
A Novel Topology Link-Controlling Approach for Active Defense of Nodes in Networks

Abstract
:1. Introduction
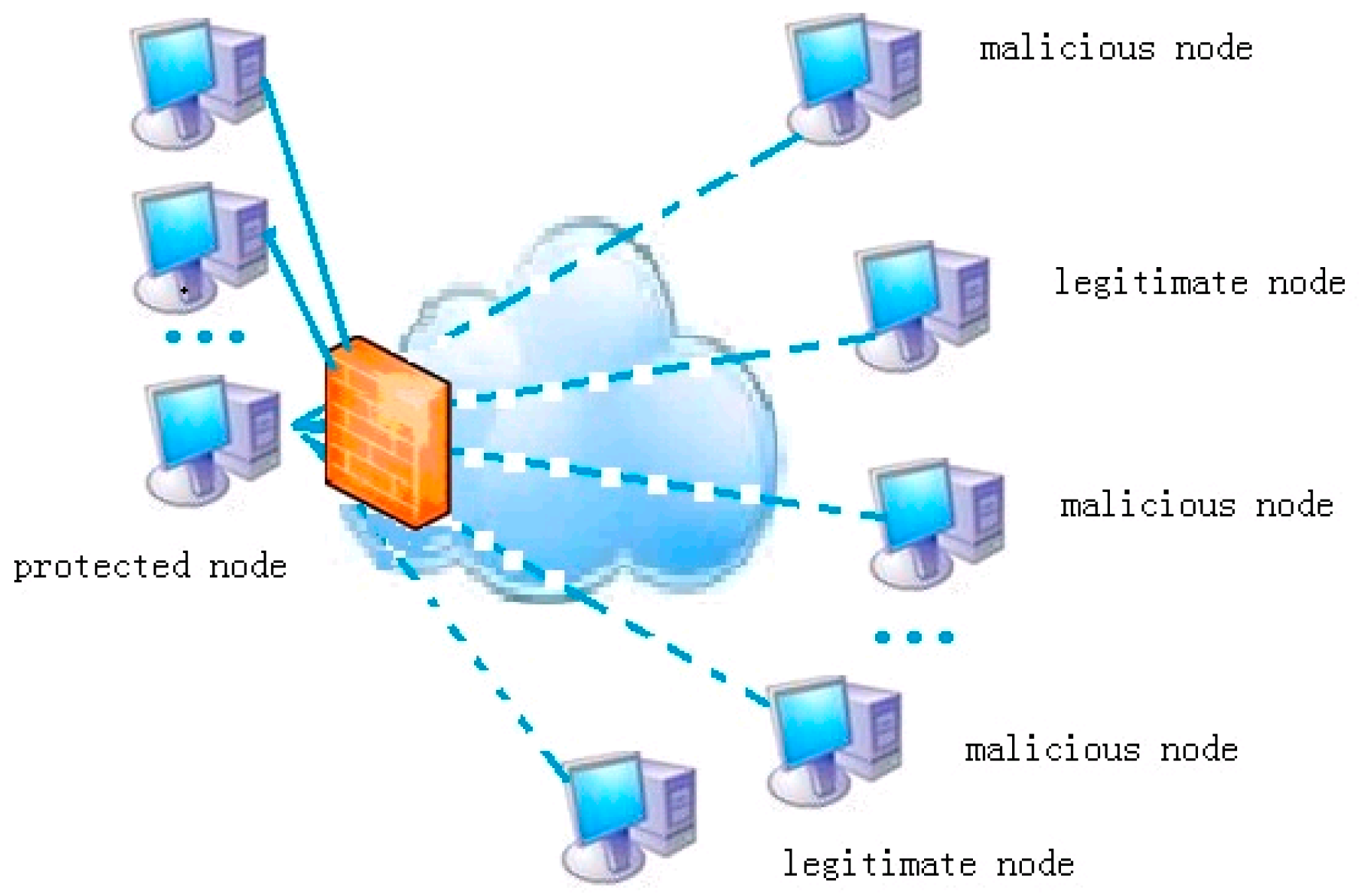
- A non-invasive method of deploying virtual sensors is proposed, which use the resource manager of each monitored node as a sensor;
- An early prediction model of node resource risk on the gateway is proposed. This model predicted the level of the resources of a protected node from the traffic on the firewall so as to provide the basis for the defense measures to start; and
- The proposed method of mitigating attacks in real-time environments to prevent malicious packets reaching the target, while allowing legal packets.
2. Related Work
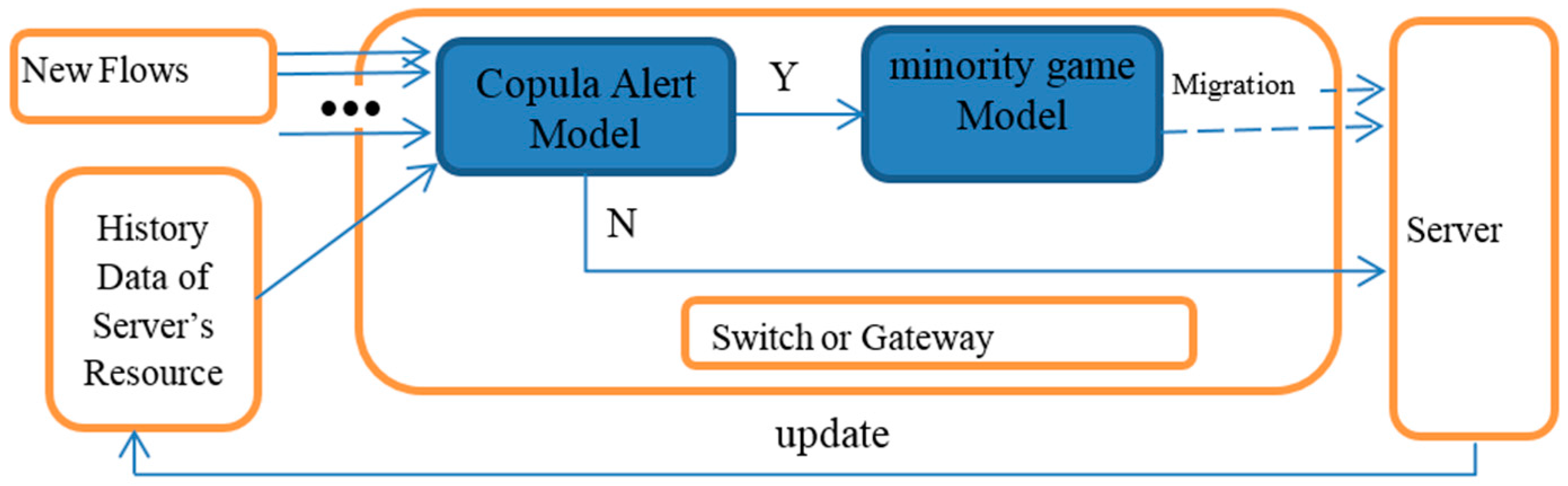
3. The Proposed Model
3.1. Early Alert Model
3.1.1. Single Resource Early Warning Model
- (1)
- The range of C is the unit interval [0,1];
- (2)
- , where at least one coordinate is equal to zero;
- (3)
- C is 2-increasing in the sense that for every a ≤ b in the measure assigned by C to the 2-box is non-negative; i.e.:
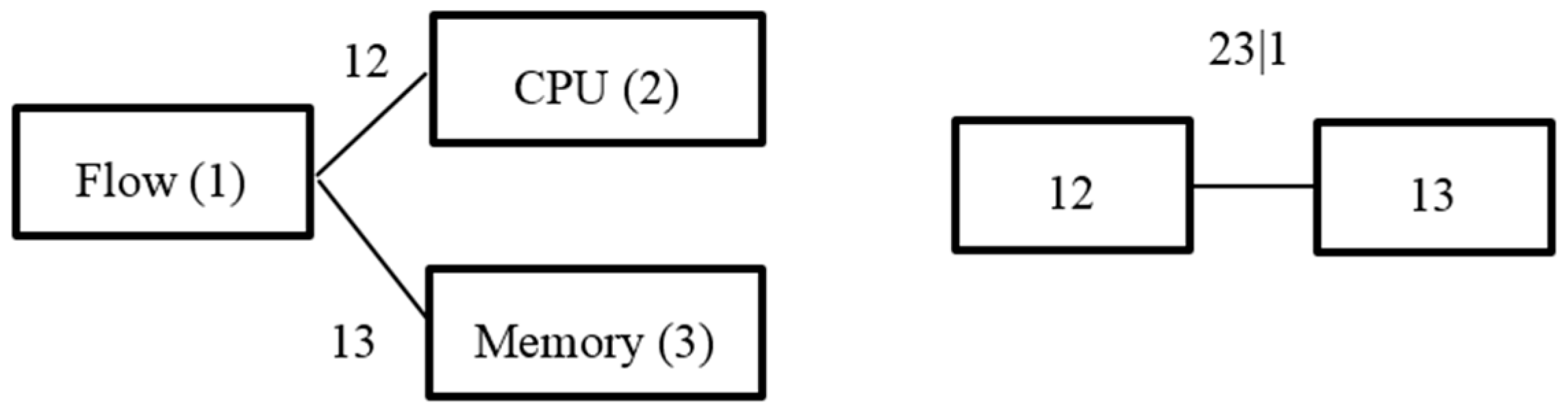
- Calculate the marginal distribution of two variables (flow and memory are chosen in our simulation).
- Select the appropriate copula function to describe the structure of the random variables according to the density function.
- Estimated copulas connect for unknown shape parameters in the model.
- Construct a joint distribution function of independent and dependent variables using a copula function, and then analyze the relevance of the independent variable, dependent variable, and the relevant model. We perform a meticulous study of sample values of the unknown dependent variable probability distribution and the relationship between the joint distributions on the basis of combining with the independent variable probability distribution characteristics of known sample values. Therefore, we can predict the unknown value of the dependent variable.
- At time t + 1, variable Xt+1 can be measured or estimated under the condition of Xt. through the copula connection function and joint distribution, combined with the polynomial fitting of the variable Yt, Yt+1 can be predicted according to the relation between the variables.
