1. Introduction
With the development of imaging instruments in the past few years, hyperspectral data processing has become increasingly more important in many fields [
1,
2,
3,
4,
5]. As a data tool with high spectral resolution, hyperspectral sensors usually utilized hundreds of spectral channels to describe spectral signatures. Generally, the primary purpose of hyperspectral images (HSI) processing is to analyze and recognize spectral data acquired by hyperspectral sensors. It is established that, different materials have distinct reflectance spectral signatures. Thus, reflectance spectra are always used for material recognition and image analysis [
6].
However, while the high dimensionality of HSI supports accurate descriptions for spectral signatures, they lead to some theoretical and practical problems, particularly the curse of dimensionality problem. In classification problems, classification accuracies are not positively correlated to the dimensionality of input data. Usually, classification is most accurate with a particular feature number, as has been demonstrated in References [
7,
8,
9]. Hence, feature extraction and dimensionality reduction techniques are important and indispensable in high-dimensional data classification and analysis. Based on known information, feature extraction (FE) techniques are generally categorized into unsupervised and supervised methods. Unsupervised FE techniques, e.g., principle component analysis (PCA) [
10], are always used for data description and representation. Supervised FE focuses on reducing the dimensionality of data to achieve better classification performance and avoid Hughes phenomena [
7]. Many supervised feature extraction algorithms have been proposed and widely used in hyperspectral image processing, such as the discriminant analysis feature extraction (DAFE) algorithm [
11], the decision boundary feature extraction (DBFE) approach [
12], and the nonparametric weighted feature extraction (NWFE) method [
13], etc.
Conventionally, HSI are treated by classifiers as spectral data cubes and a set of spectral measurements without spatial structure [
14]. Hence, the spatial structure features in HSI are discarded. However, with the development of sensors, HSI usually provides both detailed spatial structural and spectral information. Crisp and adaptive neighborhood systems are commonly used to characterize spatial structural features [
15]. The crisp system generally analyzes the spatial structure based on a tough neighborhood. The crisp system is widely used in spatial information extraction. However, it has the following limitations: (1) the classifier effectiveness may be influenced by the predefined neighborhood system without enough samples; and (2) a large neighborhood system usually results in computation problems [
16]. For this reason, adaptive neighborhood systems are also taken into account. Based on the morphology theory [
17], which has been widely used in image processing, a set of methods for spatial information extraction using adaptive neighborhood systems [
18,
19,
20,
21,
22,
23,
24] have been proposed.
Morphological profiles (MPs) [
18] have demonstrated their usefulness in spatial structure description. The sizes of different structures in an image can be determined by using geodesic opening/closing through reconstruction [
19,
20]. For any given size of a structuring element (SE), the structures that are smaller than the SE are removed, while larger structures are preserved. The spatial information of the image is extracted by applying such operators with an SE range of different sizes. This concept is usually called granulometry [
21]. The attribute profiles (APs) technique [
22] is a further development of MPs based on attribute filters, which allow for the modeling of geometrical characteristics. Compared with MPs, APs allow more precise modeling of spatial information. This is because an input image can be processed based on multiple attributes, by which different aspects of spatial structures can be described with great flexibility. When dealing with vectorial images, typically HSI, the application of morphological filters has been extended based on the concept of the vectorial image profile. Extended morphological profiles (EMPs) [
23] and extended attribute profiles (EAPs) [
21] were proposed to extract the spectral and spatial features of the hyperspectral data. In References [
21,
23], PCA was first implanted in original hyperspectral data, and the first principle components that contained particular cumulative variance were selected as the baseline images. Then MPs and APs were performed on all the selected PCs. EMP and EAP were composed by these MPs and APs, respectively. In later studies, an extended multi-attribute profile (EMAP) was proposed in References [
15,
24]. EMAP, which utilizes multi-attributes, is a more advanced version of EAP. Additionally, Reference [
25] proposed a supervised feature selection approach in attribute profiles on the basis of a genetic algorithm (GA). By introducing the GA technique, the EMAPs with the highest importance are preserved for classification. In References [
15,
25], supervised FE techniques were used to create better profiles and extract more discriminate spatial features. In Reference [
26], a state-of-the-art hyperspectral classification based on sparse representation and EMAPs was proposed. Based on the fact that the extracted EMAPs with high dimensionality should have particular class-dependent manifold structures, this classification approach exploits the inherent characteristics of EMAPs embedded in high-dimensional feature space. This method, called SUnSAL in Reference [
26], combines the benefits of sparse representation and the rich spatial structural information obtained by EMAPs.
