1. Introduction
Wind turbine generator systems (WTGS) are the fastest-growing applications in renewable power industry. The structure of WTGS is complex, its reliability becomes an important issue. As wind power generators are widely mounted on high mountains or offshore islands, it is costly for routine maintenance [
1]. Continuously condition monitoring and fault diagnosis technologies are therefore necessary so as to reduce unnecessary maintenance cost and keep system working reliably without unexpected shutdown. A typical WTGS includes gearbox, power generator, control cabinet and rotary motor,
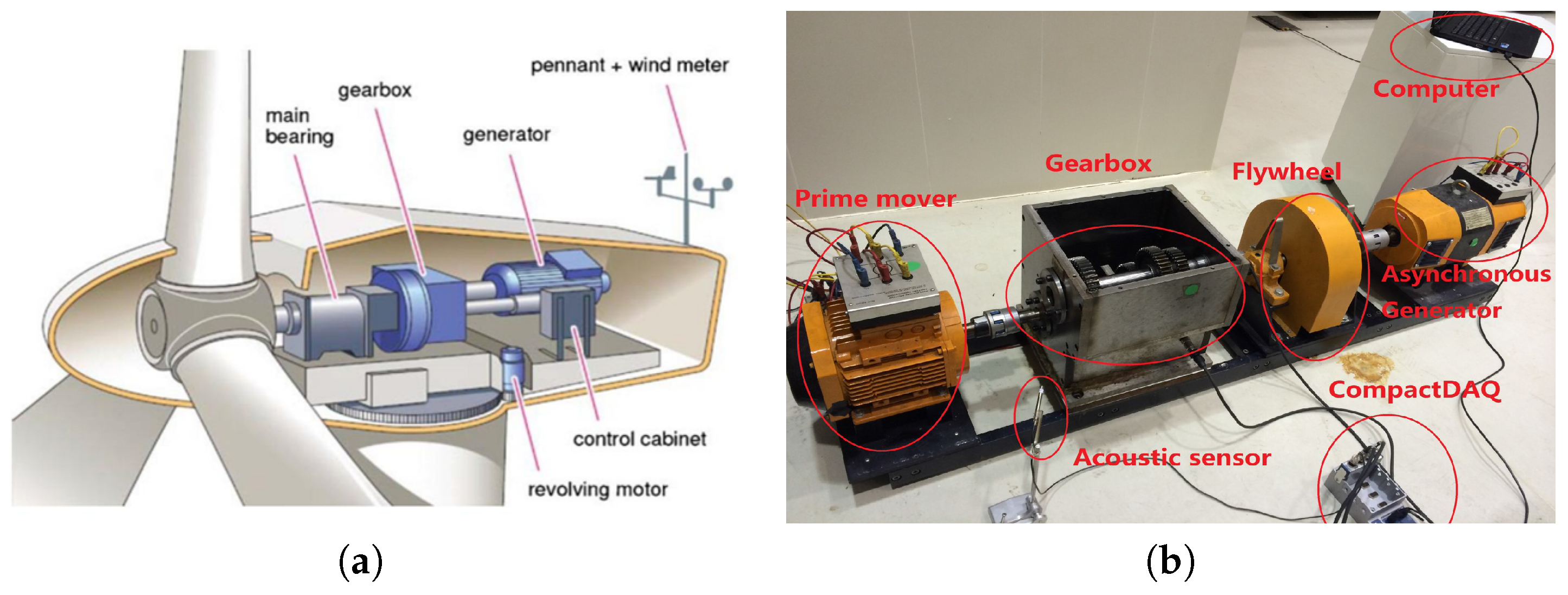
etc., (as shown in
Figure 1a), where the gearbox is statistically more vulnerable compared with other components. It shed light upon the importance of the condition monitoring of gearbox. More specifically, the faults of gearbox mainly results from two major components: gears and bearings, which include broken tooth, chipped tooth, wear-off of outer race or rolling elements of bearing,
etc. [
2]. Real-time monitoring and fault diagnosis aim to detect and identify any potential abnormalities and faults, so as to take corresponding actions to avoid serious component damage or system disaster.
