1. Introduction
With the rapid development of urbanization processes, maps used to illustrate buildings and their distribution are significant and are required in a wide range of fields. Important applications include environmental monitoring, resource management, disaster response, and homeland security [
1]. In urban areas, accurate maps are often available; however, this is not always the case for villages and there may be no digital version available, which has several negative consequences. For instance, during catastrophic events such as the Wenchuan earthquake in 2008, disaster relief could not be conveniently provided due to inadequate rural information and because the location of residential buildings was uncertain, which resulted in serious loss of life and property [
2]. A swift update of building information is very important and essential during catastrophes [
3] because secondary disasters such as tsunamis, avalanches, and landslides may follow [
4], causing swift changes to land conditions. In rural planning, which aims to benefit the inhabitants, public facilities need to be developed on the basis of the residential buildings’ distribution information [
5]. To solve such complicated problems, the tools used to identify buildings must provide rapid, accurate, efficient, and time-sequenced results.
With the help of remote sensing satellite images [
6,
7,
8], earth-observation activities on regional to global scales can be implemented owing to advantages such as wide spatial coverage and high temporal resolution [
9,
10]. Most previous studies that focus on village mapping commonly use low- and medium-spatial resolution images such as Landsat Thematic Mapper (TM), The Enhanced Thematic Mapper Plus (ETM+), and National Oceanic and Atmospheric Administration (NOAA)/ Advanced Very High Resolution Radiometer (AVHRR) [
11,
12,
13], whereas in recent years, high-resolution images such as QuickBird, Ikonos, and RapidEye facilitate high-accuracy identification. Unfortunately, considering the high cost of data acquisition, these high-resolution images are generally utilized in a specific small region and are rarely applied in large ones [
14].
A promising alternative solution is offered by Google Earth (GE), which provides open, highly spatially resolved images suitable for village mapping [
15,
16,
17,
18]. However, GE images have rarely been used as the main data source in village mapping. GE images are limited to a three-band color code (R, G, and B), which is expected to lower the classification performance due to its poor spectral signature [
19]. Actually, the potential for the classification of spatial characteristics by Google Maps has been underestimated [
20]. By analyzing the tone, texture, and geometric features in a GE image [
18,
21], experts can recognize village buildings with high confidence. Consequently, we believe that GE images can provide a good data source for village mapping.
In terms of classification technique, many methods have been studied by consulting published literature. With the help of image processing and feature extraction techniques, various machine learning algorithms [
22] in remote sensing have been implemented. The AdaBoost method [
23] is widely used in remote sensing pattern recognition. For instance, Zhang
et al. [
24] combine the K-means method with AdaBoost to classify buildings, and the overall accuracy is about 90%. Zongur
et al. [
25] utilize satellite images to detect an airport runway using AdaBoost with a circular-Mellin feature. Using an improved Normalized Difference Build-up Index (NDBI) and remote sensing images, Li
et al. [
26] dynamically extract urban land. Cetin
et al. [
27] use textural features such as the mean and standard deviation of image intensity and gradient for building detection. In the field of remote sensing detection, using the convolutional neural networks (CNN) method [
28], Chen
et al. [
29] address vehicle detection, Li
et al. [
30] focus on building pattern classifiers, and Yue
et al. [
31] use both spectral and spatial features for hyperspectral image classification. To predict geoinformative attributes from large-scale images, Lee
et al. [
32] also choose CNN, and Sermanet
et al. [
33] utilize the CNN method to identify house numbers. In high-resolution image processing, Hu
et al. [
34] solved scene classification tasks using CNN and achieved an overall accuracy of approximately 98%. Other machine learning methods such as support vector machines (SVM) [
35], which maximizes the margin in high-dimensional feature spaces using kernel methods for the samples, are introduced for classification. For the identification of forested landslides, Dou
et al. [
36] utilize a case-based reasoning approach and Li
et al. [
37] adopt two machine learning algorithms: random forest (RF) and SVM. When dealing with classifying complex mountainous forests via remote sensing images, Attarchi
et al. [
38] verify the performances of three machine learning methods: SVM, neural networks (NN), and RF. For mapping urban areas of DMSP/OLS nighttime light and MODIS data, Jing
et al. [
39] also utilize SVM.
