
Research and Application Based on Adaptive Boosting Strategy and Modified CGFPA Algorithm: A Case Study for Wind Speed Forecasting


Abstract
:1. Introduction
- (1)
- Due to the randomness and instability of wind series, a model based on the fast ensemble empirical mode decomposition technique is utilized to adaptively address the original wind speed series through decomposition into a finite number of intrinsic mode functions with a similarity property to modeling.
- (2)
- To overcome the drawbacks of the unstable forecasting results of the BP neural network, the ABBP model combined with the AB strategy is considered a strong predictor in this paper for wind-speed forecasting.
- (3)
- A novel modified algorithm, the CGFPA, is developed in the wind-speed forecasting field that, for the first time, chooses the parameter in the ABBP model for its better convergence and higher-quality solutions in lower iterations compared with the FPA.
- (4)
- Considering the skewness and kurtosis of the forecasting accuracy distribution, the forecasting availability, and the bias-variance framework, the Diebold-Mariano test is proposed to validate the accuracy and stability of the proposed model.
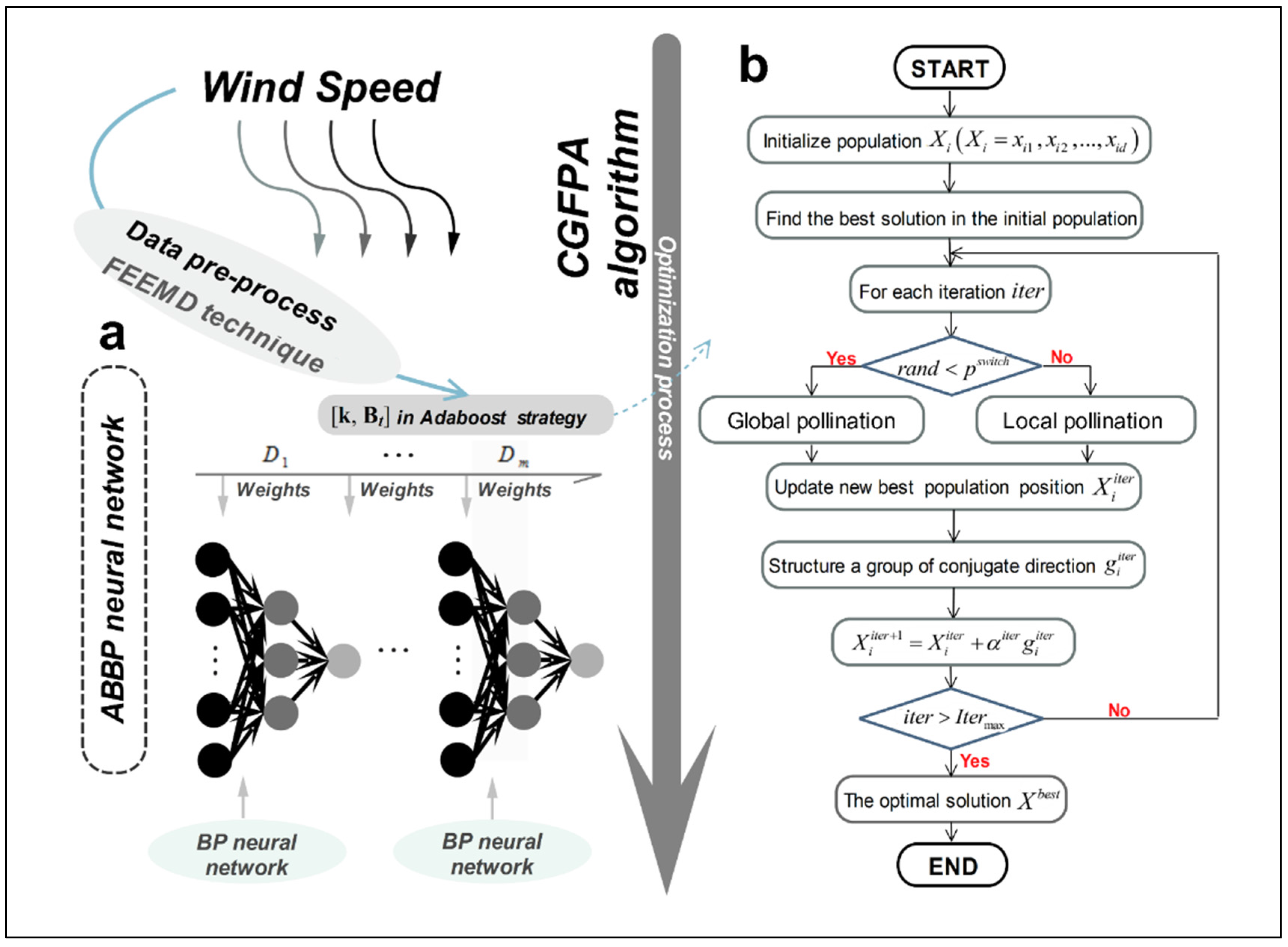
2. Methodology
2.1. Fast Ensemble Empirical Mode Decomposition
2.2. Artificial Neural Network (ANN)
2.3. Adaptive Boosting (AB) Strategy
2.4. Optimization Algorithm-CGFPA
2.4.1. Flower Pollination Algorithm (FPA)
2.4.2. Modified Optimization Algorithm-CGFPA
| Algorithm 1: CGFPA (OPTIMIZE_CGFPA). | |
| Parameters: | |
| pswitch —the switch probability. | |
| ∇—the gradient operator (total differential in all direction of space). | |
| N—the generation number of Xi. | |
| iter—current iteration number. | |
| Itermax —the maximum number of iteration. | |
| 1 | /*Initialize a population of N flowers Xi (Xi = xi1,xi2,…,xid) in random positions and initialize iter = 0.*/ |
| 2 | /*Find the best solution .*/ |
