of the water course Nea-Nidelva in Norway comprising 12 hydro power plants with upstream reservoir capacity and with a total installed capacity of 536 MW. The reservoir sizes vary, ranging from annual to weekly storage. We estimated the stochastic inflow model from a historical inflow series for the area comprising 50 years of data, as shown in
Figure 3. Inflows to individual reservoirs were scaled according to individual targets for expected annual inflow.
Normally, in a liberalized power market, a regional water course would be scheduled using exogenously-given stochastic price data, e.g., as described in [
14]. However, to simplify the mathematical model, we considered it as an isolated system being scheduled together with thermal power production serving a time-varying load. Purchase of thermal power power was modeled by 70 steps, each characterized by a fixed capacity increment and a marginal cost, which is stepwise increasing. The system was created and tuned to obtain reasonable power prices and reservoir trajectories.
Figure 3.
Historical inflow data used for fitting the stochastic inflow model. Values are in fractions of the maximum inflow value.
Figure 3.
Historical inflow data used for fitting the stochastic inflow model. Values are in fractions of the maximum inflow value.
The system was simulated for 156 weeks, using a weekly stochastic time resolution and with seven sub-periods within each week. The decomposed LP problems have on average 777 variables and 98 constraints (excluding cuts). We tested the proposed parallelization scheme using two different combinations of forward samples