3.1.2. Risk Assessment
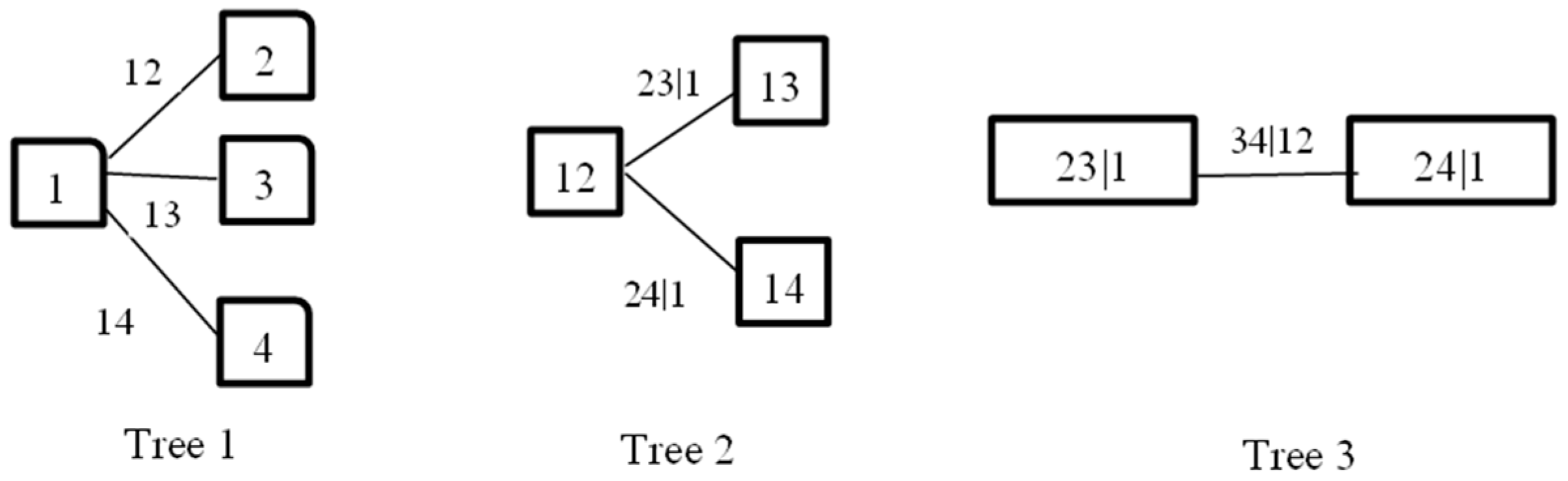
- The time series of a certain index () is selected, and—combining with the marginal distribution function —we can estimate the parameters of the copula pair density function on the first tree, such as , , etc. According to Equation (3) and the parameters of the copula pair function in Tree 1, the conditional distribution function of Tree 2 is obtained, and the corresponding observed values can also be calculated.
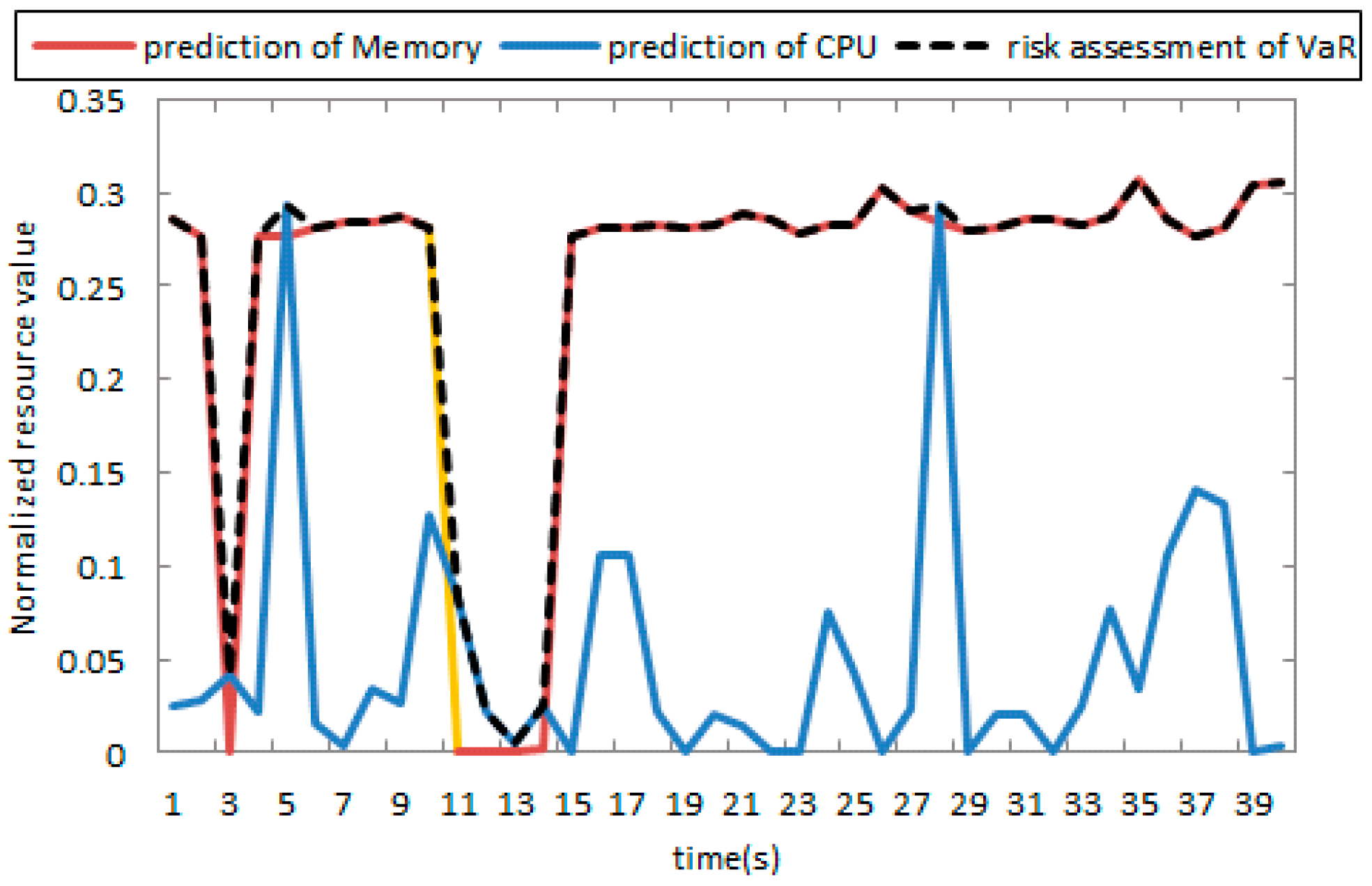