To investigate the accuracy and efficiency of identification considering the characteristics of GE images, we herein explore the feasibility of supervised machine learning approaches for building identification using AdaBoost and CNN, respectively. Both methods adopt different feature extraction schemes, enabling full exploitation of the texture, spectral, geometry, and other characteristics in the images. The AdaBoost algorithm focuses on the color and textural information of the buildings and their surrounding areas; hence, it utilizes both color information and a large number of Haar-like features.
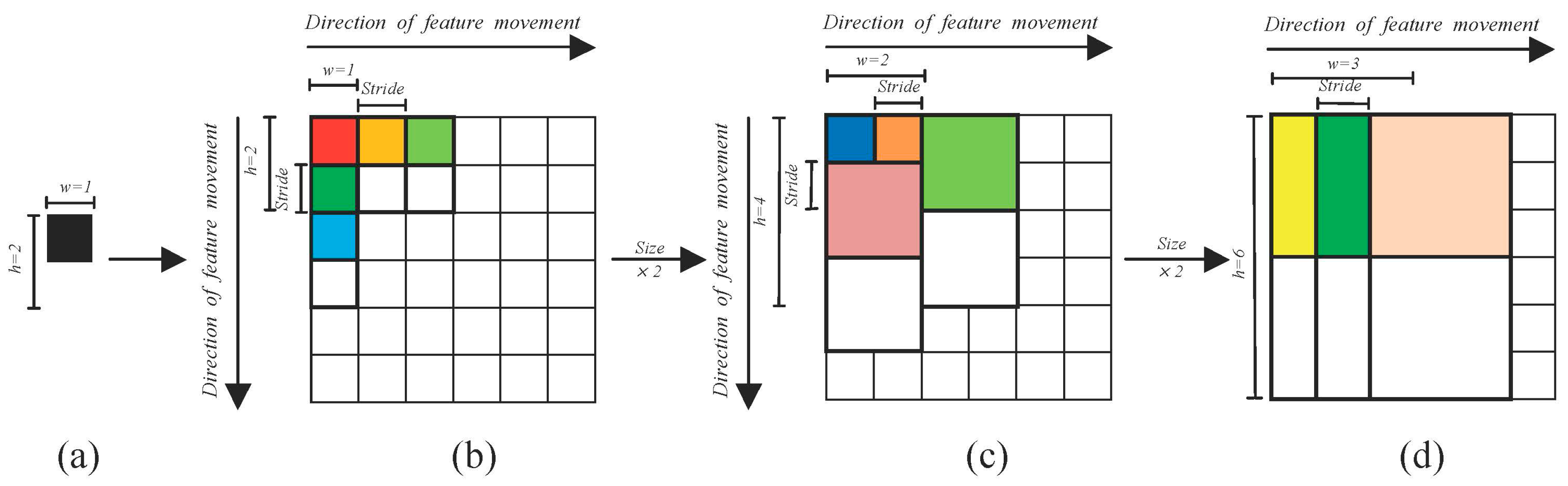
The performance of the AdaBoost method largely depends on the quality of the feature selection, which is itself quite challenging. In contrast, the CNN method achieves more robust and stronger performance than AdaBoost because it mines the deeper representative information from low-level inputs [
28]. With multilayer networks trained by a gradient descent algorithm, CNN can learn complex and nonlinear mapping from a high- to low-dimensional feature space. Here, we constructed a four layer CNN network to describe the characteristics inside an 18 × 18-pixel window and applied it to the classification.