In order to consider both the spectral features and spatial features, spectral-spatial classifiers have become increasingly important in HSI classification. A few studies, such as References [
27,
28], have proposed several spectral-spatial FE methods based on supervised FE techniques and morphological filters for HSI classification. In References [
27,
28], the spectral and spatial features were extracted using supervised FE approaches and morphological filters, and then the extracted spectral features and spatial features were fused via vector stacking. Thus, both spectral and spatial information were utilized in classification. Reference [
29] extracted the local image structures by employing local binary patterns (LBP). LBP features were extracted on all selected spectral bands. Next, the local image patterns and spectral features were fused both at the feature and decision level for classification. In Reference [
30], a spectral-spatial method using multi-hypothesis (MH) prediction for noise-robust HSI classification was proposed. By using a weighted regularization, the MH prediction finds the best linear hypothesis combination and achieves spectral-spatial classification. Inspired by the deep leaning idea, a deep feature extraction algorithm based on convolution neural networks was presented in Reference [
31]. However, it is important to note that the inner relationship between spatial and spectral features has received little attention. In order to further improve the classification accuracy, new information must be introduced and explored, particularly the information hidden in the relationship between the spectral and spatial information. References [
32,
33,
34] have demonstrated that spatial neighbors always contribute to the measured signal through adjacency effects. Hence, spectral and spatial features are not independent due to data interaction in HSI.
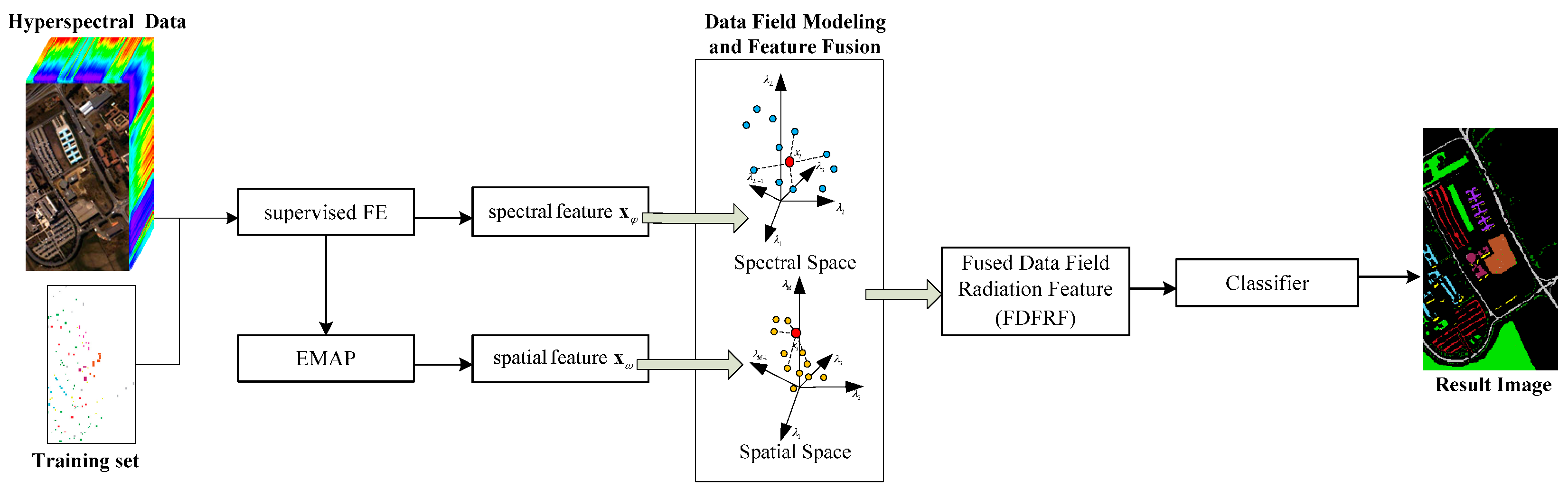
In this study, a supervised spectral-spatial classification algorithm based on data field theory is proposed. This algorithm improves classification accuracy by further processing the extracted spectral and spatial information. Unlike the current classification approaches, the proposed method aims to further improve classification performance by exploring the inner relationship between spectral and spatial information. The main motivation of the proposed method is that data influences and interactions should be taken into consideration, which is often neglected in spatial-spectral classification tasks. By considering the mutual influences and interactions between pixels, we attempt to build the connection between the spectral and spatial domains. So, more useful information hidden in the relationship between spectral and spatial information, or, for simplicity, the adjacency effects, can be explored and included for classification. In our study, spectral information was extracted by supervised FE techniques and spatial information was generated by EMAP, as performed in Reference [
27]. Next, data field modeling was applied to both the spectral and spatial domains. Based on data field modeling, the spectral and spatial information are unified. So, the unified radiation features containing both spectral and spatial information can be fused into a new radiation feature by using a linear model. Another advantage of data field modeling in both spectral and spatial domains is that the problem of the extracted spectral and spatial features having different scales can be avoided. An random forest (RF) classifier provides a final classification map [
35]. The novelty of the proposed algorithm lies in its use of data field theory to explore the relationship between the spatial and spectral information. To measure the efficacy of the presented method, we tested it by using two standard hyperspectral datasets. In the remainder of this paper,
Section 2 covers the detailed presentation of the proposed algorithm.