- Under a certain confidence level, the distribution function of the normal rate of the index combination within the time t is defined as:It is expressed at a given confidence level. In the next period of time t, the risk rate will not exceed some value rate (VaR).
- If there are n resources, is the normal value of resource. VaR is defined as Equation (23). is the highest value of n resources at each time. After the introduction of copula pair decomposition, Equation (7) can be written in the form of the integral:
3.2. Active Defense of Incomplete Strategy of a Minority Game
3.2.1. The Basics of the Minority Game Model
3.2.2. Improved Minority Game Model
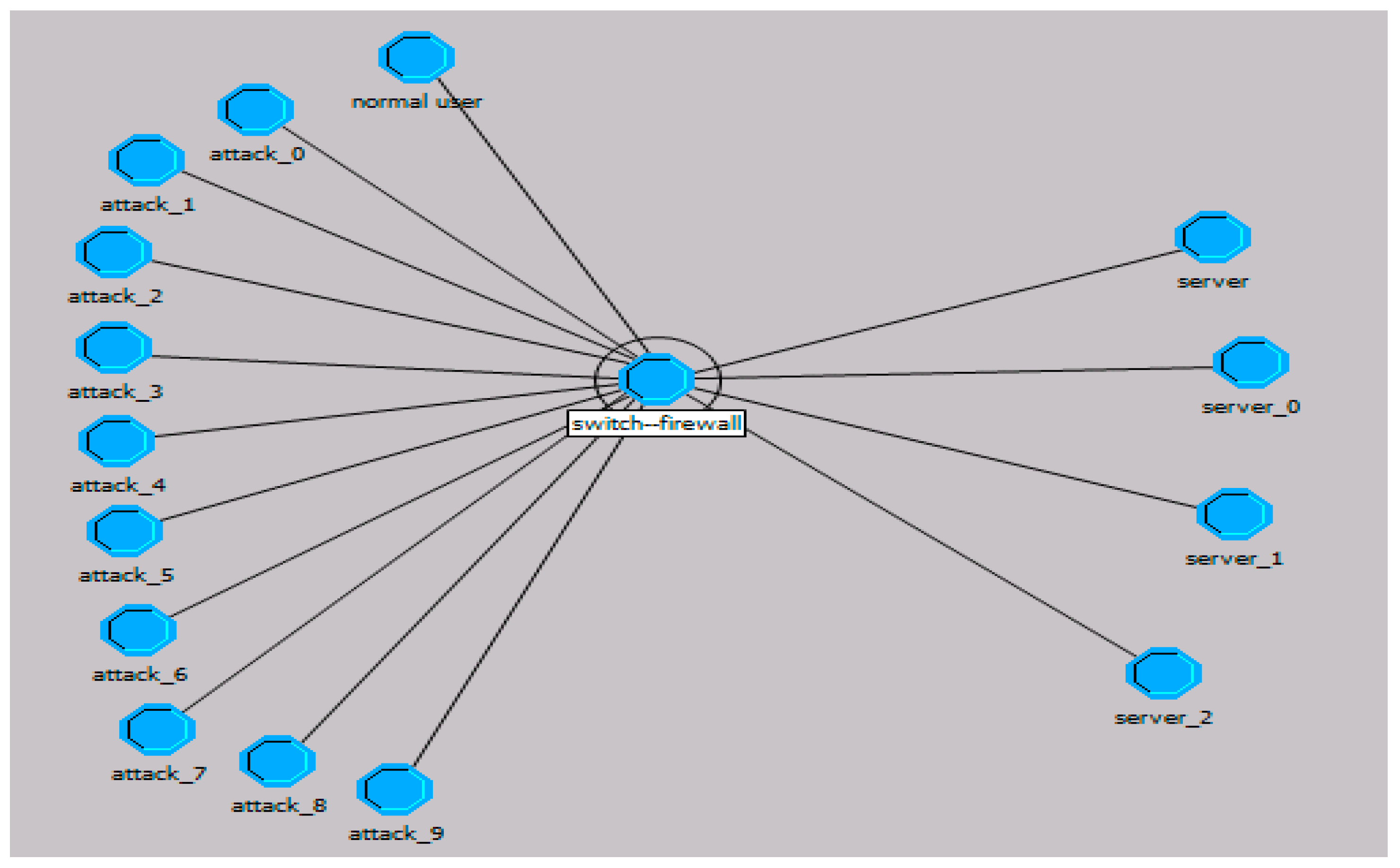
4. Simulation and Analysis
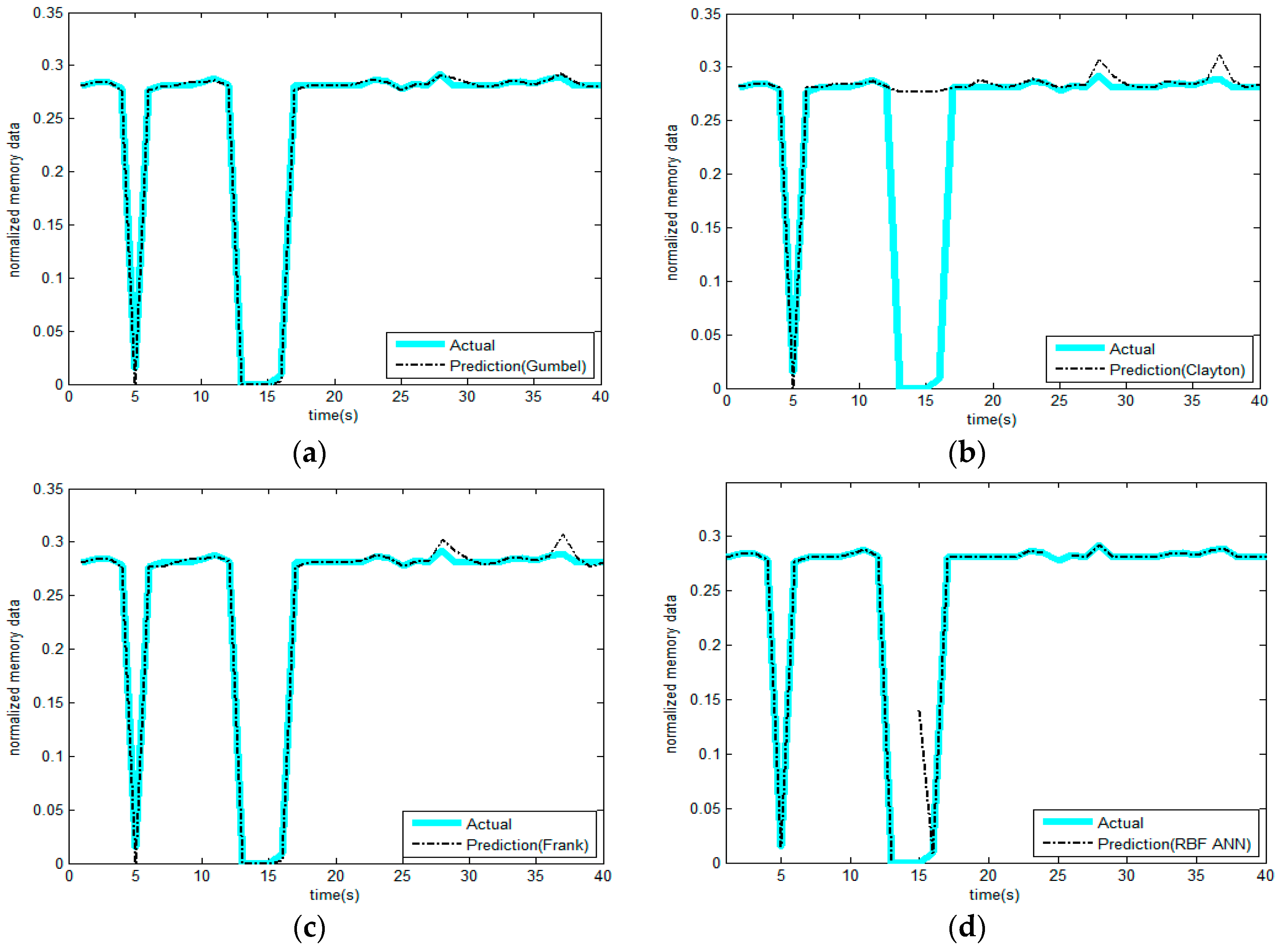
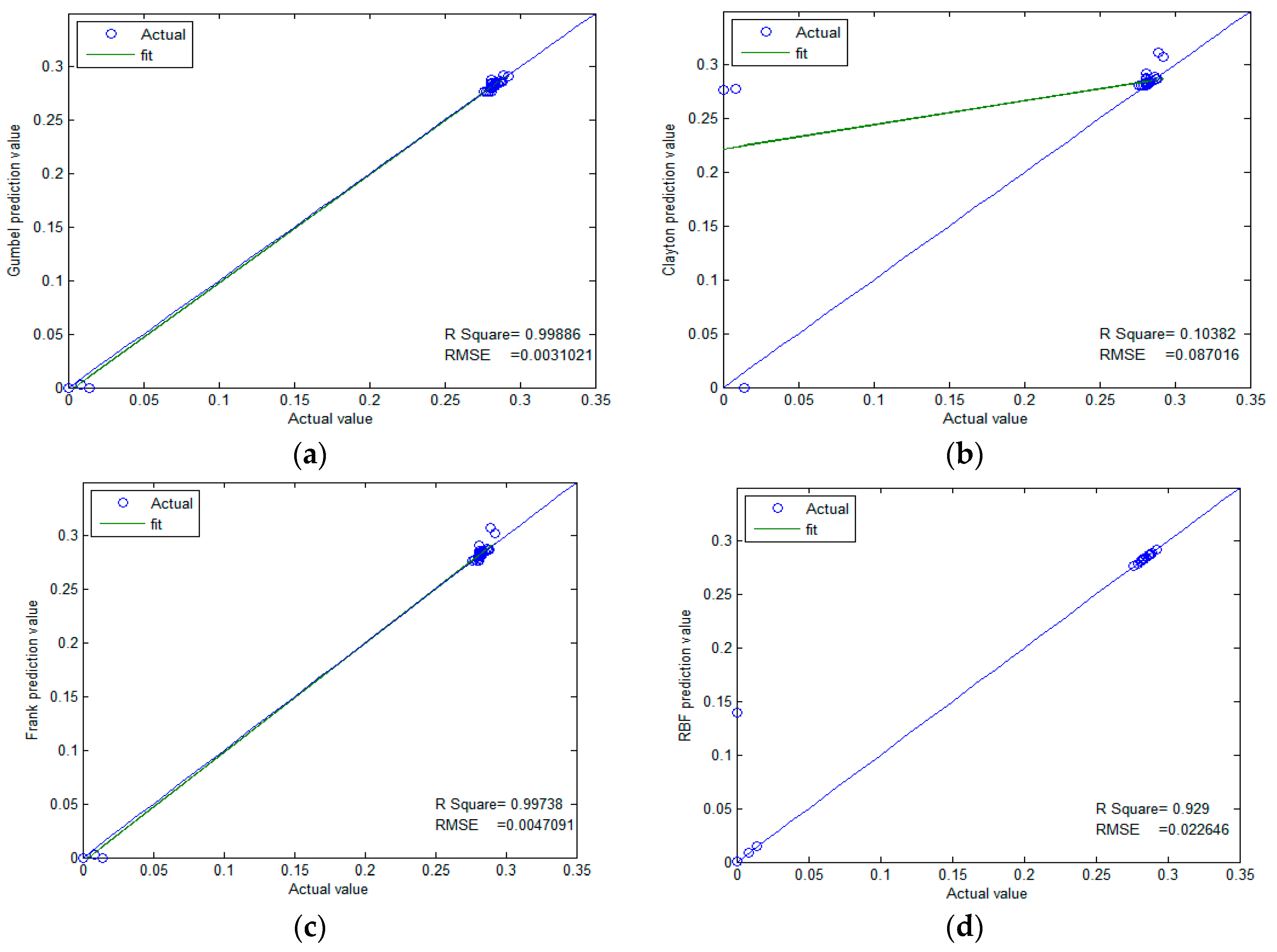
4.1. Simulation of the Alert Model
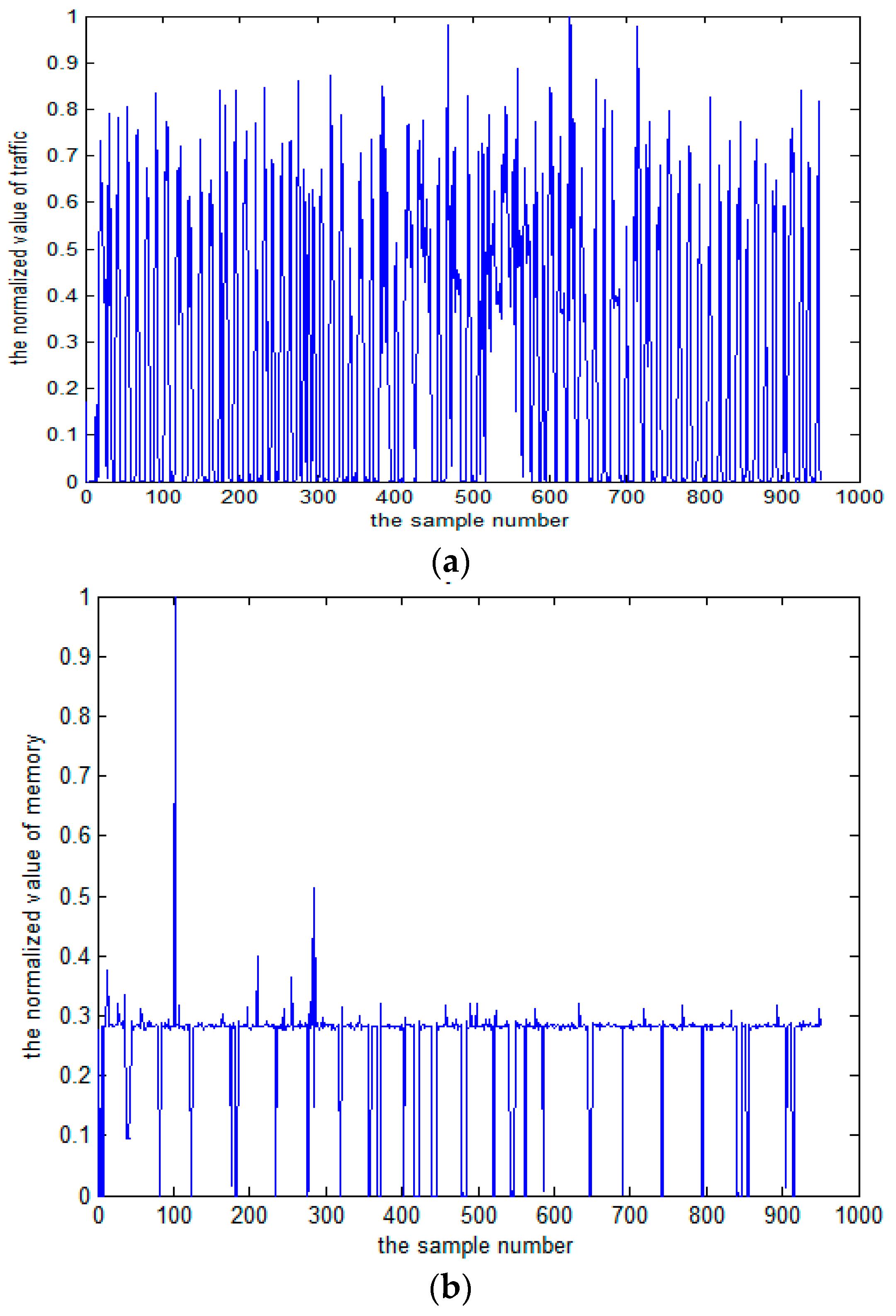
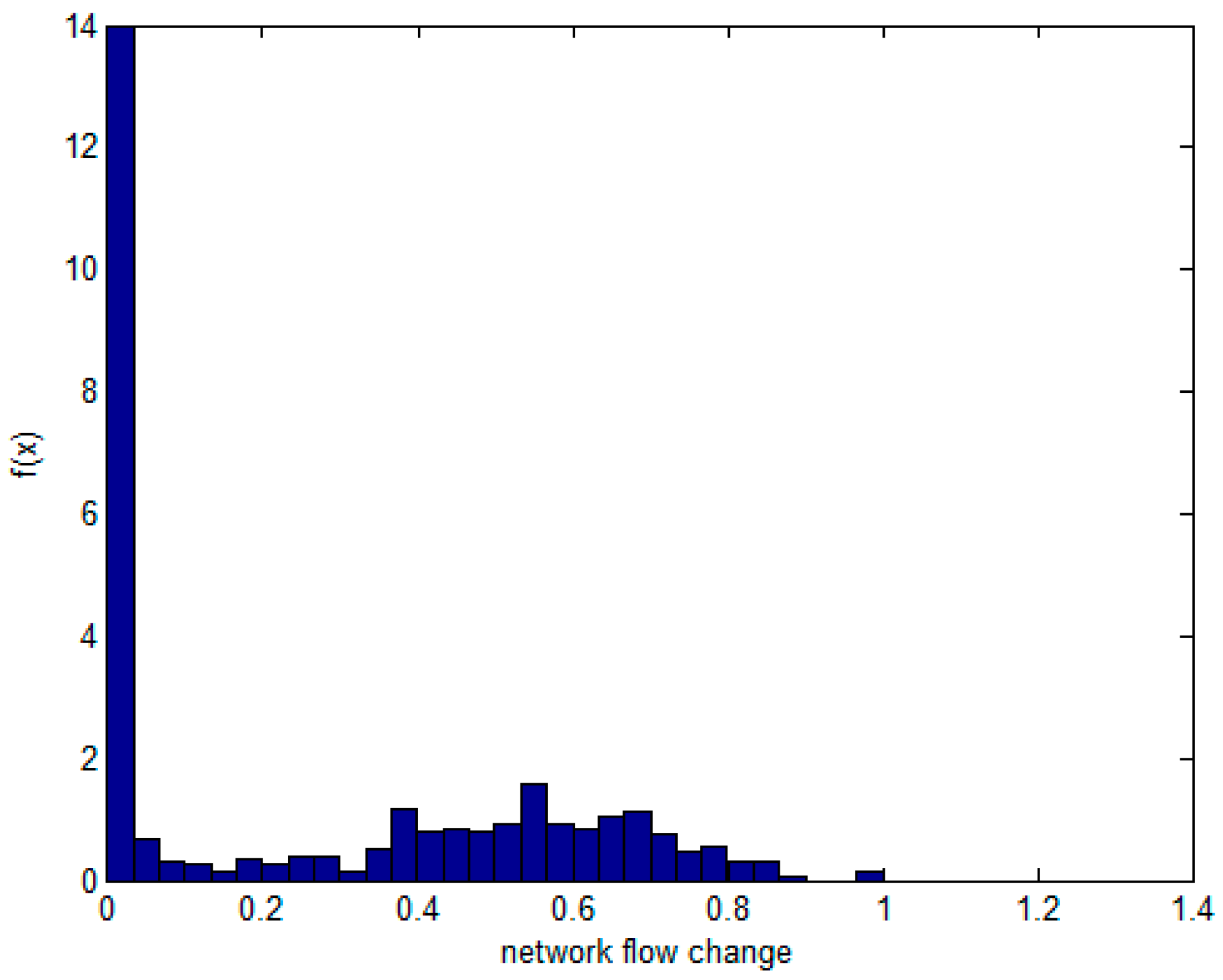
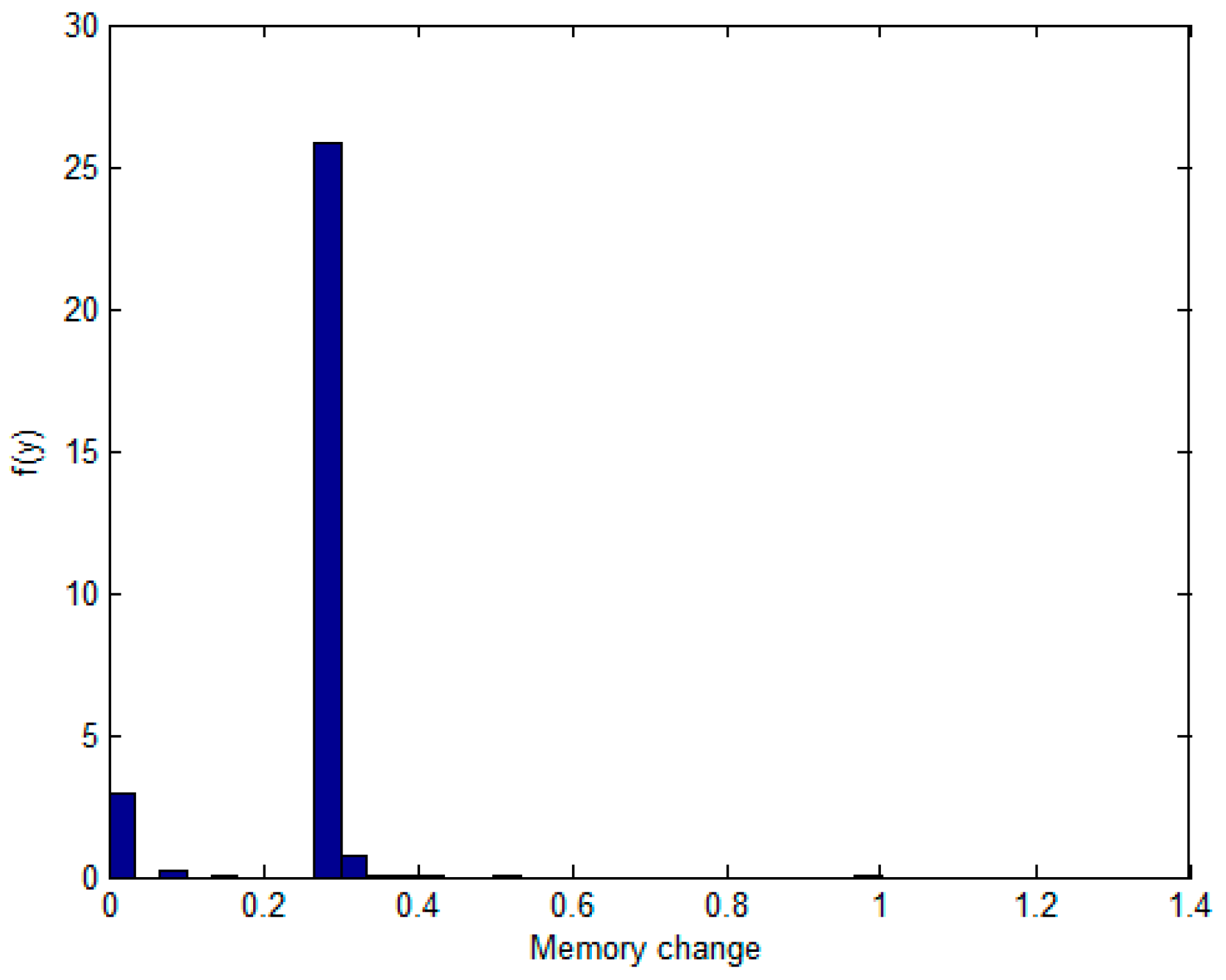
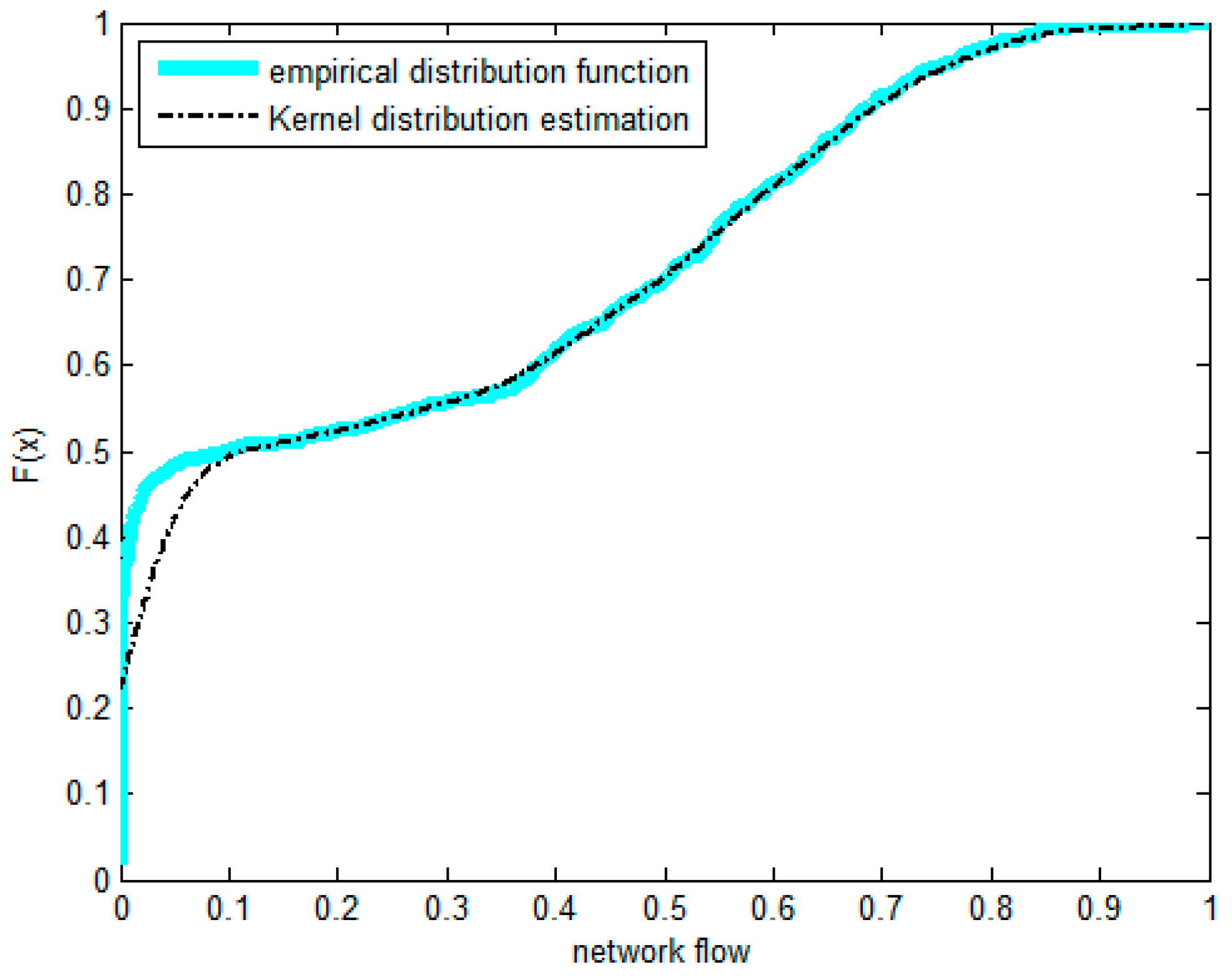
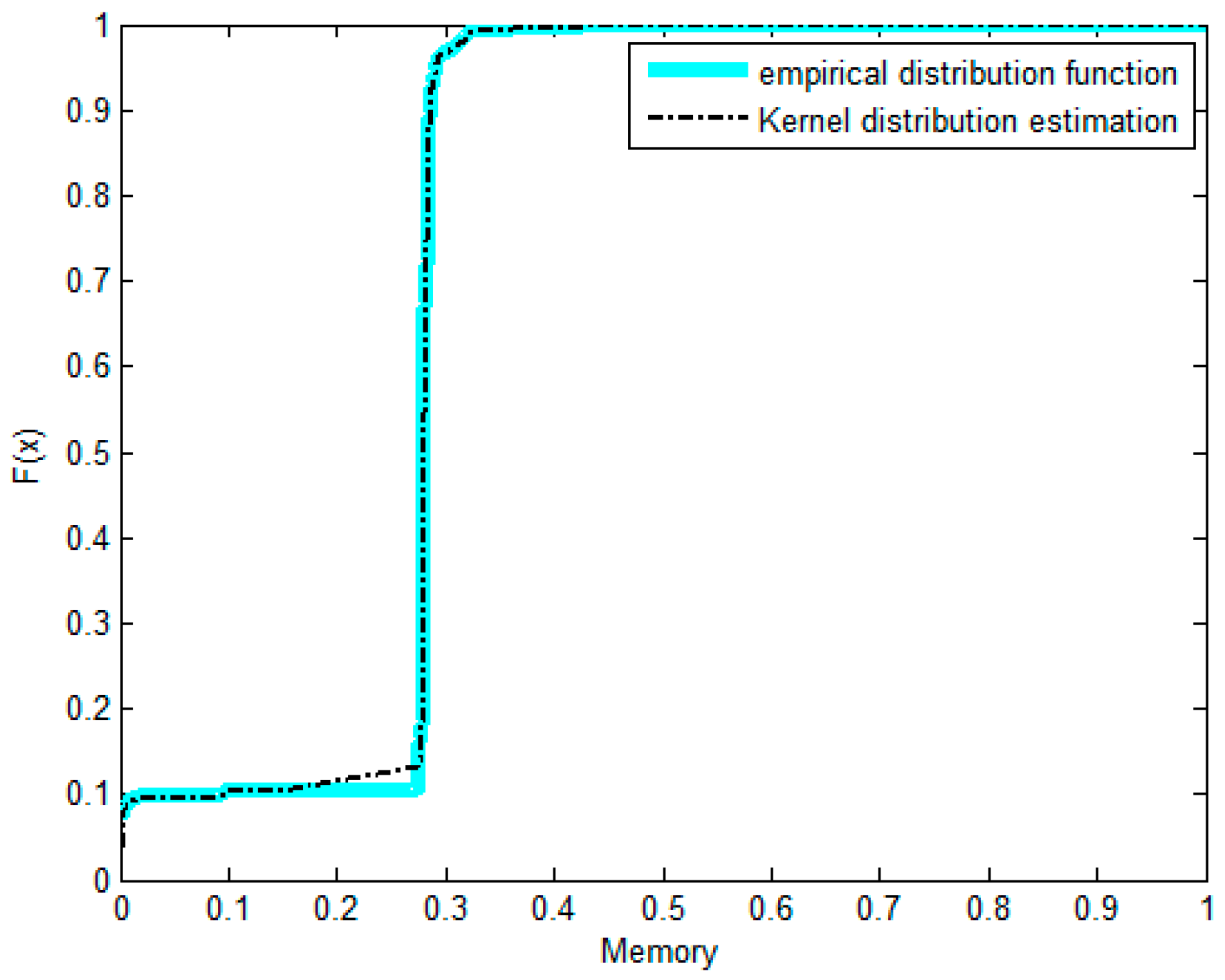
