1. Introduction
According to Urden et al. [
1], intracranial hemorrhages account for roughly 10% of strokes in the United States. While hemorrhagic strokes are less frequent than ischemic strokes (87%), the former ones present a higher mortality rate. Indeed, it seems that between 37% and 38% of hemorrhagic strokes result in death within 30 days. With approximately 795,000 strokes per year in the United States alone, the number of yearly death cases caused by intracranial hemorrhage is in the range of 30,000. Therefore, intracranial hemorrhage is considered one of the most critical health conditions, demanding rapid intervention and intensive post-traumatic healthcare. Rapid intervention requires an urgent diagnosis for this life-threatening condition. Severe headache or loss of consciousness are neurological symptoms often associated with intracranial hemorrhage. When a patient shows such symptoms, highly trained radiologists typically analyze CT scans of the patient’s brain to find and determine the type of hemorrhage. However, the manual analysis performed by radiologists is complicated and usually time consuming, inherently and undesirably postponing the intervention. In these circumstances, the fast and automatic detection and classification of intracranial hemorrhage is of utter importance.
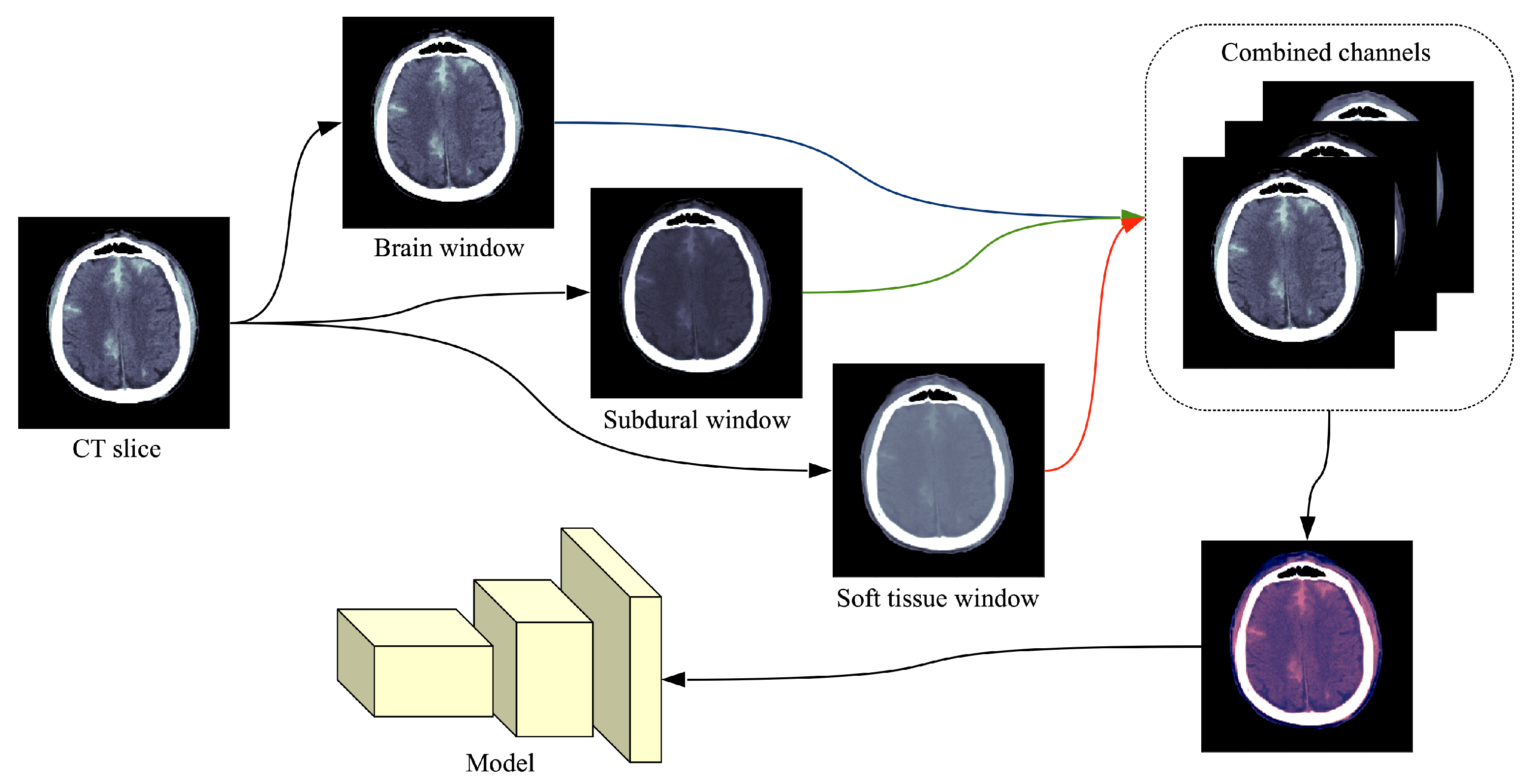
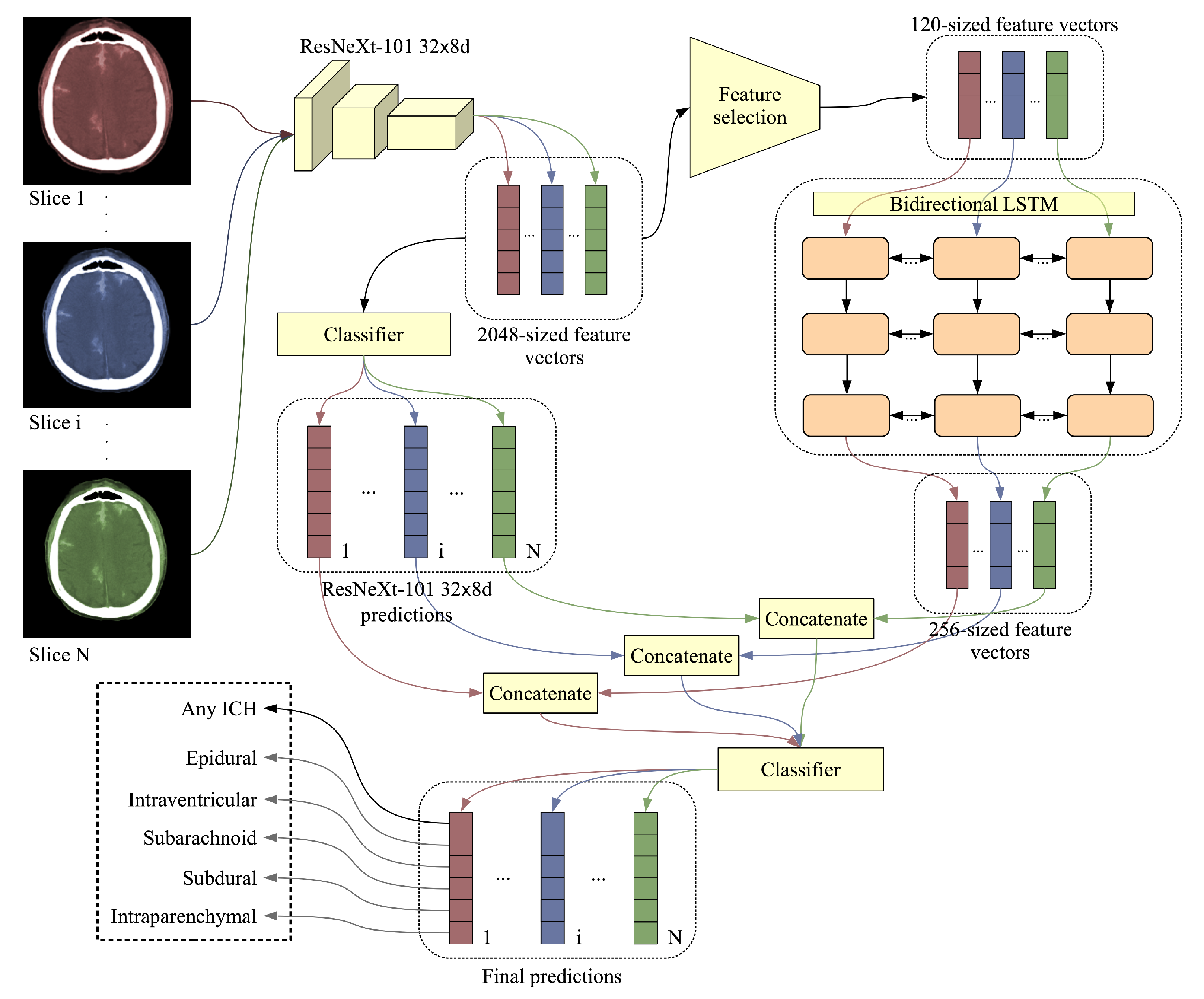
In this paper, we propose an accurate and efficient system based on a lightweight deep neural network architecture composed of a convolutional neural network (CNN) [
2,
3] that takes as input individual CT slices, and a Long Short-Term Memory (LSTM) network [
