An Evolutionary Game Model for Industrial Pollution Management under Two Punishment Mechanisms


School of Management and Engineering, Capital University of Economics and Business, Beijing 100070, China
*
Author to whom correspondence should be addressed.
Int. J. Environ. Res. Public Health 2019, 16(15), 2775; https://doi.org/10.3390/ijerph16152775
Submission received: 29 May 2019
/
Revised: 21 July 2019
/
Accepted: 31 July 2019
/
Published: 3 August 2019
(This article belongs to the Special Issue Application of Advanced Analytical Techniques to Solve Environmental Problems)
Abstract
:In recent years, with the rapid development of the economy, industrial pollution problems have become more and more serious. This paper constructs an evolutionary game model for industrial pollution between the local governments and enterprises to study the dynamic evolution path of a game system and the evolutionary stable strategy under two punishment mechanisms. The results show that, in a static punishment mechanism (SPM), the strategy between governments and enterprises is uncertain. Moreover, the evolutionary trajectory between governments and enterprises is uncertain. However, under the dynamic punishment mechanism (DPM), the evolution path between governments and enterprises tends to converge to a stable value. Thus, the DPM is more conducive than the SPM for industrial pollution control.
1. Introduction
In recent years, increasing attention has been paid to environmental pollution. One of the main sources of pollution is industrial pollution, which causes great damage on the environment. Thus, it is important to increase the efficiency of industrial pollution management. Over the past decade, there has been a widespread interest in the field of control theory to discuss environmental pollution [1,2,3,4,5]. However, industrial pollution management is a complex project which needs the participation of local governments and enterprises. Thus, different strategies selected by local governments and enterprises are very important to deal with the industrial pollution. Therefore, this is a decision problem which involves conflicting objectives. As Raquel et al. [6] illustrated, the best way to deal with this class of multi-objective conflict resolution problem is through conflict resolution, which is a special field of game theory. The theory of games was first formalized by Morgenstern and Von Neumann [7] in reference to human economic behavior and has been used in many areas, such as climatic change, emergency, and nuclear accidents. Since then, game theory has developed rapidly. Many scholars have applied this method to environmental pollution management [8,9,10,11,12,13,14,15,16]. For a review of the literature on audit mechanisms using standard game theory, see [8,9,10,15,16]. These audit mechanisms are very important for governments to conduct policy. For example, Cason et al. [8] examined the effectiveness of traditional regulatory schemes and newly emerging social information schemes for achieving compliance. However, the above research was mainly in a static principal-agent framework and based on classical game theory. Luce [17] argued that a central assumption of classical game theory is that players will behave rationally. Such an assumption would clearly be out of place in an evolutionary context.
Friedman and Daniel [18] argued that evolutionary game theory analyses players’ interaction strategy from bounded rationality. In an evolutionary game, each individual chooses among alternative actions or behaviors whose payoff or fitness depends on the choices of others. Thus, evolutionary game theory is a way of thinking about evolution at the phenotypic level when the fitness of particular phenotypes depends on their frequencies in the population [19]. Therefore, evolutionary game theory leads to a new type of ‘solution’ for a game, the ‘evolutionary stable strategy’ (ESS). An ESS is a strategy such that, if all the members of a population adopt it, then no mutant strategy could invade the population under the influence of natural selection.
Based on the assumption of bounded rationality, evolutionary game theory has seized a large and increasing share of game theory literature in recent years. It has been applied to many areas, such as interspecific competition for resources, animal dispersal, land use, plant growth and reproduction [20,21,22,23,24]. For example, Xie [24] provided a case in Hunan province, China, which discussed evolutionary game and the simulation of management strategies of fallow, cultivated land. Additionally, many scholars have applied evolutionary game theory to environmental pollution [25,26,27,28]. For example, Wang et al. [25] built a system dynamics model for studying a mixed-strategy evolutionary game between government and firms. Chen and Hu [26] used evolutionary game theory to study governments’ and manufacturers’ behavioral strategies under various carbon taxes and subsidies. Estalaki et al. [27] applied evolutionary game theory to discuss river water quality management. Shen and Wang [28] established two kinds of government supervision mechanisms based on evolutionary game theory.
To the best of our knowledge, though there is some research about industrial pollution control under the framework of evolutionary games, most of it has been mainly focused on the solution and stability of the equilibrium point. Besides, it has ignored the discussion of the central point. In a real situation, it is difficult for enterprises to strictly reduce emissions. Therefore, research on the central point will be of more practical significance. Our contributions can be summarized as follows: (1) We construct an evolutionary game model for industrial pollution between local governments and enterprises under two punishment mechanisms to study the dynamic evolution path of a game system and the evolutionary stable strategy. Notably, the evolutionary stable strategy that we studied focuses on the stability of the central point. (2) We compare the evolution process of the system under the two mechanisms.
The rest of this paper is organized as follows. Section 2 describes in detail about the evolutionary game model of industrial pollution under the static punishment mechanism (SPM). In Section 3, we describe in detail about the evolutionary game model of industrial pollution under the dynamic punishment mechanism (DPM). Finally, the conclusions of this paper are presented in Section 4.
2. The Evolutionary Game Model of Industrial Pollution under the SPM
In this section, an evolutionary game model is presented under the SPM. Furthermore, the evolutionary game model is described in detail as follows.
2.1. Research Assumptions
Assumption 1.
There are two main players in the process of industrial pollution management. The first one is the local government, marked as (LG). The second one is the enterprise, marked as (EP). Moreover, we suppose that the two players are finitely rational. In addition, we assume that each player can learn constantly and adjust its strategy to adapt to changes of environment.
Assumption 2.
In this assumption, we need to define the strategy set of the two players. To illustrate, we assume that there are two strategies for each player. Additionally, we suppose that the strategies contain two opposing evolutionary strategies. Principally, to control the industrial pollution, the local government must take measures to supervise to the enterprise, because the enterprise will discharge of pollutants in the environment. In the process of industrial pollution control, the local government can actively supervise or negatively supervise to the enterprise. To illustrate, we call on the local government to actively supervise, if it shows a strong willingness to supervise. Additionally, we call on the local government to negatively supervise if it shows a weak willingness to supervise. At the same time, the enterprise can also show a strong or weak willingness to reduce emissions.
Assumption 3.
We suppose that the probability of the local government showing a strong willingness to supervise is , so the probability of the local government showing a weak willingness to supervise is . Moreover, the enterprise can also have two choices to reduce emissions. We assume that the probability of the enterprise showing a strong willingness to reduce emissions is , so the probability of the enterprise showing a weak willingness to reduce emissions is . It is obvious that .
2.2. Parameters Setting
Due to the fact that the willingness to reduce emissions is different, the enterprise will pay a different cost to reduce emissions. In order to distinguish the cost effectively, we assume that is the cost of a strong willingness and is the cost of a weak willingness. The enterprise will pay more when it shows a strong willingness than when it shows weak willingness to reduce emissions. Thus, obviously, . Similar to the enterprise, we assume that the cost of the local government with a strong willingness is . If the local government decreases its willingness from strong to weak, the decreased cost is , . We suppose that the enterprise will get an extra benefit when it shows a weak willingness to reduce emissions. Then, we assume the extra benefit is . Moreover, we assume that if the local government shows a weak willingness to supervise, the enterprise will not be punished even if it shows a weak willingness to reduce emissions. On the contrary, we suppose that when the enterprise shows a weak willingness to reduce emissions at the same time as when the local government shows a strong willingness to supervise, the enterprise will be punished by the local government. Furthermore, we assume that the penalty value is fixed, marked as . In this case, we call the punishment mechanism the SPM. On the contrary, we assume that the penalty value is dynamic, and the dynamic penalty value is —we call this punishment mechanism the DPM. The evolutionary game model of industrial pollution under the SPM will be discussed in Section 2. Then, the evolutionary game model of industrial pollution under the DPM will be discussed in Section 3.