Nowadays, a large body of research shows that fault detection based on a machine learning-based approach is feasible. Machine learning methods, such as neural networks (NNs), support vector machine (SVM) and deep learning (DL) may be promising solutions to classify the normal and abnormal patterns. A brief workflow of machine learning methods for fault diagnosis includes analog signal acquisition, data pre-processing and pattern recognition. Regarding the feature information sources (e.g., vibration signals, acoustic and temperature signals), the vibration signals are often adopted for their ease of acquisition and sensitivity to a wide range of faults. Moreover, intelligent fault diagnosis of WTGS relies on the effectiveness of signal processing and classification methods. The raw vibration signals contain high-dimensional information and abundant noise (includes irrelevant and redundant signals), which cannot be feasibly fed into the fault diagnostic system directly [
3]. Many studies focus on the improvement of data pre-processing and feature extraction from the raw vibration signals [
4,
5]. Generally, a good intermediate representation method is required to retain the information of its original input, while at the same time being consistent to a given form (
i.e., a real-valued vector of a given size in case of an autoencoder) [
6]. Therefore, it is essential to extract the compact feature information from raw vibration signals. The data processing method simplifies the computational expense and benefits the improvement of the generation performance. Some typical feature extraction methods, such as wavelet packet transform (WPT) [
7,
8,
9,
10], empirical mode decomposition (EMD) [
11], time-domain statistical features (TDSF) [
12,
13] and independent component analysis (ICA) [
14,
15,
16,
17] have been proved to be equivalent to a large-scale matrix factorization problem (
i.e., there may be still some irrelevant or redundant noise in the extracted features) [
18]. In order to resolve this problem, a feature selection method could be employed to wipe off irrelevant and redundant information so that the dimension of extracted feature is reduced. Typical feature selection approaches include compensation distance evaluation technique (CDET) [
19], principal component analysis (PCA) and kernel principal component analysis (KPCA) [
16,
20,
21] and the genetic algorithm (GA) based methods [
22,
23,
24]. However, these linear methods have a common shortcoming in an attempt to extract nonlinear characteristics, which may result in a weak performance in the downstream pattern recognition process.
The raw vibration signals obtained from WTGS are characterized with high dimensional and nonlinear patterns, which is difficult for direct classification. In order to extract the features from the raw vibration signals, this paper introduces the concept of autoencoder and explores its application. Unlike PCA and its variants, autoencoder does not impose the dictionary elements be orthogonal, which makes it flexible to be adapted to the fluctuation in data representation [
18]. In the structure of autoencoder, each layer in the stack architecture can be treated as an independent module [
25]. The procedure shows briefly as follows. Each layer is firstly trained to produce a new (hidden) representation of the observed patterns (input data). It optimizes a local supervised criterion based on its received input representation from forehead layer. Each layer
produces a new representation that is more abstract than the previous level
[
6]. After representational learning for a feature mapping that produces a high level intermediate representations (e.g., a high-dimensional intermediate matrix) of the input pattern, whereas, it is still complex and hard to compute directly. Therefore, it is necessary to decode the high-dimensional representations into a relatively low-dimensional and simple representations. Currently, there are only very limited algorithms that could work well for this purpose:
restricted
boltzmann
machines (RBMs) [
26,
27,
28] trained with contrastive divergence on one hand, and various types of autoencoders on the other. Regarding algorithms for classification, artificial neural networks (ANN) and multi-layer perception (MLP), are widely used for fault diagnosis of rotating machinery [
3,
29,
30]. However, MLP has inevitable drawbacks which mainly reflects in local minima, time-consuming and over-fitting. Additionally, most classifiers are designed for binary classification. Regarding multiclass classification, the common methods actually employ a combination of binary classifiers with one-
versus-all (1va) or one-
versus-one (1v1) strategies [
3]. Obviously, the combination with many binary classifiers increases computational burden and training time. Nowadays, researches show that SVM works well at recognizing the rotating equipment faults [
31,
32]. Compared with early machine learning methods, global optimum and relatively high generalization performance are the obvious advantages of SVM, while it has the same demerits with MLP, namely, time-consuming and local minimal. Considering that more than one type of fault may co-exist at the same time, it may be significant to propose a classifier which could offer the probabilities of all possible faults. In order to realize this assumption, the probabilistic neural network (PNN) [
33,
34] is employed as a probabilistic classifier. It is testified that the performance of PNN is superior to the SVM based method [
29]. It trained a probabilistic classifier with a model using the Bayesian framework. However, the work [
29] failed to explain clearly the principle of decision threshold. The value of decision threshold depends on some specific validation datasets and is not generally applicable for other areas.
Recent studies show that extreme learning machines (ELM) has better scalability and achieves much faster learning speed than SVM [
35,
36]. From the structural point of view, ELM is a multi-input and multi-output or single-output structure with
single-hidden
layer
feedforward
networks (SLFNs). Thus, ELM algorithm is more appropriate to multiclass classification. This paper extends the capability of ELM to the scope of feature learning, and proposes a multi-layered ELM network for feature learning and fault diagnosis. This paper proposes an ELM based autoencoder for feature mapping, and then the new representations are fed into the ELM based classifier for multi-label recognition. The proposed multi-layered ELM network consists of an ELM based autoencoder, dimension transformation, and supervised feature recognition. The autoencoder and dimension transform reconstruct the raw data into three types of representation (
i.e., compressed, equal and sparse dimension). The original ELM classifier is applied for the final decision making.
The paper is organized as follows.