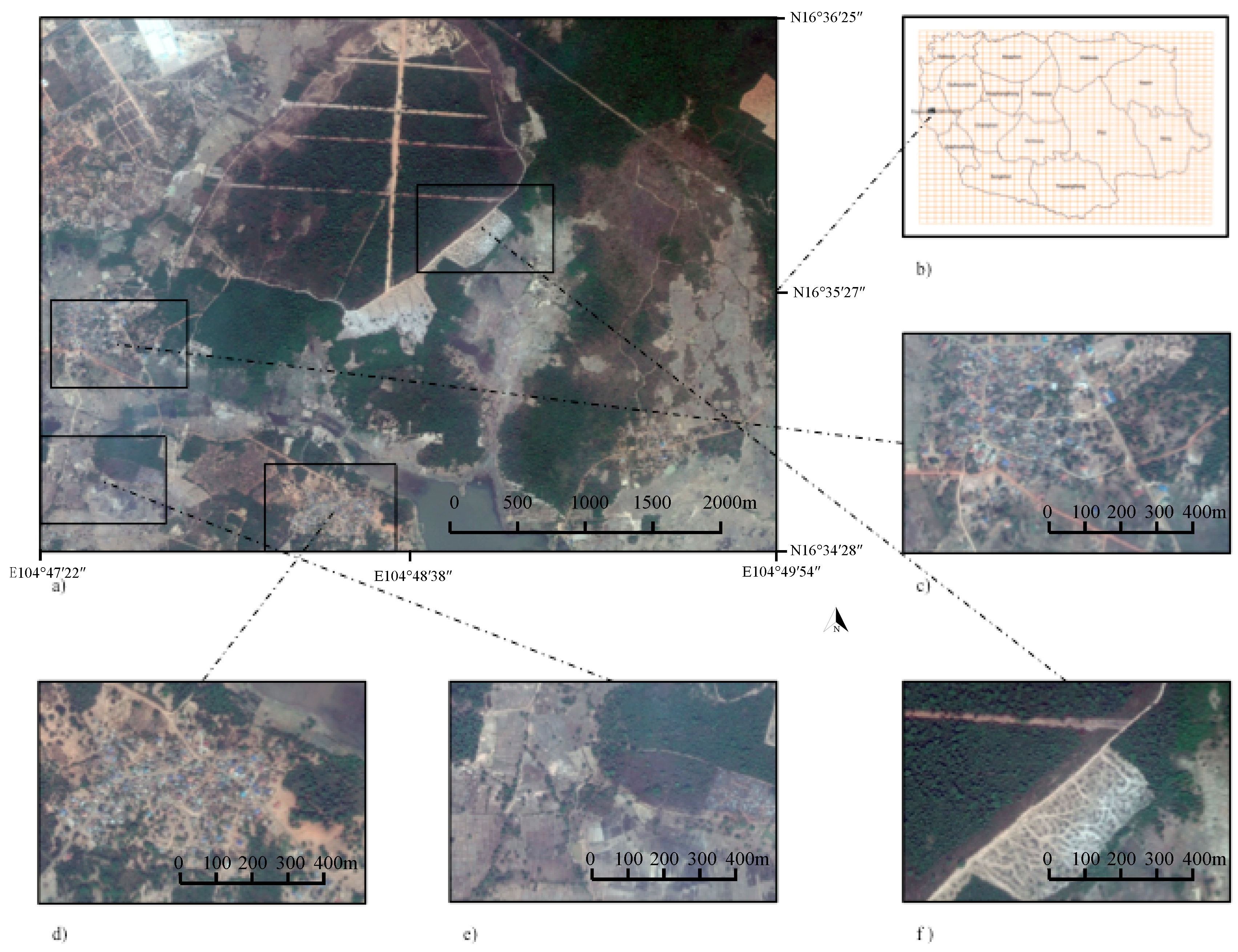
The remainder of our paper is organized as follows. In
Section 2, we describe the study area and the experimental data. In
Section 3, we briefly introduce the principles of the AdaBoost and CNN methods. We compare and analyze the experimental results of each algorithm in
Section 4. The performance of our proposed method and suggestions for future work are presented in
Section 5.