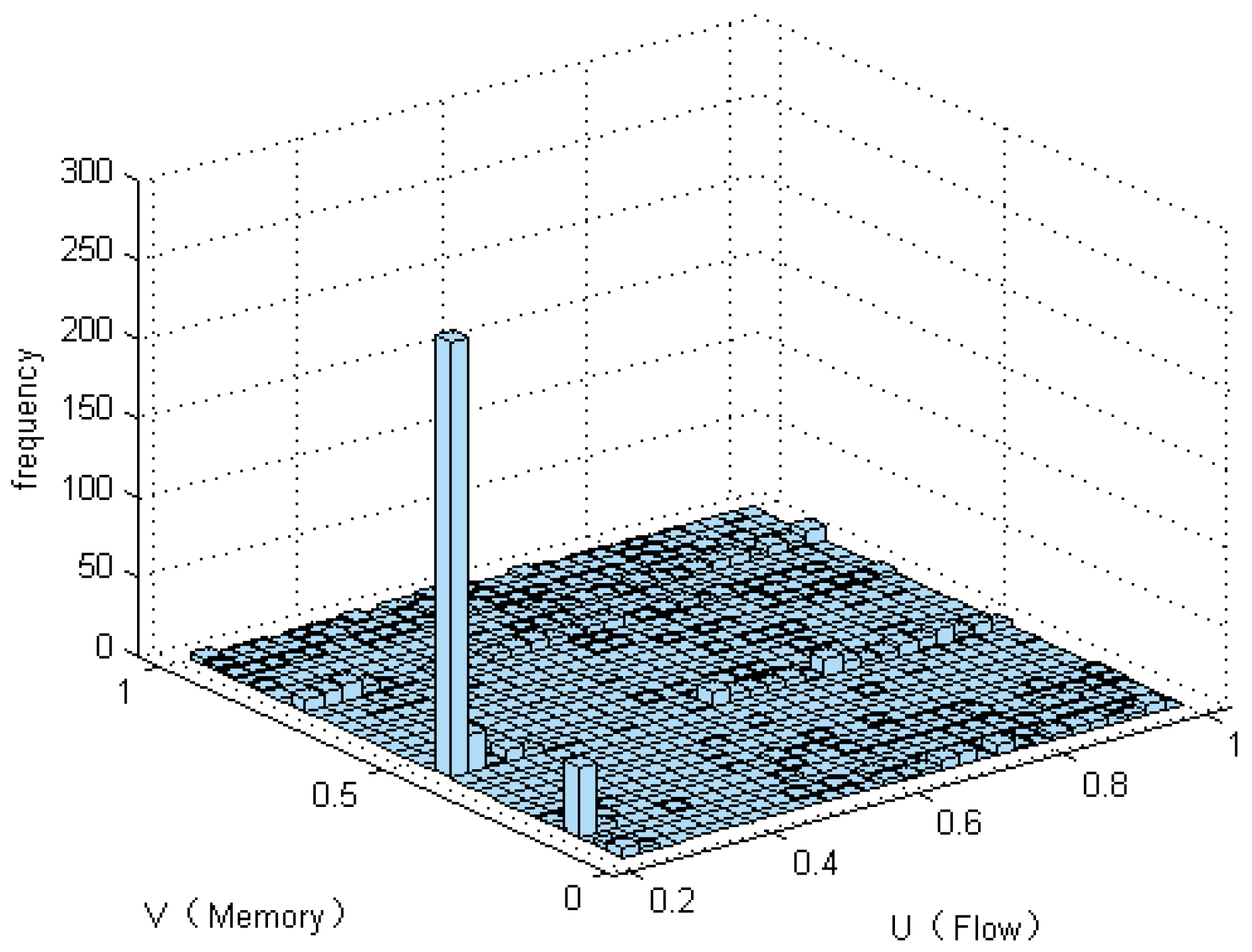
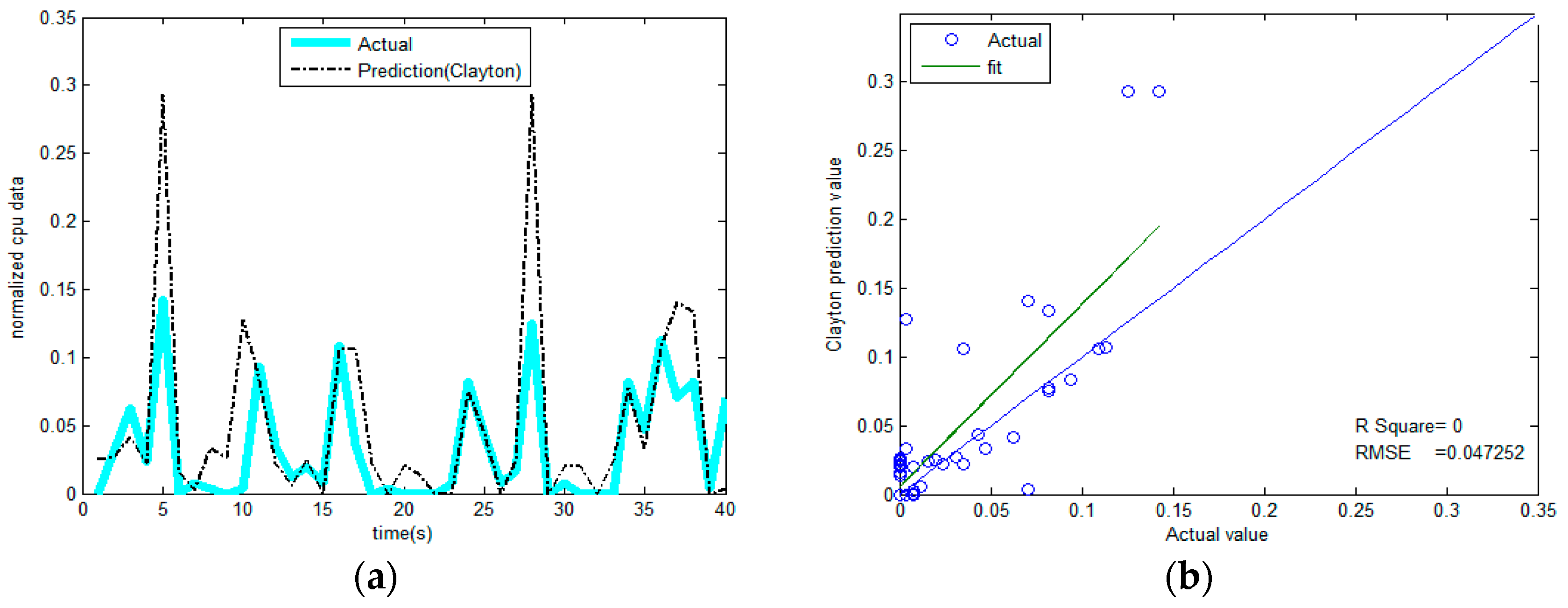
- The non-parametric methods are used to determine the X and Y of the distribution, including the empirical density function and kernel density function.The polynomial spline interpolation method is used to obtain a continuous curve for the empirical distribution of the original sample. As shown in Figure 7 and Figure 8, the two variables’ empirical distribution function and kernel estimation are basically coincident.