Section 2 presents the structure of the proposed fault diagnostic framework and the involved algorithms. Experimental rig setup and signals sample data acquisition with a simulated WTGS are implemented in
Section 3.
Section 4 discusses the experimental results of the framework and its comparisons with other methods including SVM and ML-ELM.
Section 5 concludes the study.
2. The Proposed Fault Diagnostic Framework
As shown in
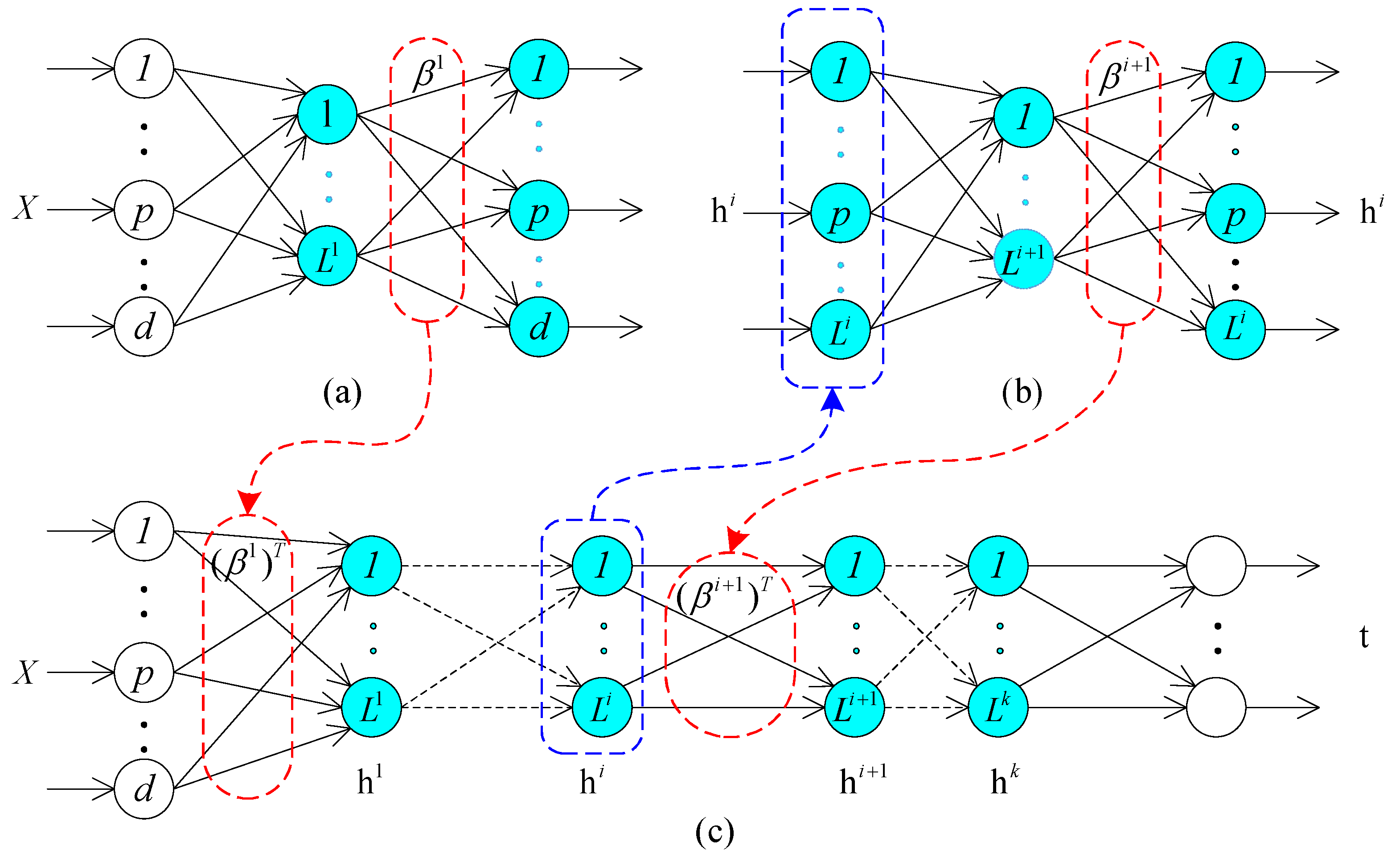
Figure 2, the proposed fault diagnosis framework is divided into three submodules: (a) ELM based autoencoder for feature extraction; (b) Matrix compression for dimension reduction; and (c) ELM based classifier for fault classification. The ELM based autoencoder enables three scales of data transformations and representations. Firstly, the raw dataset, which is usually in the form of a high-dimensional matrix, is fed into autoencoder. The autocoder network could be trained using multi-layered ELM networks, each of which is set with a different number of hidden layer nodes
L. The dimension of the output layer is set to equal with the input dataset. The output weight vector
is calculated in the ELM output mapping. Secondly, the dimensional transformation compresses the output of autoencoder with a simple matrix transform. The raw dataset is thus converted into a low-dimensioned feature matrix, which is described in detail in
Section 2.2. In order to optimize the number of hidden-layer nodes
L, a method using multiple sets of contrast tests is introduced in
Section 3.2. Finally, one classic ELM classification slice is applied for the final decision making with the input of the converted feature matrix. It is notable that the number of hidden-layer nodes is the only adjustable parameter in the proposed method. The two weighting vectors
and
are independent in two ELM networks (ELM-based autoencoder and ELM classifier). The former one is applied for regression, while the later is used for classification.
