1. Introduction
Hyperspectral imaging collects the spectral information across a certain range of the electromagnetic spectrum at narrow wavelengths (e.g., 10 nm) [
1], which makes the resulting hyperspectral image (HSI) a 3D data cube showing spatial-spectral characteristics. In contrast to traditional gray-scale or color images, abundant spectral information makes it convenient for HSIs to detect or identify objects from a cluttered background. Thus, HSIs have been widely employed in many applications, such as resource exploration [
2], environment monitoring [
3], object recognition [
4], biopharming [
5], etc.
In these applications, one of the fundamental tasks is the HSI classification, which aims to employ the classifier trained on some observed labelled samples to assign a label to each pixel based on appropriate features. Many HSI classification methods have been proposed [
6,
7,
8,
9,
10,
11]. According to the extraction of features using labelled samples or not, these methods can be roughly divided into two categories, including the supervised feature learning method and the unsupervised feature learning method. A brief review can be found in
Section 2.
In the supervised feature learning method, a specific objective function is designed to drive feature learning from labelled samples [
12,
13]. Recently, witnessing the great success of deep neural networks (DNNs) in various computer vision tasks [
14,
15], some studies begin addressing HSI classification with DNNs [
16,
17], where the desired feature and classifier are integrated into a unified mapping function and can be learned from labelled samples via an end-to-end training scheme. More importantly, with the deep hierarchical structure, DNNs enable the learning of more representative features and discriminative classifiers, thus obviously improving the classification accuracy. To this end, extensive labelled samples are needed in training the DNNs. However, labelling pixels in an HSI mainly depends on the experience of experts in geoscience, which is often costly and time-consuming. Therefore, it is crucial in practice to deal with HSI classification with limited labelled samples [
18].
When being confronted with limited labelled samples, most studies [
19,
20] adopt an unsupervised feature learning method, where features are extracted in an unsupervised way (i.e., without using the supervision provided by labelled samples) and then embedded into a supervision-inspired classifier. However, most of these methods suffer from two limitations. On one hand, they often employ a heuristic feature extraction model with shallow structure, which prevents the extracted features from being representative enough for challenging cases (e.g., different materials exhibit similar spectra in an HSI, or vice versa). On the other hand, supervision-inspired classifiers only leverage the information of labelled samples without consideration of the crucial unsupervised correlation provided by those unlabelled samples (e.g., intra-class similarity and inter-class dissimilarity). In other words, this kind of classifier considers the unlabelled samples independently, which makes it difficult to deal with various challenging cases (e.g., sample variation or noise corruption). Both of these limitations hinder those unsupervised feature learning methods from successfully dealing with challenging cases in HSI classification.
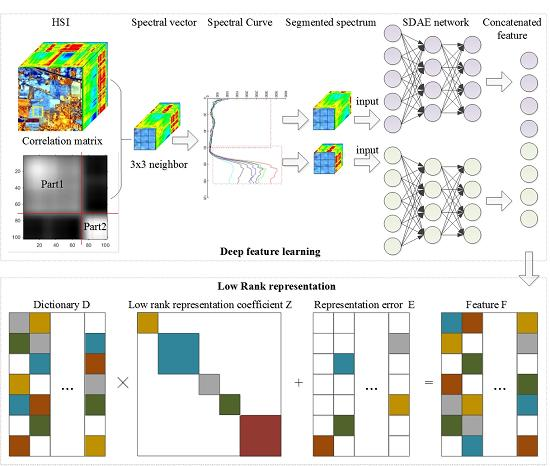
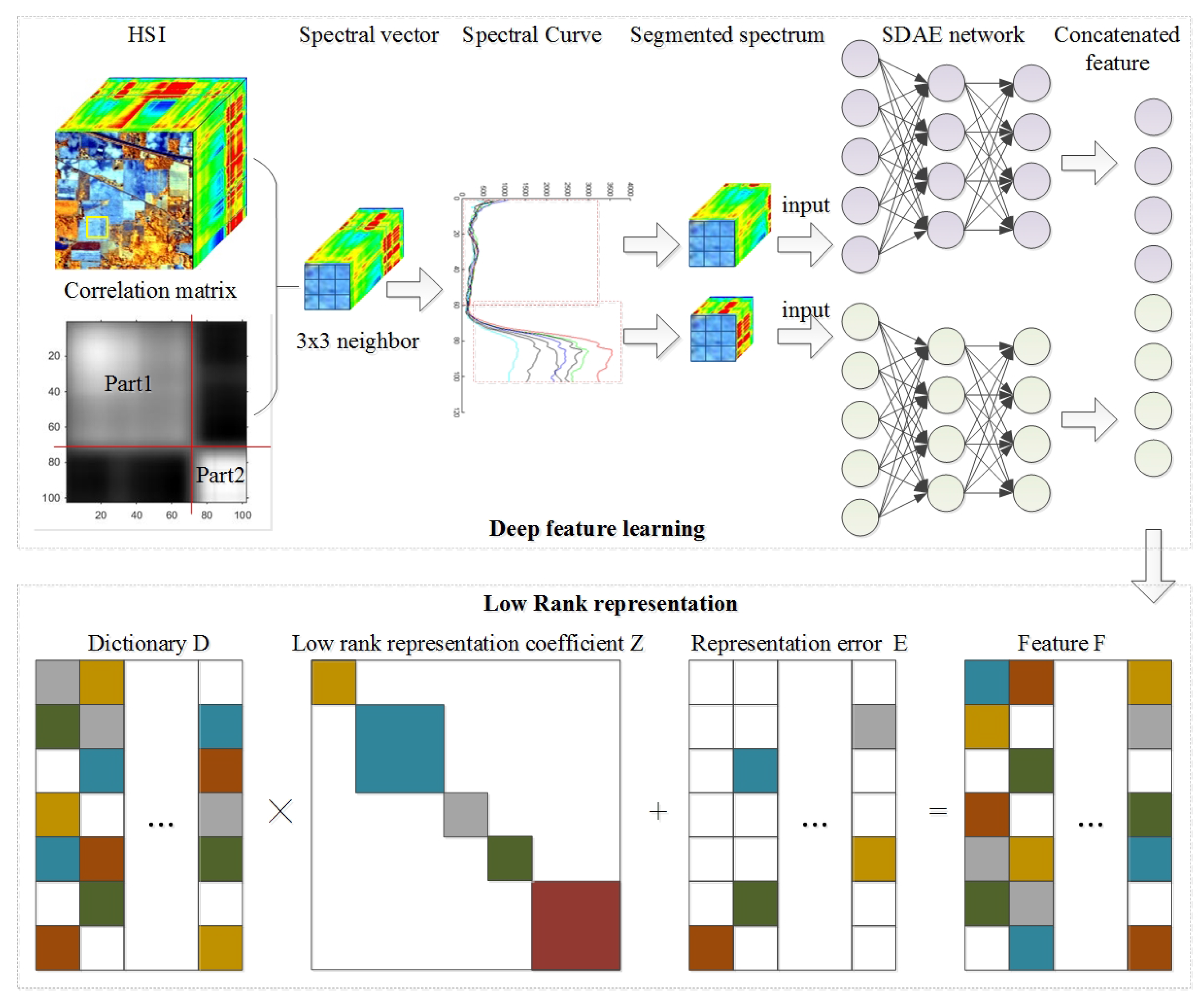
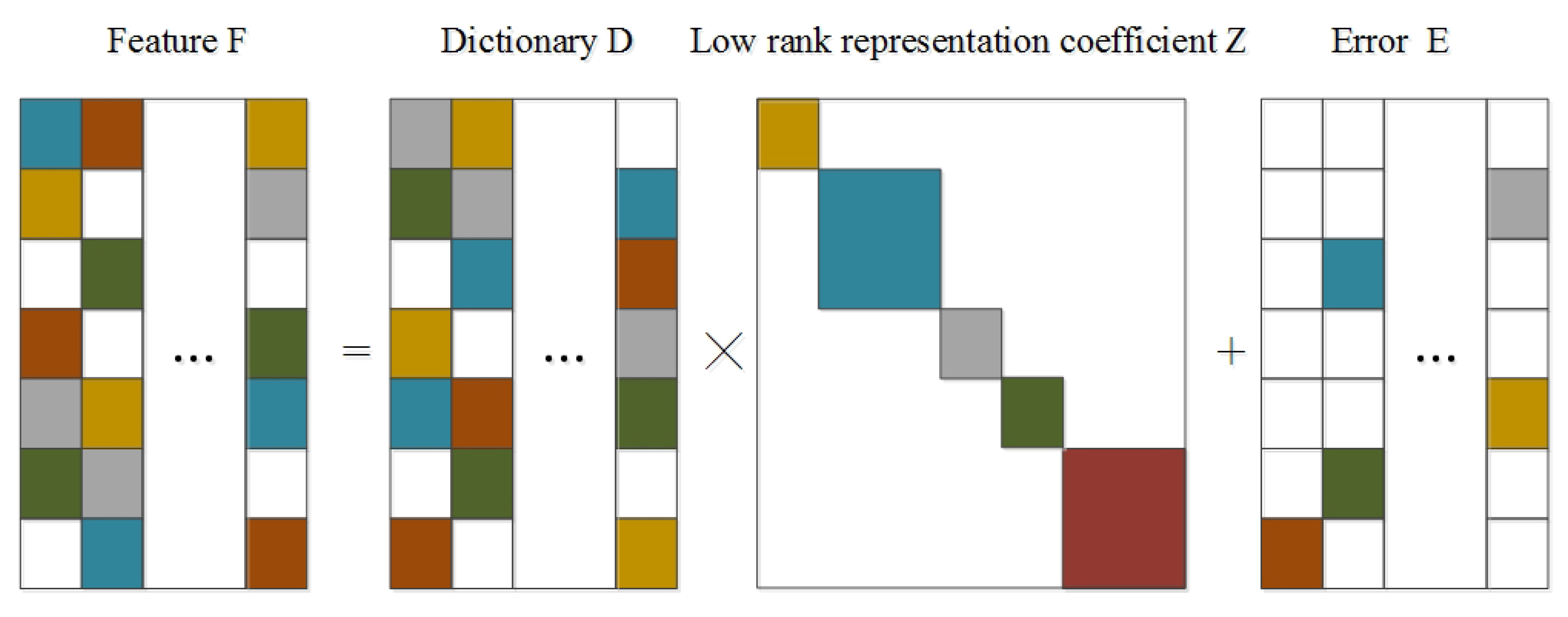
To mitigate these limitations, we present an effective low-rank representation based HSI classification framework. Inspired by the success of the stacked auto-encoder [
21] in unsupervised learning, we propose a novel unsupervised segmented stacked denoising auto-encoder-based feature learning model to extract the spatial-spectral characteristics of each pixel in the imagery with deep hierarchical structure. Then, a low-rank representation based classification strategy is developed to incorporate both the supervision information from labelled sample and the unsupervised low-rank property among unlabelled samples into a robust classifier. In the proposed framework, the deep structure of the segmented stacked denoising auto-encoder enables the learning of a complicated feature for each pixel. Moreover, the spatial-spectral setting further increases the representative power of the resulted feature. In the robust classifier, the intra-class similarity and inter-class dissimilarity among unlabelled samples are implicitly captured in classification by exploiting the low-rank property in their representation space, which improves the robustness of the classifier to various challenging cases. Both of these advantages lead to obvious improvements in HSI classification accuracy, especially when the labelled samples are limited. Experiments on two standard HSI classification datasets demonstrate the superiority of the proposed framework over several sate-of-the-art methods.
