1. Introduction
In every ground excavation project, the rock brittleness needs to be measured as a key property of rock mass. In designing geotechnical engineering structures, especially those that are constructed on the rock mass, a proper insight into the rock’s brittleness is of great value. For instance, using rock-brittleness-related information, engineers are able to assess the wellbore stability and performance quality of a hydraulic fracturing job [
1,
2]. In addition, with the use of such information, the shale rocks mechanic properties can be regulated well. Meanwhile, a number of parameters, including the volumetric fraction of strong minerals, carbonates, weak elements, and pores, can be used to define the Young’s modulus and strength of these properties [
3,
4]. Brittleness also plays an important role in assessing the stability of the surrounding rock mass in deep underground projects [
5].
Brittleness can be the reason behind numerous disastrous incidents associated with rock mechanics, such as rock-bursts [
6,
7,
8,
9]. According to the literature, in the prediction performance of the tunnel boring machines (TBMs) and roadheaders, brittleness can be taken into account as a significant and effective factor [
10,
11]. Moreover, this property can effectively define the excavation effectiveness of drilling, which is a parameter of a great effect in coal mining processes [
12,
13]. As a result, an important part of the projects related to geotechnical and rock engineering, is the measurement of rock brittleness [
7]. Despite all facts explained above, Altindag [
14] argued that no consensus exists on defining and measuring standards of this brittleness. On the other hand, according to Yagiz [
13], various properties of the rock influence rock brittleness. A number of researchers have stated that brittleness is related to the lack of ductility or ductility inversion [
15]. Brittleness was defined by Ramsey [
16] as the loss of the inter-particle cohesion of a rock. According to Obert and Duvall [
17], brittleness is the inclination of a material, like cast iron or lots of rock types, to split due to being subjected to a pressure equivalent to or higher than the yield stress of the material. Normally, highly brittle rock has six characteristics: (1) failure under an insignificant force, (2) having a great compressive-to-tensile strength ratio, (3) the production of small particles, (4) great interior friction angle, (5) great firmness, and (6) the generation of completely developed characteristics following hardness lab experiments [
15,
17]. A review of literature indicates that most of studies carried out into rock brittleness index (BI) have been on the basis of the relationship between tensile and uniaxial compressive strengths of the rock samples [
18,
19,
20,
21,
22]. Nevertheless, only a few researchers have discussed a relationship between BI and other rock properties, such as hardness, quartz content, elasticity modulus, internal friction angle, Poisson’s ratio, etc. [
23,
24,
25]. The models presented have not shown enough capability to estimate BI. The reason is that the majority of these models make use of one or two dependent parameters [
13,
21,
22].
In recent years, many researchers have applied soft computing (SC), artificial intelligence (AI), and machine learning (ML) techniques to solve science and engineering problems [
8,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61,
62,
63,
64,
65,
66,
67,
68,
69,
70,
71,
72,
73,
74,
75]. Although a number of researchers have already confirmed the applicability of ML techniques for solving problems appearing in engineering fields, numerous ML techniques have still remained unused in studies focusing on rock BI prediction. A comprehensive review of the literature showed that no study has been published examining the viability of popular ML techniques, e.g., support vector machine (SVM), in the prediction of BI values. Thus, this study aims to assess the feasibility of SVM to predict BI. To this end, eight SVM models are developed with different approaches. In the following, the principles of the methods and the descriptions of the used material are described. Then, after proposing several empirical equations to predict the rock BI, the design process of ML models and their results will be discussed. Eventually, the best ML model is selected and introduced to predict rock BI.