2.1. Extreme Learning Machines Based Autoencoder
ELM is a recently prevailing machine learning method that has been successfully adopted for various applications [
37,
38]. ELM is characterized with its single hidden layer structure, of which the parameters are initialized randomly. The parameters of the hidden layer are independent upon the target function and the training dataset [
39,
40]. The output weights which link the hidden layer to output layer are determined analytically through a Moore-Penrose generalized inverse [
37,
41]. Benefited from its simple structure and efficient learning algorithm, ELM owns very good generalization capability superior to the traditional ANN and SVM. The basics of ELM is summarized as follows:
where
is the output weight vector between the hidden nodes and the output nodes.
is the hidden nodes output for the input
and
is the
i-th hidden node activation function.
Given the
N training samples
, the ELM is to resolve the follow problems:
where
is the target labels, the matrix
is the hidden nodes output.
The output weight vector
can be calculated by Equation (
3),
where
is the Moore-Penrose generalized inverse of matrix
.
In order to obtain better generalization performance and to make the solution more robust, a positive constraint parameter
is added to the diagonal of
in the calculation of the output weight, as shown in Equation (
4).
To perform autoencoding and feature representation, the ELM algorithm is modified as follows: the target matrix is set equally to the input data, namely,
. The random assigned input weights and biases of the hidden nodes are chosen to be orthogonal. Widrow [
42] introduced a Least Mean Square (LMS) method implementation for ELM and a corresponding ELM based autoencoder in which non-orthogonal random hidden parameters (
i.e., weights and biases) are used. However, orthogonalization of randomly generated hidden parameters tends to improve the generalization performance of ELM autoencoder. Generally, the objective of ELM based autoencoder is to represent the input features meaningfully in the following three optional representations:
- (1)
Compressed representation: represent features from a high dimensional input data space to a low dimensional feature space;
- (2)
Sparse representation: represent features from a low dimensional input data space to a high dimensional feature space;
- (3)
Equal representation: represent features from an input data space dimension equal to feature space dimension.
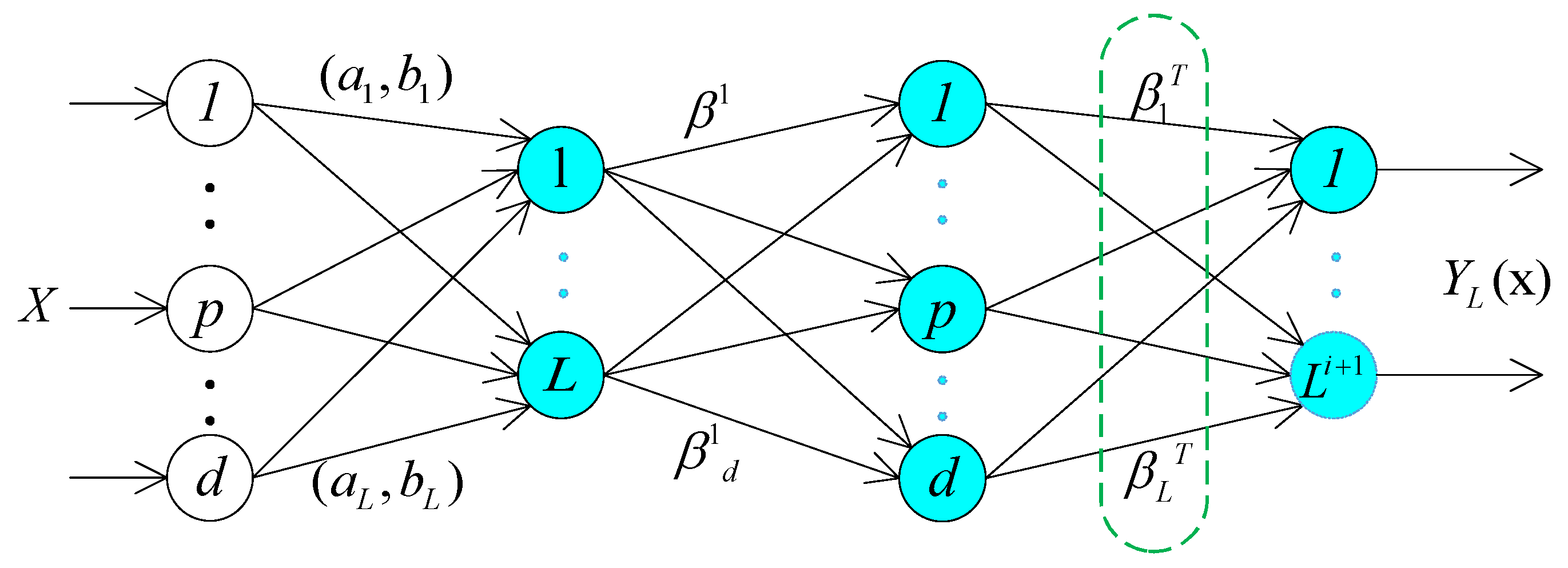
Figure 3 shows the structure of random feature mapping. In an ELM based autoencoder, the orthogonal random weight matrix and biases of the hidden nodes project the input data to a different or equal dimensional space as shown by Johnson-Lindenstrauss Lemma and calculated by Equation (
5):
where
are the orthogonal weight vector and
is the orthogonal random bias vector between the input layer and hidden layer.