and backward realizations
, as shown in
Table 1. These settings are similar to those being used in many operational models. For both cases, we experimented with different numbers of processors (
) and cuts to wait for in the backward iteration (
). To ensure that the forward iteration did not become a bottleneck for parallel efficiency, the maximum number of slave processors was kept lower than or equal to the number of forward samples in both of the cases.
Table 1.
Test case characteristics.
Table 1.
Test case characteristics.
| Cases | | | Max No. Processors | Serial CPU Time |
|---|
| Case 1 | 71 | 12 | 72 | 1 h 10 min |
| Case 2 | 200 | 50 | 144 | 5 h 3 min |
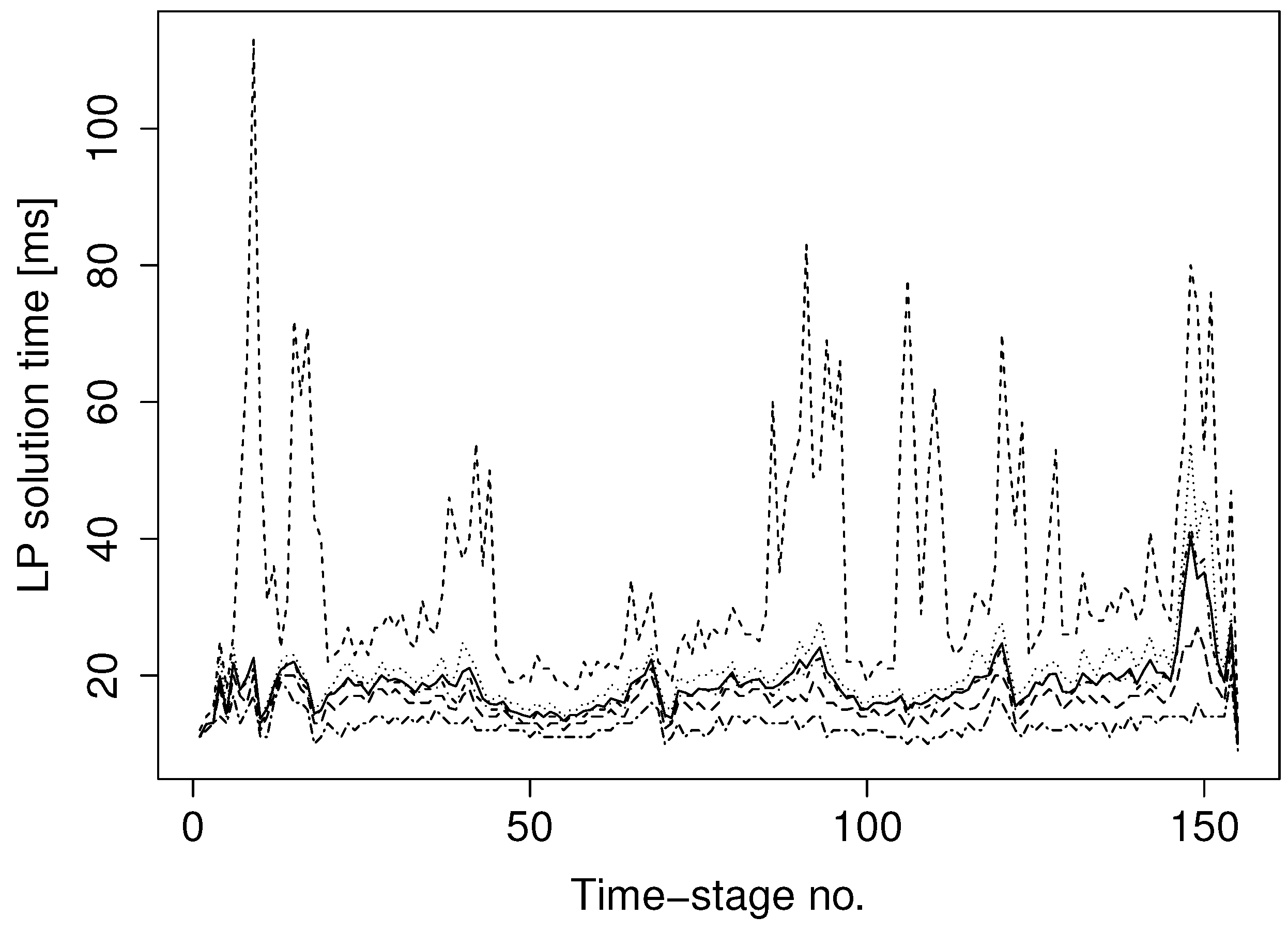
Relaxation of the stage-wise synchronization points in the backward iteration makes sense as long as LP solution times differ significantly between processors. We measured the time each processor spent solving all of its
backward realizations in each time stage for a given backward iteration in Case 1. The distribution of solution times among different processors per time stage is shown in
Figure 4. The figure displays the significant differences between the outliers (100 and zero percentiles) and the remaining measurements, represented by the 25, 50 and 75 percentiles. The large differences between the 100 and zero percentiles indicate that there is a potential for improving computational performance by relaxing the backward iteration stage wise synchronization points.
Figure 4.
LP solution times (in milliseconds) per time stage in the backward iteration. The curves represent the 0, 25, 50, 75 and 100 percentiles.