2. Related Works
Several studies proposed empirical formulas to approximate the rock brittleness [
24,
25,
76,
77]. The majority of these studies considered the relationship between tensile and uniaxial compressive strength of the rock samples. Hucka and Das [
25] proposed two formulas as B
1 = σ
c/σ
t and B
2 = σ
c − σ
t/σ
c + σ
t, where σ
c and σ
t denote the uniaxial compression strength and tensile strength, respectively. Altindag [
78] and Yarali and Soyer [
79] developed the following formulas, respectively: B
3 = σ
c * σ
t/2. B
4 = (σ
c * σ
t)
0.72. Meng et al. [
20] and Nejati and Moosavi [
24] developed the following formula, respectively, using more factors: B
5 = σ
c0.84 +
E0.51/σ
t0.21 and B
6 = (σ
p − σ
c)/s
p. In this formula, σ
c, σ
t, σ
p, and
E denote the uniaxial compression strength, tensile strength, peak strength, and elastic modulus, respectively. Among these empirical equations, the general form (B
1), which was proposed by Hucka and Das [
25], is the most commonly used by other researchers [
13,
21,
22]. In the prediction of the rock BI value, the single input and the multi-inputs predictive systems such as simple and multiple linear regression models have used [
22,
23,
24,
25]. Although multiple linear regression models demonstrated a higher precision level in comparison with the available simple regression models [
18,
21,
22], they are not always robust enough to describe the behavior of complex systems accurately [
62,
80]. In addition, the accuracy level of these models is not good enough for prediction of rock BI [
21,
22].
In field of ML, AI, and SC techniques, only limited research has been carried out for the aim of predicting the BI values of rock. Kaunda and Asbury [
81] made use of an artificial neural network (ANN) technique with the help of system inputs like the Poisson’s ratio, unit weight, the velocity of the S and P waves, and the elastic modulus. Forming fuzzy inference system (FIS) and conducting non-linear regression analysis, Yagiz and Gokceoglu [
18] attempted to predict rock BI. For the development of these models, the uniaxial compressive strength (UCS), unit weight, and Brazilian tensile strength (BTS) of the rock were used as inputs. Their finding showed that the FIS model can be effectively applied to the same field for further research. Some predictive equations were suggested by Koopialipoor et al. [
21] to calculate the BI value of rock as a function of intact rock properties, such as density, p-wave velocity, and the Schmidt hammer rebound number. They hybridized ANN and the firefly algorithm into a single model aiming at developing the proposed equations. In another study, the genetic programming model feasibility was tested by Khandelwal et al. [
22] in a way to predict the intact rocks brittleness level. For the purpose of estimating the BI of rock mass, they employed multiple input variables, such as BTS, UCS, and unit weight. As the literature review shows, many soft computing methods, such as SVM, have not been used to predict the BI. Due to this, the authors decided to apply and develop SVM models to predict BI of the rock samples.
4. Results and Evaluations
This study developed four single and four hybrid SVM models with different kernels to predict rock BI. Thus, four models were single-based and four models were hybrid-based. This study used five performance indices, including R, the root means square error (RMSE), the mean absolute error (MAE), the variance account for (VAF), and the a20-index to evaluate the accuracy performance of these eight models (
Figure 6). The research team also used a simple ranking method to rank the performance of the developed models. In this method, each model was evaluated within the training and testing phase separately. For each performance indicator, the highest rank equaled four (4) because each classification included four models. Accordingly, the lowest rank equaled one (1) (if the multiple models do not obtain an equal value for a certain indicator). For the models that achieved the same value for a certain indicator, an equal rank was assigned. For each phase, the sum of the ranks was calculated. Finally, the cumulative ranking was calculated for each model by summing the training and testing ranks. More details regarding the ranking system and its calculation process can be found in the original study conducted by Zorlu et al. [
87].
Four single-SVM models were developed using different kernels, including RBF, POL, SIG, and LIN. To develop each of these models, several parameters were identified and employed. These parameters are shown in
Table 3. First of all, the authors used a stopping criterion, which stood for determining when to stop the optimization algorithm. To control the trade-off between maximizing the margin and minimizing the training error term, a value of regularization parameter (C) was used. A regression precision (epsilon) value which caused errors to be accepted provided that they are less than the value specified here. RBF gamma was used only for the RBF kernel, while the gamma was used only for the POL and SIG kernels. Both gammas improved the classification accuracy and reduced the regression error for the training data. Finally, the “degree”, controlled the complexity of the mapping space, and was used only for the polynomial kernel.