The output weight
of ELM based autoencoder is applied for learning the transformation from input dataset to the feature space. For sparse and compressed representation, output weight
is calculated by Equation (
6),
where the vector
is the input data and output data, the input data equals to the output in proposed autoencoder.
For equal dimension representations, the output weight
is calculated by Equation (
7),
2.2. Dimension Compression
This paper adopts the regression method to train the parameters of the autoencoder. However, the above transform is not enough for the data preprocessing, because the dimension of input data does not decrease (see Equation (
2) and let
). The output data with equal dimension of input data cannot reduce the complexity of the post classifier. After all the parameters of autoencoder are identified, this paper applies a transform to represent the input data. The eventual representation vector shows in Equation (
8),
where
is the final output of autoencoder. The dimension of
is shown as Equation (
9). The subscripts
N and
L represent the number of input samples and hidden layer nodes, respectively.
From the Equations (
8) and (
9), the procedure from the high-dimensional vector to the low-dimensional vector can be explained that each element in sample data
has relationship with
, in other words,
can be seen as a weight distribution of
. The procedure from
to
is an unsupervised learning as the parameters have been identified in the first part as shown in
Figure 2.
Unlike the concept of DL-based autoencoder, the proposed ELM-based autoencoder shows differences at the following four aspects:
- (1)
The proposed autoencoder is a ELM based network composing of a set of single-hidden-layer slice, whereas the DL-based autoencoder is a multiple hidden layers network.
- (2)
DL tends to adopt BP algorithm to train all parameters of autoencoder, differently, this paper employs the ELM to configure the network with supervised learning (
i.e., Let the output data equal to input data,
). We can get the final output weight
so as to transform input data into a new representation through Equation (
8). The dimension of converted data is much smaller than the raw input data.
- (3)
The DL-based autoencoder tends to map the input dataset into high-dimensional sparse features. While this research applies a compressed representation of the input data.
- (4)
The DL-based autoencoder trained with BP algorithm is a really time-consuming process as it requires intensive parameters setting and iterative tuning. On the contrary, each ELM slice in the multi-layered ELM based autocoder can be seen as an independent feature extractor, which relies only on the feature output of its previous hidden layer. The weights or parameters of the current hidden layer could be assigned randomly.
2.3. ELM for Classification
Regarding the binary classification problems, the decision function of ELM is:
Unlike other learning algorithms, ELM tends to reach not only the smallest training error but also the smallest norm of output weights. Bartlett’s theory [
7,
43] mentioned that if a neural network is used for a pattern recognition problem, the smaller size of weights brings a smaller square error during the training process, and then realizes a better generalization performance, which doesn’t relate directly to the number of nodes. In order to reach smaller training error, the smaller the norms of weights tend to have a better generalization performance. For a
m-label classification case, ELM aims to minimize the training error as well as the norm of the output weights. The problem can be summarized as:
where
is the vector of the output weight between the hidden layer of
l-nodes and the output nodes.
where
is the output vector of the hidden layer which maps the data from the
d-dimensional input space to the
l-dimensional hidden-layer space
,
is the training data target matrix.
In the binary classification case, ELM has just a single output node. The optimal output value is chosen as the predicted output label. However, for a multiclass identification problem, this binary classification method could not be applied directly. There are two conditions for multilabel classification:
- (1)
If the ELM only has a single-output node, among the multiclass labels, ELM selects the most closed value as the target label. In this case, the ELM solution to the binary classification case becomes a specific case of multiclass solution.
- (2)
If the ELM has multi-output nodes, the index of the output node with the highest output value is considered as the label of the input data.