In general, this study mainly contributes in the following three aspects:
We propose a novel segmented stacked denoising auto-encoder-based spatial-spectral feature learning model.
We develop an effective low-rank representation based robust classifier.
We demonstrate state-of-the-art performance in HSI classification, especially when the labelled samples are limited.
The remainder of this paper is organised as follows. In
Section 2, we introduce the related work.
Section 3 gives the details of the proposed framework. The experimental results are reported in
Section 4. The study is discussed in
Section 5. Finally, a conclusion is provided in
Section 6.
2. Related Work
In this section, we will briefly review the existing feature learning methods and classifiers for HSI classification. Specifically, those feature learning methods can be divided into supervised methods and unsupervised methods.
Supervised feature learning method. A deep neural network (DNN) is a kind of machine learning method; the basic idea is to build a neural network model containing multiple hidden layers, which needs a large amount of training data to train the network model. There are already many supervised DNN methods [
12,
14,
15,
16,
17,
22,
23,
24,
25,
26]. In [
22], deep convolutional neural networks (DCNNs) are employed to classify HSIs directly in the spectral domain. In [
12], Zhang et al. proposed a dual-channel convolutional neural network-based spectral-spatial classification framework; in this article, a one-dimensional CNN is applied to extract the hierarchical spectral features and a two-dimensional CNN is used to extract the hierarchical spatial features, then a softmax regression classifier is used to combine the spectral and spatial features together and predict classification results. Because deeper neural networks are more difficult to train, in [
14], He et al. proposed the image recognition method based on deep residual network (ResNet) to deal with the difficulty of training in DNNs. In [
23], a ResNet is built for HSI classification. The back propagation neural network (BP) [
27,
28] is also a well-known supervised machine learning method, and it has been used in remote sensing image classification [
27] and handwritten digit recognition [
28]. However, as we all know, most of the supervised feature leaning methods need a large amount of labelled data to train the model, which is always unrealistic when there are only a small number of labelled samples available. Therefore, more and more scholars began to study unsupervised feature learning methods.
Unsupervised feature learning method. Transformation-based feature learning methods [
29,
30,
31,
32] map or transfer the original data from the high-dimensional data space into the low-dimensional feature space. The well-known transformation-based characteristics learning methods include principal component analysis (PCA), minimum noise fraction (MNF), etc. PCA [
32] can express data in minimum mean square error, but it will be influenced by noise. Therefore, Green et al. [
30] and Lee et al. [
31] proposed minimum noise separation methods, which arrange the components of the transformation according to the order of signal-to-noise ratio (SNR). Morphological profile-based methods (MPs) are also a kind of unsupervised feature learning method. MPs [
33,
34] with erosion and dilation operators can capture spatial structures in the images, leading to high classification accuracy. In [
33], Li et al. proposed a generalized composite kernel-based method (GCK); first the principal component analysis (PCA) is used to extract the principal components, then the extended multi-attribute morphological profiles (EMAPs) are used to extract spatial information, and lastly the multinomial logistic regression is utilized as the classifier. In addition, the stacked auto-encoder (SAE) is a well-known unsupervised deep feature learning method [
21,
35]. Considering that the spectrum of the HSI is high and has information redundancy, in order to fully excavate the spectral correlation and reduce the dimensionality, in [
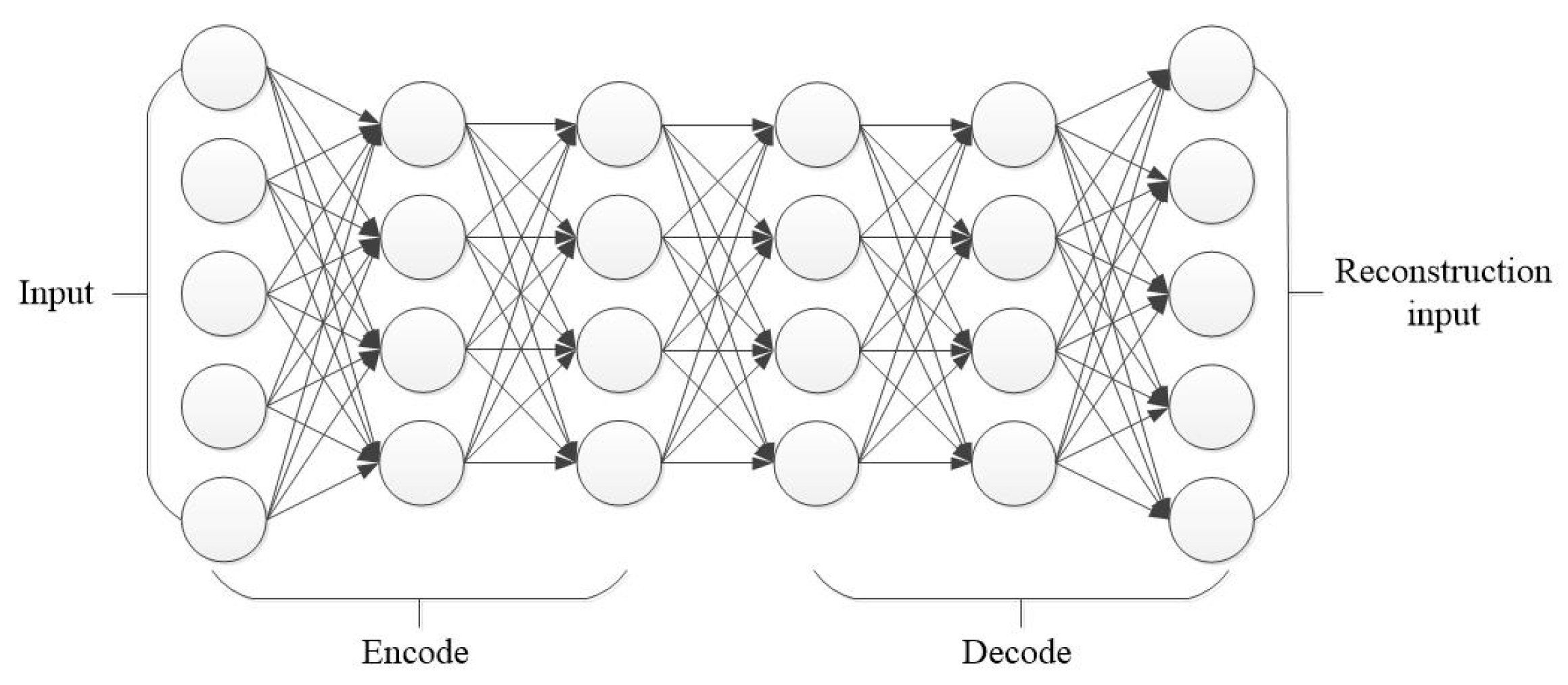
21], Zabalza et al. segment the spectral band into different groups and then use different SAE networks to extract the deep features. Unsupervised learning methods have achieved tremendous success, but most of these methods extract features with shallow structure, which limits the representation capacity of the models, so in this study, we extracted deep features with the stacked denoising auto-encoder (SDAE). After the features are extracted, we need a classifier to sign the feature to a certain class label.