4. Result and Discussion
During the experiment, we first trained the classification model using the sample data and then applied the model to the test dataset. The classification performance was evaluated by three widely used parameters.
- (1)
Confusion Matrix (see
Table 2): This parameter comprehensively describes the performance of a binary classification result.
- (2)
Overall Accuracy: Measures the overall performance of the classifier.
where
is the total number of pixels.
- (3)
Kappa: This parameter comprehensively describes the classification accuracy by measuring the inter-rater agreement among qualitative items [
45]. Kappa is defined as follows:
The performances of AdaBoost and CNN are evaluated in
Section 4.1 and
Section 4.2, respectively. All input training data are contained in the 900 × 600 pixel RGB image shown in
Figure 1d. The same image is used for the test data. The test results of the two algorithms are compared and discussed in
Section 4.3. In
Section 4.4, we test the entire image (
Figure 1a, with a size of 3600 × 4500 pixels) by CNN. To enhance the performance, we also alter the input training data. The accuracy of the experiment is evaluated by comparing the result with the ground truth, which contains the tree labels (building areas, non-building areas, and unknown areas such as cloud cover).
4.1. Result of AdaBoost
In the training section, the positive samples contain information of the recognized target, which herein refers to building information; conversely, negative samples are without information of a recognized target such as trees, roads, and unknown areas.
The confidence obtained by AdaBoost is thresholded by a parameter called Terra. However, when Terra was set to 0 (as in traditional AdaBoost methods), the performance was greatly degraded by the large number of false positives in the classification results. After observing the results for different values of Terra, we selected the optimal Terra based on the Kappa criterion. The following result indicates the progress from using color features to add Haar-like features.
4.1.1. Color Feature
As previously mentioned, the classifier was optimized by trialing four kinds of input samples from
Figure 1d. All the testing samples were also prepared from
Figure 1d. There must be a one-to-one size correspondence between the testing and training samples, as shown in
Table 3. Since the edges are ignored, the number of testing samples differs among the tests.
After the training procedure, four kinds of stronger classifier emerged: AdaBoost_A–D.
To test the accuracy of classifiers generated in the training part, we utilize the classifiers obtained to detect the testing samples, respectively, and the results are as follows (
Table 4).