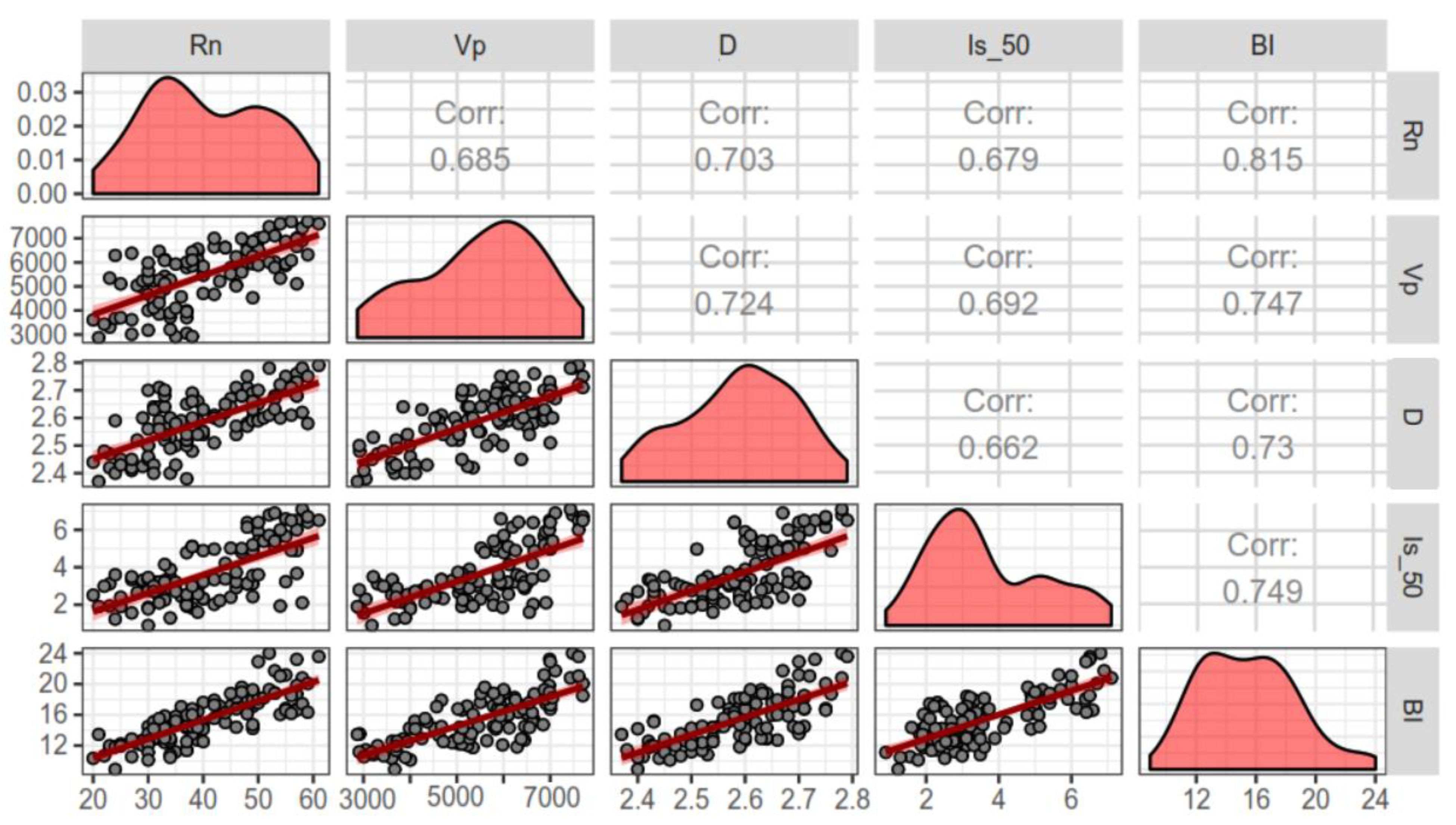
To develop the hybrid-based models, the research team initially performed an input selection to identify the most relevant inputs and remove the irrelevant data. Thus, a feature selection (FS) technique was used. The FS used the likelihood ratio, which tests for target-input independence. The following criteria to perform the screening were used: (1) the maximum percentage of missing values (70.0) and (2) the minimum coefficient of variation (0.1). The FS was performed using four inputs, including V
p, D, R
n, and Is
50. Finally, the FS removed “D” from the list of inputs. Once the FS was performed, the authors again developed the SVM models using different kernels. As previously mentioned, several parameters were used to develop the hybrid-based SVM models that are shown in
Table 4.