Statistical learning-based classifier. Statistical learning is based on a statistical function; it uses the typical representative sample to complete the training of the classification model, lets the classification and recognition system learn the category characteristics, and then classifies according to the classification rules. K-nearest neighbor (KNN), K-means, and iterative self-organizing data analysis technique(ISODATA) are the most common statistical learning methods. In [
36], Guo et al. proposed the classification method based on the KNN; in this paper the good value
k is determined automatically. In [
37], Abbas et al. proposed the classification method based on K-means and ISODATA clustering algorithms. Spectrum matching-based methods directly match a spectrum with the known spectrum in the spectral library or the reference spectrum, then the spectrum is classified according to the matching result. The common methods include spectral encoding match, spectral correlation coefficient, spectral angle match, spectral information divergence method, etc. In [
38], Xu et al. proposed the spectral matching approach based on scale-invariant feature transform(SIFT). In [
39], Murphy et al. introduced the variable information into the spectral angle match to improve the classification accuracy. In [
40], Du et al. first applied spectral information divergence on the hyperspectral image classification; the similarity measure is the probability of spectral information divergence distribution between two pixels. When the spectral information divergence is smaller, the two pixels are more similar. In [
41], Baassou et al. combined the dispersion of spatial and spectral information to carry out high spectral image classification. Support vector machine (SVM) [
7,
42,
43,
44,
45,
46] is a typical kernel-based classification method; the basic idea is to map the originally indivisible feature space to the high-dimensional linear separable feature space by kernel function, so as to solve a non-linear classification problem by a linear classification method. Since the dimension of the original data has no effect on the size of the kernel matrix, the kernel function method can effectively deal with the high-dimensional data, thus avoiding the dimension disaster problem of the traditional pattern recognition methods. In addition, logistic regression (LR) [