Section 3 presents a series of experiments with two standard HSI test datasets. In
Section 3, the experimental results of different test cases are analyzed and key parameters used in the proposed method are discussed. The advantages of the proposed approach and proposed subjects for future investigation are drawn in
Section 4, followed by the conclusions in
Section 5.
3. Experiments and Results
Two standard datasets, the Reflective Optics Systems Imaging Spectrometer (ROSIS-03) University of Pavia dataset and the Airborne Visible Infrared Imaging Spectrometer (AVIRIS) Indian Pines dataset, which are frequently used in research, were used in this study.
The first test dataset is a hyperspectral dataset collected from the University of Pavia, Italy, by the ROSIS-03 airborne instrument. In this dataset, nine classes of interest were considered in the image scene. This dataset, which is composed of 103 bands of 610 × 340 pixels, provides a high spatial resolution of 1.3 m/pixel. The training and test sets were composed of 3909 and 42,788 samples, respectively. The number of training and test samples is shown in
Table 1.
The Indian Pines dataset is a standard test dataset acquired in 1992 using the AVIRIS sensor. The data consists of 145 × 145 pixels with a medium spatial resolution of about 20 m/pixel. In this test case, the spectral channels in the atmosphere absorption bands were removed, so 200 data channels were used. Sixteen classes of interest were considered. For this dataset, a total of 695 pixels and 9671 pixels were used to make up the training and test sets, respectively. The number of available test and training samples is displayed in
Table 2.
The details of the training and test sets of the two datasets are given in References [
27,
36]. To maintain consistency with previous results, we used the same size training and test sets adopted by other state-of-the-art approaches. We also adopted samples with precisely the same spatial locations as in the previous studies. Each method was executed only once because the samples that we used were identical to those used in the previous studies. False color images of the two datasets are presented in
Figure 2.
3.1. Experimental Setup
In all the experimental datasets, the spectral-spatial classification method
which was proposed in Reference [
27], known as AUTOMATIC, was employed for comparison. The FE approach used is denoted by
n. Here, the HSI data were first transformed by the FE approach. The spectral feature
was the output of this step. Next, the spatial feature
was obtained by EMAP and the FE approach. Finally,
and
were stacked together for classification. DAFE and DBFE were employed for supervised FE. DAFE is often applied to dimension reduction and feature extraction in a pattern recognition field. The class centers and covariance matrix of each class are calculated by training samples in DAFE. As a parametric method, DAFE achieves a satisfactory performance if the data approximately follow a normal distribution. DBFE extracts both discriminately informative and redundant features from the decision boundary. Using the decision boundary feature matrix, the decision boundary is described and features are extracted. For example,
denotes that the raw data were first transformed by DAFE. Then the EMAP was performed on the baseline images obtained by DAFE. Finally, the spectral features extracted by DAFE and the spatial features obtained by EMAP were stacked together.