- 3.
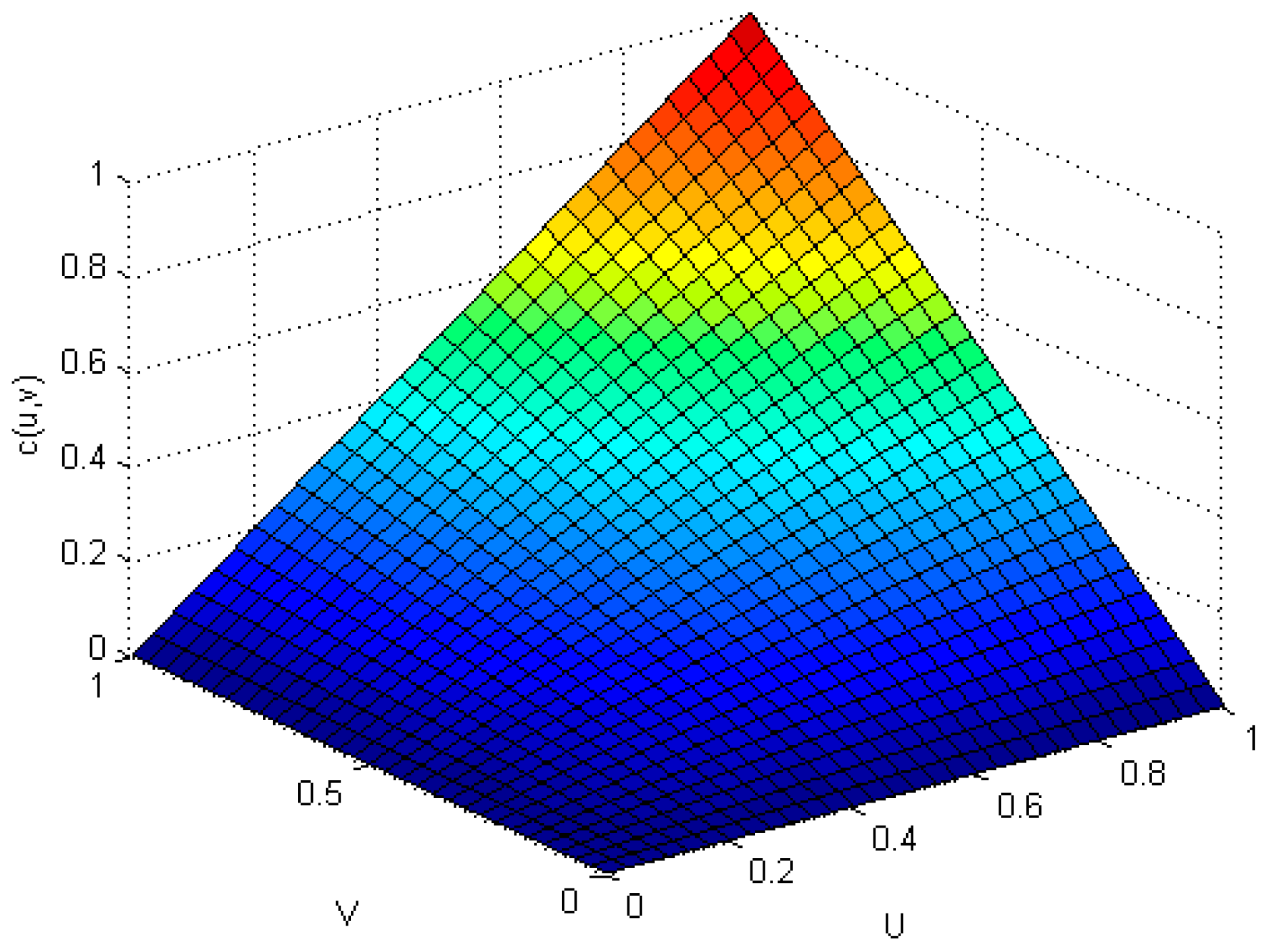
- The sample value of the known variable X in t + 1() is 0.0000978. The corresponding marginal distribution probability is computed through interpolation. Put α into the Gumbel-copula formula.
- 4.
- Proceed with the fitting of the samples. We obtain an approximate Equation (31) as follows:
Risk Assessment
4.2. Simulation of Incomplete Strategy of the Minority Game
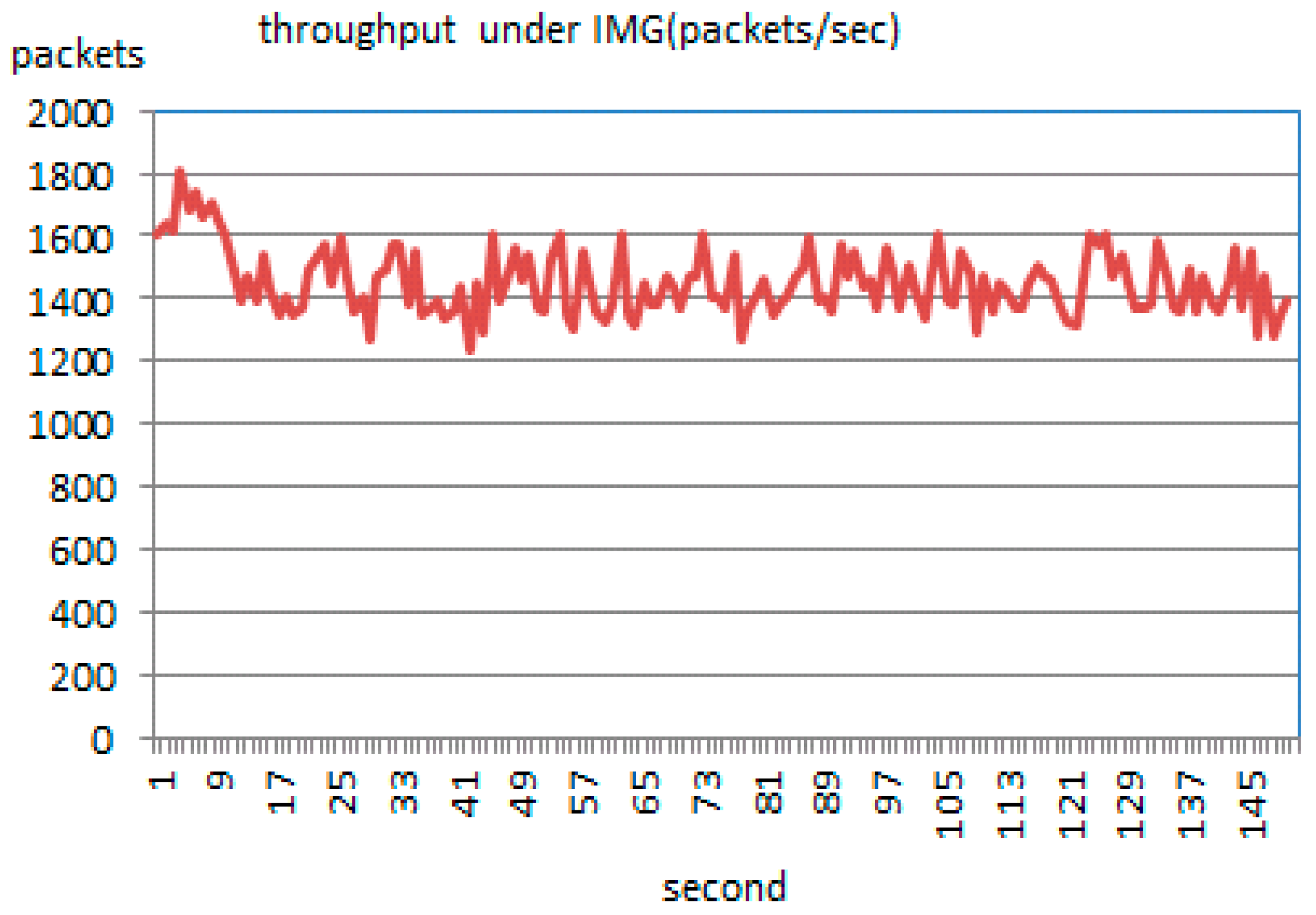
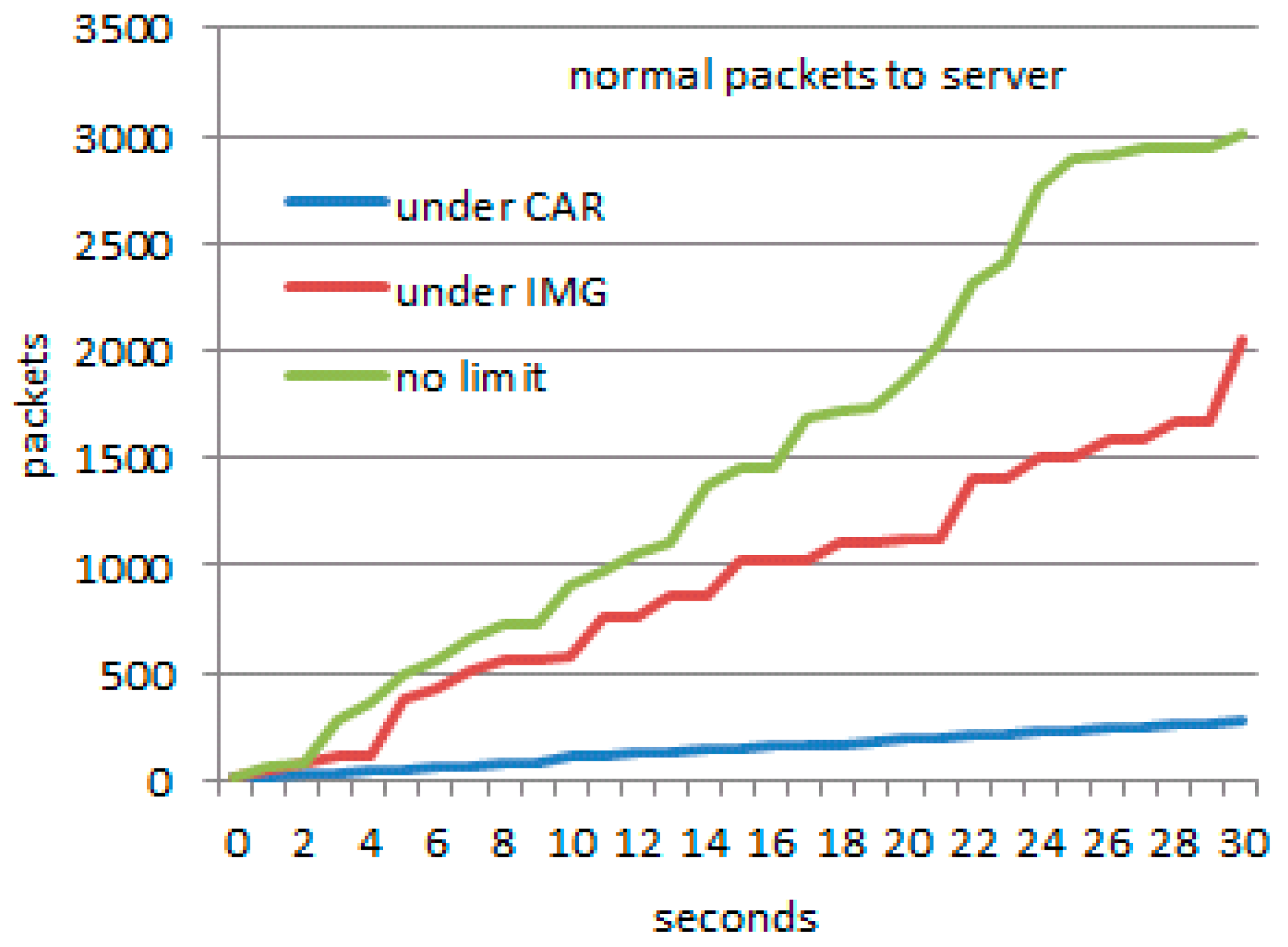
4.2.1. Simulation Process for Scenario 1
4.2.2. Simulation Process for Scenario 2
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- CDNetworks. 2015 DDoS Attack Trends and Outlook for 2016. Available online: http://www.cdnetworks.com.sg/cdnetworks-publishes-2015-ddos-attack-trends-and-outlook-for-2016/ (accessed on 10 January 2016).