47,
48,
49] uses the regression function to classify the features into one or multiple classes. These conventional methods can achieve classification tasks easily, but they consider the unlabelled samples independently and neglect the inter-class and intra-class property, which leads to these methods failing to gain robust classification results. Thus, representation based methods gain attention.
Representation based classifier. Representation based methods [
13,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61] implement the classification task by constructing a representation dictionary as a feature subspace and projecting the sample to the feature space, such that the sample is linearly represented by the dictionary atoms. In most cases, only a few of the representation coefficients is not zero, so we also call it a sparse representation based classifier. One class of broadly used representation based methods is structured sparse coding. In [
13,
57], a sparsity constraint (e.g.,
norm is used to depict the sparsity, and
norm is used to depict the convex) is always added onto a sparse coefficient in the structured sparse coding; there is always some other joint sparsity prior, such as the Laplacian prior. In [
50], Wen et al. proposed joint adaptive sparsity and a low-rankness-based online video denoising framework; in this work, the sparse of the vector and the low-rankness of the matrix are considered. Compared with traditional classifiers, representation based methods can better exploit data correlation; in this paper, we develop a classifier based on the representation learning.
4. Experiments and Results
4.1. Datasets
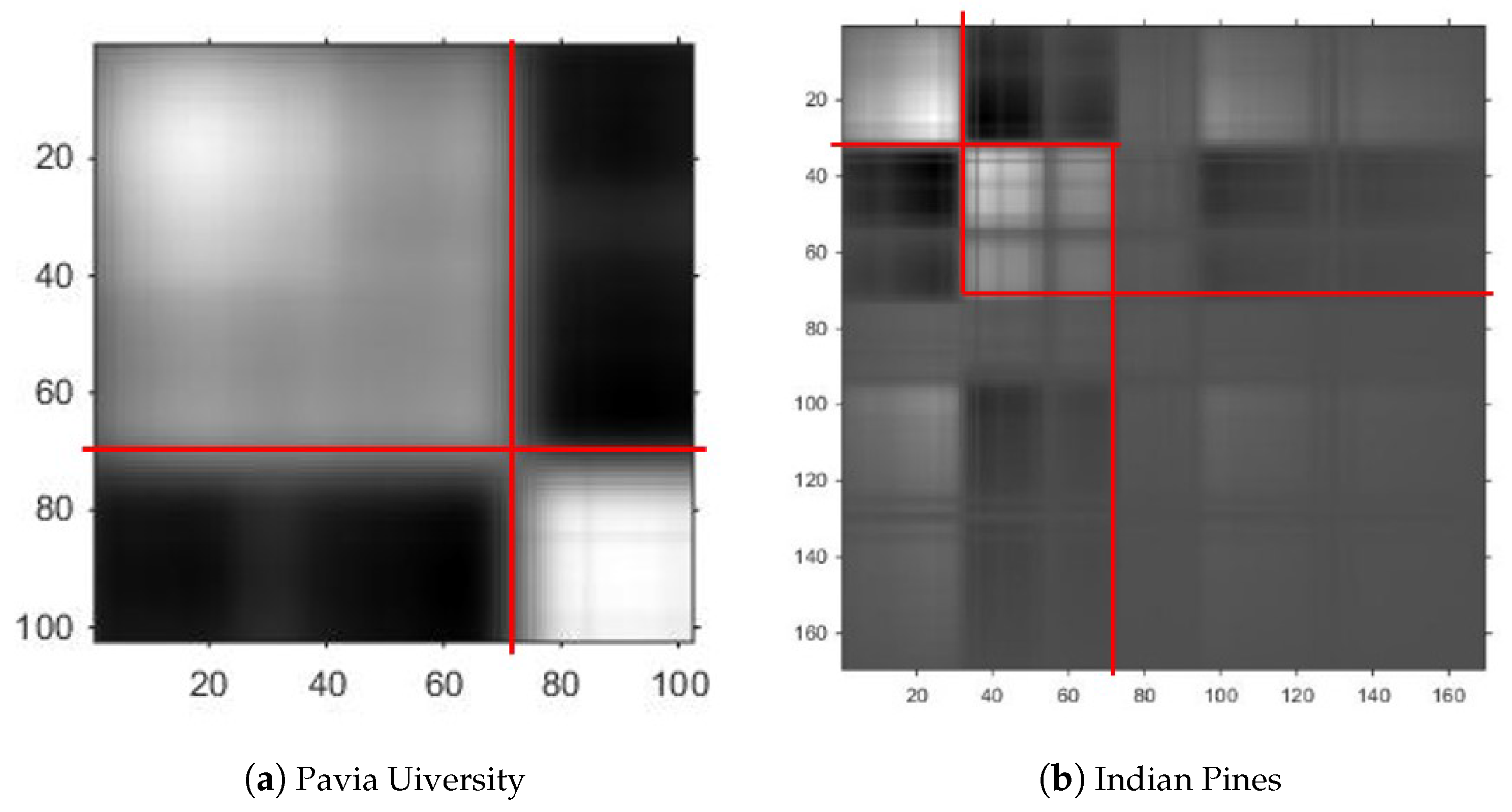
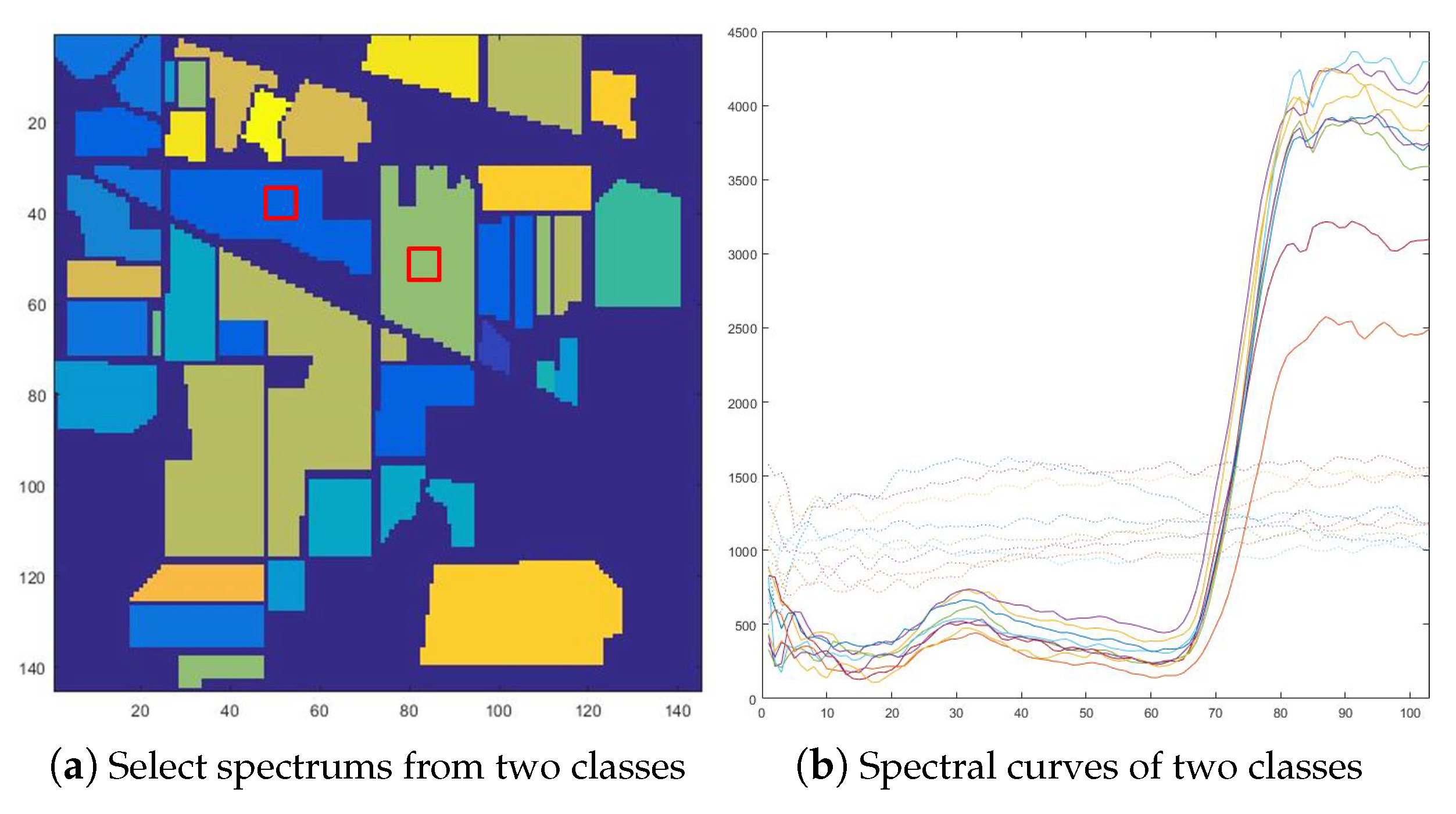
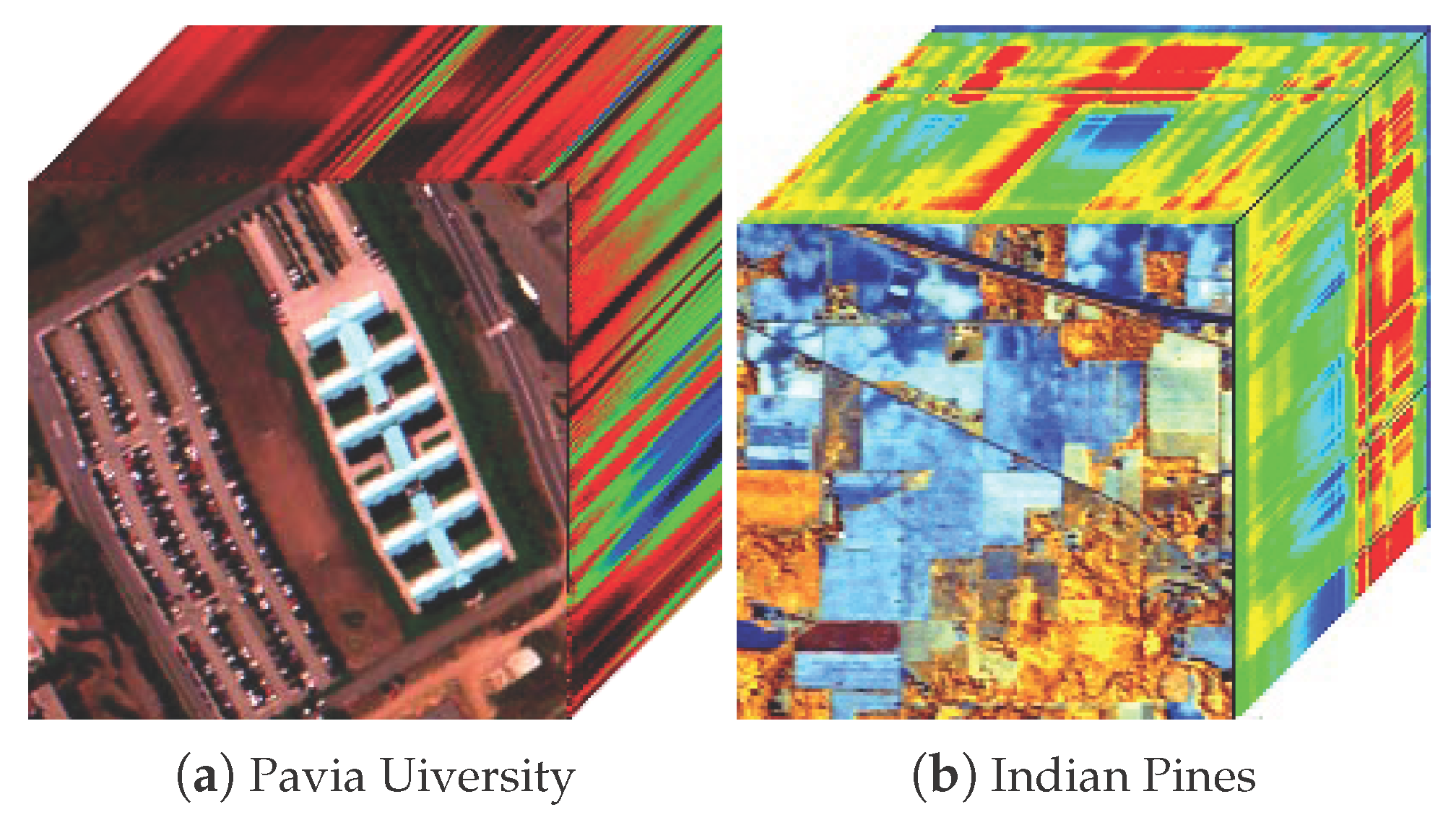
As
Figure 7, the Pavia University dataset was collected by the Reflective Optics System Imaging Spectrometer (ROSIS) sensor. The image scenes have 610 × 340 pixels, as collected by the German Aerospace Agency. The dataset has 103 spectral bands. It has a spectral coverage from 0.43 to 0.86 µm and a spatial resolution of 1.3 m. Approximately 42,776 labelled pixels with 9 classes are from the ground truth map, and the numbers of training and test samples are shown in
Table 1.