4] that takes as input multiple feature embeddings (corresponding to an entire CT scan) provided by the CNN. To our knowledge, there are only a handful of works that employed a similar neural architecture, based on convolutional and recurrent layers, for intracranial hemorrhage detection [
5,
6,
7,
8]. Among these, there is only one prior work that classifies intracranial hemorrhage into subtypes [
8]. The main novelty of our work, differentiating it from the prior literature, consists in integrating a feature selection method for more efficient processing. As such, we consider various ways of selecting useful features from the penultimate layer of the CNN. First of all, we select features by considering the weight assigned by the Softmax layer of the CNN to each feature, with respect to each subtype of intracranial hemorrhage. Second of all, we consider Principal Component Analysis (PCA) as an alternative approach for feature selection. The selected features are given as input to the LSTM, irrespective of the feature selection method. By taking into account slices from an entire CT scan, the LSTM mimics the review process performed by doctors, thus improving the slice-level predictions. In addition, another novelty of our framework is to feed the CNN predictions as input to the Softmax classification layer of the LSTM, concatenating them with the LSTM feature vectors. This brings an accuracy boost with negligible computational overhead. Furthermore, we downscale the CT slices by a factor of
, which allows us to train the model faster. Certainly, reducing the input size and performing feature selection also translates into faster inference times.