2.3. The Evolutionary Game between the Enterprise and the Local Government
In this section, the evolutionary game model for industrial pollution under the SPM is established. First of all, when the local government shows a strong willingness to supervise, the expected return of the enterprise is given by
On the contrary, when the local government shows a weak willingness to supervise, the expected return of the enterprise is given by
In addition, we assume that the average benefit of the enterprise is given by
Then, according to Equations (1)–(3), the replicated dynamic equation of the enterprise can be obtained as follows:
Moreover, when the enterprise shows a strong willingness to reduce emissions, we assume that the expected return of the government is given by
On the contrary, when the enterprise shows a weak willingness to reduce emissions, we suppose that the expected return of the government is given by
In addition, we assume that the average benefit of the local government is given by
Furthermore, from Equations (5)–(7), we obtain the replicated dynamic equation of the local government as follows:
Thus, according to Equations (4) and (8), a dynamic system is given by
2.3.1. The Jacobi Matrix Partial Stability Analysis
According to the method of the Jacobi matrix proposed by Friedman and Daniel [18], we can obtain the evolutionary stability of the replicated dynamic system at the equilibrium point. We suppose that the Jacobi matrix of system is . Thus, we have the corresponding Jacobi matrix as follows:
Then, according to Equation (10), we have:
The trace of the matrix is:
According to Equation (9), let , so the possible equilibrium points of system are: among with .
Then, from Equations (11) and (12) and the point , we have:
Then, the value of the matrix determinant and the trace of the matrix from the five equilibrium points are given in Table 3.
According to evolutionary theory, if the Jacobi matrix satisfies , then the corresponding equilibrium point is the locally asymptotically stable fixed point, and the corresponding evolutionary strategy is the evolutionary stability strategy. From Section 2.2, we can see that and . Then, we have and . Furthermore, the following four cases are discussed.
Case 1.
If , then the evolutionary stability of local equilibrium points is presented as shown in Table 4.
Case 2.
If , then the evolutionary stability of local equilibrium points is presented as shown in Table 5.
Case 3.
If , then the evolutionary stability of local equilibrium points is presented as shown in Table 6.
Case 4.
If , then the evolutionary stability of local equilibrium points is presented as shown in Table 7.
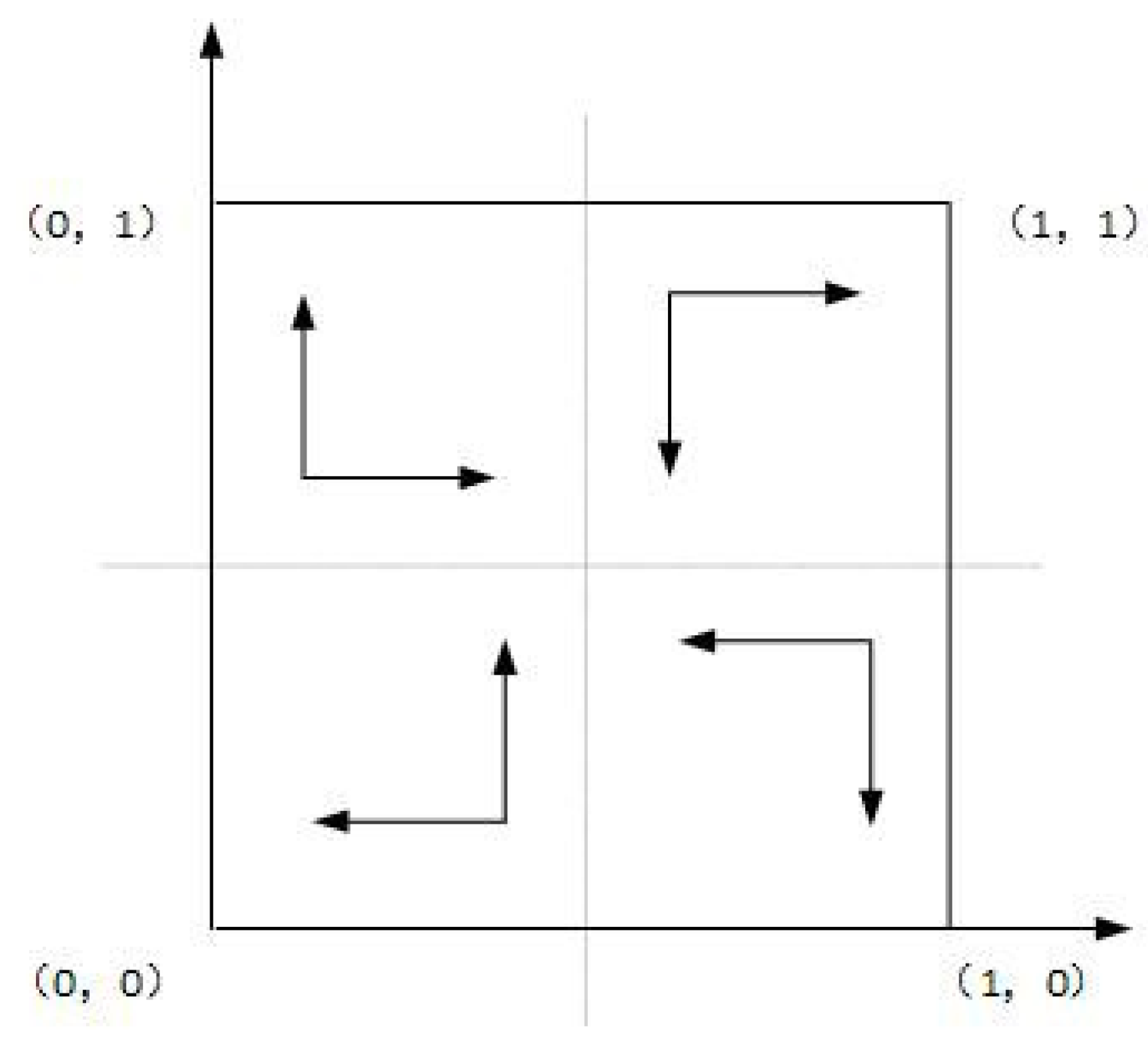
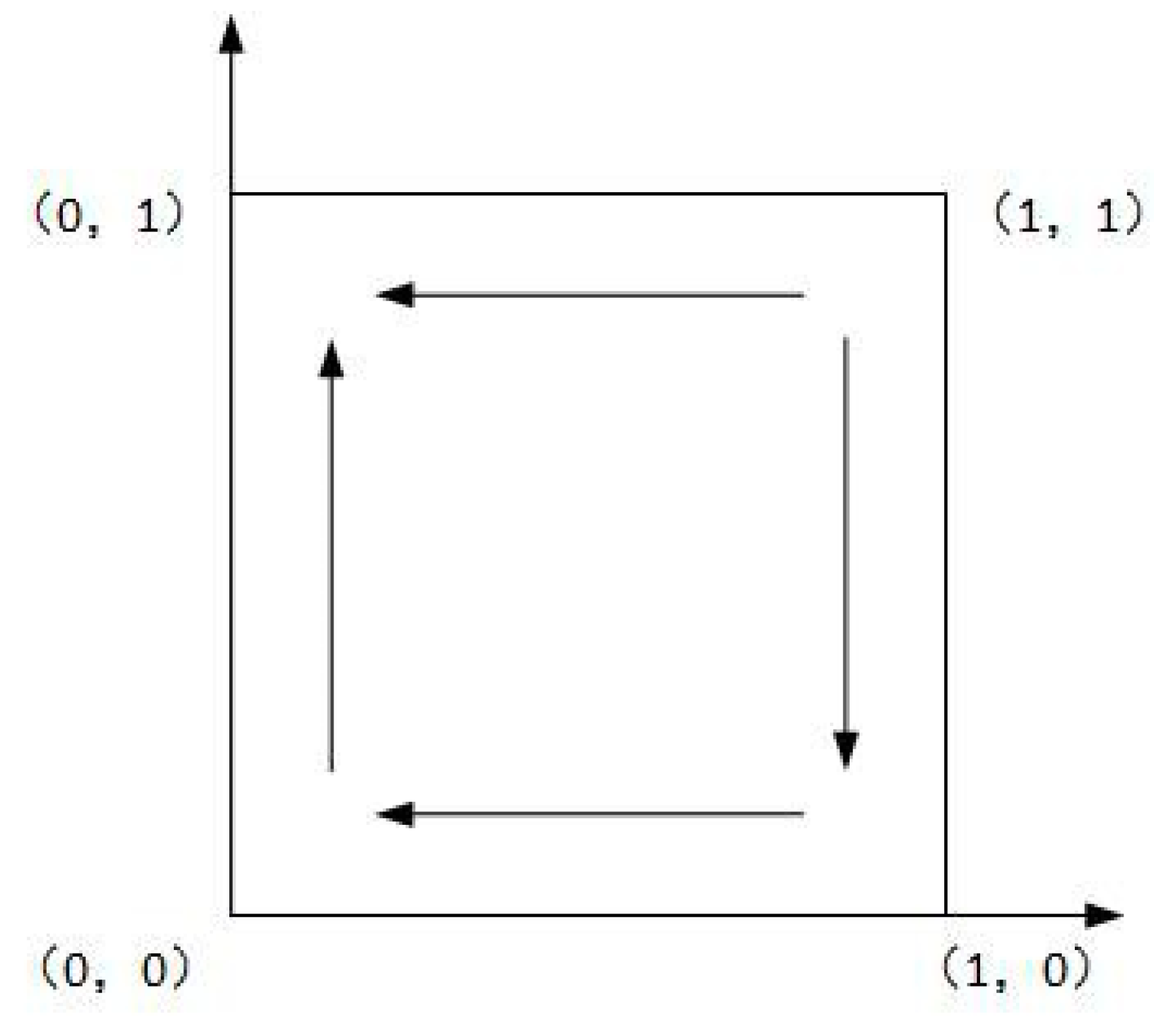
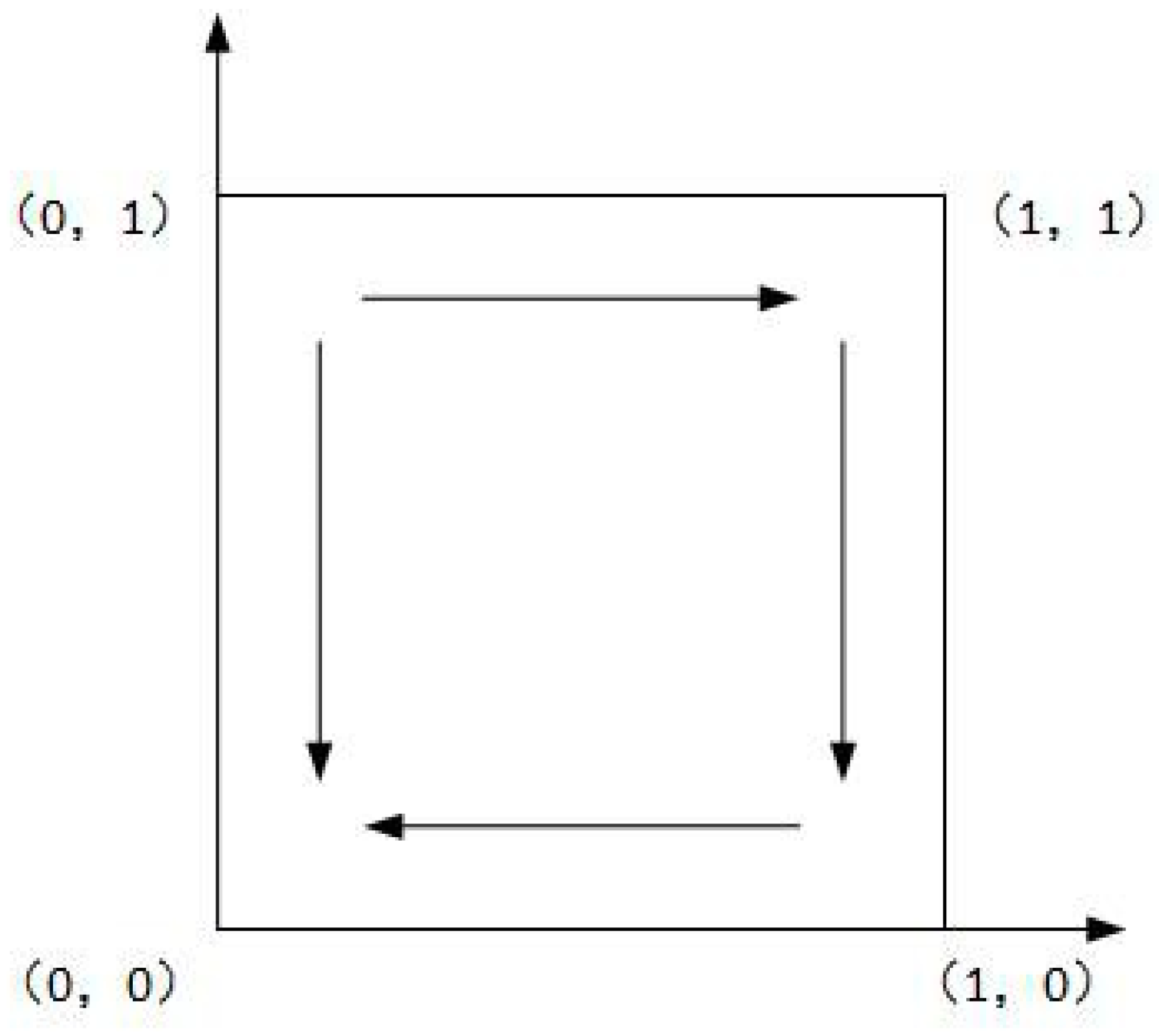
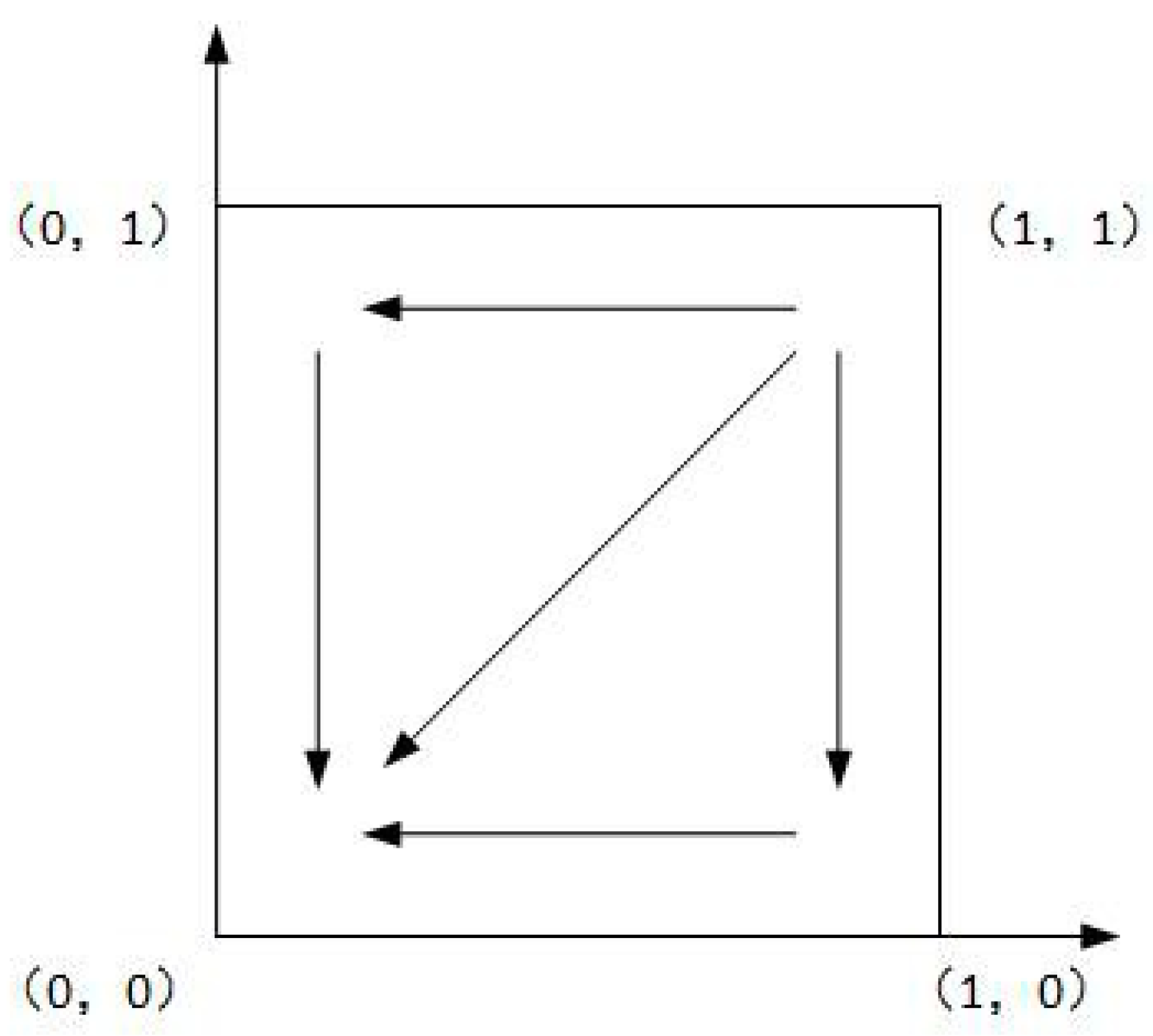
As shown in Case 1, if , and , there are four saddle points and a central point. Then, there is no ESS point. Therefore, in this case, no certain strategy between the local government and the enterprise is reached. As shown in Case 2, if and , then there is a ESS point at (0,1). In this case, the enterprise will completely show a weak willingness to reduce emissions, and the local government will adopt the strategy which shows a strong willingness to supervise. Moreover, as shown in Cases 3 and 4, there is an ESS point at (0,0). Thus, although the enterprise shows a weak willingness to reduce emissions, the local government still shows a weak willingness to supervise. Furthermore, four evolutionary phase diagrams are presented in Figure 1, Figure 2, Figure 3 and Figure 4.