The Indian Pines dataset was gathered by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor in northwestern Indiana, USA. There are 145 × 145 pixels and 220 spectral channels, the spectral coverage from 0.4 to 2.45 µm including the visible and infrared spectral region with a spatial resolution of 20 m. From the statistical viewpoint, we discarded some classes which only have a few labelled samples and selected nine classes, for which the numbers of training and test samples are listed in
Table 2.
4.2. Comparison Methods
To demonstrate the superiority of the proposed method, we compared it with eight state-of-the-art classification methods on HSIs, including SVM [
42], Hu’s CNN [
22], ResNet [
23], SDAE-LR [
20], SSAE-SVM [
21], GCK [
33], and SSDAE-LRR. Among these methods, SVM, SSAE-SVM, GCK, and SSDAE-LRR adopt the unsupervised feature learning scheme, while the others employ an end-to-end training scheme to learn features from labelled samples. Specifically, SVM adopts the raw spectrum as the feature for each pixel. SDAE-LR utilizes the SDAE method to pretrain the network; in the top layer of the network, the logistic regression (LR) approach is utilized to perform supervised fine-tuning and classification. SSAE-SVM employs different SAE on segmented data to extract deep features. The difference from the proposed method is that SSAE-SVM only integrates the spectral information into features without considering the spatial information, and it adopts the SVM as the classifier. Similar to the proposed method, SSDAE-LRR uses different SDAE to extract features, and then a low-rank representation based classifier (LRR) is utilised to classify the feature; when the size
K of the neighbouring region is set as 1, the proposed method degrades into SSDAE-LRR.
In implementation, Hu’s CNN and GCK are trained with the codes published by authors, and the other methods are re-implemented by ourselves; the tuned parameters are adopted for best performance.
In the proposed method, the size K of the neighbouring region is set to 3. The number of encoding or decoding layers is changed from 3 to 6; the optimal selection of these parameters is set according to the real test data, the learning rate is 0.1, and the batch size is 20. The deep features that we obtained from Pavia University and Indian Pines were 50 and 20, respectively. Consider a given HSI X, which has s bands; when there are l encoding and decoding layers in the SDAE network, the number of neurons in each hidden layer is , respectively. Hence, the number of parameters is . For the Pavia University dataset, when training the SDAE network, the number of labelled samples is 1800 and unlabelled samples is 4000, the total parameters are 2.6 × 105 (1.5 × 105 and 1.1 × 105 for each segment). For the Indian Pines dataset, there are 1800 labelled samples and 4000 unlabelled samples used to train the network; the total parameters are 5 × 105 (0.5 × 105, 0.9 × 105, and 3.9 × 105 for each segment).
4.3. Evaluation Metric
To quantitatively evaluate the performance of all methods, we adopted three standard measuring criteria, namely overall accuracy (OA), average accuracy (AA), and KAPPA coefficient. OA denotes the classification accuracy on all testing samples, AA measures the average class-wise classification accuracy across all classes, and the KAPPA coefficient calculates the statistic degree of agreement in classification over the expected results, and is often normalized to 0 and 1. For each criterion, a larger score denotes a better classification result.
4.4. Comparison with State-of-the-Art Methods
In this part, we mainly focus on demonstrating the superiority of the proposed method in terms of classification accuracy over the other comparison methods. To this end, we conducted classification experiments on the two mentioned datasets. The number of training and testing samples are listed in
Table 1 and
Table 2. To reduce the effect of random sampling on the classification result, we report the average classification results for all methods across 10 rounds with different sampling results.
Table 3 and
Table 4 summarize the numerical classification results of all methods on two HSI datasets, where 200 labelled samples per class were used for training (a total of 1800 samples). We can find that the proposed method produced much higher classification accuracy than that of SVM. For example, on the Pavia University dataset, the proposed method outperformed SVM by 7.37% in OA. On the Indian Pines dataset, the proposed method outperformed SVM by 3.60% in OA. This demonstrates that the deeply learned feature performs better than the heuristically shallow feature. Moreover, the proposed method even outperformed the state-of-the-art supervised feature learning method with deep neural networks—Hu’s CNN and ResNet. This is because training deep neural networks with limited labelled samples is prone to becoming trapped in local minima, while the proposed unsupervised deep feature learning scheme have sufficient unlabelled samples for training. Compared with SDAE-LR, SSAE-SVM, and SSDAE-LRR, the proposed method improved the OA by 3.58%, 5.68%, and 2.93% on the Pavia University dataset, and the improvements to Indian Pines dataset was up to 3.36%, 5.22%, and 3.97%, respectively. On the Pavia University dataset and the Indian Pines dataset, GCK outperformed the proposed method by 0.57% and 4.75% in OA, respectively. However, in
Table 5 and
Table 6, when only 100 labelled samples were used for training, the proposed method outperformed GCK by 7.66% and 28.66% in OA on the Pavia University dataset and the Indian Pines dataset. We can conclude that the proposed method outperformed GCK in HSI classification with small labelled samples. These demonstrate the effectiveness of the spatial-spectral deep feature as well as the robust low-rank representation based classifier.