- Lee, K.; Kim, J.; Kwon, K.H.; Han, Y.; Kim, S. DDoS attack detection method using cluster analysis. Expert Syst. Appl. 2008, 34, 1659–1665. [Google Scholar] [CrossRef]
- Sachdeva, M.; Kumar, K.; Singh, G. A comprehensive approach to discriminate DDoS attacks from flash events. J. Inf. Secur. Appl. 2016, 26, 8–22. [Google Scholar] [CrossRef]
- Malecki, F. Simple ways to dodge the DDoS bullet. Netw. Secur. 2012, 8, 18–20. [Google Scholar] [CrossRef]
- Zhang, C.; Cai, Z.; Chen, W.; Luo, X.; Yin, J. Flow level detection and filtering of low-rate DDoS. Comput. Netw. 2012, 56, 3417–3431. [Google Scholar] [CrossRef]
- Mehic, M.; Slachta, J.; Voznak, M. Whispering through DDoS attack. Perspect. Sci. 2016, 7, 95–100. [Google Scholar] [CrossRef]
- Shiaeles, S.N.; Katos, V.; Karakos, A.S.; Papadopoulos, B.K. Real time DDoS detection using fuzzy estimators. Comput. Secur. 2012, 31, 782–790. [Google Scholar] [CrossRef]
- Lee, S.M.; Kim, D.S.; Lee, J.H.; Park, J.S. Detection of DDoS attacks using optimized traffic matrix. Comput. Math. Appl. 2012, 63, 501–510. [Google Scholar] [CrossRef]
- Li, M. Change trend of averaged Hurst parameter of traffic under DDOS flood attacks. Comput. Secur. 2006, 25, 213–220. [Google Scholar] [CrossRef]
- Gulisano, V.; Callau-Zori, M.; Zhang, F.; Ricardo, J.-P.; Marina, P. STONE: A streaming DDoS defense framework. Expert Syst. Appl. 2015, 42, 9620–9633. [Google Scholar]
- Upadhyay, R.; Bhatt, U.R.; Tripathi, H. DDOS Attack Aware DSR Routing Protocol in WSN. Procedia Comput. Sci. 2016, 78, 68–74. [Google Scholar] [CrossRef]
- Mansfield-Devine, S. The growth and evolution of DDoS. Netw. Secur. 2015, 2015, 13–20. [Google Scholar] [CrossRef]
- Arun Raj Kumar, P.; Selvakumar, S. Detection of distributed denial of service attacks using an ensemble of adaptive and hybrid neuro-fuzzy systems. Comput. Commun. 2013, 36, 303–319. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. An empirical evaluation of information metrics for low-rate and high-rate DDoS attack detection. Pattern Recognit. Lett. 2015, 51, 1–7. [Google Scholar] [CrossRef]
- Xiao, P.; Qu, W.; Qi, H.; Li, Z. Detecting DDoS attacks against data center with correlation analysis. Comput. Commun. 2015, 67, 66–74. [Google Scholar] [CrossRef]
- Alenezi, M.N.; Reed, M.J. Uniform DoS traceback. Comput. Secur. 2014, 45, 17–26. [Google Scholar] [CrossRef]
- Saied, A.; Overill, R.E.; Radzik, T. Detection of known and unknown DDoS attacks using Artificial Neural Networks. Neurocomputing 2016, 172, 385–393. [Google Scholar] [CrossRef]
- Beitollahi, H.; Deconinck, G. A Four-StepTechnique forTackling DDoS Attacks. Procedia Comput. Sci. 2012, 10, 507–516. [Google Scholar] [CrossRef]
- Tariq, U.; Malik, Y.; Abdulrazak, B.; Hong, M.P. Collaborative Peer to Peer Defense Mechanism for DDoS Attacks. Procedia Comput. Sci. 2011, 5, 157–164. [Google Scholar] [CrossRef]
- Dou, W.; Chen, Q.; Chen, J. A confidence-based filtering method for DDoS attack defense in cloud environment. Future Gen. Comput. Syst. 2013, 29, 1838–1850. [Google Scholar] [CrossRef]
- Vissers, T.; Somasundaram, T.S.; Pieters, L.; Govindarajan, K.; Hellinckx, P. DDoS defense system for web services in a cloud environment. Future Gen. Comput. Syst. 2014, 37, 37–45. [Google Scholar] [CrossRef]
- Spyridopoulos, T.; Karanikas, G.; Tryfonas, T.; Oikonomou, G. A game theoretic defence framework against DoS/DDoS Cyber Attacks. Comput. Secur. 2013, 38, 39–50. [Google Scholar] [CrossRef]
- Chen, Y.; Fu, Y.; Wu, X. Active defense strategy selection based on non-zero-sum attack-defense game model. J. Comput. Appl. 2013, 33, 1347–1349. [Google Scholar] [CrossRef]
- Shen, Y.; Yan, Z.; Kantola, R. Analysis on the acceptance of Global Trust Management for unwanted traffic control based on game theory. Comput. Secur. 2014, 47, 3–25. [Google Scholar] [CrossRef]
- Bedi, H.; Roy, S.; Shiva, S. Mitigating congestion based DoS attacks with an enhanced AQM technique. Comput. Commun. 2015, 56, 60–73. [Google Scholar] [CrossRef]
- Chen, F.; Gou, C.; Guo, X.; Gao, J. Prediction of stock markets by the evolutionary mix-game model. Phys. A 2008, 387, 3594–3604. [Google Scholar] [CrossRef]
- Chau, H.F.; Chow, F.K.; Ho, K.H. Minority game with peer pressure. Physica A 2004, 332, 483–495. [Google Scholar] [CrossRef]
- Wang, Z.X.; Deng, Z.Z.; Li, L. Fair and efficient network congestion control algorithm based on minority game with local information. J. Commun. 2014, 35, 148–155. [Google Scholar]
- Internet Engineering Task Force (IETF). Computing TCP's Retransmission Timer. Available online: http://ietfreport.isoc.org/idref/rfc6298/ (accessed on 20 June 2016).