2.3.2. System Simulation Analysis
In order to intuitively observe the dynamic evolution process of the strategy selected between the local government and the enterprise, the MATLAB system simulation tool was used under the four cases. The assumed values of the parameters under the four cases are shown in Table 8.
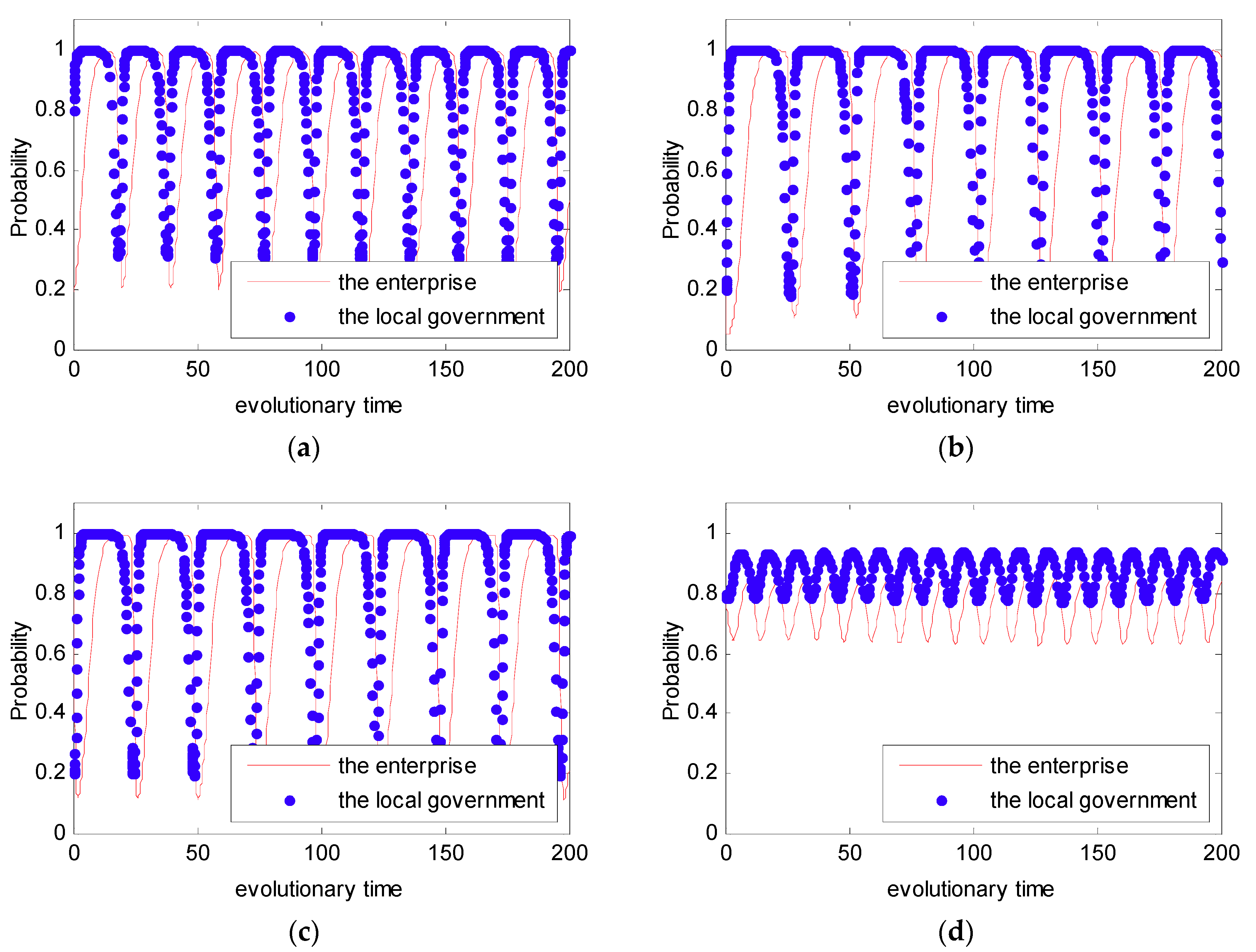
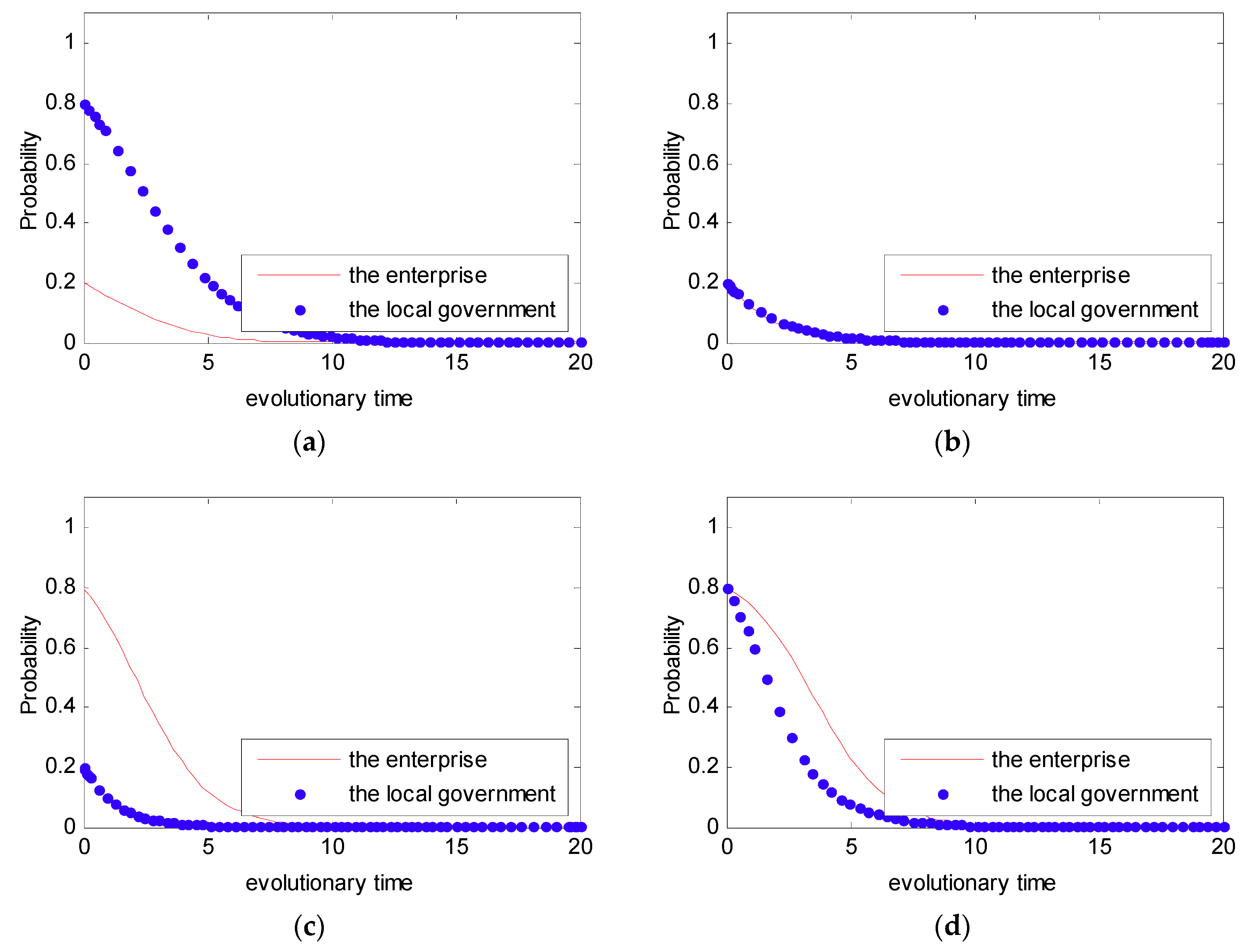
In Case 1, we assumed that the initial value as . Additionally, in order to entirely present the evolutionary game between the local government and the enterprise, four initial states of were simulated with different probabilities: (0.2, 0.8), (0.2, 0.2), (0.8, 0.2), (0.8, 0.8). The four initial states stand for four different strategies; that is to say that the strategies selected by the local government and the enterprise were: Weak willingness to reduce emissions, strong willingness to supervise; weak willingness to reduce emissions, weak willingness to supervise; strong willingness to reduce emissions, weak willingness