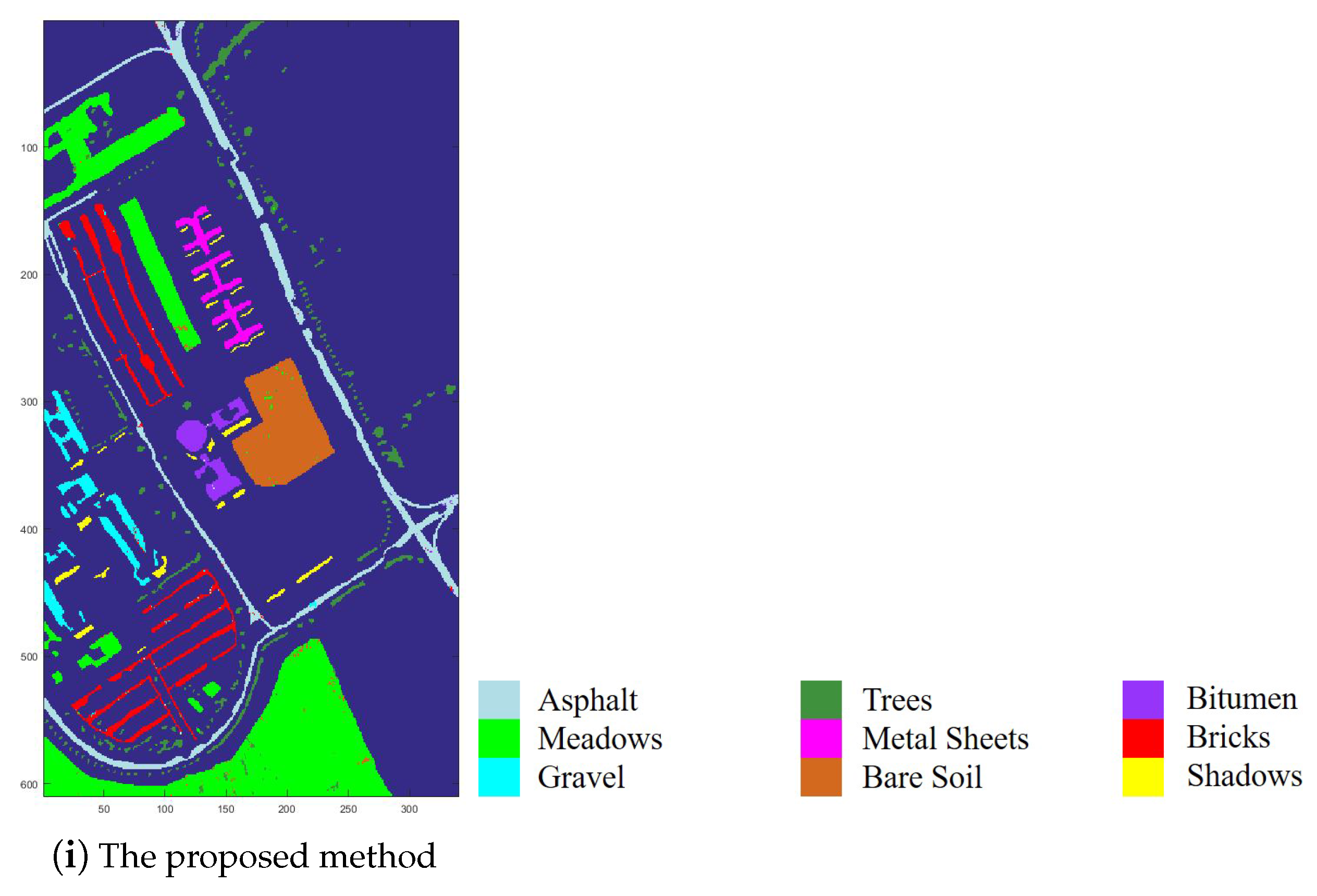
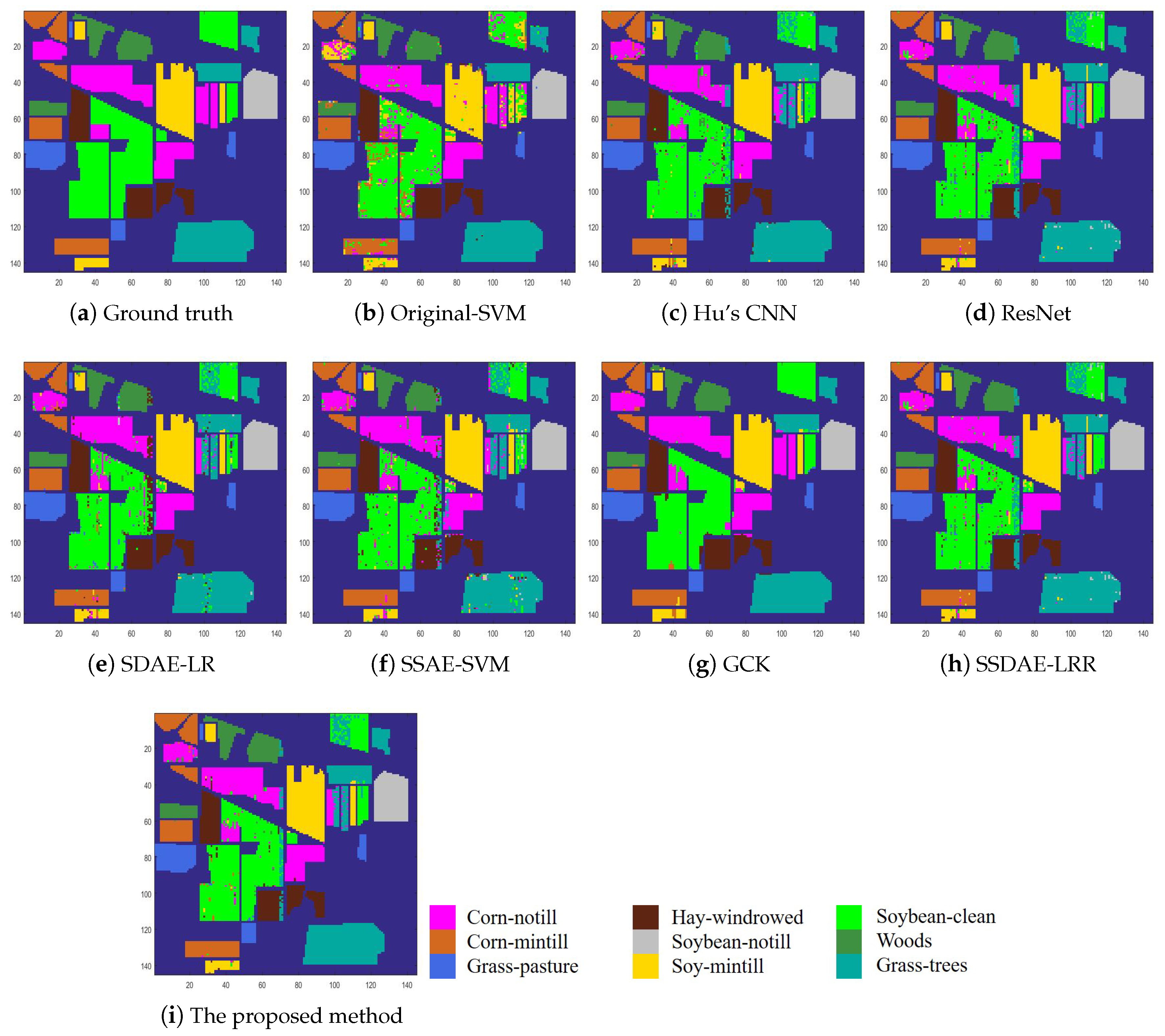
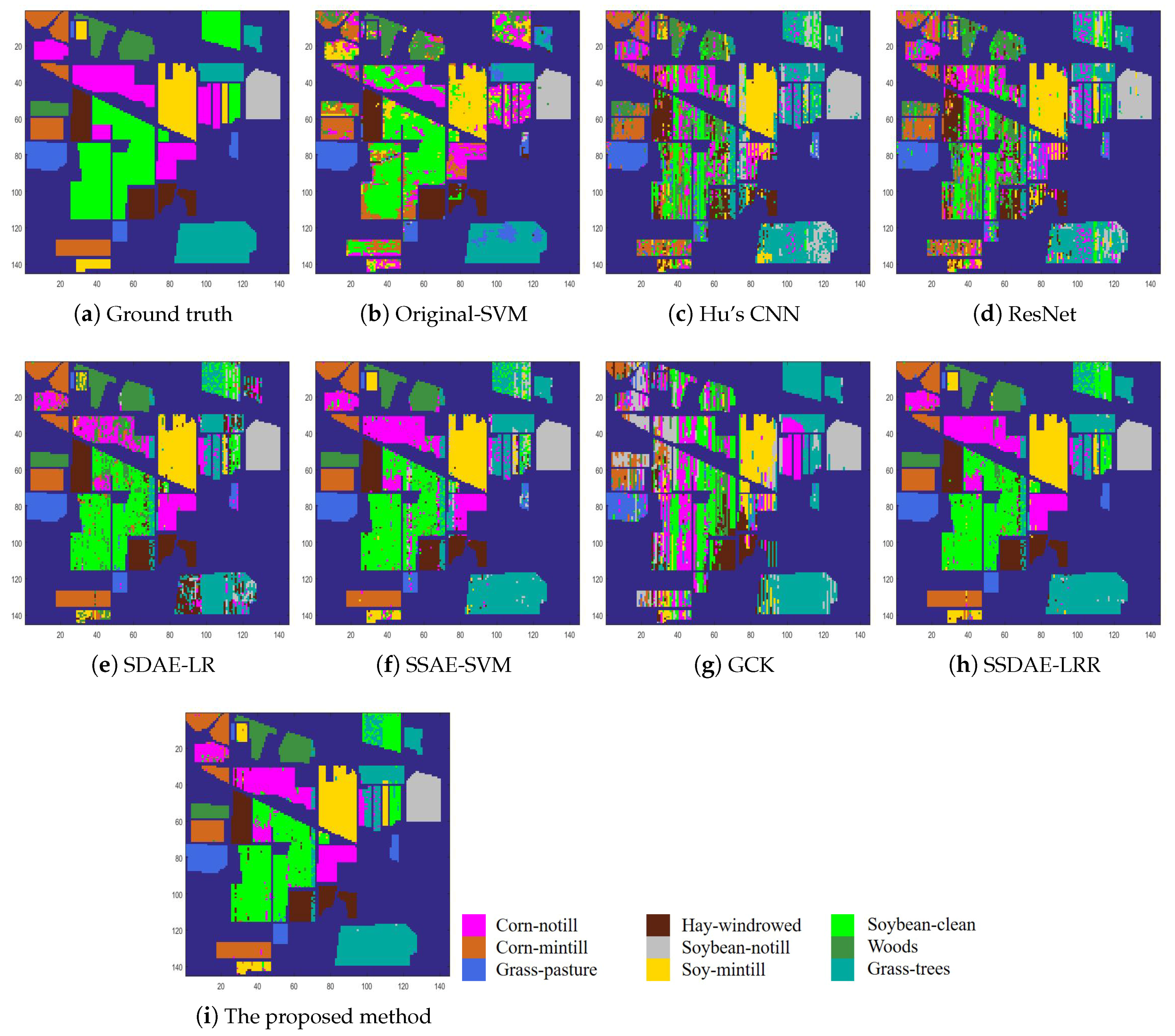
In order to further illustrate the superiority of the proposed method, we show the visual classification maps for all methods in
Figure 8,
Figure 9,
Figure 10 and
Figure 11. It can be seen that the proposed method shows more homogeneous results in each class than other comparison methods. This is because the proposed method depicts the intra-class similarity and inter-class dissimilarity among all samples well, with the robust classifier, while most of the comparison methods consider each unlabelled sample independently.