Motivated by the goal of providing fast diagnosis and constrained by our computing infrastructure, we designed a system that is focused on minimizing the computational time. Nevertheless, we present empirical results indicating that, using our system, we ranked in the top
(27th place) in the RSNA Intracranial Hemorrhage Detection challenge (
https://www.kaggle.com/c/rsna-intracranial-hemorrhage-detection/), from a total of 1345 participants. In the challenge, the systems were ranked by the weighted mean log loss, and our best score was
. However, this score is not indicative of how well the system performs in comparison to highly trained radiologists. Therefore, after the challenge, we conducted a subjective intracranial hemorrhage detection assessment by radiologists, indicating that the classification accuracy rate of our deep model is on par with that of doctors specialized in reading CT scans.
In order to allow further developments and results replication, we provide our code as open source in a public repository (
https://github.com/warchildmd/ihd). Another contribution of our work is to integrate Grad-CAM visualizations [
9] in our system, providing useful explanations for its predictions. In this paper, we also provide interpretations by a team of radiologists for some of the visualizations produced for difficult or controversial cases. Considering the presented facts, we believe that our system is a viable option when a fast diagnosis or a second opinion on intracranial hemorrhage detection are needed.
In summary, we make four contributions:
We propose a joint convolutional and recurrent neural model for intracranial hemorrhage detection and subtype classification, which incorporates a feature selection method that improves the computational efficiency of our model.
We conduct a human evaluation study to compare the accuracy level of our system to that of highly trained doctors.
We provide our code online for download, allowing our results to be easily replicated.
We provide interpretations explaining the decisions of our model.
The rest of this paper is organized as follows. We present related work in
Section 2. We describe our method in detail in
Section 3. Our experiments and results are presented in
Section 4. We provide interpretations and visualizations to explain our model’s decisions in
Section 5. Finally, we draw our conclusions in
Section 6.
2. Related Work
After the initial success of deep learning [
10] in object recognition from images [
3,
11], deep neural networks have been adopted for a broad range of tasks in medical imaging, ranging from cell segmentation [
12] and cancer detection [
13,
14,
15,
16,
17] to intracranial hemorrhage detection [
5,
8,
18,
19,
20,
21,
22] and CT/MRI super-resolution [
23,
24,
25,
26]. Since we address the task of intracranial hemorrhage detection, we consider related works that are focused on the same task as ours [
5,
6,
7,
8,
18,
19,
20,
21,
22,
27,
28,
29,
30], as well as works that study intracranial hemorrhage segmentation [
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44].
While most of the recent works proposed deep learning approaches such as convolutional neural networks [
18,
20,
21,
22,
27,
29,
30,
37], fully-convolutional networks (FCNs) [
19,
32,
33,
36,
38,
39] and hybrid convolutional and recurrent models [
5,
6,
7,
8], there are still some recent works based on conventional machine learning methods, e.g., superpixels [
43,
44], fuzzy C-means [
31,
35], level set [
42,
43], histogram analysis [
41], thresholding [
40] and continuous max-flow [
34].
Bhadauria et al. [
31] employed fuzzy C-means and region-based active contour for brain hemorrhage segmentation. The authors automatically estimated the parameters that control the propagation of contour through fuzzy C-means clustering. Gautam et al. [
35] used fuzzy C-means with a different purpose, that of removing the skull, applying wavelet transform and thresholding on the remaining tissue. Two other recent methods are based on the idea of thresholding [
40,
41]. Pszczolkowski et al. [
40] used the mean and the median intensity in T2-weighted MRI to compute a segmentation threshold, while Ray et al. [
41] analyzed the density of pixels at different levels of intensity to find the desired threshold. Some methods [
43,
44] partitioned the 2D or 3D images into small segments known as superpixels or supervoxels, respectively. Sun et al. [
44] obtained supervoxels by using C-means clustering and by removing the smaller clusters. Soltaninejad et al. [
43] applied their method on both 2D or 3D images, grouping the superpixels and supervoxels based on their average intensity. They determined the final contour of the hemorrhage region by a distance-regularized level set method. Another method based on the distance-regularized level set method was proposed by Shahangian et al. [
42]. In addition to hemorrhage segmentation, Shahangian et al. [
42] performed classification of segmented regions by extracting shape and texture features. Chung et al. [
34] solved a convex optimization function using the continuous max-flow algorithm. They used an edge indicator for regularization. The methods based on statistical or standard machine learning approaches presented so far [
31,
34,
35,
40,
41,
42,
43,
44] are not suitable for large-scale datasets, requiring manual adjustment of parameters and careful monitoring of the results. Indeed, Chung et al. [
34] acknowledge that such methods can only be used in a semi-automatic scenario. Unlike these methods, we employ deep neural networks, which exhibit a strong generalization capacity and are able to provide accurate and robust results on large image databases.