According to the conclusion of study [
35], the single-output node classification can be considered a specific case of multi-output nodes classification when the number of output nodes is set to 1. This paper discuss only the multi-output case.
If the original number of class labels is
P, the expected output vector of the
M-output nodes is
. In this case, only the
P-th elements of
is set to 1, while the rest is set to 0. The classification problem (see Equation (
11)) for ELM with multi-output nodes can be formulated as Equation (
14),
where
is the training error vector of the
M-output nodes with respect to the training sample
.
Based on the
Karush-
Kuhn-
Tucker (KKT) theorem, to train ELM is equivalent to solve the following dual optimization problem:
We can have the KKT corresponding optimality conditions as follows:
where
. In this case, by substituting Equations (
16) and (
17) into Equation (
18), the aforementioned equations can be equivalently written as:
From Equations (
16)–(
19), we have:
The output function of ELM classifier shows:
For multiclass cases, the predicted class label of a given testing sample is the index number of the output node which has the highest output value for the given testing sample. Let
denoted the output function of the
j-th output node (
i.e.,
), and then the predicted class label of sample
is:
In short, there are very few parameters required to set in ELM algorithm. If the feature mapping is already known, only one parameter C needs to be specified. The generalization performance of ELM is not sensitive to the dimensionality l of the feature space (i.e., the number of hidden nodes) as long as l is not set to be too small. Different from SVM which usually requests to specify two parameters (C,), single-parameter setting makes ELM easy and efficient in the computation for feature representation.
2.4. General Workflow
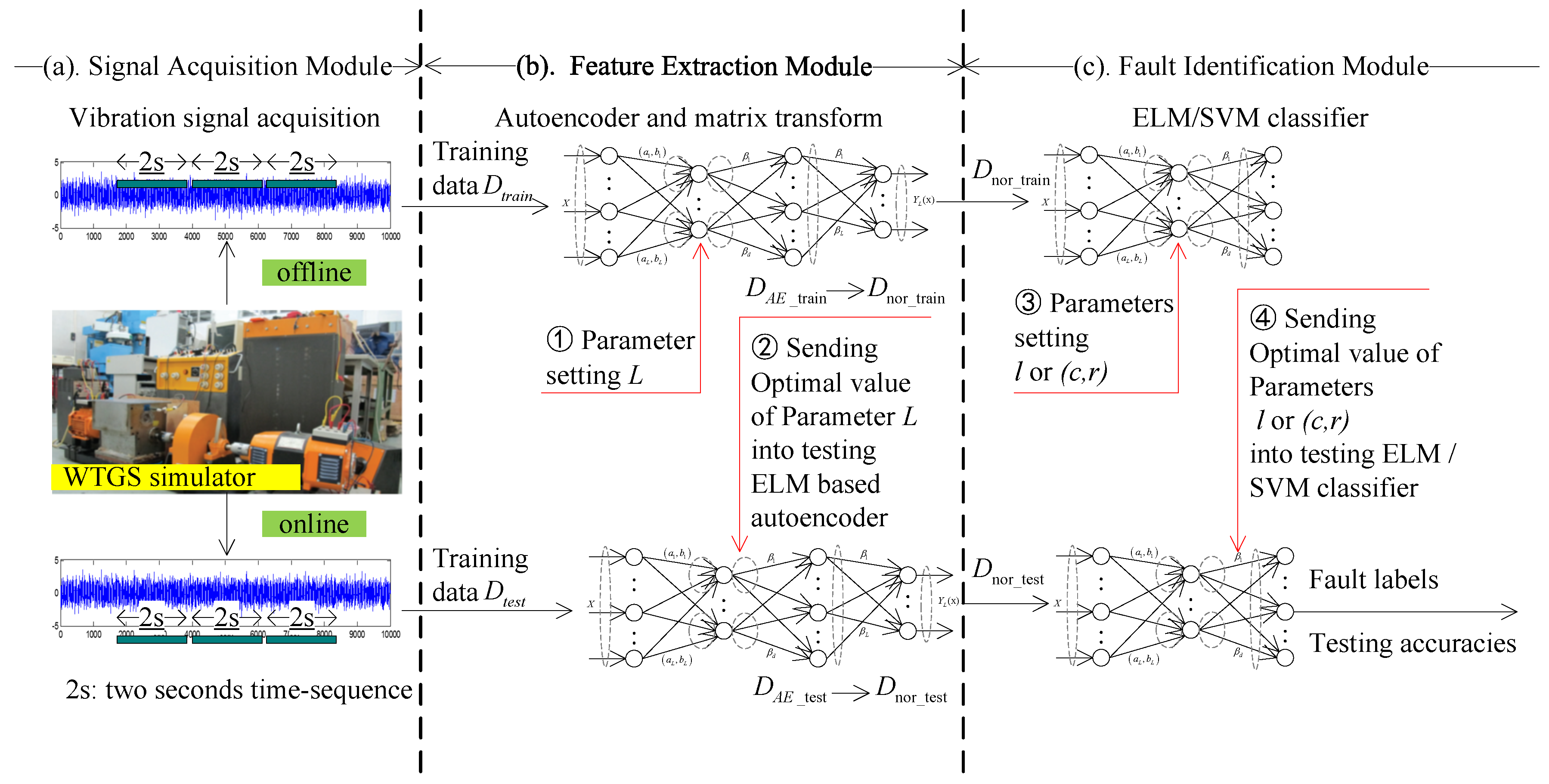
Table 1 summarizes the ELM training algorithm. The flowchart of the proposed fault diagnostic system for WTGS shows in
Figure 4. It consists of three components, namely, (a) signal acquisition module; (b) feature extraction module; (c) fault identification module. For the signal acquisition module, the real-time dataset
acquisition model uses accelerometers to record the vibration signals of the WTGS. Two tri-axial accelerometers are mounted on the outboard of the gearbox along with the shaft transmission, in order to acquire the vibration signals along the horizontal and vertical directions respectively. The training dataset
and testing dataset
are recorded from experiment by accelerometers. In this paper, the real-time signal is processed by the data pre-processing approaches (
i.e.,
is converted into
), which is identified by the simultaneous fault diagnostic model. In feature extraction module, ELM based autoencoder is employed to generate the most important information (