As we can infer from the result table, classifier B has the optimum solution, with a Kappa of 0.306 and overall accuracy of 96.04%.
4.1.2. Haar-Like Features + Color Features
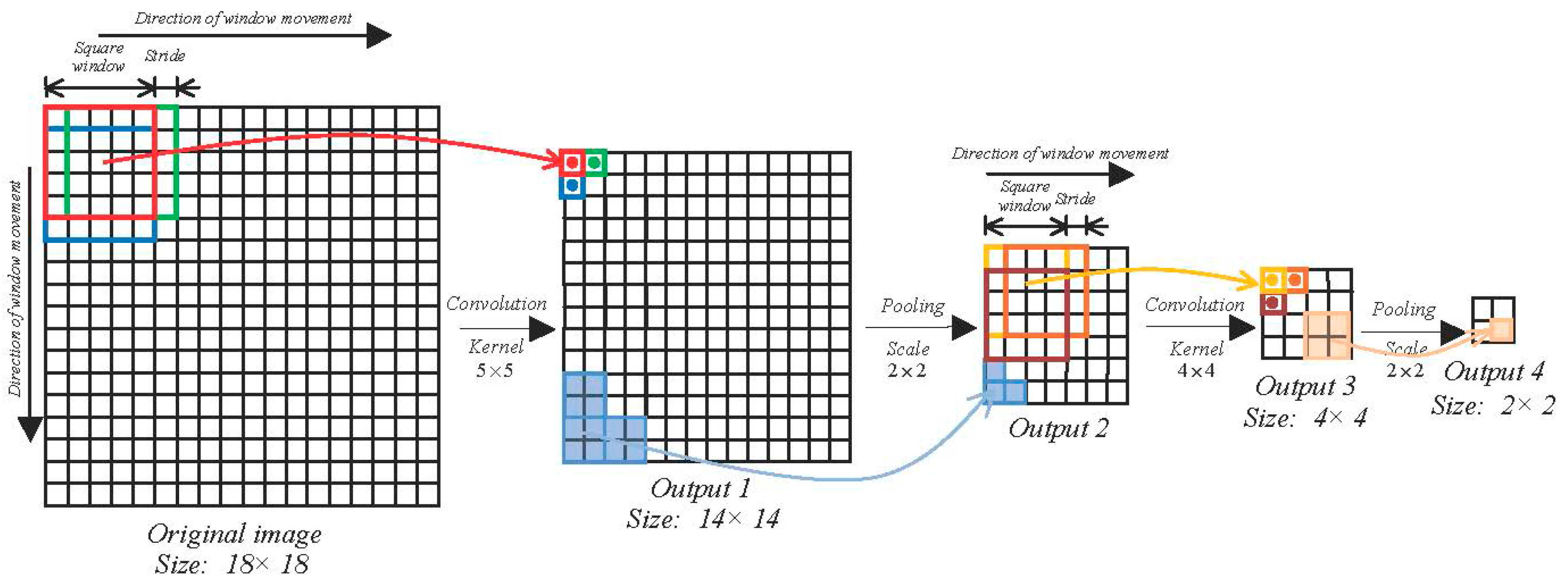
To enhance the accuracy of the classifier, we incorporate Haar-like features and color features to mine deeper texture information of the target. Based on the feature value theory, by calculating the entire feature value via an integral image algorithm, the AdaBoost method can be achieved.
The training samples are captured from
Figure 1d, with 111 pieces of positive sample and 283 negative samples, all sized at 25 × 25 pixels in gray-scale. The positive and negative samples are the gray-scale images of buildings and non-buildings, respectively. The input training data is a matrix of Haar-like feature values. The size of the Haar-like features can be stretched or reduced, and they can move within the entire image. The dimension of a two-rectangle feature would reach 3328; therefore, considering that the dimension of the input training data is extremely large, only four kinds of common Haar-like feature have been used. Based on the principle of
Figure 2, the total dimension of the input features is 3328 × 2 + 2600 + 2276 = 11532. The testing data is also shown in
Figure 1d. After combining with the color features, the result of the identification is enhanced to Kappa of 0.312 and the overall accuracy is enhanced to 96.22%. Compared with the result of using color features only, this result is somewhat improved.
4.2. Result of CNN
In the CNN algorithm training process, placing the training samples and their relevant labels together is necessary. To test the influence of the input parameters on the final classifier, we utilize a control variate method as follows (
Table 5).
After the training part of CNN, three different classifiers are generated from CNN_A to CNN_C. After utilizing the classifiers to test the given figure, the result and the corresponding figure will be produced (
Table 6).
Compared with the respective results, the obtained classifier CNN_C performs well in detecting the buildings from the given figure. Kappa is enhanced to 0.564 and the overall accuracy reaches 96.30%. In such cases, the confusion matrix and the outcome figures are as follows (
Table 7).
As we mentioned in the definition of the confusion matrix, in the method based on CNN, actual buildings that were correctly classified as buildings is 12,540, non-buildings incorrectly labeled as buildings is 17,366, buildings that were incorrectly marked as non-buildings is 799, and number of correctly classified non-buildings is 459,034. Although the number of non-buildings that were incorrectly labeled as buildings is a little bit high, impacting the performance of the result, other parts of the matrix perform well.