One of the first works to adopt deep learning for intracranial hemorrhage detection is that of Phong et al. [
21]. The authors found that convolutional neural networks pre-trained on ImageNet [
45] can successfully be used for intracranial hemorrhage diagnosis. Lee et al. [
20] proposed a system composed of four different CNN models pre-trained on ImageNet, while also integrating a method to explain the decisions through Grad-CAM visualizations [
9]. Different from Phong et al. [
21] and Lee et al. [
20], Arbabshirani et al. [
18] trained CNNs from scratch on a large dataset of nearly 50 thousands images. Islam et al. [
37] trained a VGG-16 model with atrous (dilated) convolutions on CT slices. The output corresponding to each CT slice is subsequently processed by a 3D conditional random field that provides the final result considering entire CT scans. Chang et al. [
27] employed a modified Mask R-CNN architecture [
46], in which the backbone is a hybrid 3D and 2D version of Feature Pyramid Networks [
47]. Ker et al. [
29] applied image thresholding to improve the results of a 3D CNN that takes as input multiple consecutive slices. As the 3D convolutions are rather computationally expensive, the authors adopted a shallow architecture with three convolutional and two fully-connected layers. Saab et al. [
30] formulated intracranial hemorrhage detection as a multiple-instance learning task, in which the labels are provided at the scan level instead of the slice level. This allows them to incorporate data from a large number of patients. Rao et al. [
22] used a deep CNN in a framework that finds misdiagnosis of intracranial hemorrhage in order to mitigate the impact of negative patient outcomes. Unlike the methods that employed CNNs for intracranial hemorrhage detection [
18,
20,
21,
22,
27,
29,
30,
37], with or without pre-training, we take our model a step further and use the CNN activations maps from the penultimate layer as input to an LSTM network that processes entire CT scans. This gives our model the ability to correct erratic predictions at the slice level.
For intracranial hemorrhage segmentation, there are a few works [
32,
36,
38,
39] that employed the U-Net model [
12], a fully-convolutional network shaped like an auto-encoder with skip connections. Hssayeni et al. [
36] used the standard U-Net model, their main contribution being a dataset of 82 CT scans. Cho et al. [
32] combined the conventional U-Net architecture with an affinity graph to learn pixel connectivity and obtain smooth (less noisy) segmentation results. Kwon et al. [
38] proposed a Siamese U-Net architecture, in which the long skip-connections are replaced by a Siam block. They reported better results than a conventional U-Net. In order to alleviate the class imbalance problem in their dataset, Patel et al. [
39] introduced a weight map for training a U-Net model with 3D convolutions. Cho et al. [
33] proposed a cascaded framework for intracranial hemorrhage detection and segmentation. For the detection task, they employed a cascade of two CNN models. The positively labeled examples are passed through two FCN models and the corresponding segmentation maps are summed up into a final and more accurate segmentation map. Kuo et al. [
19] trained a patch-based fully convolutional neural network based on a ResNet architecture with 38 layers and dilated convolutions. The authors reported accuracy rates comparable to that of trained radiologists for acute intracranial hemorrhage detection. The state-of-the-art methods based on FCN models [
19,
32,
33,
36,
38,
39] are mainly focused on the segmentation task, whereas our focus is on the detection task. Some of the FCN models are based on 3D convolutions, obtaining better segmentations by considering adjacent CT slices. For the detection task, we propose a more efficient architecture that processes 3D CT scans without requiring 3D convolutions. While being more computationally efficient, our CNN and LSTM architecture is not suitable for segmentation, although we can interpret the Grad-CAM visualizations as some sort of rough segmentation maps.
One of the first works to propose a joint CNN and LSTM model for intracranial hemorrhage detection is that of Grewal et al. [
5]. Their method performs segmentation at multiple levels of granularity and binary classification of intracranial hemorrhage. Another method based on a similar architecture is proposed by Patel et al. [
6]. The authors trained the model on a larger dataset of over 25 thousand slices. Vidya et al. [
7] employed a CNN on CT sub-volumes, combining the outputs at the sub-volume level into an output at the scan level through a recurrent neural network (RNN). Their method is designed to identify hemorrhage, without being able to classify it into the corresponding subtype. Unlike these related methods [
5,
6,
7], we propose a method that is able to classify intracranial hemorrhage into subtypes: epidural, intraparenchymal, intraventricular, subarachnoid, subdural. To our knowledge, the only method with a similar design and the same capability of detecting the five subtypes of intracranial hemorrhage is that of Ye et al. [
8]. They employed a cascaded model, with an RNN for intracranial hemorrhage detection and another RNN for subtype classification. We propose a more efficient model that detects intracranial hemorrhage and classifies it into the corresponding subtype in a single shot. Setting our focus on efficiency and novelty, we employ a feature selection method in order to find the most useful features learned by our CNN, obtaining a compact representation to be used as input to our bidirectional LSTM. This aspect differentiates our model from the related literature.