Figure 4.
LP solution times (in milliseconds) per time stage in the backward iteration. The curves represent the 0, 25, 50, 75 and 100 percentiles.
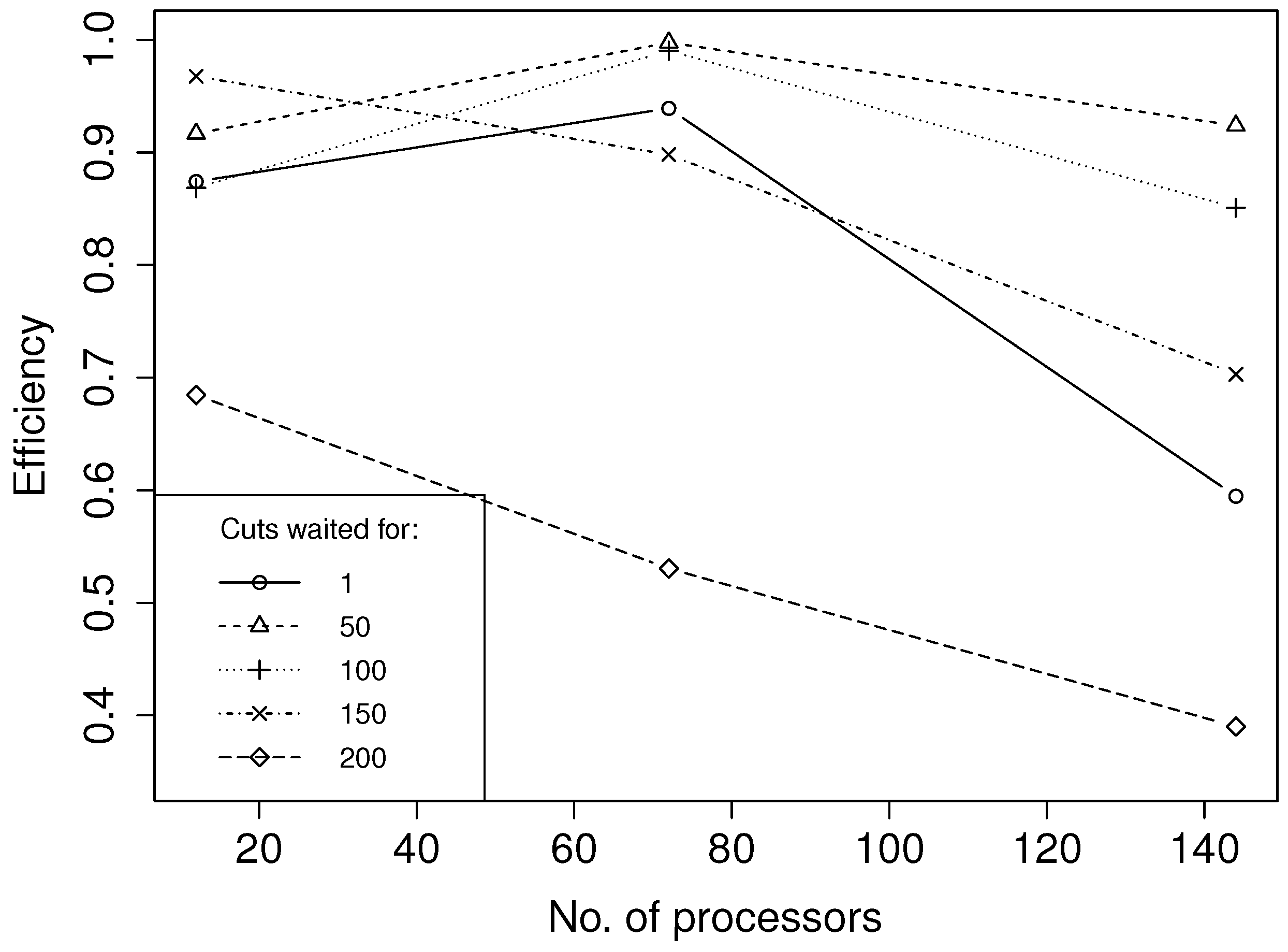
4.1. Parallel Efficiency
Generally, the gain achieved by applying parallel processing can be measured in terms of the efficiency of the parallel implementation when compared to the serial execution. Efficiency is defined as the ratio between the serial run-time on one core and the product of the parallel run-time on a number of cores divided by that number [
15].
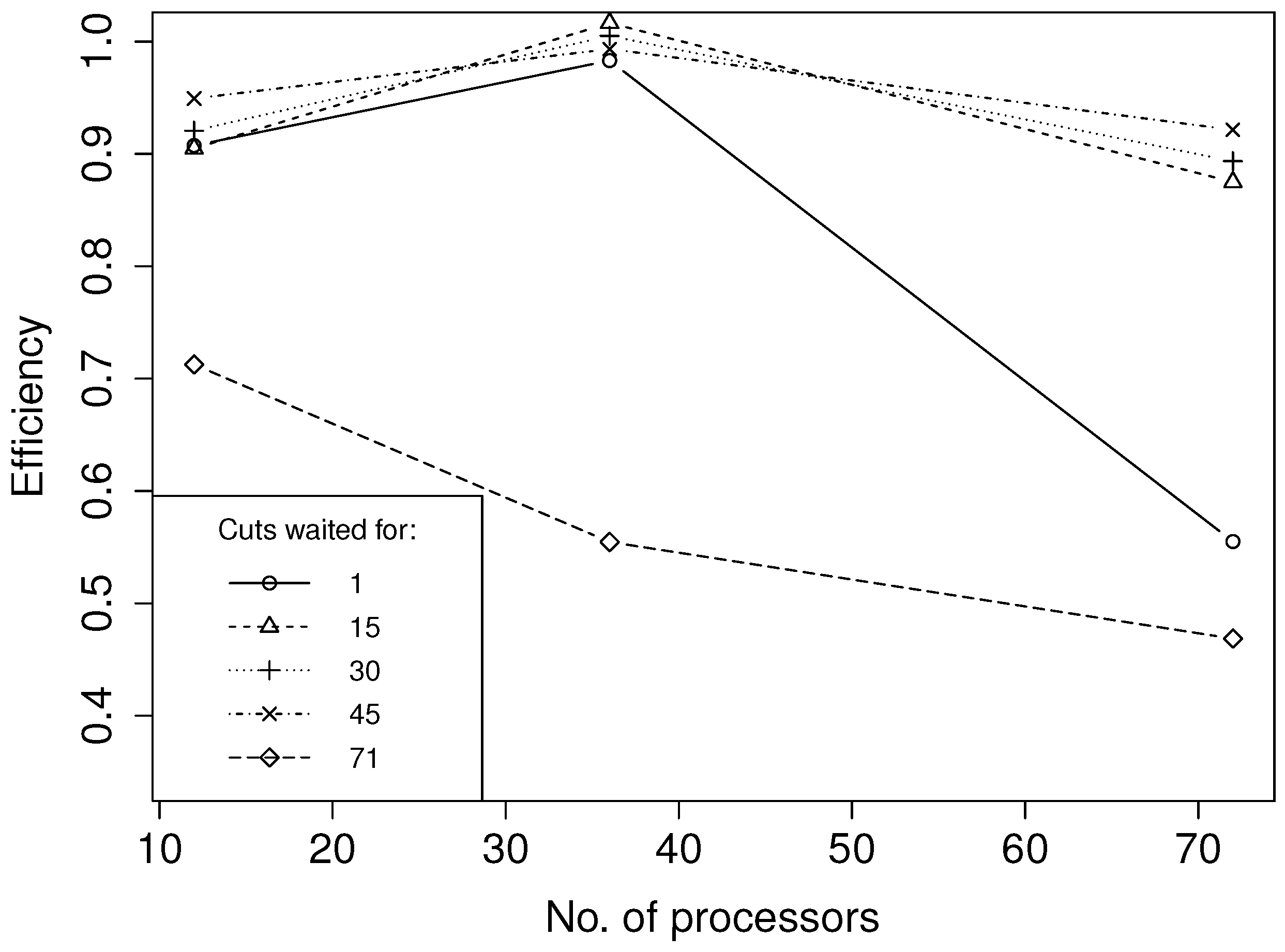
Each of the curves in
Figure 5 and
Figure 6 shows the parallel efficiency for different numbers of processors for a given value of
for Cases 1 and 2, respectively. Waiting for all cuts,
i.e.,
= 72 in Case 1 and
= 200 in Case 2, serves as the base cases. Thus, we can measure the computational improvement in synchronization point relaxation against the base cases by inspecting
Figure 5 and
Figure 6. All data points represent averages of 10 independent runs. Results from both cases indicate that optimal parallel efficiency is obtained when partially relaxing the backward iteration stage-wise synchronization points. By keeping the synchronization points, we experienced a decreasing parallel efficiency with increasing number of processors. When partially relaxing the synchronization points, the parallel efficiency is maintained at a higher level with an increasing number of processors. Note that the low parallel efficiency shown in both cases when running at a maximum number of processors and with