According to the results above, we can conclude that the proposed method outperformed the other 7 state-of-the-art comparison methods.
4.5. Effectiveness Verification
In this part, we conduct extensive experiments to validate the effectiveness of the proposed method in three respects. To verify the effectiveness of the deep spatial-spectral feature, we show the experiments of the proposed method and its three deep spatial-spectral feature-based variants in
Section 4.5.1; to demonstrate the effectiveness of the robust classifier, the details of the proposed method compared with its three variants based on the robust classifier are given in
Section 4.5.2; in
Section 4.5.3, the robustness to limited labelled samples is provided.
4.5.1. Effectiveness of the Deep Spatial-Spectral Feature
To demonstrate the effectiveness of the proposed deep spatial-spectral feature (i.e., segmented stacked denoising auto-encoder-based spatial-spectral feature), we compare the proposed method with its three variants, namely Hu’s CNN-LRR, SDAE-LRR, and SSDAE-LRR. Similar to the proposed method, the low-rank representation based classifier (LRR) is adopted by those three variants. In contrast, Hu’s CNN-LRR adopts the supervised learned feature in comparison to Hu’s CNN, SDAE-LRR employs the feature learned by SDAE without segmentation and spatial-spectral setting, while SSDAE-LRR utilizes the feature learned by segmented SDAE without spatial-spectral setting.
With the same experimental setting as
Section 4.2, the comparison results of all these methods on two datasets are provided in
Table 1 and
Table 2. It can be seen that the proposed method outperformed all the other variants in all cases. For example, on the Pavia University dataset, the proposed method outperformed those variants by at least 2.93% in OA, 2.51% in AA, and 2.80% in KAPPA. The superiority over Hu’s CNN-LRR demonstrates that the proposed deep spatial-spectral feature performed even better than the supervised learned feature. The superiority over SSDAE-LRR verifies that the spatial-spectral setting can further improve the representative capacity of HSI. The superiority of SSDAE-LRR over SDAE-LRR illustrates the effectiveness of the band segmentation, which is similar to the conclusion in [
21].
In general, the proposed deep spatial-spectral feature is effective for HSI classification.
4.5.2. Effectiveness of the Robust Classifier
To verify the effectiveness of the low-rank representation based classifier (LRR), we compare the proposed method with three variants, including SSDAESS-SVM, SSDAESS-LR and SSDAESS-OMP. For fair comparison, these three variants employ the same segmented SDAE spatial-spectral feature (denoted as SSDAESS) to characterize the unlabelled samples. The only difference from the proposed method is that they adopt different classifiers. In particular, SSDAESS-SVM and SSDAESS-LR adopt the SVM and LR as the classifiers, respectively. In contrast to those two statistical learning-based classifiers, SSDAESS-OMP adopts the sparse representation based classifier, which is implemented by the classical sparse coding method, orthogonal matching pursuit (OMP).
Under the same experimental settings as
Section 4.2, the comparison results on two datasets are summarized in
Table 7. It can be seen that the proposed method obviously outperformed these three variants in all cases. Taking the Indian Pines dataset as an example, the proposed method surpassed these variants by at least 0.83% in AA, 1.20% in OA, and 1.21% in KAPPA. With the exception of the supervision provided by the labelled samples, SSDAESS-OMP also considers the similarity between the labelled samples and the unlabelled one which belong to the same class; because of this, it performed better than SSDAESS-SVM and SSDAESS-LR. However, SSDAESS-OMP considers each unlabelled sample independently; viz., it fails to utilize the crucial intra-class similarity as well as the inter-class dissimilarity among those unlabelled samples as the proposed method, which limits its performance.
The experimental results above demonstrate that the proposed robust classifier is effective for HSI classification.
4.5.3. Robustness to Llimited Labelled Samples
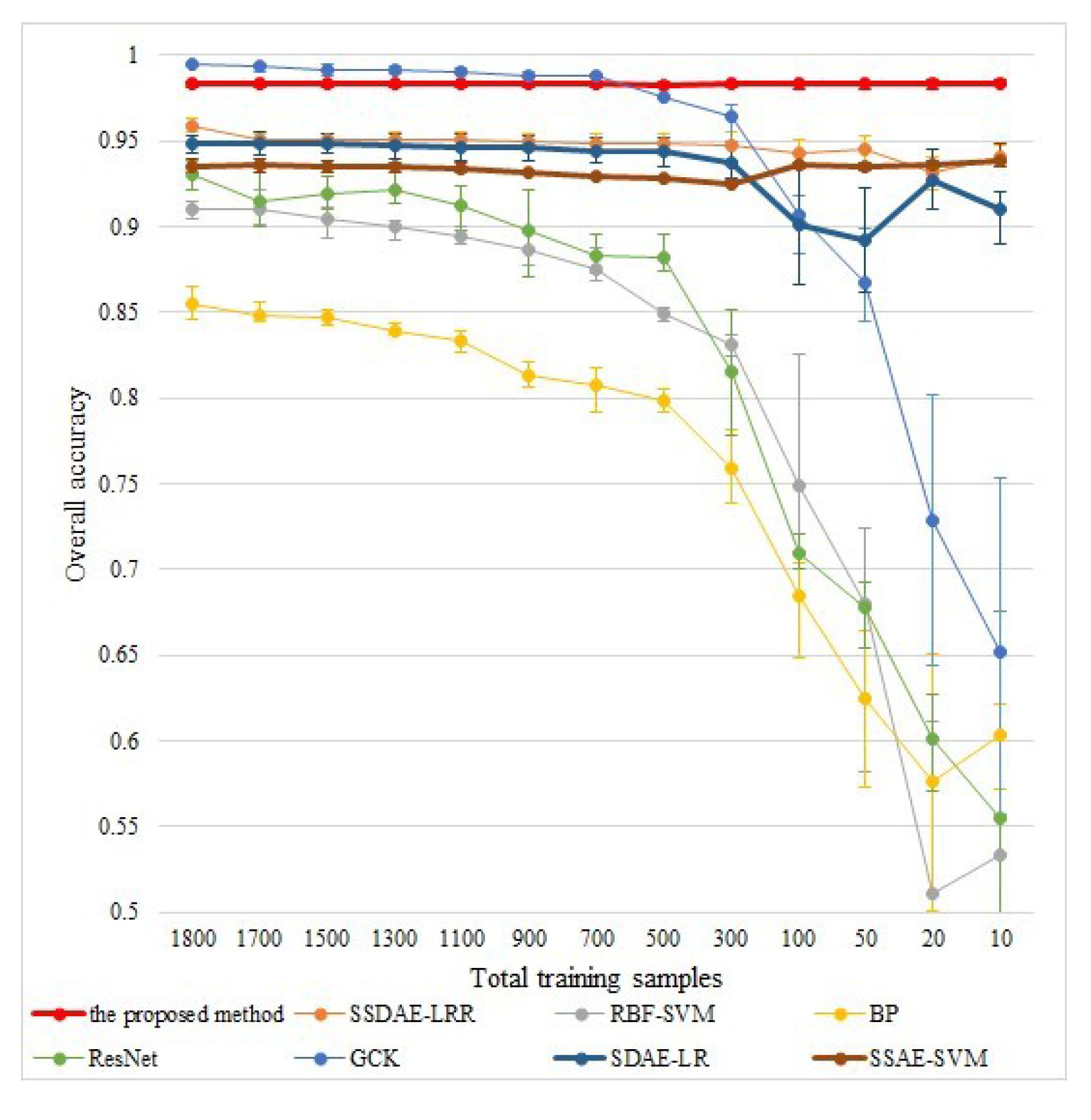
Finally, to further demonstrate the potential of the proposed method in dealing with limited labelled samples, we compare the proposed method with seven state-of-the-art methods (namely SSDAE-LRR, RBF-SVM, BP [
27], ResNet, GCK, SDAE-LR, and SSAE-SVM) on two datasets with different numbers of labelled samples.