It should be emphasized that the features containing more than 99% of cumulative eigenvalues were selected when DAFE and DBFE were employed in the following experiments. The classification results obtained by using the spectral information were reported only for comparison. We use DA and DB to indicate the spectral information extracted by DAFE and DBFE, respectively. The EMAP methods were also employed to demonstrate the superiority of the proposed algorithm. The DA
p and DB
p denote the EMAPs that were generated based on the features extracted by DAFE and DBFE, respectively. The EMAP-based classification methods proposed in References [
25,
26], which were respectively denoted by GA and SUnSAL, were employed. The recent state-of-the-art spectral-spatial classification approaches, including MH [
29] and LBP [
30], were used for comparisons. For the MH approach, the hypotheses for prediction were generated using the manually selected spectral-band partitions as suggested in [
29]. In the LBP method, the criterion of linear prediction error (LPE) [
37] was used for spectral band selection, and LBP features were extracted on these selected bands. Then, the LBP features and selected spectral bands were fused at the feature level, and processed by the classifier. To make our methods fully comparable with the reference techniques, the thresholds and values used for this experimental setup were selected from References [
15,
27].
The term
signifies our proposed method. The FE approach is denoted by
n. The spectral feature
and spatial feature
were fused into FDFRF in our proposed method. In the experiments, we set
, i.e., five NNs in each class were considered in the data field modeling. The features extracted by all the methods were analyzed by an RF classifier. In all the experiments, the number of trees was set to 200, as suggested in References [
15,
35,
36], in order to achieve a trade-off between the classification performance and time cost for the learning phase. The method performances were evaluated by three measurements: the overall accuracy (OA), the average accuracy (AA), and the Kappa coefficient (
). However, in order to avoid unnecessary redundancy in the following, the experimental results and comparison will only be analyzed based on OA.
3.2. Results
As shown in
Table 3 and
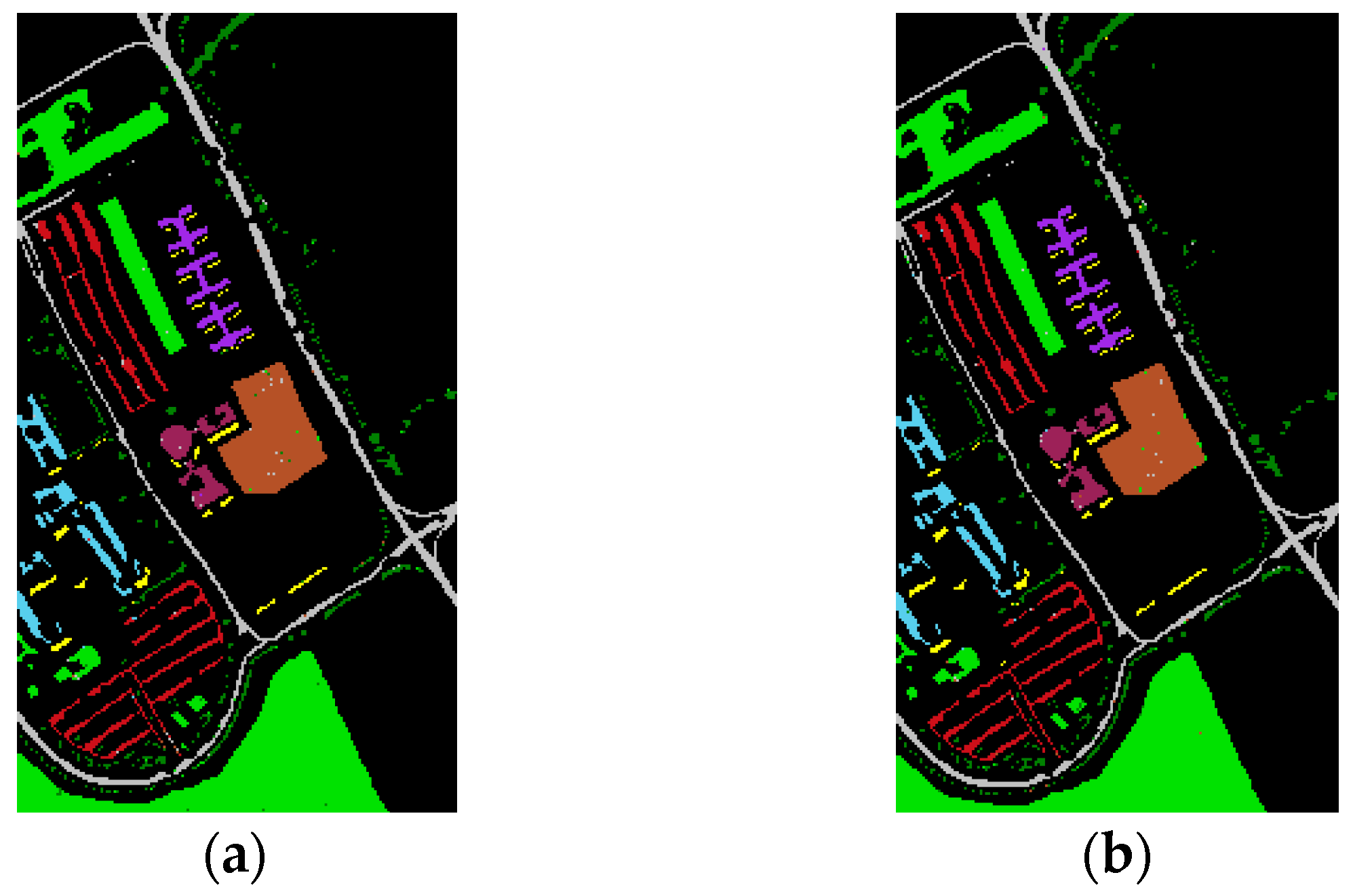
Table 4, the results of our experiments with the two datasets show that feature fusion based on the data field theory can improve classification accuracy compared to the reference methods. The classification results acquired by the proposed method on the two datasets by the proposed method are shown in detail in
Figure 3 and
Figure 4.