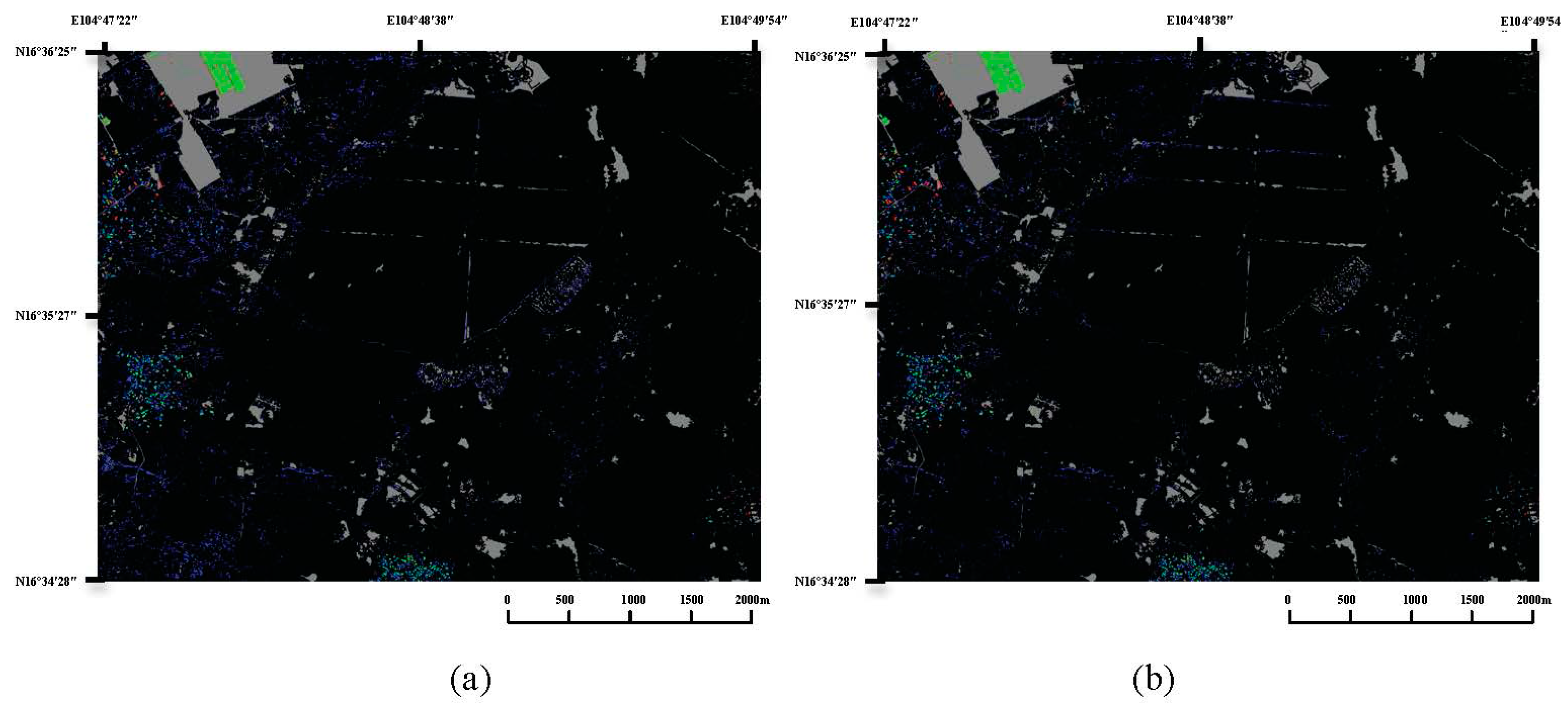
In the outcome figure of CNN_C, gray refers to the unknown part, green means the actual buildings that were correctly classified as buildings, blue indicates the non-buildings that were incorrectly labeled as buildings, red shows the buildings that were incorrectly marked as non-buildings, and black denotes the correctly classified non-buildings. As shown in the result, the CNN_C classifier has high performance in detecting buildings. In
Figure 4b, it can be seen that the classification error decreases stably as the iteration increases.