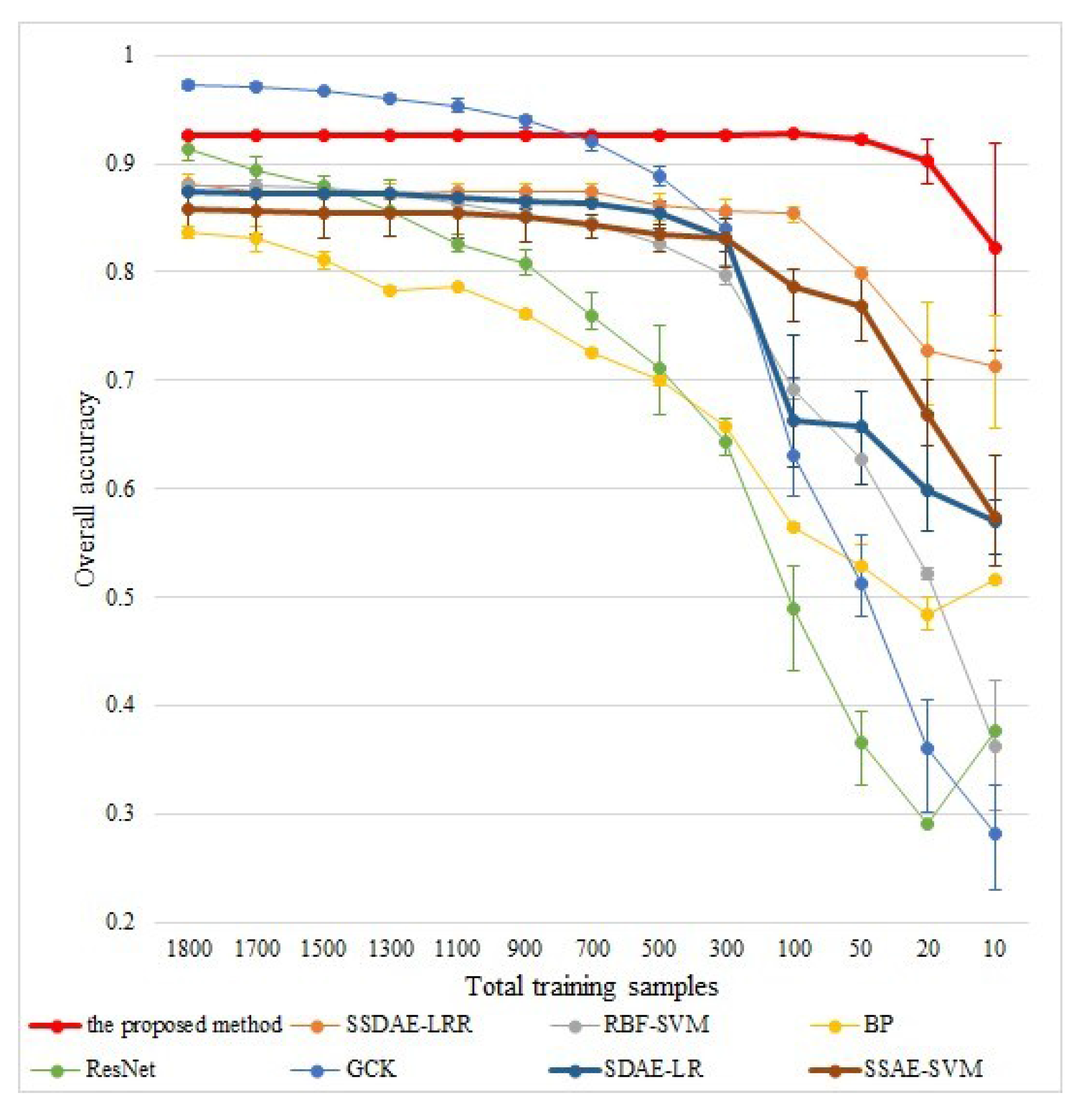
When the total number of the labelled samples ranges from 10 to 1800 (we balanced the number of samples in each class as much as possible), the classification results for all methods on two datasets are shown in
Figure 12 and
Figure 13. In
Figure 12, we can find that when the total labelled samples were more than 900 (samples per class were more than 100), the classification accuracy for all methods was still over 81%, and the proposed method was comparable to GCK. When the total number of labelled samples decreased below 900 (samples per class were less than 100), the performances of RBF-SVM, BP, ResNet, and GCK dropped sharply. Similar phenomena can also be observed in
Figure 13. This demonstrates that both supervised-learned features and unsupervised-learned shallow features are sensitive to the amount of labelled samples. In contrast, the proposed method preserved its performance well, even when the total number of labelled samples was 10 (one sample per class), as shown in
Figure 12; on the Pavia University dataset, the overall accuracy was 98.40%, and the performances of SSDAE-LRR, SDAE-LR, and SSAE-SVM dropped slightly. These demonstrate that both the unsupervised-learned deep features performed robustly to the limited labelled sample; although SDAE-LR is an supervised method, it can utilise more unlabelled information in the training phase. Since the proposed SSDAE feature further considers the spatial information as well as embedding it into a robust classifier, the proposed method outperformed SSDAE-LRR in all cases. Moreover, the superiority was increased when the total number of labelled samples dropped, especially in
Figure 13.
Therefore, we can conclude that the proposed method is effective for HSI classification with limited labelled samples.
5. Discussion
In this paper, a low-rank representation based HSI classification framework is proposed. The experimental results above demonstrate the effectiveness of the proposed method, especially when the labelled samples are limited.
According to the results of the experiments, it can be seen that when the number of labelled samples is fixed as in
Table 3 and
Table 4, the proposed method not only obviously surpassed SVM which with shallow structure, but also even outperforms the state-of-the-art supervised feature learning methods with deep neural networks (e.g., Hu’s CNN and ResNet). The reason for this comes from two aspects.
On one hand, the proposed method adopts the SSDAE framework to allow features to be learned unsupervised with a deep hierarchical structure, which enables the resulting features to be much more representative than the shallow features which were heuristically learned by those unsupervised feature learning-based methods. Although Hu’s CNN and ResNet also adopt the deeply learned features, their supervised feature learning scheme is prone to being trapped in local minima (i.e., over-fitting), especially when the labelled samples are limited. Meanwhile, the proposed unsupervised deep feature learning scheme has sufficient unlabelled samples for training.
On the other hand, all of the methods compared herein establish their classifiers based only on the supervision provided by the labelled samples, while the proposed method incorporates the supervision as well as the crucial unsupervision (i.e., inter-class similarity and inter-class dissimilarity) provided by unlabelled samples into a robust classifier.
In addition, the proposed method obviously outperformed two sets of variants—one set with different features as in
Table 8, and the other with different classifiers as in
Table 7. This demonstrates that both the proposed deep unsupervised feature learning scheme and the robust classification are crucial for HSIs classification. Finally, with a variable number of labelled samples, the stable superiority of the proposed method over the compared methods demonstrates the effectiveness of the proposed method in addressing HSIs classification with limited labelled samples.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}