
Seg-Road: A Segmentation Network for Road Extraction Based on Transformer and CNN with Connectivity Structures


 , , ,
, , ,
Abstract
:
1. Introduction
- (1)
- By comparing existing models, this article proposes the Seg-Road, which achieves state-of-the-art (SOTA) performance on the DeepGlobe dataset, with an IoU of 67.20%. Furthermore, Seg-Road also achieves an IoU of 68.38% on the Massachusetts dataset.
- (2)
- (3)
- This paper proposes the use of PCS for improving the fragmentation of road segmentation in remote sensing images and analyses the general shortcomings of the current model and future research directions.
2. Data and Methods
2.1. Data Collection
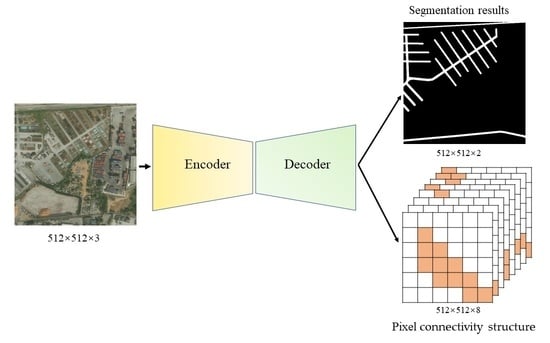
2.2. Seg-Road Model
2.2.1. Encoder
2.2.2. Decoder
- (1)
- The distance to initialize the pixel spacing is r; the connected label element values are initialized as 0, and the shape is 8 × H × W, where 8 represents the current pixel point of 8 orientation numbers.
- (2)
- From the first pixel in the upper left corner, the current pixel point and the upper left bit pixel point with distance r are determined according to the principle of left-to-right and top-to-bottom; if both of them are road target pixels, the label of the current pixel point is recorded as 1.
- (3)
- Repeat step (2) and traverse through 8 directions (top left, top, top right, left, right, bottom left, and bottom right) to obtain 8×H×W feature labels, which represent the connectivity relationships of 8 directions. This will help mitigate the fragmentation issue of road segmentation in remote sensing images.
2.2.3. Loss
2.2.4. Seg-Road Inference
3. Experiments and Results Analysis
3.1. Experimental Parameters
3.2. Experimental Evaluation Indexes
3.3. Evaluation of Experimental Effects
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


References
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Dong, J.; Wang, N.; Fang, H.; Hu, Q.; Zhang, C.; Ma, B.; Ma, D.; Hu, H. Innovative Method for Pavement Multiple Damages Segmentation and Measurement by the Road-Seg-CapsNet of Feature Fusion. Constr. Build. Mater. 2022, 324, 126719. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Mattyus, G.; Wang, S.; Fidler, S.; Urtasun, R. Enhancing Road Maps by Parsing Aerial Images around the World. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road Network Extraction: A Neural-Dynamic Framework Based on Deep Learning and a Finite State Machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Yu, Z.; Chang, R.; Chen, Z. Automatic Detection Method for Loess Landslides Based on GEE and an Improved YOLOX Algorithm. Remote Sens. 2022, 14, 4599. [Google Scholar] [CrossRef]
- Yu, Z.; Chen, Z.; Sun, Z.; Guo, H.; Leng, B.; He, Z.; Yang, J.; Xing, S. SegDetector: A Deep Learning Model for Detecting Small and Overlapping Damaged Buildings in Satellite Images. Remote Sens. 2022, 14, 6136. [Google Scholar] [CrossRef]
- Mosinska, A.; Marquez-Neila, P.; Kozinski, M.; Fua, P. Beyond the Pixel-Wise Loss for Topology-Aware Delineation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; Dewitt, D. RoadTracer: Automatic Extraction of Road Networks from Aerial Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-Linknet: Linknet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tan, Y.Q.; Gao, S.H.; Li, X.Y.; Cheng, M.M.; Ren, B. Vecroad: Point-Based Iterative Graph Exploration for Road Graphs Extraction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Vasu, S.; Kozinski, M.; Citraro, L.; Fua, P. TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation. In Proceedings of the Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Mei, J.; Li, R.J.; Gao, W.; Cheng, M.M. CoANet: Connectivity Attention Network for Road Extraction from Satellite Imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, K.; Jiao, L. CSANet: Cross-Scale Axial Attention Network for Road Segmentation. Remote Sens. 2022, 15, 3. [Google Scholar] [CrossRef]
- Liu, Z.; Yeoh, J.K.W.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic Pixel-Level Detection of Vertical Cracks in Asphalt Pavement Based on GPR Investigation and Improved Mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Yuan, W.; Xu, W. GapLoss: A Loss Function for Semantic Segmentation of Roads in Remote Sensing Images. Remote Sens. 2022, 14, 2422. [Google Scholar] [CrossRef]