5. Assessment by Radiologists and Discussion
While our best system attains an impressive log loss value of
, placing us in the top 30 ranking from a total of 1345 participants in the RSNA Intracranial Hemorrhage Detection challenge, it is hard to assess how well it performs with respect to trained radiologists, without a direct comparison. Therefore, we decided to use 100 CT scans (24,290 slices), held out from the validation set, to compare our deep learning models with three specialists willing to participate in our study. Some statistics regarding the ground-truth labels for the selected scans are provided in
Table 4. We note that some CT scans can have multiple subtypes of ICH. Hence, the sum of positive labels for all subtypes (
) is higher than the number of scans labeled as ICH (52).
We provide the outcome of the subjective assessment study by radiologists on the held out CT scans in
Table 5. We compare the annotations provided by three doctors with the labels provided by the CNN model and the joint CNN and LSTM model, respectively. The evaluation metrics are computed at the scan level. For a fair comparison with our systems, the doctors were not given access to the ground-truth labels during the annotation. We note that two of the doctors, doctor #2 and #3, are highly trained specialists, treating intracranial hemorrhage cases on a daily basis in their medical practice. This explains why their scores are much higher than the scores attained by doctor #1, who is a specialist in treating tumors through radiation therapy, rarely encountering intracranial hemorrhage cases in the day to day practice. The study reveals that our deep learning models attain scores very close to those of doctor #2 and #3, even surpassing them for the EPH subtype (our top accuracy being
) and the IPH subtype (our top accuracy being
). Our models are also better at generic ICH detection, our top accuracy being
with the plain CNN model. Based on our subjective assessment study by radiologists, we concluded with the doctors that our models exhibit sufficiently high accuracy levels to be used as a second opinion in their daily medical practice. The team of doctors considered the fact that our AI-based system attains performance levels comparable to those of trained radiologists very impressive.
In order to better assess the behavior of our system with respect to the radiologists included our study, we produced Grad-CAM visualizations [
9] for the CT scans that were wrongly labeled by doctor #2 and by our CNN model (ResNeXt-101
d). We considered all scans that had at least one wrong label. There are 39 wrong labels given by doctor #2 and 40 wrong labels by our system. Interestingly, there is a high overlap (over
) between the wrong labels of doctor #2 and those of our system. Considering that there are 22 mistakes in common, we have strong reasons to suspect that the ground-truth labels might actually be wrong. As the ground-truth labels are also given by specialists [
28], this is a likely explanation for the high overlap between the mistakes of doctor #2 and those of our CNN model. After seeing the ground-truth labels and making a careful reassessment, our team of doctors found at least 25 ground-truth labels that are wrong and another 5 that are disputable. Since the total number of labels for the 100 CT scans is 600 (6 classes × 100 scans), the wrong labels identified in the ground-truth account for less than
from the total amount, which is acceptable. Nevertheless, we emphasize that the CT scans selected for the Grad-CAM-based analysis are either difficult (a doctor or our system produced a wrong label) or controversial (the ground-truth labels are suspect of being wrong). In total, we gathered a set of 35 controversial or difficult scans, with a total of 414 controversial or difficult slices (we did not include slices without wrong labels). For each CT slice and for each positive label provided by our system, we produced a Grad-CAM visualization. Our team of doctors analyzed each and every Grad-CAM visualization, labeling each visualization as correct (the system focuses on the correct region, covering most of hemorrhage, without focusing on other regions), partially correct (the system focuses on some hemorrhage region while also focusing on non-hemorrhage regions or missing some other hemorrhage region) or incorrect (the hemorrhage region is completely outside the focus area of our system). From the total of 414 visualizations,
were labeled as correct,
as partially correct and the remaining
as incorrect. Considering that the 414 slices represent difficult or controversial cases, we believe that the percentage of incorrect visualizations is not high enough to represent a serious concern.
For the correct and partially correct visualizations, the doctors observed that the focus region of the system is not perfectly aligned with the hemorrhage area. When the CT slices contain SAH, a general observation is that our CNN-based system seems to concentrate on the eye orbits, the sinus or the nasal cavities, which is not right. Another general observation is that, for some visualizations labeled as incorrect, the system actually focuses on blood hemorrhage outside the skull, which is not entirely a bad thing, i.e., it is good that the system detects hemorrhage anywhere in the CT image, but it should learn to look for hemorrhage inside the skull only. Doctor #2 labeled 3 CT scans as EPH, but these were false positives. After seeing the ground-truth labels and the Grad-CAM visualizations, the team of doctors (which includes doctor #2) was able to correct the false positives for EPH, confirming the ground-truth labels which indicate that the respective scans contain SDH. The doctors observed that most of the correct visualizations are produced for specific hemorrhage types, namely IPH, IVH and SAH. The worst visualizations are typically produced for the generic ICH class (any type). This is because, during training, the system is not forced to detect all hemorrhage regions in order to label a CT slice as ICH. While it is sufficient for our system to detect at least one hemorrhage region to label the corresponding slice as ICH, the doctors would have expected the system to indicate all hemorrhage regions through the visualization. In order to visualize all hemorrhage regions, the doctors concluded that it is mandatory to jointly consider the Grad-CAM visualizations for all detected types of hemorrhage.