For the University of Pavia dataset, the data field feature fusion resulted in significantly improved classification accuracy. As can be observed from
Table 3,
outperformed the other methods with an OA of 99.4%.
achieved 19%, 4.1%, and 13.4% improvement in OA over DA, DA
p and
, respectively. Compared with the corresponding reference DB, DB
p and
methods,
improved the OA by 20.5%, 3.4%, and 2.6%, respectively. It is also important to emphasize that
exhibited excellent classification performances with an OA of 96.8%. In comparison,
and
achieved small improvements in OA of 2.1% and 2.6%, respectively. Although the improvements in classification accuracy are not remarkable in the manner of OA, more than 65.6% and 81.2% of test samples misclassified by
were corrected by
and
, respectively. We can therefore conclude that the proposed method effectively improved the classification performance.
Compared with the results reported in
Table 3, it is easy to deduce that DBFE outperforms DAFE. The primary reason may be that DAFE is not full rank, so that some discriminative spectral information was lost. It should be noted that the classification performances of AUTOMATIC, which stacked the spectral and spatial features together, were affected by different FE approaches. The OA resulting from
is 11.3% more than that of
. Compared to the EMAP approaches, AUTOMATIC improved the classification accuracy when DBFE was employed. However, AUTOMATIC classification decreased when DAFE was performed. The proposed method is much more robust with respect to the choice of the FE technique. Classification results always remained at a high level when different FE approaches were used. This is because our method further fused the extracted spectral and spatial features. As a result, the useful information that lies in the spectral-spatial relationship and can contribute to the classification was included.
Compared with the employed state-of-the-art HSI classification methods, the proposed method additionally achieved competitive classification performance in this test case. achieved the best classification results in terms of OA, AA and the value. As can be observed from the classfication results, achieved approximately 3.3%, 1.3%, 0.6% and 0.2% improvements in OA over GA, SUnSAL, LBP and MH, respectively. Though the OA improvements are seemingly very small, almost 84.6%, 68.4%, 50% and 25% of misclassified samples in these methods were corrected, respectively. Moreover, also produced a satisfactory classification performance with an OA of 98.9%. Although the MH approach reported a higher classification accuracy with an OA of 99.2%, is competitive because it perfomed better than all the other reference methods.
In contrast to the University of Pavia dataset, the low spatial resolution, which leads to more mixed pixels, makes the classification task more complex in the Indian Pines dataset. For this test case, the HSI classification results, obtained by further feature fusion, were generally better than the corresponding compared methods. For example,
achieved 33.3%, 5.7%, and 3.5% improvements in OA over DA, DA
p, and
, respectively.
improved the OA of DB, DB
p, and
by 31.9%, 5.4%, and 11.9%, respectively. The best accuracies were obtained by using
which achieved an OA of 96.8%. It should be noted that reference methods exhibited acceptable performances in terms of classification accuracies. In contrast, the
achieved the best performances in 11 classes and
performed better than all the reference methods in 11 classes. As the results represented in
Table 4 show, DAFE performs better than DBFE in terms of OA, AA, and the Kappa coefficient. A possible reason may be that the presence of the pixels with mixed spectra leads to the features number extracted by DBFE being insufficient to discriminate the samples in different classes.