- Sun, J.; Li, Y. Multi-Feature Fusion Network for Road Scene Semantic Segmentation. Comput. Electr. Eng. 2021, 92, 107155. [Google Scholar] [CrossRef]
- Lian, R.; Huang, L. DeepWindow: Sliding Window Based on Deep Learning for Road Extraction from Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1905–1916. [Google Scholar] [CrossRef]
- Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sens. 2022, 14, 3892. [Google Scholar] [CrossRef]
- Tardy, H.; Soilán, M.; Martín-Jiménez, J.A.; González-Aguilera, D. Automatic Road Inventory Using a Low-Cost Mobile Mapping System and Based on a Semantic Segmentation Deep Learning Model. Remote Sens. 2023, 15, 1351. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, C.; Li, J.; Xie, N.; Han, Y.; Du, J. Reconstruction Bias U-Net for Road Extraction from Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2284–2294. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Chen, Z.; Chang, R.; Pei, X.; Yu, Z.; Guo, H.; He, Z.; Zhao, W.; Zhang, Q.; Chen, Y. Tunnel Geothermal Disaster Susceptibility Evaluation Based on Interpretable Ensemble Learning: A Case Study in Ya’an–Changdu Section of the Sichuan–Tibet Traffic Corridor. Eng. Geol. 2023, 313, 106985. [Google Scholar] [CrossRef]
- Singh, S.; Batra, A.; Pang, G.; Torresani, L.; Basu, S.; Paluri, M.; Jawahar, C.V. Self-Supervised Feature Learning for Semantic Segmentation of Overhead Imagery. In Proceedings of the British Machine Vision Conference 2018, BMVC 2018, Newcastle, UK, 3–6 September 2019. [Google Scholar]
- Chen, D.; Zhong, Y.; Zheng, Z.; Ma, A.; Lu, X. Urban Road Mapping Based on an End-to-End Road Vectorization Mapping Network Framework. ISPRS J. Photogramm. Remote Sens. 2021, 178, 345–365. [Google Scholar] [CrossRef]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.V.; Paluri, M. Improved Road Connectivity by Joint Learning of Orientation and Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xie, Y.; Zhang, J.; Shen, C.; Xia, Y. CoTr: Efficiently Bridging CNN and Transformer for 3D Medical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention—MICCAI 2021, Strasbourg, France, 27 September–1 October 2021. Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). [Google Scholar]
- Fang, J.; Lin, H.; Chen, X.; Zeng, K. A Hybrid Network of CNN and Transformer for Lightweight Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1103–1112. [Google Scholar]
- Pinto, F.; Torr, P.H.; Dokania, P.K. An impartial take to the cnn vs transformer robustness contest. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–24 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 466–480. [Google Scholar]
- Chen, J.; Chen, X.; Chen, S.; Liu, Y.; Rao, Y.; Yang, Y.; Wang, H.; Wu, D. Shape-Former: Bridging CNN and Transformer via ShapeConv for multimodal image matching. Inf. Fusion 2023, 91, 445–457. [Google Scholar] [CrossRef]
- Kitaev, N.; Kaiser, A.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Rao, R.M.; Liu, J.; Verkuil, R.; Meier, J.; Canny, J.; Abbeel, P.; Sercu, T.; Rives, A. Msa transformer. In Proceedings of the International Conference on Machine Learning: PMLR, Online, 18–24 July 2021; pp. 8844–8856. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Weng, Y.; Zhou, T.; Li, Y.; Qiu, X. NAS-Unet: Neural Architecture Search for Medical Image Segmentation. IEEE Access 2019, 7, 44247–44257. [Google Scholar] [CrossRef]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-Deeplab: Hierarchical Neural Architecture Search for Semantic Image Segmentation. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. Max-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raska, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yan, H.; Zhang, C.; Yang, J.; Wu, M.; Chen, J. Did-Linknet: Polishing D-Block with Dense Connection and Iterative Fusion for Road Extraction. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2186–2189. [Google Scholar]
- Wang, Y.; Seo, J.; Jeon, T. NL-LinkNet: Toward Lighter but More Accurate Road Extraction with Nonlocal Operations. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Mattyus, G.; Luo, W.; Urtasun, R. DeepRoadMapper: Extracting Road Topology from Aerial Images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yan, L.; Liu, D.; Xiang, Q.; Luo, Y.; Wang, T.; Wu, D.; Chen, H.; Zhang, Y.; Li, Q. PSP Net-Based Automatic Segmentation Network Model for Prostate Magnetic Resonance Imaging. Comput. Methods Programs Biomed. 2021, 207, 106211. [Google Scholar] [CrossRef]