The performance index results of the single-based models together with their ranking values are presented in
Table 5. The results show that the SVM-RBF model achieved the highest rank for both training (19) and testing (17) phases. Consequently, this model achieved the highest cumulative rank (36). This model was followed by SVM-POL, SVM-LIN, and SVM-SIG models, respectively. Concerning the hybrid-based models, the results of which are shown in
Table 6, the FS-SVM-RBF model obtained the highest rank for training (20), while the FS-SVM-POL obtained the highest rank for testing (18). In terms of cumulative ranking, the FS-SVM-RBF achieved the highest rank (31).
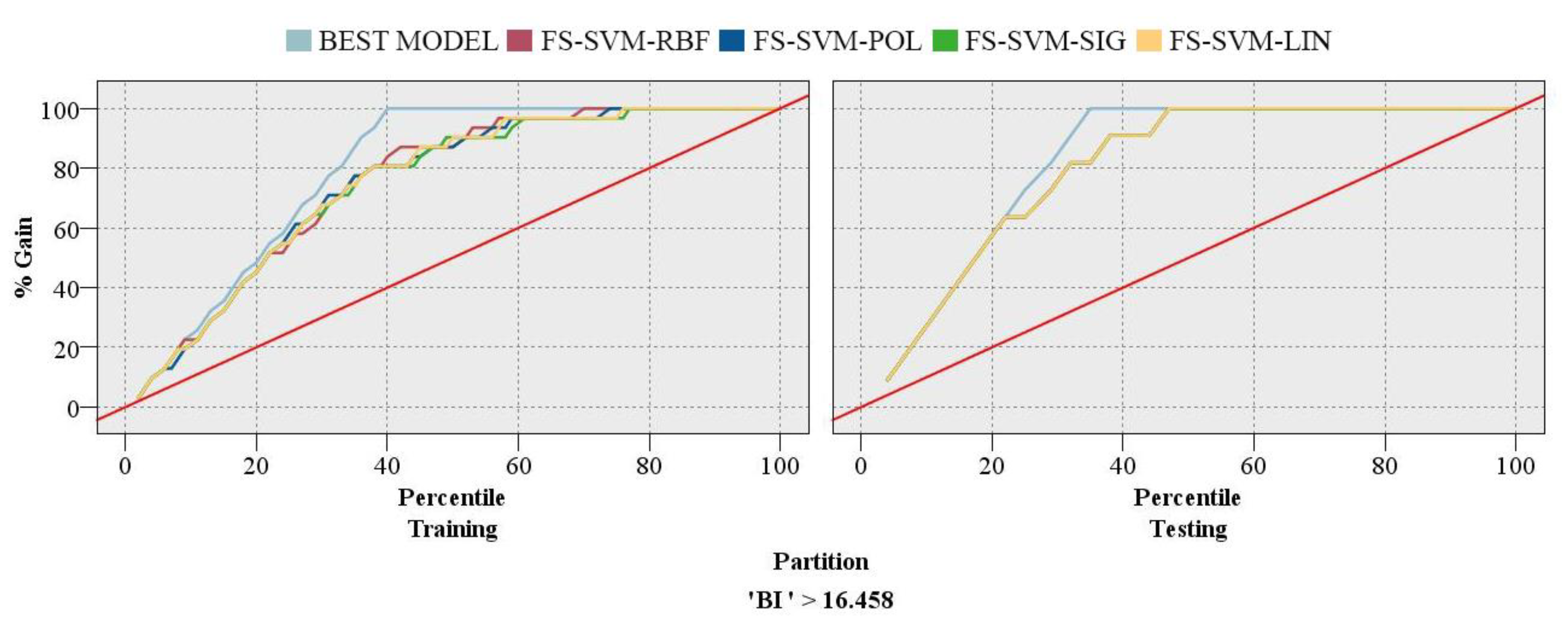
This present study also employed a chart of gains to evaluate the performance of the SVM models that were developed. Gains can be computed as follows:
where
n denotes the number of hits in quantile and
N denotes the total number of hits. Here, it is necessary to mention that “hit” refers to the success of a model to predict the values greater than the midpoint of the fields range (BI > 16.458). In the gains chart, the blue line signifies the perfect model that has perfect confidence (where hits = 100% of cases), the diagonal red line represents the at-chance model, and the other lines in the middle represent the other models. To compare a model developed and the at-chance model, the area between a model and the red line can be used. In fact, this area identifies how much better a proposed model is compared to the at-chance model. Moreover, the area between a model proposed and the perfect model identifies where a proposed model can be improved.