= 1 is due to the additional computation time caused by the slower convergence when only waiting for one cut.
Figure 5.
Parallel efficiency as a function of the number of processors for Case 1. Each line corresponds to a separate choice of .
Figure 5.
Parallel efficiency as a function of the number of processors for Case 1. Each line corresponds to a separate choice of .
Figure 6.
Parallel efficiency as a function of the number of processors for Case 2. Each line corresponds to a separate choice of .
Figure 6.
Parallel efficiency as a function of the number of processors for Case 2. Each line corresponds to a separate choice of .
4.2. Convergence
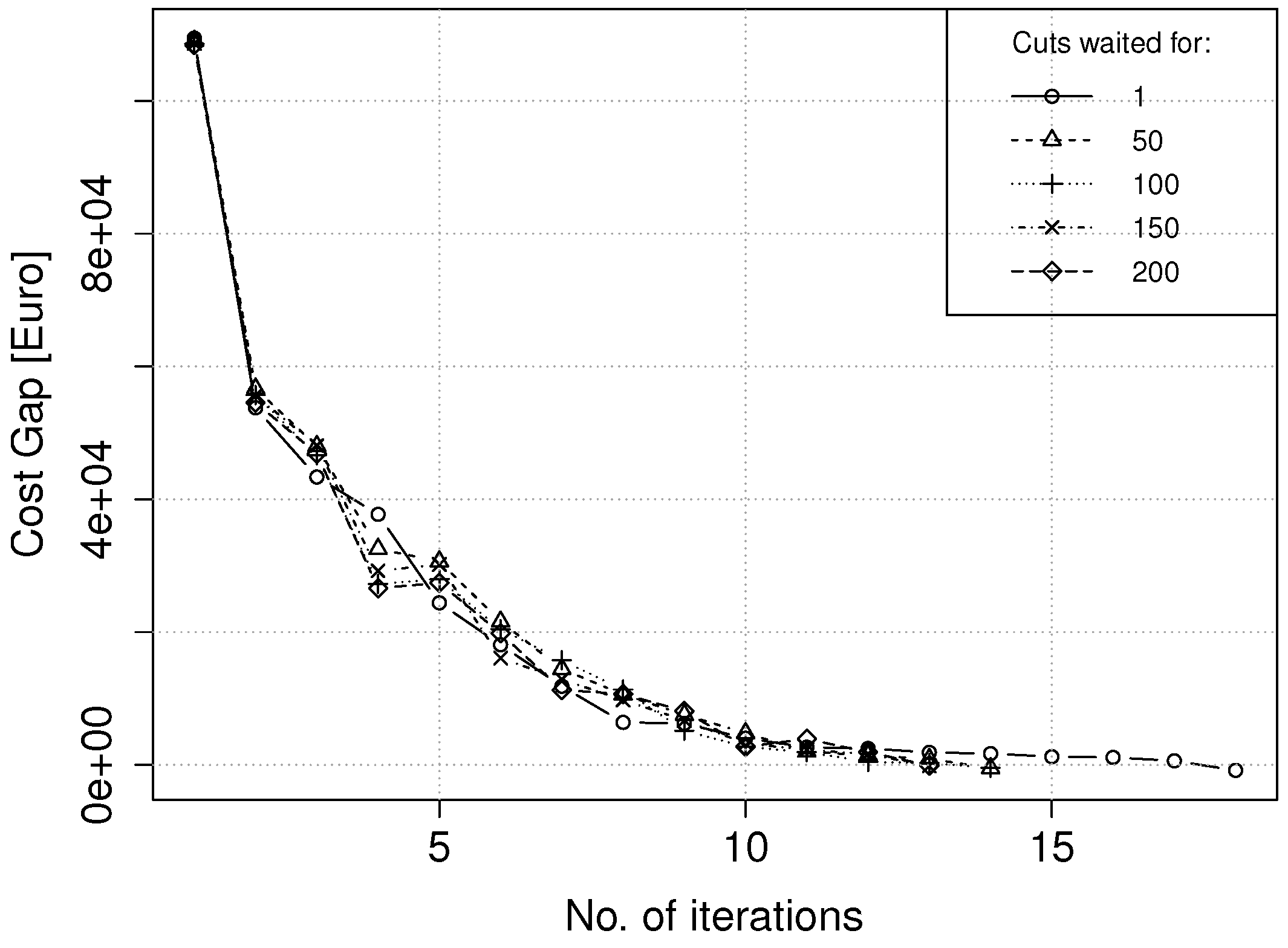
The increase in efficiency when relaxing the synchronization points implies that the convergence properties of the algorithm have not been dramatically changed. This implication is verified by looking at the cost gaps for Case 2 in
Figure 7. Generally, lower values of
result in higher numbers of iterations until the convergence criteria are met. This was as expected, since by decreasing
, each processor may have less cuts available at each stage and is therefore likely to have a less precise approximation of the future expected cost function. However, for the cases we have studied, the numbers of additional iterations needed when relaxing the synchronization points were modest.
Figure 7.
Cost gap as a function of the number of iterations in the SDDP algorithm. The data are from Case 2, with and with different values of .
Figure 7.
Cost gap as a function of the number of iterations in the SDDP algorithm. The data are from Case 2, with and with different values of .
5. Conclusions
A parallel processing scheme for the SDDP algorithm applied to the LTHS problem was presented. In contrast to traditional parallel schemes used with the SDDP algorithm, the stage-wise synchronization points in the backward iteration are relaxed. Thus, each processor does not need to wait for all processors to complete their jobs before starting a new job. Since the expected generator schedules should not be affected by the synchronization point relaxation, the sole benefit of introducing the relaxation can be measured in terms of improved computational performance.
A case study based on a Norwegian watercourse was established for the purpose of testing the parallel processing scheme. The test results show that the parallel efficiency significantly improves when partially relaxing the backward iteration synchronization points. In between synchronization and full relaxation, the optimal number of processors to wait for balances the trade-off between a precise approximation of the future expected cost function and processor waiting time. Results from two different test cases show that the optimal number of cuts to wait for is case dependent.
The case study reflect a simplified version of operational data, both in terms of system size and physical details being modeled. However, we believe that the presented case study results demonstrate a significant potential for improvement in the parallel efficiency of operational SDDP models.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