In the Indian Pines dataset, the results also indicate that the AUTOMATIC approach is affected by different FE methods. Our method avoided this problem by using data field modeling and further feature fusion. As can be observed from the classification results reported in
Table 4, the state-of-the-art spectral-spatial methods improved the classification more significantly than the spectral-based methods DA and DB in this test case. This may be because the spectral information is less dominant in this test case and introducing spatial information effectively contributes to the classification problem. As with the Pavia University dataset, our method obtained competitive results for this dataset in comparison to the other state-of-the-art methods. The best classification result was obtained by
with an OA of 96.8%, and the missclassified rates decreased approximately 48.4%, 46.6%, 52.2% and 25.6% compared to GA, SUnSAL, LBP and MH, respectively. Moreover,
also performed competitively with better classification accuracies than the other reference methods, except for MH.
As Equation (5) shows, the feature number (i.e., the dimensionality of the FDFRFs) in our method is determined by the number of the classes and NNs used in the data field modeling. The feature numbers of our method were 45 and 80 using the Pavia University dataset and Indian Pines dataset, respectively. The proposed method can be seen as an advancement of the AUTOMATIC approach. Accordingly, the feature numbers of the proposed method and AUTOMATIC are listed in
Table 5. It can be seen from
Table 5 that the proposed method achieved better classification results with acceptable feature numbers. Compared to the EMAP reference methods, our methods effectively reduced the feature numbers and improved classification accuracy. Moreover,
(consisting of 45 features) performed better than
, which consisted of 59 features in the Pavia University dataset. In the Indian Pines dataset, the proposed method also showed superior classification performance over AUTOMATIC approaches with an acceptable feature number.
Finally, we compare the computational complexity of the classification methods. As an example, the processing times (in seconds) of the methods with the Indian Pines dataset are shown in
Table 6. All experiments were implemented using MATLAB on an Intel Core i5 CPU with 3.2 GHz and 4 GB of RAM. As can be seen in
Table 6, the DAFE-based methods have an obvious advantage in computational time compared to DBFE-based approaches because DAFE is faster than DBFE. The computational costs of data field-based methods are higher than those of the corresponding AUTOMATIC approaches owing to the burden of building FDFRFs. Compared to the other methods, our method achieved superior classification performances at the cost of greater computational complexity and time consumption. However, the speed of our method could be improved by using time-efficient feature extraction approaches and parallel computing techniques.
3.3. Parameters
In this section, two important parameters used in the presented algorithm are discussed. First, the radiation factors used in the radiation function are analyzed, and an adaptive method for determining the radiation factor is put forward. Secondly, the relationship between the algorithm performance and , the number of NNs used in data field modeling, is discussed.
As shown in Equation (1), the radiation intensity is jointly determined by the distance measurement
and the radiation factor. Radiation factors determine the character of the radiation effects in data fields or, for simplicity, the range of the data radiation domain. The distance measurement can lose meaning when
is extremely small or large. The data interact strongly when
is very small, whereas, the interactions between data are negligible if
is very large. Additionally, as before, we use different radiation factors in different spaces and classes when calculating radiation intensities. In this study, the values of the radiation factors were determined by the training samples. For a given training sample
, the training set can be divided into two parts, as mentioned in
Section 2. The vector mean value of the Same Class Subset spectral features is denoted by
, which can be considered as the center of the class
in the spectral feature space. It is desirable for the training samples in the same class and different classes to have as strong and weak radiations as possible, respectively, i.e.,:
where
is the mean value of the distances between
and the samples in the Same Class Subset, and
is the mean value of the distances from
to the samples in the Different Class Subset. Therefore,
(i.e., the radiation factor of
in the spectral domain data field) can be adaptively determined by the training samples. The radiation factor of
in the spatial domain data field, which is denoted by
, can be determined in the same way.