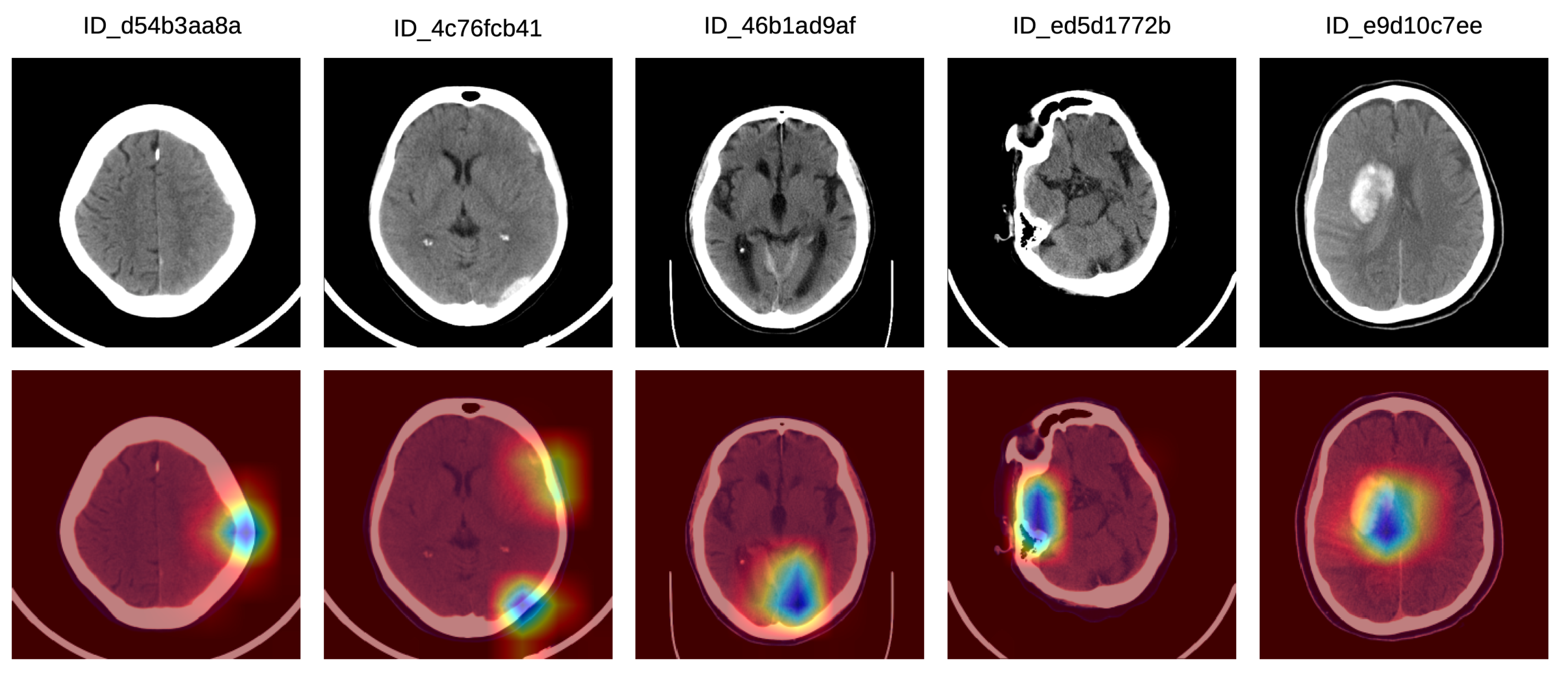
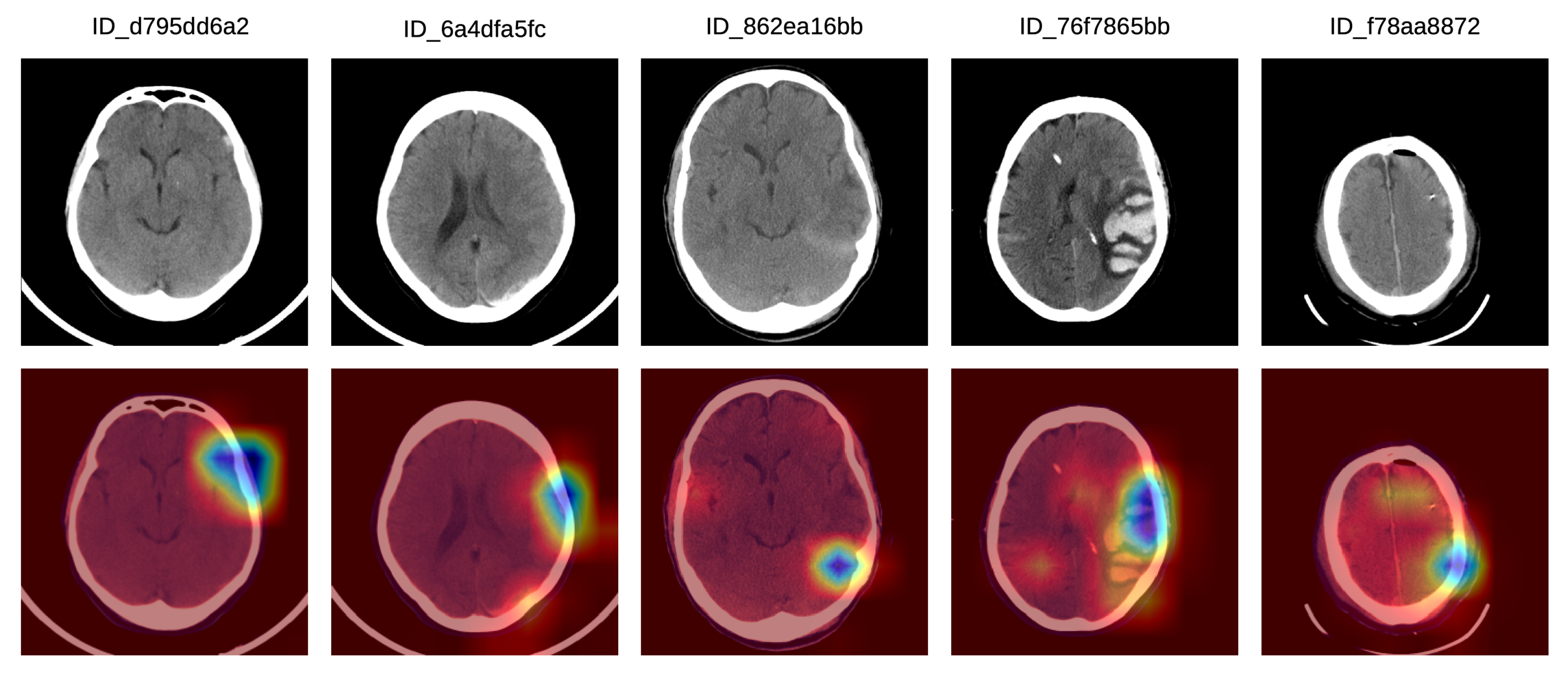
In order to better understand how doctors classified the Grad-CAM visualizations as correct, partially correct or incorrect, we next present a detailed analysis of five particular Grad-CAM examples from each category. In
Figure 5, we illustrate a set of Grad-CAM visualizations that were labeled as correct by the doctors. In the first (left-most) sample, the system concentrates on the subdural hemorrhage in the left frontal lobe. In the second sample, the system correctly concentrates its attention on two hemorrhage regions, one in the left frontal lobe and one in the left parietal lobe. In the following two samples, we observe that our system focuses on hemorrhage in various regions, namely in the posterior median (tentorial) lobe (third example) and in the temporal right lobe (fourth example). In the fifth (right-most) sample in
Figure 5, the hemorrhage within the focus area is located in the right paramedian region, the slice being labeled as IPH and IVH.
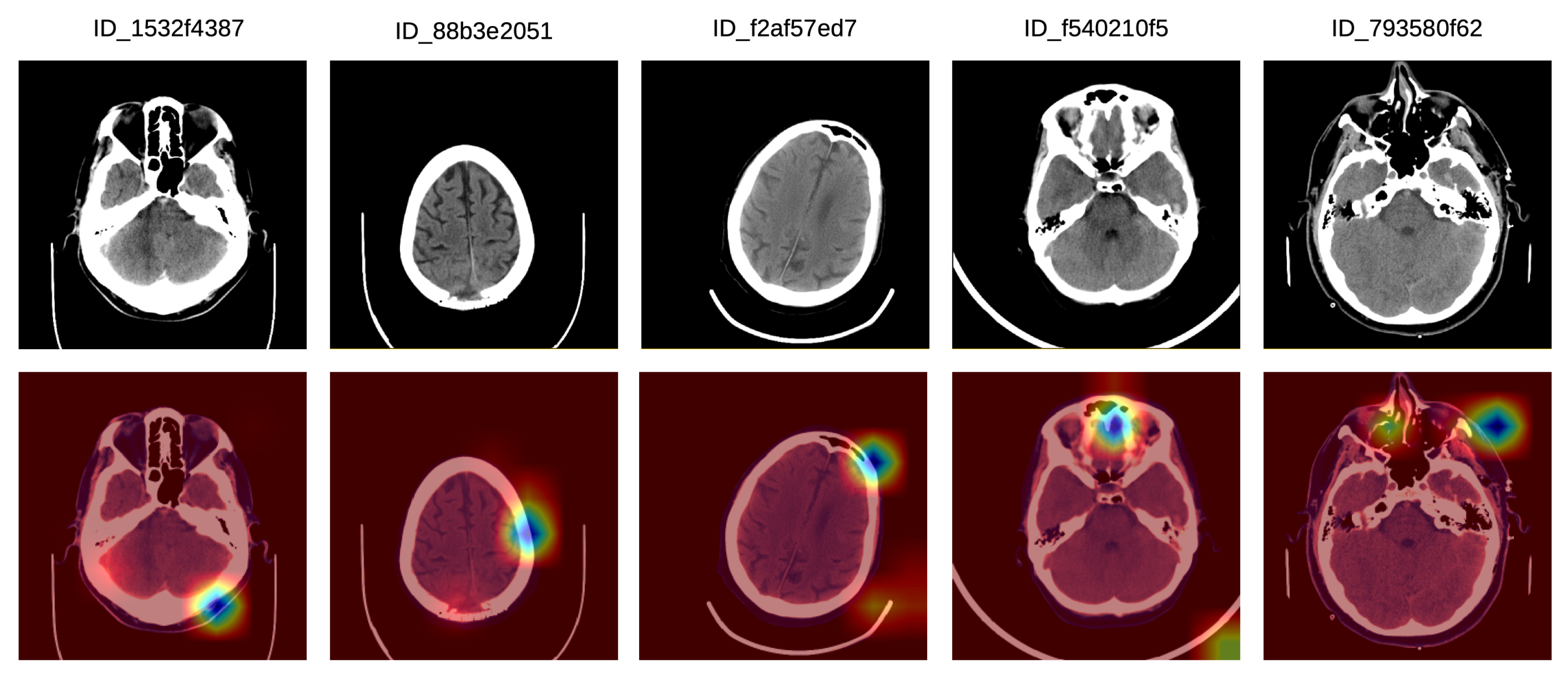
In
Figure 6, we show a set of Grad-CAM visualizations that were labeled as partially correct by the doctors. In the first partially correct sample, the system focuses on the hemorrhage situated in the left frontal lobe, failing to indicate the hemorrhage in the left posterior temporalis. In the second sample from the left, the system focuses on the left frontal hemorrhage, while the left parietal (posterior) hemorrhage is not sufficiently highlighted. In the third Grad-CAM visualization, the system concentrates mostly on the tentorial left (posterior latero-median) hemorrhage, and only barely on the right temporal hemorrhage. The system seems to ignore the hemorrhage in the left temporal lobe. In the fourth partially correct example, the focus region includes the left median temporal IPH and the anterior left frontal SDH, but the right temporal SAH is not sufficiently highlighted by our system. In the fifth (right-most) sample in