to supervise; and strong willingness to supervise, strong willingness to supervise. The simulation analysis is presented in Figure 5. From Figure 5, we can see that no matter what the initial state is, the strategy between the local government and the enterprise is uncertain. Besides, the strategy between the local government and the enterprise presents periodic concussion. In the following, the evolutionary process between the local government and the enterprise under the DPM is further discussed.
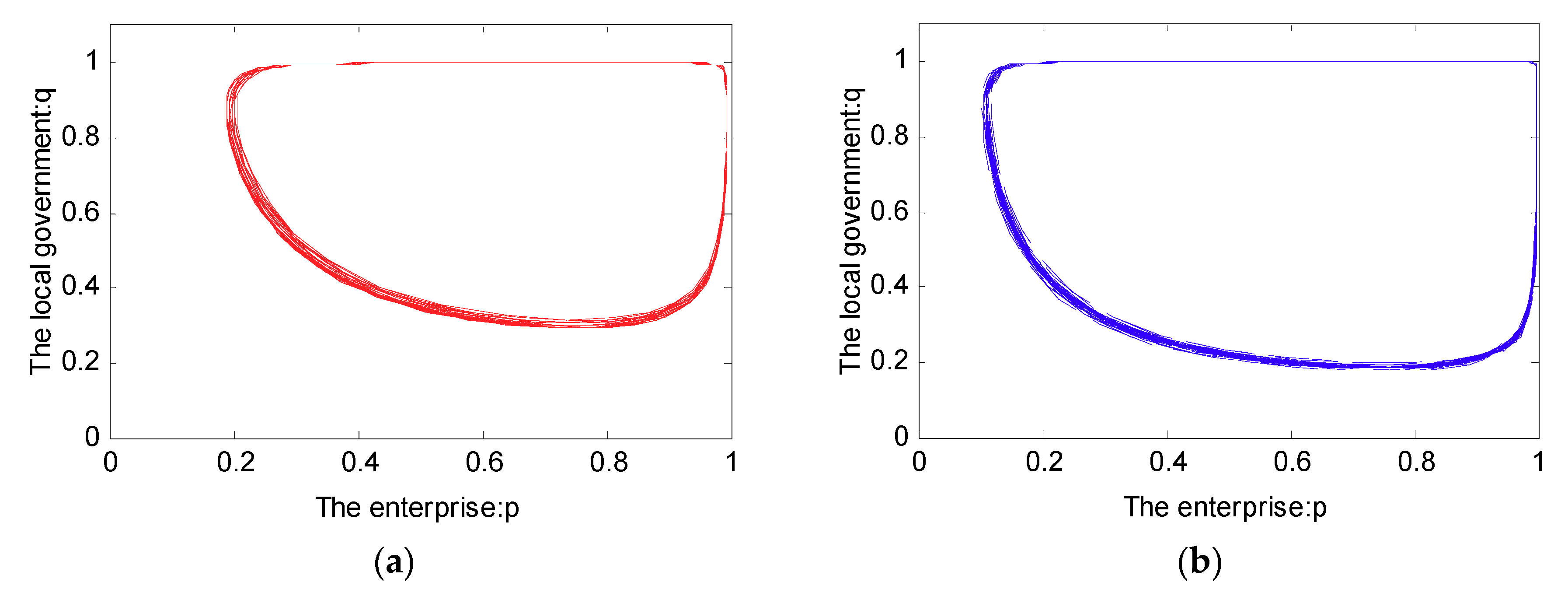
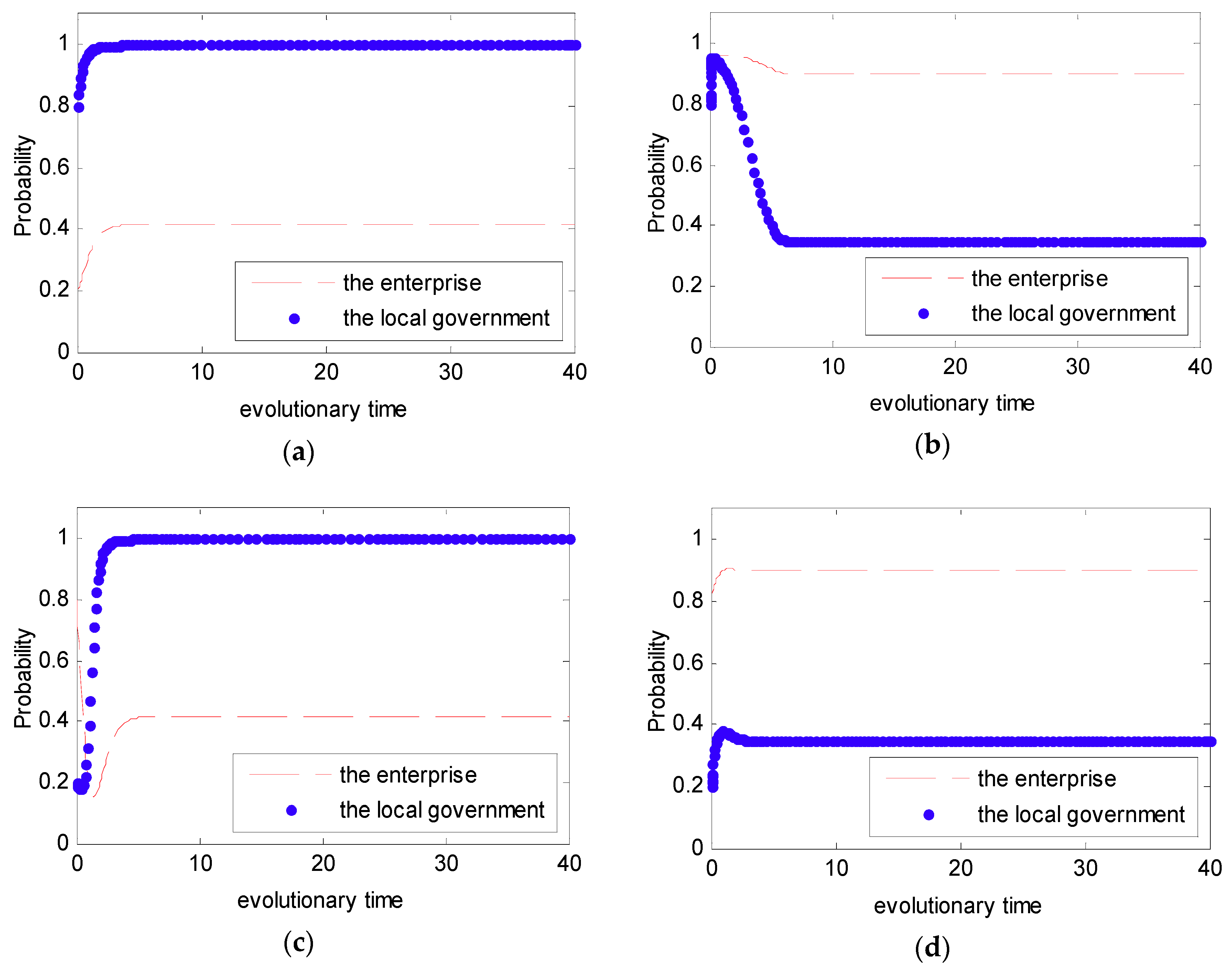
In Case 1, we know that the strategy between the local government and the enterprise is uncertain. Furthermore, let and ; the simulation analysis is presented in Figure 6. As can be seen in Figure 6, the evolutionary path of the behavioral strategy between the local government and the enterprise presents a closed loop. This means that no certain strategies between the local government and the enterprise will be reached in the real world.