- Chen, Z.; Chang, R.; Zhao, W.; Li, S.; Guo, H.; Xiao, K.; Wu, L.; Hou, D.; Zou, L. Quantitative Prediction and Evaluation of Geothermal Resource Areas in the Southwest Section of the Mid-Spine Belt of Beautiful China. Int. J. Digit. Earth 2022, 15, 748–769. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Fang, H.; Lafarge, F. Pyramid Scene Parsing Network in 3D: Improving Semantic Segmentation of Point Clouds with Multi-Scale Contextual Information. ISPRS J. Photogramm. Remote Sens. 2019, 154, 246–258. [Google Scholar] [CrossRef] [Green Version]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the NAACL HLT 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, New Orleans, LA, USA, June 2018. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Gibbons, F.X. Self-Attention and Behavior: A Review and Theoretical Update. Adv. Exp. Soc. Psychol. 1990, 23, 249–303. [Google Scholar] [CrossRef]
- Chen, Z.; Chang, R.; Guo, H.; Pei, X.; Zhao, W.; Yu, Z.; Zou, L. Prediction of Potential Geothermal Disaster Areas along the Yunnan–Tibet Railway Project. Remote Sens. 2022, 14, 3036. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as Deep: Spatial CNN for Traffic Scene Understanding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The ApolloScape Open Dataset for Autonomous Driving and Its Application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2702–2719. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Range |
|---|---|
| Input size | 512 × 512 |
| Activation | ReLU |
| Optimizer | Adam |
| Segmentation loss | Cross entropy |
| PCS loss | Binary cross entropy |
| Dropout | 0.2 |
| PSC-r | 2 |
| Seg-Road-s | Seg-Road-m | Seg-Road-l | |
|---|---|---|---|
| Parameters(Mb) | 4.18 | 14.12 | 28.67 |
| FPS | 98 | 81 | 42 |
| Model | MIoU (%) | F1 (%) | Precision (%) | Recall (%) | FPS | |
|---|---|---|---|---|---|---|
| D-LinkNet [11] | 57.62 | 63.00 | 77.11 | 76.69 | 77.53 | 96 |
| DeepRoadMapper [42] | 58.06 | 64.38 | 78.04 | 77.21 | 78.89 | 36 |
| RoadCNN [10] | 59.12 | 65.49 | 79.08 | 78.14 | 80.04 | 72 |
| PSPNet [45] | 58.94 | 65.99 | 79.20 | 77.90 | 80.54 | 75 |
| LinkNet34 [40] | 58.26 | 66.21 | 79.65 | 77.63 | 81.78 | 105 |
| CoANet [14] | 59.11 | 69.42 | 81.22 | 78.96 | 83.61 | 61 |
| CoANet-UB [14] | 63.36 | 80.69 | 89.25 | 86.54 | 92.13 | 40 |
| Seg-Road-s | 61.14 | 78.49 | 87.67 | 86.45 | 88.93 | 109 |
| Seg-Road-m | 64.31 | 80.64 | 89.41 | 86.56 | 92.45 | 81 |
| Seg-Road-l | 67.20 | 82.06 | 91.43 | 90.05 | 92.85 | 42 |
| Model | MIoU (%) | F1 (%) | Precision (%) | Recall (%) | FPS | |
|---|---|---|---|---|---|---|
| D-LinkNet [11] | 61.45 | 75.72 | 80.61 | 78.77 | 82.53 | 96 |
| DeepRoadMapper [42] | 59.66 | 72.21 | 76.39 | 75.71 | 77.09 | 36 |
| RoadCNN [10] | 62.54 | 78.74 | 81.37 | 79.80 | 83.02 | 72 |
| PSPNet [45] | 58.91 | 72.23 | 75.22 | 74.37 | 76.09 | 75 |
| LinkNet34 [40] | 61.35 | 75.87 | 80.17 | 78.77 | 81.63 | 105 |
| CoANet [14] | 61.67 | 76.42 | 81.56 | 78.53 | 84.85 | 61 |
| CoANet-UB [14] | 64.96 | 80.92 | 88.67 | 85.37 | 92.24 | 40 |
| Seg-Road-s | 64.78 | 80.54 | 88.41 | 85.56 | 91.45 | 109 |
| Seg-Road-m | 66.29 | 81.48 | 89.23 | 86.84 | 91.76 | 81 |
| Seg-Road-l | 68.38 | 83.89 | 90.02 | 87.34 | 92.86 | 42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, J.; Chen, Z.; Sun, Z.; Guo, H.; Leng, B.; Yu, Z.; Wang, Y.; He, Z.; Lei, X.; Yang, J. Seg-Road: A Segmentation Network for Road Extraction Based on Transformer and CNN with Connectivity Structures. Remote Sens. 2023, 15, 1602. https://doi.org/10.3390/rs15061602
Tao J, Chen Z, Sun Z, Guo H, Leng B, Yu Z, Wang Y, He Z, Lei X, Yang J. Seg-Road: A Segmentation Network for Road Extraction Based on Transformer and CNN with Connectivity Structures. Remote Sensing. 2023; 15(6):1602. https://doi.org/10.3390/rs15061602
Chicago/Turabian StyleTao, Jingjing, Zhe Chen, Zhongchang Sun, Huadong Guo, Bo Leng, Zhengbo Yu, Yanli Wang, Ziqiong He, Xiangqi Lei, and Jinpei Yang. 2023. "Seg-Road: A Segmentation Network for Road Extraction Based on Transformer and CNN with Connectivity Structures" Remote Sensing 15, no. 6: 1602. https://doi.org/10.3390/rs15061602