and
) of the input dataset (
and
). In order to avoid domination of largest feature values,
and
are normalized into
and
which are within [0, 1]. After feature extraction and normalization, the datasets
and
are sent into classifier for fault recognition. Regarding the real application of this method, the proposed scheme can be seen as a fault pattern indicator in the whole wind forms protection system. First, the real-time vibration signals are collected by accelerators installed on transmission case, and then the vibrations signals are converted into voltage signals and sent into sampling unit. The sampling unit modulates these signals and sends the processed signals into recognition unit. Compared with the proposed scheme, the functions of vibration signals acquisition unit and sampling unit equal to the module (a) in
Figure 4. Second, the pattern recognition unit extracts the input signals and classifies them into different labels, and then outputs single or multilabels to the decision making unit. The function of pattern recognition unit equals to the modules (b) and (c) in
Figure 4.
4. Experimental Results and Discussion
In order to verify the effectiveness of the proposed scheme, this paper applies various combinations of methods to realize the contrast experiments. Testing accuracy and testing time are introduced to evaluate the prediction performance of the classifier. As suggested in
Section 3, the ELM based autoencoder can convert the input data space into three types of output data space. In this paper, we choose the compressed dimensional representation and use the ELM learning method to train the parameters. The function of autoencoder is to get an optimal matrix
, and the function of matrix transform is to reduce the dimension of input
. Before the experiments, it is not clear how many dimensions it is appropriate to cut down. In other words, the model needs proper values of
L and
to improve the testing accuracies. In order to get a set of optimal parameters (
i.e., hidden layer nodes
L in autoencoder, hidden layer nodes
l in classifier),
(
includes dataset
and
) is applied to train the networks. As shown in
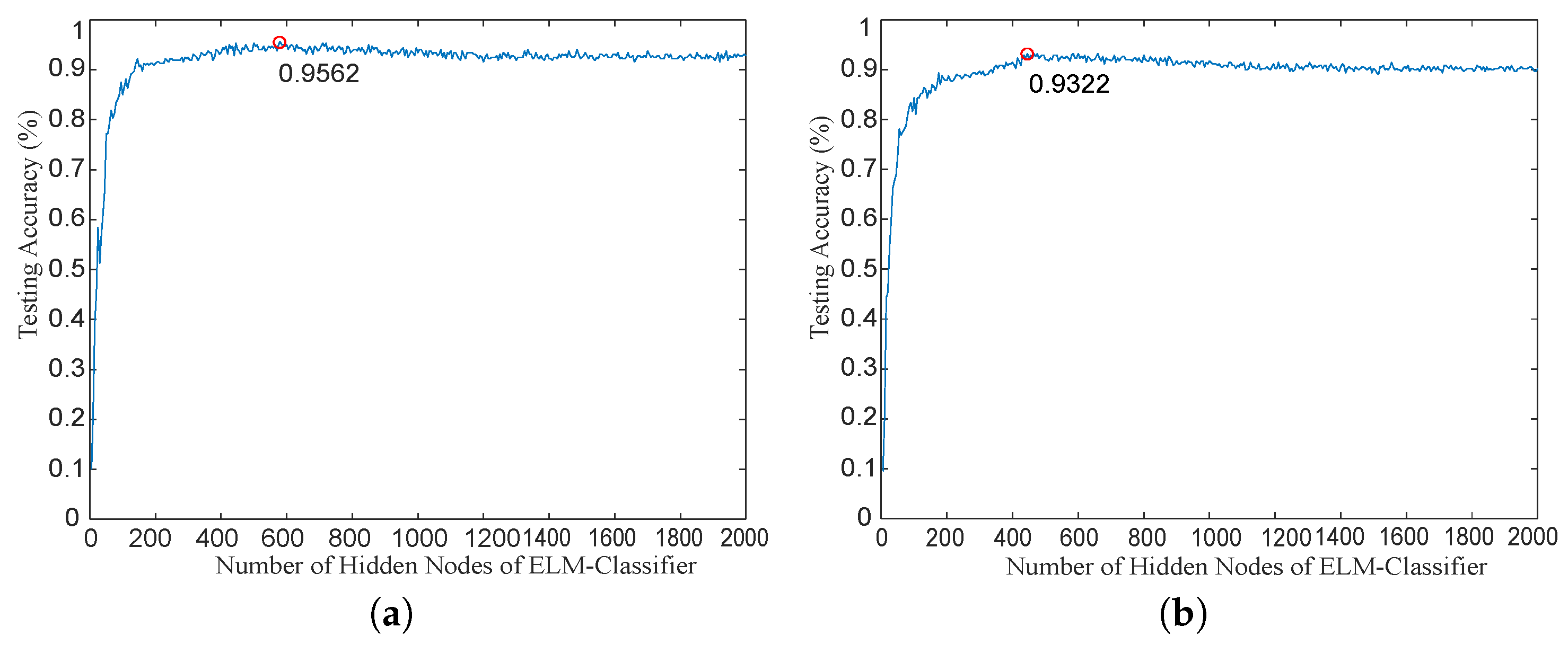
Figure 7a,b,we set the number of hidden layer nodes
, when the number of hidden layer nodes
l increase from 1 to 2000 at 10 interval, the largest accuracy is 95.62% at single fault condition and 93.22% simultaneous-fault condition, respectively. The optimal hidden layer nodes in the classifier is set as
.
As suggested in
Table 5, a total of 16 kinds of combinations of method are implemented to compare the generation performance. According to the feature extraction, this paper takes three kinds of methods as references. They are WPT+TDSF+KPCA combination, EMD+SVD combination and LMD+TDSF combination, respectively. This paper takes the Db4 (Daubechies) wavelet as the mother wavelet and sets the level of decomposition at the range from 3 to 5. The