In the gains chart, it is necessary to maximize the space between the models’ curves and at-chance model. Moreover, the higher lines show better models, particularly on the left side of the chart.
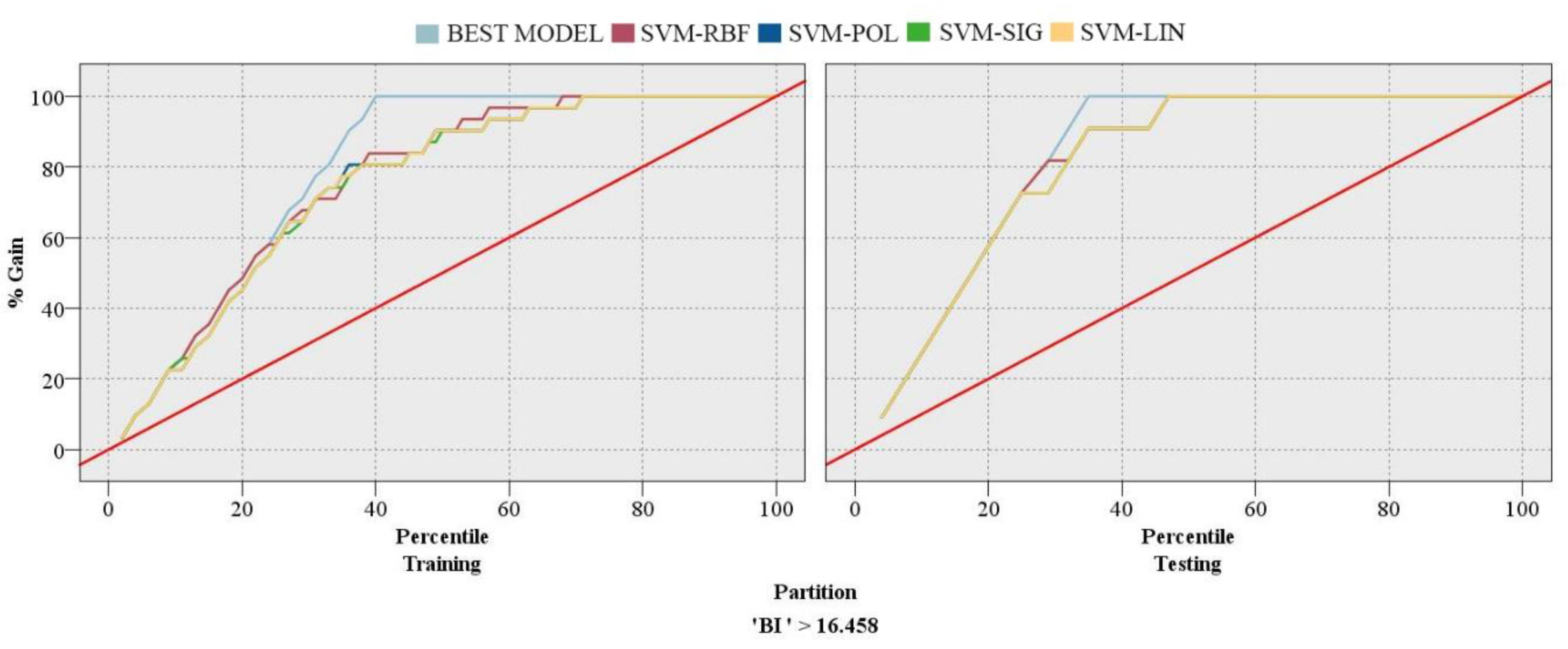
Figure 7 shows the gains chart for single-based SVM models in predicting the rock BI. For the training phase, the SVM-RBF model was the best (the highest line/maximum space between the model curve and the at-chance model) and the SVM-LIN was the worst (the lowest line/minimum space between the model curve and the at-chance model). Concerning the testing phase, interestingly, the models showed similar behavior. The gains charts for hybrid-based SVM models in predicting the rock BI are displayed in
Figure 8. For the training phase, the FS-SVM-RBF model was the best and FS-SVM-SIG was the worst.