| 3 | while iter < Itermax do |
| 4 | for i←1 to N do |
| 5 | if rand< pswitch then |
| 6 | Do global pollination . |
| 7 | Else |
| 8 | Do local pollination . |
| 9 | end if |
| 10 | /*Evaluate , replace by if the newly generation is better.*/ |
| 11 | end for |
| 12 | /*Update the current best solution .*/ |
| Calculate . | |
| /*Calculate the gradient (search direction) .*/ | |
| /*Determined searching step αiter by utilize the line search method.*/ | |
| Let and calculate . | |
| 13 | iter = iter+1 |
| 14 | end do |
| 15 | end while |
| 16 | return Xbest. |
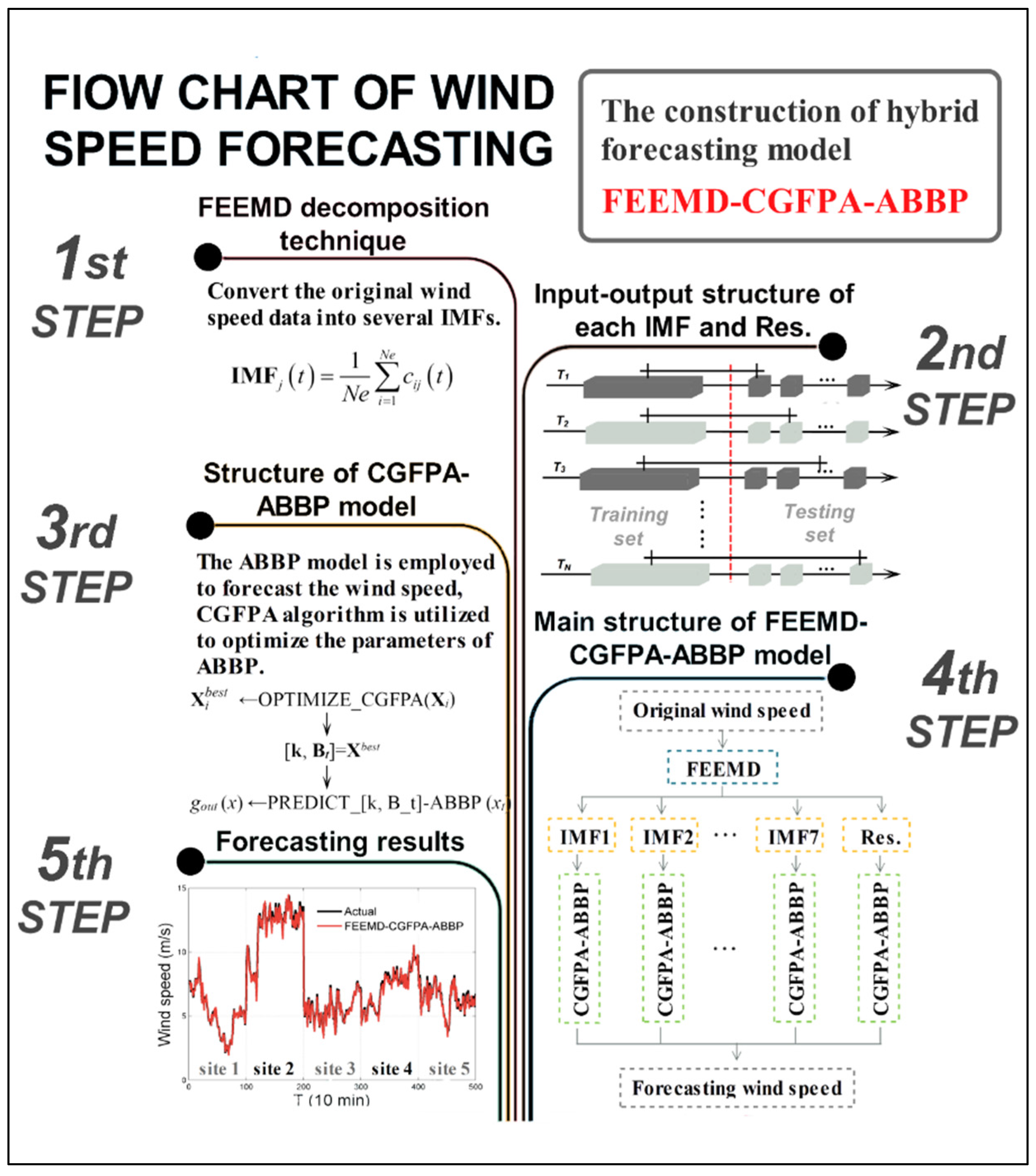
3. Hybrid FEEMD-CGFPA-ABBP Model
| Algorithm 2: FEEMD-CFFPA-ABBP (MODOL_HYBRID). | |
| Input: | |
| P—the input data matrix | |
| Output: | |
| T—the output data matrix | |
| Parameters: | |
| Ne—the ensemble number of trials. α—the amplitude of added white noise. M—the repeat times of trials Θ—the critical point of updating the weight distribution. k—the adjustment factor of the weight distribution. Bt—the normalization factor. | |