- Sklar, A. Random variables, joint distributions, and copulas. Kybernetika 1973, 9, 449–460. [Google Scholar]
- Genest, C.; Rivest, L. Statistical inference procedures for bivariate Archimedean copulas. J. Am. Stat. Assoc. Theory Methods 1993, 88, 1034–1043. [Google Scholar] [CrossRef]
- Chao, M.; Xin, S.Z.; Min, L.S. Neural network ensembles based on copula methods and Distributed Multiobjective Central Force Optimization algorithm. Eng. Appl. Artif. Intell. 2014, 32, 203–212. [Google Scholar] [CrossRef]
- Nelsen, R. An Introduction to Copulas; Springer: New York, NY, USA, 2006. [Google Scholar]
- Reinhold, K.; Engqvist, L.; Consul, A.; Ramm, S. A Male birch catkin bugs vary copula duration to invest more in matings with novel females. Anim. Behav. 2015, 109, 161–166. [Google Scholar] [CrossRef]
- Kazianka, H.; Pilz, J. Copula-based geostatistical modeling of continuous and discrete data including covariates. Stoch. Environ. Res. Risk Assess. 2010, 24, 661–673. [Google Scholar] [CrossRef]
- Challet, D.; Zhang, Y.C. Emergence of cooperation and organization in an evolutionary game. Physica A 1997, 246, 407–418. [Google Scholar] [CrossRef]
- Yang, S.; Sun, S. The minority game with incomplete strategies. Physica A 2007, 379, 645–653. [Google Scholar] [CrossRef]
- Bottazzi, G.; Devetag, G. A laboratory experiment on the minority game. Physica A 2003, 324, 124–132. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategyn−2 | Strategyn−1 | Staten−2 | Staten−1 | Current Scenarios Estimate | Choice |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | Never send or choose not to send in the first couple of steps, did not affect the resources, could be estimated as the normal flows. | 1 |
| 0 | 0 | 0 | 1 | Never send or choose not to send in the first couple of steps, affected the resources, could be estimated as the attack flows. | 0 |
| 0 | 0 | 1 | 0 | Never send or choose not to send in the first couple of steps, affected the resources, could be estimated as the attack flows. | 0 |
| 0 | 0 | 1 | 1 | Never send or choose not to send in the first couple of steps, affected the resources, could be estimated as the attack flows. | 0 |
| 0 | 1 | 0 | 0 | Choose to send in the previous step, did not affect the resources, could be estimated as the normal flows. | 1 |
| 0 | 1 | 0 | 1 | Choose to send in the previous step, affect the resources, could be estimated as the attack flows. | 0 |
| 0 | 1 | 1 | 0 | Choose not to send in the first couple of steps, affect the resources, choose to send in the previous step, did not affect the resources, could be estimated as the normal flows. | 1 |
| 0 | 1 | 1 | 1 | Choose not to send in the first couple of steps, affect the resources, choose to send in the previous step, affect the resources, could be estimated as the attack flows. | 0 |
| 1 | 0 | 0 | 0 | Choose to send in the first couple of steps, did not affect the resources, choose not to send in the previous step, did not affect the resources, could be estimated as the normal flows. | 1 |
| 1 | 0 | 0 | 1 | Choose to send in the first couple of steps, did not affect the resources, choose not to send in the previous step, affect the resources, could be estimated as the normal flows. | 1 |
| 1 | 0 | 1 | 0 | Choose to send in the first couple of steps, affect the resources, choose not to send in the previous step, did not affect the resources, could be estimated as the attack flows. | 0 |
| 1 | 0 | 1 | 1 | Choose to send in the first couple of steps, affect the resources, choose not to send in the previous step, affect the resources, could be estimated as the attack flows. | 0 |
| 1 | 1 | 0 | 0 | Choose to send in the first couple of steps, did not affect the resources, could be estimated as the normal flows. | 1 |
| 1 | 1 | 0 | 1 | Choose to send in the first couple of steps, did not affect the resources, could be estimated as the attack flows. | 0 |
| 1 | 1 | 1 | 0 | Choose to send in the first couple of steps, affect the resources, but did not affect in the first step, could be estimated as the normal flows. | 1 |
| 1 | 1 | 1 | 1 | Choose to send in the first couple of steps, all affected resources, but did not affect in the first step, could be estimated as the attack flows. | 0 |
| Parameters | Flow | CPU | Memory |
|---|---|---|---|
| –0.0821 | 0.0055 | –0.0570 | |
| –0.3954 | –0.3412 | –0.4276 | |
| –0.3523 | –0.2012 | –0.4752 | |
| 0.3720 | 0.1495 | 0.1785 | |
| β | 0.4278 | 0.5000 | 0.3352 |
| γ | 0.5722 | 0.5000 | 0.5973 |
| v | 3.0958 | 3.0703 | 6.0349 |
| –0.2036 | 0.0209 | –0.2782 |
| Parameters | |||
|---|---|---|---|
| The initial parameter values | 0.0793 | 0.2351 | 0.1323 |
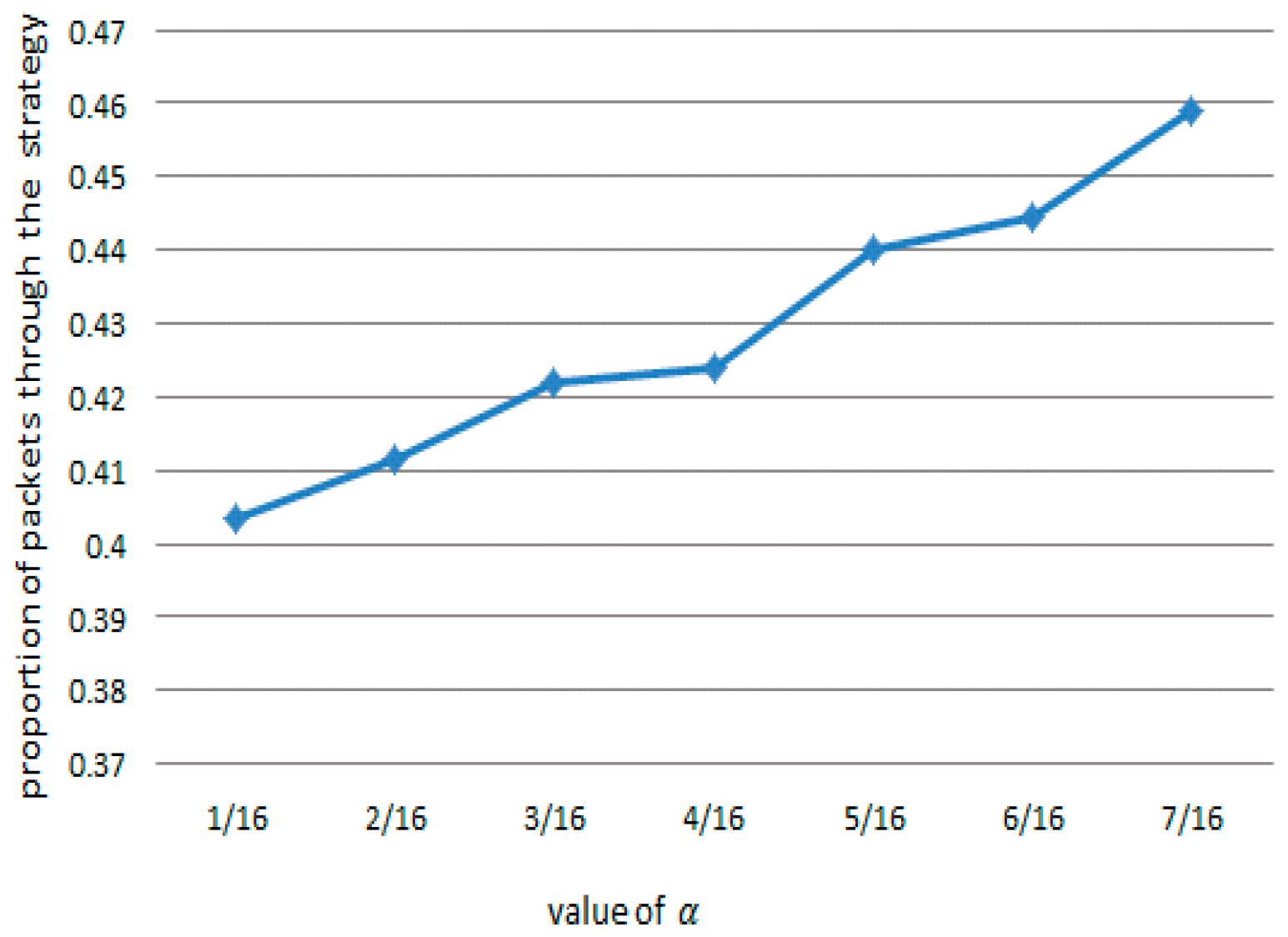
| Value | Simulation Time (Seconds) | IMG (Packets) (Normal Packets Arriving to Server) |
|---|---|---|
| 7/16 | 45 s | 2054 |
| 6/16 | 43 s | 1990 |
| 5/16 | 40 s | 1970 |
| 4/16 | 38 s | 1898 |
| 3/16 | 35 s | 1842 |
| 2/16 | 35 s | 1842 |
| 1/16 | 34 s | 1806 |
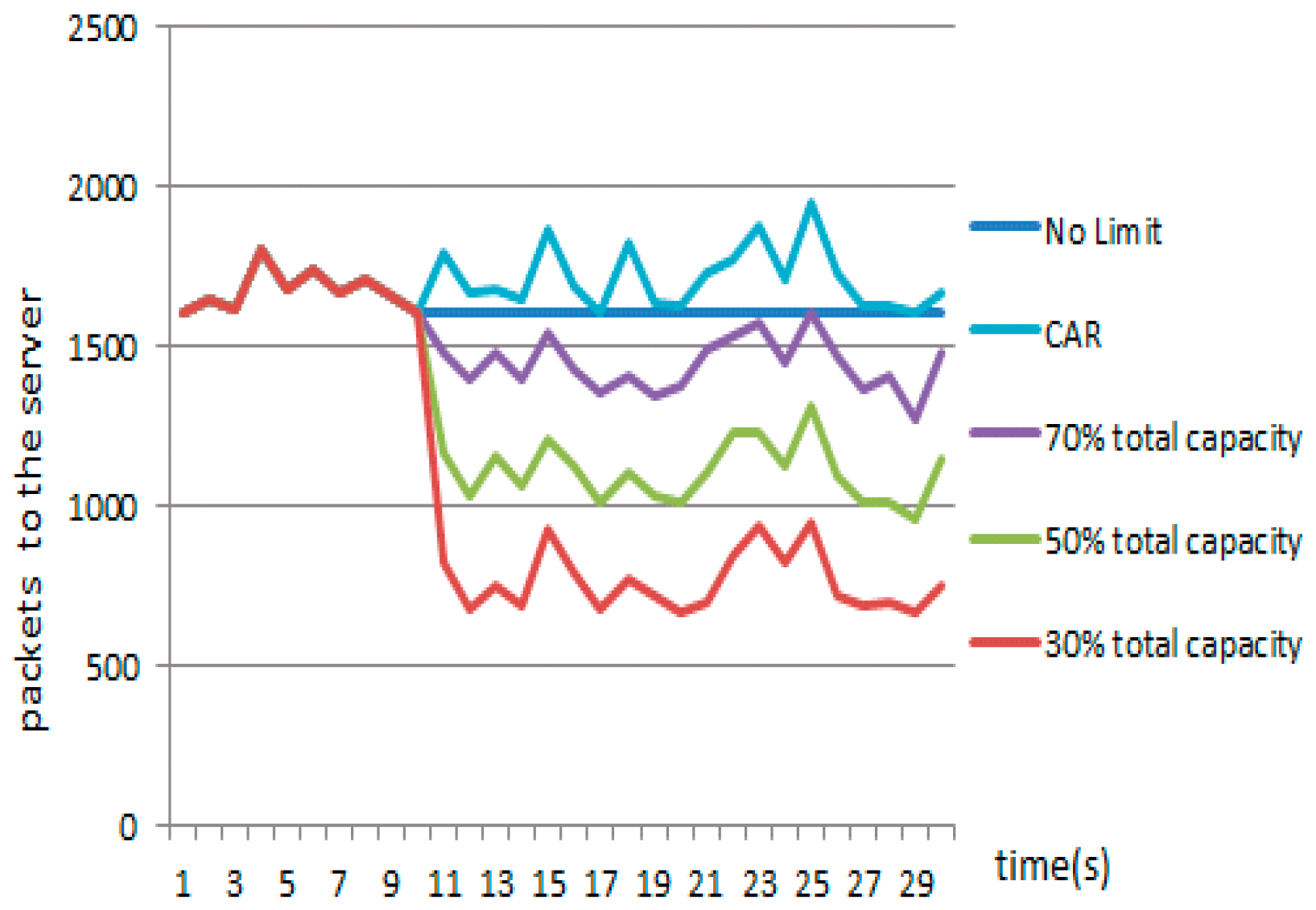
| Attractor Value | IMG (Packets) (Normal Packets Arriving to Server) |
|---|---|
| 70% capacity | 2054 |
| 50% capacity | 1559 |
| 30% capacity | 1119 |
| CAR | 271 |
| No limit | 3012 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Hu, H.; Ke, Q.; Xiong, N. A Novel Topology Link-Controlling Approach for Active Defense of Nodes in Networks. Sensors 2017, 17, 553. https://doi.org/10.3390/s17030553
Li J, Hu H, Ke Q, Xiong N. A Novel Topology Link-Controlling Approach for Active Defense of Nodes in Networks. Sensors. 2017; 17(3):553. https://doi.org/10.3390/s17030553
Chicago/Turabian StyleLi, Jun, HanPing Hu, Qiao Ke, and Naixue Xiong. 2017. "A Novel Topology Link-Controlling Approach for Active Defense of Nodes in Networks" Sensors 17, no. 3: 553. https://doi.org/10.3390/s17030553