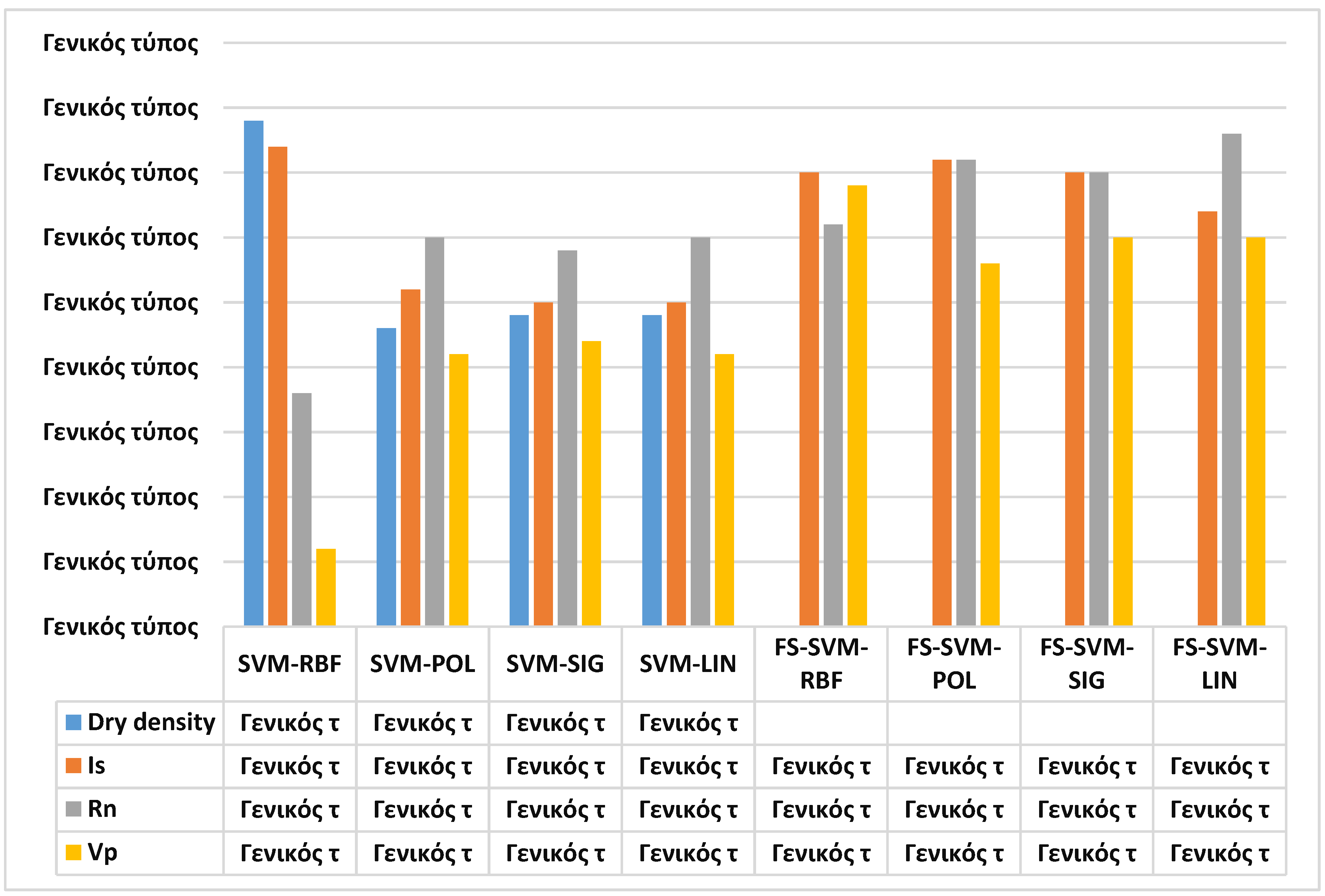
Each of the models developed identified the importance of the input variables to predict the rock BI. The importance of these variables is shown in
Figure 9. As can be seen, while the three single-based models, including the SVM-POL, SVM-SIG, and SVM-LIN, identified R
n as the most important variable, the SVM-RBF identified density as the most important input variable. All four single-based SVM models identified the V
p as the least important variable. For the hybrid models, as the FS removed the density from the input lists, these models evaluated the importance of three inputs, including R
n, V
p, and, Is
50 to predict the BI. Three hybrid-based models, including FS-SVM-RBF, FS-SVM-POL, and FS-SVM-SIG identified the Is
50 as the most important input, while the FS-SVM-LIN identified the R
n as the most important input. Besides, FS-SVM-POL and FS-SVM-SIG identified R
n as the most important input along with the Is
50. V
p was identified as the least important factor by FS-SVM-POL, FS-SVM-SIG, and FS-SVM-LIN, while the FS-SVM-RBF identified R
n as the least important input for predicting the BI.