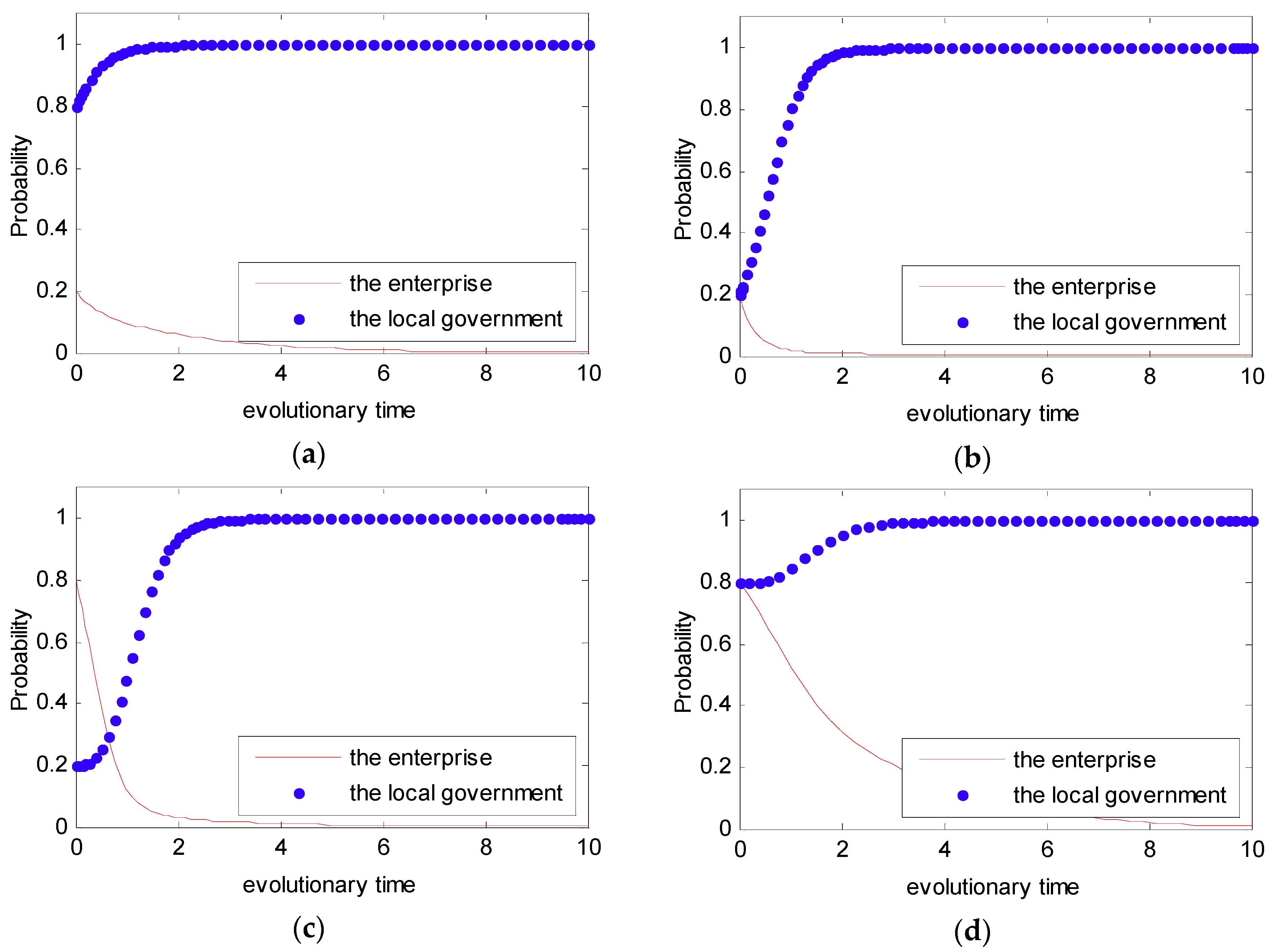
In Case 2, we assume that the initial value as to satisfy the condition that . Additionally, similar to Case 1, four initial states were simulated with different probabilities: (0.2, 0.8), (0.2, 0.2), (0.8, 0.2), (0.8, 0.8). This simulation analysis is presented in Figure 7. From Figure 7, we can see that no matter what the initial state is, the strategy between the local government and the enterprise is certain, and it converges to (0,1). Thus, in this situation, the final evolutional result is that the local government tends to show a strong willingness to supervise, while the enterprise tends to show a weak willingness to reduce emissions.