In our proposed method, the number of NNs
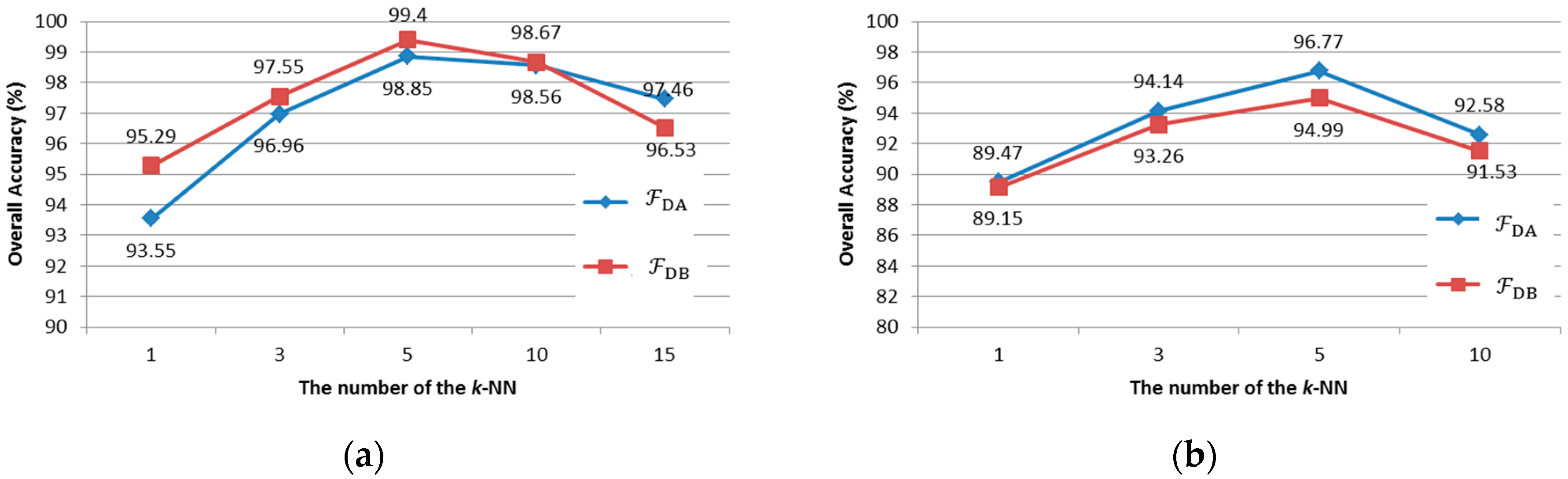
k is the most important parameter in determining the data field modeling accuracy and classification performance. The influence of
k on the algorithm performance, measured by OA, can be observed in
Figure 5. Note that OA increases with
k. However, the classification performance decreases when
and
in the Indian Pines dataset and Pavia University dataset, respectively. This is because a large
k may lead to a higher dimension of FDFRF, which may cause the Hughes phenomenon. Moreover, a large
k also brings a higher computation cost. Based on our experimental results, it is reasonable to set
k = 5, which avoids the Hughes phenomenon and achieves a good trade-off between the classification performance and computation cost.
3.4. Experiments Using Reduced Training Samples
As can be observed in
Table 1 and
Table 2, a large training set with 3909 training samples was used in the University of Pavia test case and a relatively small training set was employed in the Indian Pines dataset with 15 or 50 training pixels per class. In order to further validate the classification performance using a small training sample size, an additional experiment was performed using the Pavia University dataset with a reduced number of training samples. In this experiment, 30 training samples per class were randomly selected from the provided 3909 training samples to form the small training sample set.
Table 6 reports the classification OA, AA,
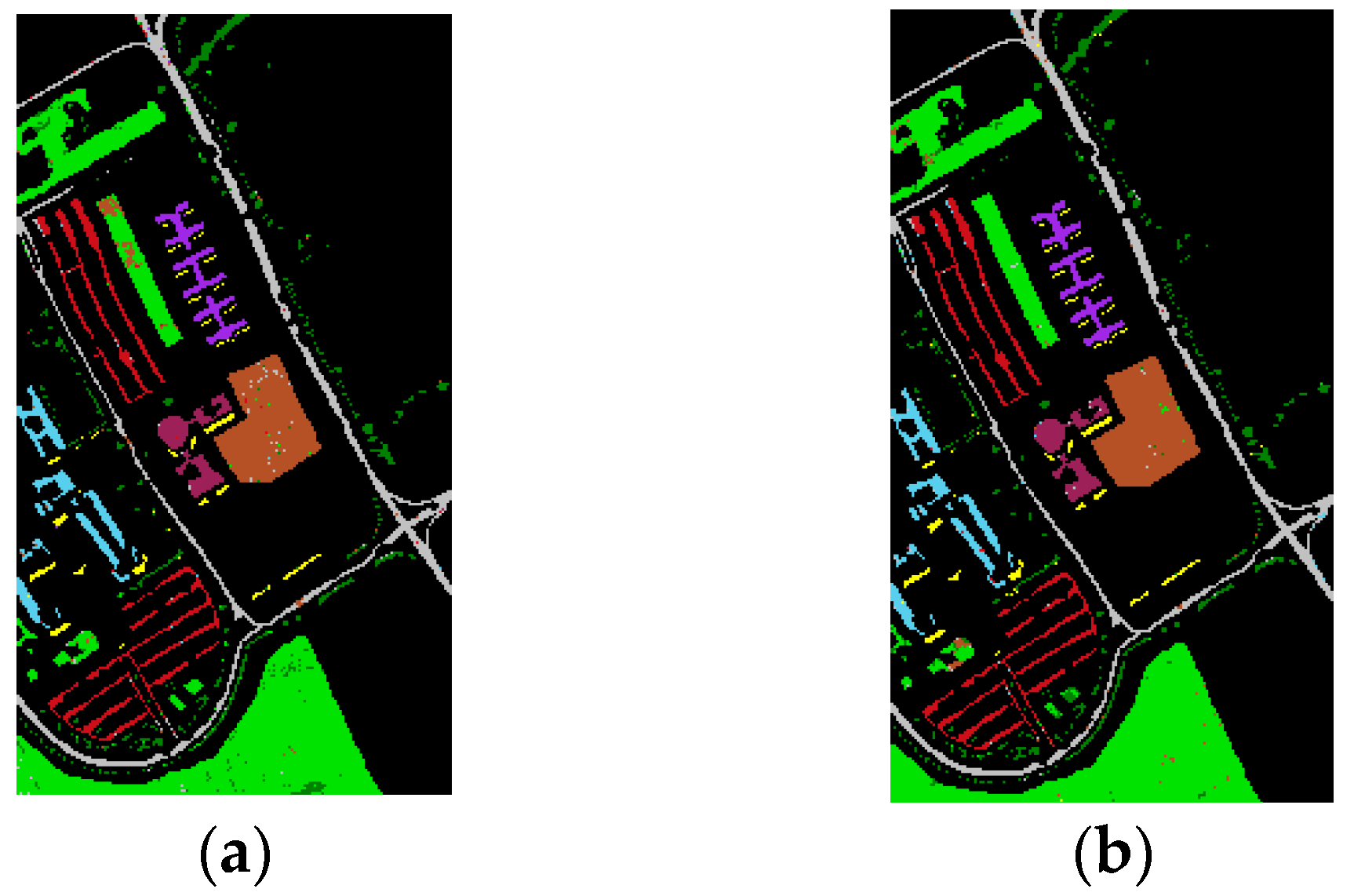
value, and individual class accuracies achieved by different approaches. The classification maps acquired by our proposed method using the small training sample size are shown in