4.3. Comparison and Discussion
We utilized machine learning methods including AdaBoost and CNN to identify buildings from remote sensing images and generated the relative testing results, as mentioned in
Section 4.1 and
Section 4.2, respectively. Inferring from the comparisons in accuracy, the best result of Kappa and overall accuracy are 0.312% and 96.20% in the AdaBoost algorithm, respectively, whereas in CNN, the result is enhanced to 0.564% and 96.30%, respectively. According to the comparison, in the corresponding testing area, the Kappa of our CNN method is approximately 25% higher than that of AdaBoost. For overall accuracy, CNN also outperforms AdaBoost.
Note that the traditional visual interpretation of remote sensing images is a complex and time-consuming process. Although it has very high accuracy, it is not suited to large-scale automation projects. The effect of AdaBoost methods is highly dependent on the training feature. The color and Haar-like features chosen in our experiment cannot express all the helpful and useful features of the buildings, which impacts the accuracy of the result. In contrast, CNN can mine and extract deeper information on the input features of building, which can be helpful in identification.
4.4. Practical Application
In this section, we demonstrate how the CNN method works via the entire image in
Figure 1a, which is 30 times bigger than that in
Figure 1d. We compare two kinds of input training data and separately obtain the identification results as follows (
Table 8).
The training data in type Train_B contains more diverse negative sample information than that in Train_A, with 150,000 samples including information of mountains and other types of land. The identification results are as follows (
Table 9).
As observed from the testing result, the Kappa and overall accuracy increase when the negative training samples are expanded. In
Figure 4, most of the village buildings can be identified, but the inaccuracy points are mainly distributed in the village boundary and some building-like areas. From
Figure 5b, areas such as mountains can be identified as non-buildings areas, whereas they could not be detected in
Figure 5a.
To detect the details of the performance of Train_B, we split the image into 30 small images of size 900 × 600 pixels as follows (
Figure 6).
The performance of each part is different and the accuracy comparison is as follows.
For different study areas, the overall accuracy of the CNN method can be up to 99.00%. We only show part of the results in
Table 10, especially those containing information of buildings (positive pixels) where Kappa can be up to 0.888, which indicates high performance. We can also infer that the overall accuracy of the proposed method is considerably stable in different areas. As Kappa is relatively low in some areas, identification accuracy can be improved by expanding the training data, as shown in previous processes.
In general, the experimental results indicate that our proposed method based on machine learning, especially on CNN, has high performance in remote sensing identification of buildings.
5. Conclusions and Future Work
In this paper, we propose two kinds of supervised machine learning methods for building identification based on GE images. The corresponding machine learning methods AdaBoost and CNN help us obtain building identification classifiers by training the designed samples. Applying the obtained AdaBoost and CNN classifiers to automatically extract information of buildings from the remote sensing images generates the identification maps of buildings.
The proposed method shows the ability of supervised machine learning in village mapping, which is experimentally demonstrated by including several kinds of areas in Kaysone. The obtained classifier can be used for all cases and no manual interaction is needed. Our method of CNN achieves a Kappa of 0.564 and an overall accuracy of 96.30%, which is comparable to those of AdaBoost and other methods.
Furthermore, the proposed method can be efficiently utilized in remote sensing recognition of not merely buildings. By training the prior knowledge of the corresponding identification samples, the proposed method can generate a classifier that has the ability to classify relative targets and leads to promising classification results. Therefore, based on the result of this experiment, our proposed method is a promising approach that might be applied to many potential applications in the near future.
Although this study indicates that the proposed method could be efficiently used in building identification, further and more detailed exploration on the method is required in the future. First, to test the method’s stability, more extended and sophisticated areas need to be tested. Second, to alleviate the labor-intensive task of training the data, we will apply the learned model of one area to other areas with similar landscapes. Unfortunately, the spectral characteristics of remote sensing images respond to the varying conditions of image capture. To improve the performance in such cases, we will consider a transfer learning technique. Third, we will apply the proposed method to other feature identifications in high-resolution remote sensing images, such as roads and agricultural land. We are also interested in extending this method to classifications of multi-class landscapes. We believe that the proposed method has great practical value for solving diverse classification problems.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}