radial
basis
function (RBF) acts as kernel function for KPCA. In order to reduce the number of trials, the hyperparameter
R of RBF based on
is tried for
v ranged from – 3 to 3. In the KPCA processing, this paper selects the polynomial kernel with
and the RBF kernel with
. After dimension reduction, a total of 80 principal components are obtained. After feature extraction, the next step is to optimize parameters of classifiers. This paper takes four kinds of methods, namely PNN, RVM, SVM and ELM. As mentioned previously, probabilistic based classifiers have their own hyperparameters for tuning. PNN uses spread
s and RVM employs width
. In this case study, the value of
s is set from 1 to 3 at an interval of 0.5, and the values of
is selected from 1 to 8 at an interval of 0.5. In order to find the optimal decision threshold, this paper sets the search region at the range from 0 to 1 at an interval of 0.01. For the configuration of ELM, this paper takes the sigmoid function as the activation function and sets the number of hidden modes
l as 600 for a trial. According to the experimental results in
Table 4, a total of 80 components are obtained from the feature extractor. It is clear that the accuracies with autoencoder are higher than those with WPT+TDSF+KPCA. The results can be explained because the ELM based autoencoder holds all information of the input data during the representational learning. However, KPCA tends to hold the important information and inevitably lose some unimportant information.
In order to compare the performances of classifiers, this paper sets the contrast experiments with the same ELM based autoencoder and different classifiers. As shown in
Table 5, the number of hidden nodes
L in autoencoder is 800, the last dimensions of training data
and testing data
are 1800×800 and 280×800, respectively. As suggested in
Figure 7, this optimal value of
l is 600. According to the experimental results not listed here, SVM employed polynomial kernel with
and
= 4 show the best accuracy.
Table 6 shows that the fault detection accuracy of ELM is similar to that of SVM, while the fault identification time of ELM and SVM take 20 ms and 157 ms respectively. The performance of ELM is much faster than SVM. Quick recognition is necessary for real-time fault diagnosis system. In actual WTGS application, the real-time fault diagnostic system is required to analyze signals for 24 hours per day. In terms of fault identification time, ELM is faster than SVM by 88.46%. The test results show that ELM and SVM have relatively high testing accuracies, but the advantage of ELM is embodied in testing time, which is very significant in real situation because a practical real-time WTGS diagnostic system will analyze more sensor signals than the two sensor signals used in this case study.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}