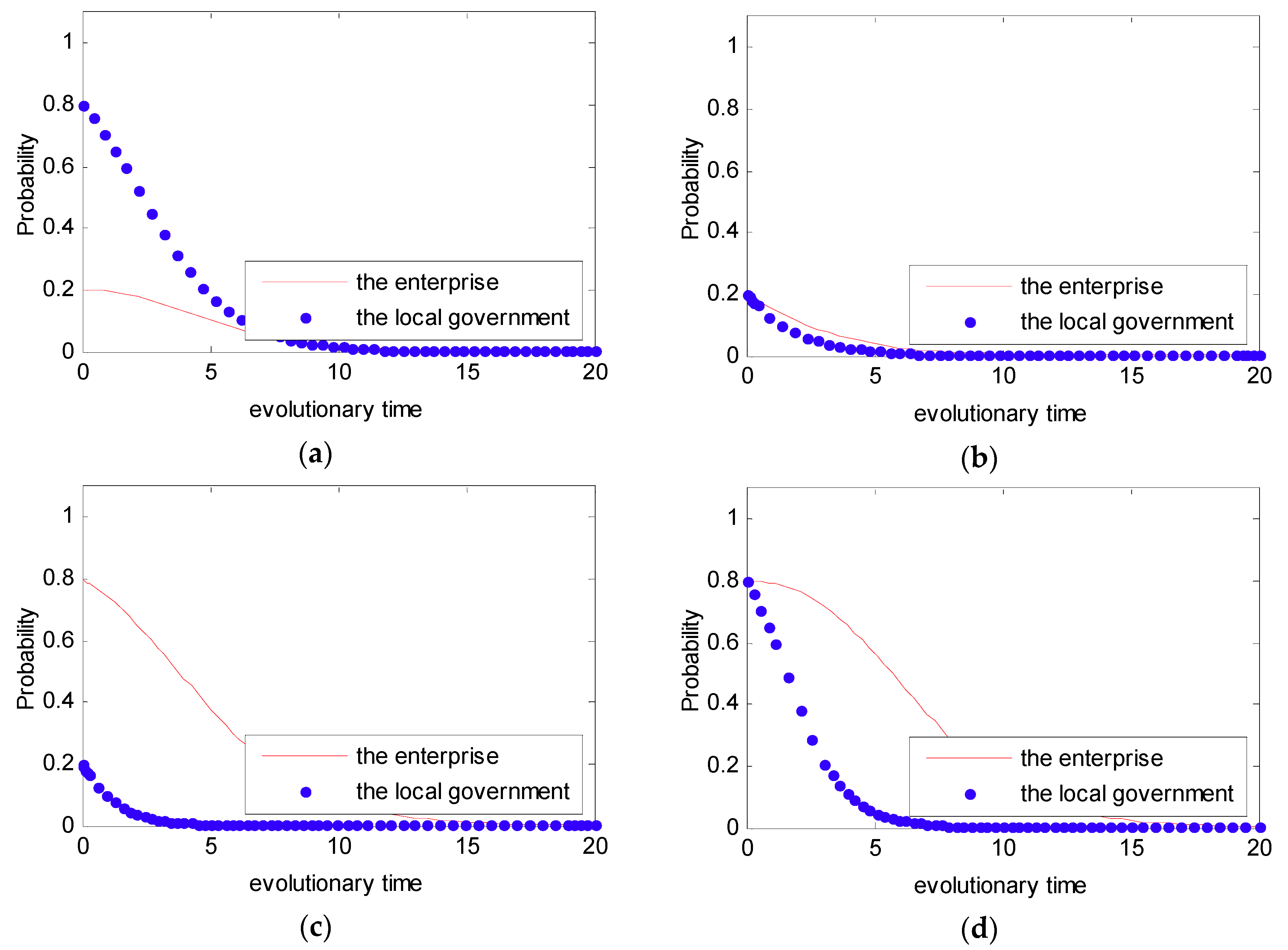
Similar to Cases 1 and 2, for Cases 3 and 4, four initial states of were simulated with different probabilities: (0.2, 0.8), (0.2, 0.2), (0.8, 0.2), (0.8, 0.8). The simulation analyses are presented in Figure 8 and Figure 9. From Figure 8 and Figure 9, we can see that no matter what the initial state is, the strategy between the local government and the enterprise is certain, and it converges to (0,0). Thus, the final evolutional result is that the local government tends to show a weak willingness to supervise, while the enterprise tends to show a weak willingness to reduce emissions.
3. The Evolutionary Game Model of Industrial Pollution under the DPM
3.1. The Model under the DPM
In this section, we assume that the penalty value is dynamic, and the dynamic penalty value is . We call this punishment mechanism the DPM. In the DPM, we suppose that the penalty value is proportional to the probability of the enterprise which shows a weak willingness to reduce emissions. As such, we set , where is the maximum penalty. Based on the above analysis, a new payoff matrix under the DPM is shown in Table 9.
Based on the payoff matrix under the DPM, we can establish an evolutionary game model. Then, the dynamic system combined by the replicated dynamic equation of the local government and the enterprise is given by
In the dynamic system (14), let . As such, the possible equilibrium points of system are: among which .
If we suppose that the Jacobi matrix of system is , we can recalculate the corresponding Jacobi matrix as follows:
According to Section 2.3.1, the strategy selected by the local government and the enterprise is uncertain. In addition, in other cases, the strategy selected by the local government and the enterprise is certain. As such, we just discuss the Case 1 under the DPM.
Case 5.
If and . Substituting into the Equation (14) for the sake of simplicity, we have the evolutionary stability of local equilibrium points in this case as shown in Table 10.
3.2. Simulation Analysis
In order to intuitively observe the dynamic evolution process of the strategy selected between the government and the enterprise under the DPM, the simulation analysis was used under the Case 1. In Case 1, we set the initial value in the payoff matrix as to satisfy the condition that . However, under the DPM, we assume that , , and . Additionally, in order to present the evolutionary game between the local government and the enterprise, four initial states of were simulated with different probabilities: (0.2, 0.8, 6), (0.2, 0.8, 6), (0.8, 0.2, 100), (0.8, 0.2, 100). The four initial states stand for four different strategies, namely a weak willingness to reduce emissions and a strong willingness to supervise under the condition that and a strong willingness to reduce emissions and a weak willingness to supervise under the condition that . The simulation analysis is presented in Figure 10.
From Figure 5 and Figure 6, we can see that the strategy between the government and the enterprise is uncertain and presents periodic concussion under the SPM. Moreover, we find that the evolutionary path of the behavioral strategy between the local government and the enterprise presents a closed loop. However, from Figure 10, we can see that no matter what the initial state is, the strategy between the local government and the enterprise is certain. Provided with different probabilities, the probabilities of choosing a strong willingness strategy will converge to different values. Moreover, while the penalty value is increased, the probability that the enterprise tends to actively reduce emissions is greatly increased.
4. Conclusions
This paper presents an evolutionary game model for industrial pollution under two punishment mechanisms. The strategy between local governments and enterprises is uncertain and presents periodic concussion under the SPM. Moreover, the evolutionary path of the behavioral strategy between local governments and enterprises presents a closed loop. However, under the DPM, the strategy between local governments and enterprises is certain, and it converges to different values. Moreover, while the penalty value is increased, the probability that enterprises tend to actively reduce emissions is greatly increased. As such, the results show that the DPM is more conducive than the SPM for industrial pollution control.
From the above results, some recommendations are presented to the policy of local governments. On the one hand, local governments can adopt the DPM when dealing with industrial problems. On the other hand, local governments should actively take some measures to promote enterprises to protect the environment. Moreover, local governments can appeal to the public to participate in environmental supervision to reduce the cost of its supervision.
This paper studied an evolutionary game model for industrial pollution under two punishment mechanisms. However, central governments’ punishments to local governments was not taken into account. As such, a further research direction would be studying situations where central governments’ punishments to local governments are taken into account.
Author Contributions
Conceptualization, C.W.; methodology, F.S.; software, F.S.; validation, C.W.; formal analysis, F.S.; investigation, C.W.; resources, C.W.; data curation, F.S.; writing—original draft preparation, F.S.; writing—review and editing, C.W.; visualization, C.W.; supervision, C.W.; project administration, C.W.; funding acquisition, C.W.
Funding
This work was supported by the Natural Science Foundation of Beijing, China (Grant No.9182002).