5. Discussions
This study was set out to compare SVM models with different kernels to predict the rock BI. These kernels included RBF, POL, SIG, and LIN. The research team used two approaches for developing these SVM models. First, they developed single models, which meant that no input selection was conducted before developing these models. Second, they hybridized the SVM models with an FS technique.
The comparison of these approaches may help researchers to have a better insight into the advantages and disadvantages of the hybridization of different kernels of SVM techniques with an input selection technique (i.e., FS). The proposed models were compared in terms of accuracy performance, gains performance, and input variable importance. To develop the single-based models, four inputs, including D, Is50, Rn, and Vp were used to predict the BI, while the hybrid-based models were developed using three inputs (Is50, Rn, and Vp), because the FS technique removed one of the inputs (density) from the input list.
In terms of accuracy performance, the SVM models that were developed using the RBF kernel achieved the highest accumulative ranking regardless of whether they were single or hybrid. It is also worth noting that while the SVM-RBF model achieved the highest rank for both training and testing datasets, the FS-SVM-RBF model achieved the highest rank only for the training stage. Concerning the gains performance, the SVM models that used the RBF kernel again achieved the best results regardless whether they were single or hybrid. Thus, these findings imply that the RBF kernel is the most suitable choice to be used to develop the SVM models, regardless of whether these models are single or hybrid, for predicting the BI.
This study also evaluated the manner in which the SVM models identified the importance of each input variable. For single-based models, the SVM-RBF model differently identified the most important input from other single models. For the hybrid-based models, the FS-SVM-LIN differently identified the most important input. The accuracy and gains performance of SVM models that use the RBF kernel can support the power of these models to identify the importance of the input variables to predict the BI.
6. Conclusions
In this paper, an attempt has been made to predict the rock BI using empirical and ML techniques. The review of empirical relations revealed that although the performance capacity of the developed empirical equations is suitable, there is a need to develop an ML technique considering all model inputs, i.e., Vp, D, Rn, and Is50. Then, four single SVM models of SVM-RBF, SVM-POL, SVM-SIG, and SVM-LIN together with and four hybrid SVM models FS-SVM-RBF, FS-SVM-POL, FS-SVM-SIG, and FS-SVM-LIN were constructed to predict BI of the rock samples. The results of the cumulative rank values of 36, 30, 15, and 25 were obtained for the SVM-RBF, SVM-POL, SVM-SIG, and SVM-LIN models, respectively. In addition, cumulative rank values of 31, 29, 17 and 30 were achieved for the FS-SVM-RBF, FS-SVM-POL, FS-SVM-SIG, and FS-SVM-LIN models, respectively. This shows that the RBF is the most successful kernel for both single and hybrid SVM models to estimate the BI of the rock. As a concluding remark, the authors would like to stress that the modeling process presented in this study can be used in other areas of research as well, in order to succeed in solving a problem from a new point of view. Further studies that intend to use the SVM models should develop both single and hybrid models with different kernels. Then, they will understand the behavior of different kernels in a better way and will therefore select the most accurate and reliable model. In addition, future research should use a database with more samples that can help to improve the accuracy and generalizability of the prediction.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}