Figure 6, our system correctly annotates the SDH in the left frontal lobe, but the SDH in the parietal right lobe is not highlighted by the system.
Finally, we illustrate a set of incorrect Grad-CAM visualizations in
Figure 7. In the left-most sample, there is a bilateral posterior hemorrhage that is outside the focus area of the system, which seems to have turned its attention on extracranial hemorrhage instead. In the second incorrect example, the system focuses on the left frontal lobe, but the lesion is located in the posterior median parietal lobe. In the third example, there is no intracranial injury, and the system seems to focus mostly on the extracranial area, which is not of interest. In the fourth incorrect visualization, there is a left temporal intraparenchymal lesion outside the focus area of the system, which seems to concentrate on the anterior median region instead. In the fifth example in
Figure 7, there is an anterior left temporal lesion which the system does not concentrate on. Instead, the system system focuses on the anterior and the right paramedian regions, and also on the left anterior facial and extracranial mass.
As a generic conclusion of this analysis, the doctors found the Grad-CAM visualizations very useful, considering that the best application of our system is to provide a second informative opinion for ER patients that are suspected of ICH. Here, the system could aid ER doctors in making a fast and correct diagnostic, which could prove crucial in saving a patient’s life.
6. Conclusions
In this paper, we presented an approach based on convolutional and LSTM neural networks for intracranial hemorrhage detection in 3D CT scans. Our method is able to attain performance levels comparable to those of trained specialists, in the same time reaching a loss of in the RSNA Intracranial Hemorrhage Detection challenge, which brings us on the 27th place (top ) from a total of 1345 participants. All these results were obtained while making important design choices to reduce the computational footprint of our model, namely (i) the reduction of CT slices from to pixels and (ii) the inclusion of a feature selection method before passing the CNN embeddings as input to the bidirectional LSTM. We conclude that analyzing hemorrhage at the CT scan level, through a joint ResNeXt and BiLSTM network, is more effective than performing the analysis at the CT slice level, through a single ResNeXt model. We also deduce that performing feature selection is both efficient and effective when it comes to intracranial hemorrhage detection and subtype classification. Furthermore, we performed an analysis of Grad-CAM visualizations for some of the most difficult or controversial CT slices. The team of doctors that performed the manual annotations of the CT slices selected for their subjective assessment concluded that our system is an useful tool for their daily medical practice, providing useful predictions and visualizations.
In future work, we will work closely with the medical team to improve our model by incorporating their feedback. One of the most important problems is that our system can predict the correct label for a certain subtype of intracranial hemorrhage without considering all the locations for the respective subtype. While this behavior produces very good accuracy rates, it is not optimal for visualizing all the regions with hemorrhage. We aim to solve this issue in future work by considering pixel-level annotations, e.g., segments or bounding-boxes, allowing us to penalize the model during training when it fails to detect a certain hemorrhage region.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}