Acknowledgments
Authors would like to thank the Editor and the anonymous reviewers for their valuable comments and detailed suggestions that have improved the presentation of this paper.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Plourde, C.; Yeung, D. A model of industrial pollution in a stochastic environment. J. Environ. Econ. Manag. 1989, 16, 97–105. [Google Scholar] [CrossRef]
- Frederick, V.D.P.; De Zeeuw, A.J. International aspects of pollution control. Environ. Resour. Econ. 1992, 2, 117–139. [Google Scholar] [Green Version]
- Lin, W.T. The control of environmental pollution and optimal and employment decisions. Optim. Control Appl. Methods 2010, 8, 21–36. [Google Scholar] [CrossRef]
- Forster, B.A. Optimal consumption planning in a polluted environment. Econ. Rec. 2010, 49, 534–545. [Google Scholar] [CrossRef]
- Lusky, R. A model of recycling and pollution control. Can. J. Econ./Rev. Can. Deconomique 2001, 9, 91–101. [Google Scholar] [CrossRef]
- Raquel, S.; Ferenc, S.; Emery, C., Jr.; Abraham, R. Application of game theory for a groundwater conflict in Mexico. J. Environ. Manag. 2007, 84, 560–571. [Google Scholar] [CrossRef] [PubMed]
- Morgenstern, O.; Von Neumann, J. Theory of Games and Economics Behavior; Princeton University Press: Princeton, NJ, USA, 1953. [Google Scholar]
- Cason, T.; Friesen, L.; Gangadharan, L. Regulatory performance of audit tournaments and compliance observability. Eur. Econ. Rev. 2016, 85, 288–306. [Google Scholar] [CrossRef] [Green Version]
- Gilpatric, S.M.; Vossler, C.A.; McKee, M. Regulatory enforcement with competitive endogenous audit mechanisms. Rand J. Econ. 2011, 42, 292–312. [Google Scholar] [CrossRef]
- Gintis, H. The Bounds of Reason: Game Theory and the Unification of the Behavioral Sciences; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Misiolek, W.S. Pollution control through price incentives: The role of rent seeking costs in monopoly markets. J. Environ. Econ. Manag. 1989, 15, 1–8. [Google Scholar] [CrossRef]
- Yao, D.A. Strategic responses to automobile emissions control: A game-theoretic analysis. J. Environ. Econ. Manag. 1988, 15, 419–438. [Google Scholar] [CrossRef]
- Milliman, S.R.; Prince, R. Firm incentives to promote technological change in pollution control. J. Environ. Econ. Manag. 1989, 17, 247–265. [Google Scholar] [CrossRef]
- Kumar, A.; Patil, R.S.; Dikshit, A.K.; Islam, S.; Kumar, R. Evaluation of control strategies for industrial air pollution sources using American meteorological society/Environmental protection agency regulatory model with simulated meteorology by weather research and forecasting model. J. Clean. Prod. 2016, 116, 110–117. [Google Scholar] [CrossRef]
- Oestreich, A.M. Firm’s emissions and self-reporting under competitive audit mechanisms. Environ. Resour. Econ. 2015, 62, 949–978. [Google Scholar] [CrossRef]
- Oestreich, A.M. On optimal audit mechanisms for environmental taxes. J. Environ. Econ. Manag. 2017, 84, 62–83. [Google Scholar] [CrossRef]
- Luce, R.D.; Raiffa, H.; Teichmann, T. Games and decisions. Phys. Today. 1958, 11, 33–34. [Google Scholar] [CrossRef]
- Friedman, D. Evolutionary games in Economics. Econom. 1991, 59, 637–666. [Google Scholar] [CrossRef]
- Smith, J.M. Evolution and the Theory of Games; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar]
- Dijkstra, B.R.; Vries, F.P.D. Location choice by households and polluting firms: An evolutionary approach. Eur. Econ. Rev. 2006, 50, 425–446. [Google Scholar] [CrossRef]
- Lawlor, L.R.; Smith, J.M. The coevolution and stability of competing species. Am. Nat. 1976, 110, 79–99. [Google Scholar] [CrossRef]
- Hamilton, W.D.; May, R.M. Dispersal in stable habitats. Nature 1977, 269, 578–581. [Google Scholar] [CrossRef]
- Mirmirani, M.; Oster, G. Competition, Kin Selection, and Evolutionary stable strategies. In Multicriteria Optimization in Engineering and in the Sciences; Springer: Boston, MA, USA, 1988. [Google Scholar]
- Xie, H.; Wang, W.; Zhang, X. Evolutionary game and simulation of management strategies of fallow cultivated land: A case study in Hunan province, China. Land Use Policy 2018, 71, 86–97. [Google Scholar] [CrossRef]
- Wang, H.; Cai, L.; Zeng, W. Research on the evolutionary game of environmental pollution in system dynamics model. J. Exp. Theor. Artif. Intell. 2011, 23, 39–50. [Google Scholar] [CrossRef]
- Chen, W.; Hu, Z. Using evolutionary game theory to study governments and manufacturers behavioral strategies under various carbon taxes and subsidies. J. Clean. Prod. 2018, 201, 123–141. [Google Scholar] [CrossRef]
- Estalaki, S.M.; Abed-Elmdoust, A.; Kerachian, R. Developing environment penalty functions for river water quality management: Application of evolutionary game theory. Environ. Earth Sci. 2015, 73, 4201–4213. [Google Scholar] [CrossRef]
- Shen, L.; Wang, Y. Supervision mechanism for pollution behavior of Chinese enterprises based on haze governance. J. Clean. Prod. 2018, 197, 571–582. [Google Scholar] [CrossRef]
Figure 1.
Phase diagram of Case 1.

Figure 2.
Phase diagram of Case 2.

Figure 3.
Phase diagram of Case 3.

Figure 4.
Phase diagram of Case 4.

Figure 5.
Probability of choosing strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .
Figure 5.
Probability of choosing strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .

Figure 6.
The simulation analysis between the local government and the enterprise. (a)
and (b) .

Figure 7.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .
Figure 7.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .

Figure 8.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .
Figure 8.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .

Figure 9.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .
Figure 9.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .

Figure 10.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .
Figure 10.
Probability of choosing a strong willingness strategy for different time t. (a) ; (b) ; (c) ; and (d) .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
All parameters.
| Parameters | Definitions | Value Range |
|---|---|---|
| LG | The local government | - |
| EP | The enterprise | - |
| Probability of the local government showing a strong willingness to supervise | ||
| Probability of the enterprise showing a strong willingness to reduce emissions | ||
| The cost of a strong willingness for the enterprise | ||
| The cost of a weak willingness for the enterprise | ||
| The cost of a strong willingness for the government | ||
| The cost of a weak willingness for the government | ||
| Extra benefit for the enterprise | ||
| The penalty value |
Table 2.
The payoff matrix under the static punishment mechanism (SPM).
| The Enterprise | The Government | |
|---|---|---|
| Strong willingness | ||
| Weak willingness | ||
Table 3.
All parameters.
| Equilibrium Point | Expression | |
|---|---|---|
Table 4.
The evolutionary stability of local equilibrium points in Case 1.
| Equilibrium Point | Results | ||
|---|---|---|---|
| − | Saddle point | ||
| − | Saddle point | ||
| − | Saddle point | ||
| − | Saddle point | ||
| + | Central point |
Table 5.
The evolutionary stability of local equilibrium points in Case 2.
| Equilibrium Point | Results | ||
|---|---|---|---|
| − | Saddle point | ||
| + | − | ESS | |
| − | Saddle point | ||
| ± | + | Unstable point | |
| − | 0 | Central point |
Table 6.
The evolutionary stability of local equilibrium points in Case 3.
| Equilibrium Point | Results | ||
|---|---|---|---|
| + | − | ESS | |
| + | + | Unstable point | |
| − | Saddle point | ||
| − | Saddle point | ||
| − | 0 | Central point |
Table 7.
The evolutionary stability of local equilibrium points in Case 4.
| Equilibrium Point | Results | ||
|---|---|---|---|
| + | − | ESS | |
| − | Saddle point | ||
| − | Saddle point | ||
| + | + | Unstable point | |
| + | 0 | Central point |
Table 8.
The assumed values of the parameters under the four cases.
| Parameters | Case 1 | Case 2 | Case 3 | Case 4 |
|---|---|---|---|---|
| 3 | 3 | 1.2 | 1.2 | |
| 1 | 1 | 1 | 1 | |
| 2 | 2 | 2 | 2 | |
| 1 | 1 | 1 | 1 | |
| 4 | 4 | 0.5 | 0.5 | |
| 1.5 | 2.5 | 0.2 | 0.5 |
Table 9.
The payoff matrix under the dynamic punishment mechanism (DPM).
| The Enterprise | The Government | |
|---|---|---|
| Strong willingness | ||
| Weak willingness | ||
Table 10.
The equilibrium points in Case 1 under the DPM.
| Equilibrium Point | Results | ||
|---|---|---|---|
| − | Saddle point | ||
| − | Saddle point | ||
| − | Saddle point | ||
| − | Saddle point | ||
| + | 0 | Central point |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, C.; Shi, F. An Evolutionary Game Model for Industrial Pollution Management under Two Punishment Mechanisms. Int. J. Environ. Res. Public Health 2019, 16, 2775. https://doi.org/10.3390/ijerph16152775
AMA Style
Wang C, Shi F. An Evolutionary Game Model for Industrial Pollution Management under Two Punishment Mechanisms. International Journal of Environmental Research and Public Health. 2019; 16(15):2775. https://doi.org/10.3390/ijerph16152775
Chicago/Turabian StyleWang, Chuansheng, and Fulei Shi. 2019. "An Evolutionary Game Model for Industrial Pollution Management under Two Punishment Mechanisms" International Journal of Environmental Research and Public Health 16, no. 15: 2775. https://doi.org/10.3390/ijerph16152775
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.