Figure 6. As can be observed in
Table 7,
and LBP achieved the best classification performance in terms of OA, with an OA of approximately 96.6%. However, LBP performed better in terms of the AA and
value and obtained the smallest degradation in OA. The reason might be because the LBP approach can extract the detailed local image characteristics, such as corners, edges and knots. Hence, it is more efficient and robust in describing spatial features than EMAP-based methods, particularly in the small training sample size case.
also demonstrated a competitive performance under the small training sample size. Compared with all the reference methods except LBP and
,
obtained higher classification accuracies. Therefore, it can be concluded that our proposed technique can achieve satisfactory classification results with limited training data.




 Trees,
Trees,  Asphalt,
Asphalt,  Bitumen,
Bitumen,  Gravel,
Gravel,  Metal sheets,
Metal sheets,  Shadows,
Shadows,  Meadows,
Meadows,  Bricks,
Bricks,  Bare soil; (c,d) AVIRIS Indian Pines dataset,
Bare soil; (c,d) AVIRIS Indian Pines dataset,  Alfalfa,
Alfalfa,  Corn-notil,
Corn-notil,  Corn-mintill,
Corn-mintill,  Corn,
Corn,  Grass-pasture,
Grass-pasture,  Grass-trees,
Grass-trees,  Grass-pasture-mowed,
Grass-pasture-mowed,  Hay-windrowed,
Hay-windrowed,  Oats,
Oats,  Soybean-notill,
Soybean-notill,  Soybean-mintill,
Soybean-mintill,  Soybean-clean,
Soybean-clean,  Wheat,
Wheat,  Woods,
Woods,  Bldg-grass-tree-drives,
Bldg-grass-tree-drives,  Stone-steel-towers.
Stone-steel-towers.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}