| (S, TFt, BTFt, BLFt)—the parameters of the BP neural network. iterp—the number of weak predictors. pswitch—the switch probability. N—the generation number of Xi. ∇—the gradient operator (total differential in all spatial directions). iter—current iteration number. Itermax—the maximum number of iterations. | |
| 1 | IMFj(t)←PREPROCESSING_FEEMD(ri(t)); |
| 2 | /*Perform the following operations for each IMF.*/ |
| 3 | /*Initialize the weight distribution of m training sample Dt(i) = 1/m, error rate εn = 0.*/ |
| 4 | Sample normalization. xt = (xt − xmin)/(xmax − xmin). |
| 5 | /*Weak predictor forecasting. By selecting different BP network functions, construct different types of weak predictors.*/ |
| 6 | for t←1 to iter do |
| 7 | net = newff (P,T,S,TFt,BTFt,BLFt). |
| 8 | /*Obtain the error rate εt of forecast series gt(x) and the distribution weights of the next weak predictor.*/ |
| 9 | for i←1 to m do |
| 10 | Find a best value of [k, Bt] by using optimization algorithm. |
| 11 | ←OPTIMIZE_CGFPA(Xi (Xi = xi1, xi2, …,xid)) |
| 12 | iter = iter + 1. |
| 13 | /*[k,Bt] = Xbest.*/ |
| 14 | end do |
| 15 | end do |
| 16 | return gout (x). |
3.1. Normalization and Preprocessing of Wind Speed Data
3.2. Choice of Fitness Function
4. Experimentation Design and Results
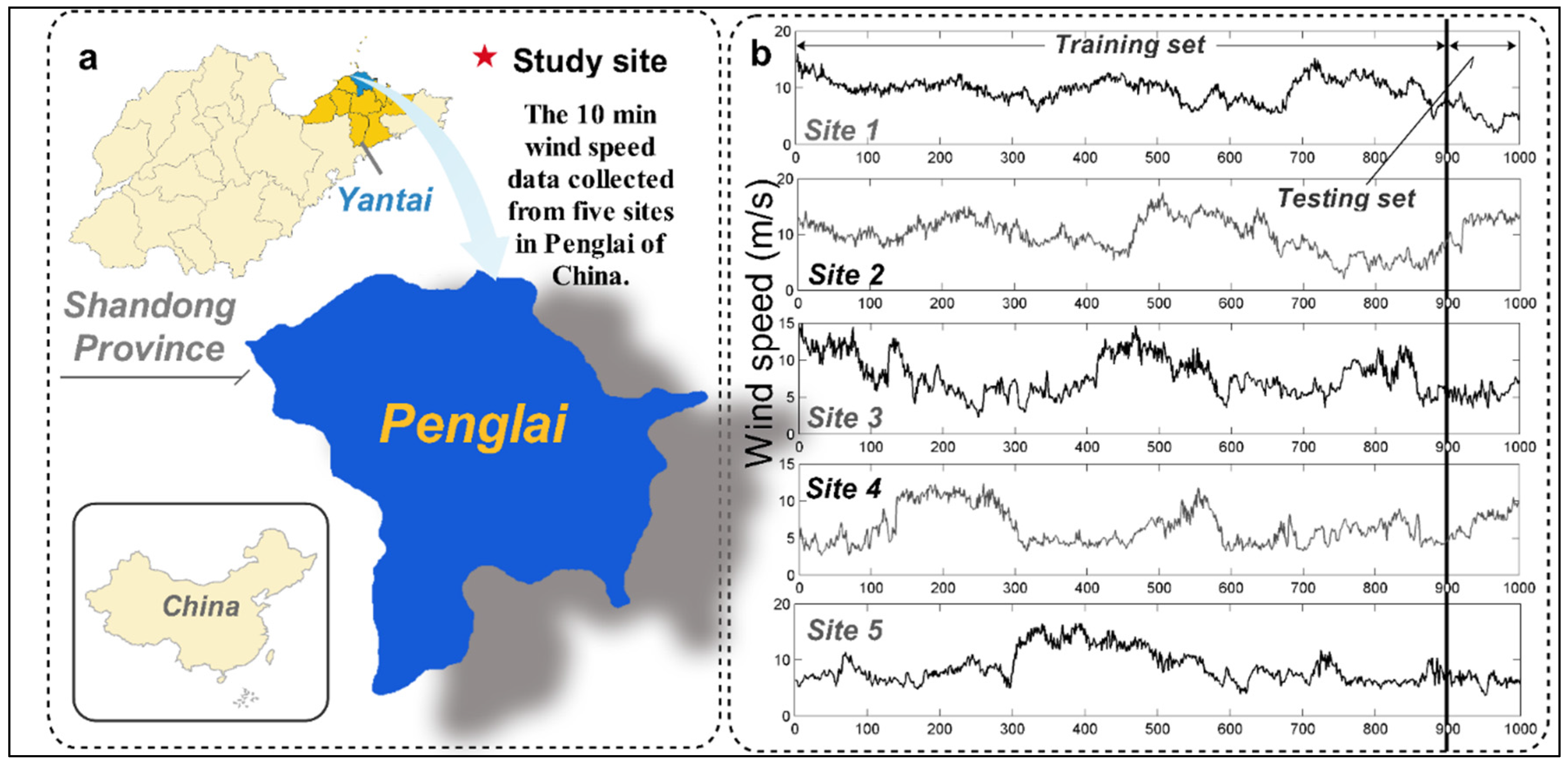
4.1. Study Area and Datasets
4.2. Evaluation Criteria of Forecast Performance
4.3. Experimental Setup
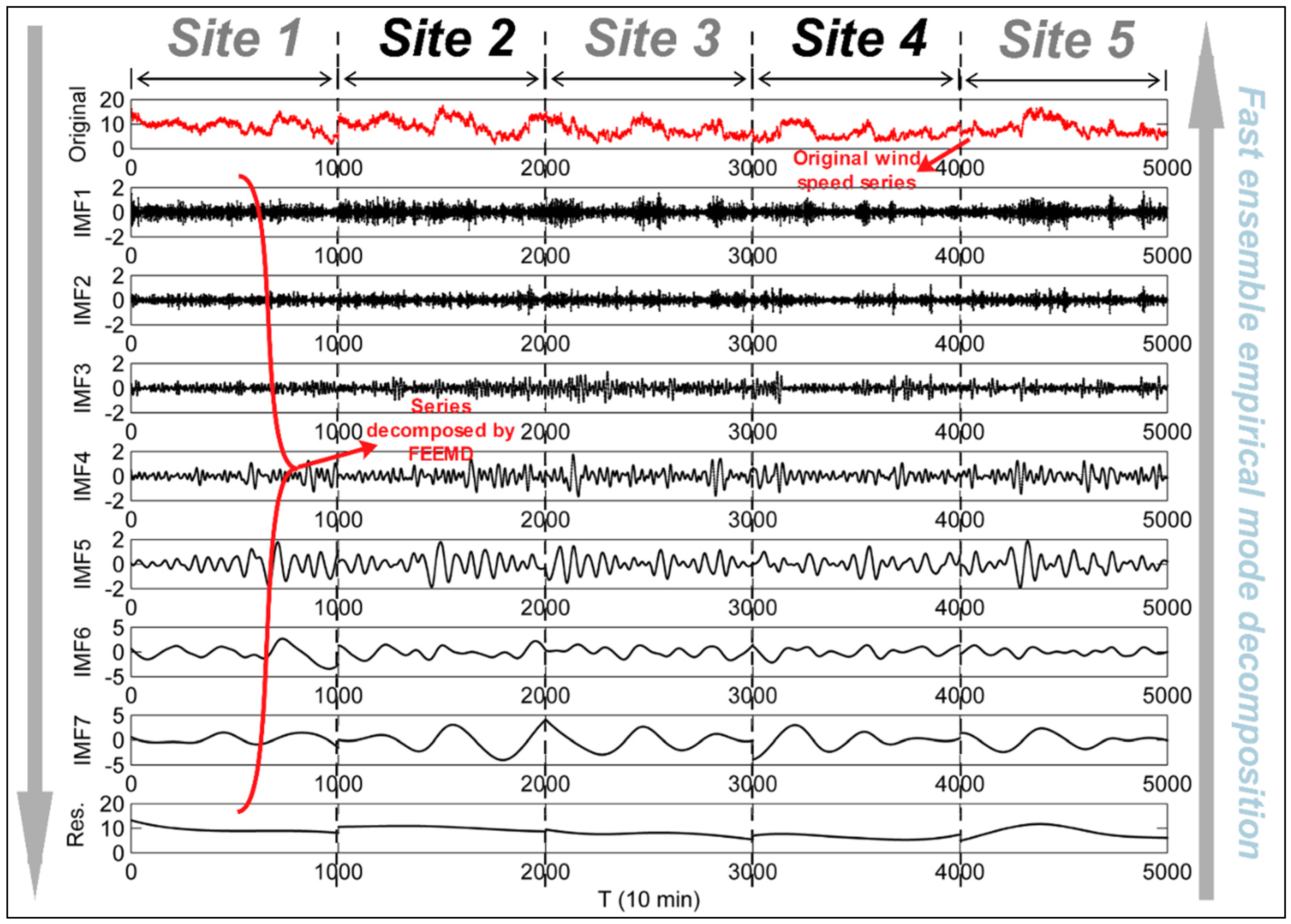
4.3.1. Experiment I: Results of Data Preprocessing
- (1)
- The extracted IMFs are graphically indicated to illustrate the order of frequency from highest the lowest. The high- and low-frequency entries are given in the first few and last few IMFs, respectively. The former represent high noise or time variation in the original wind speed series, while the latter represent long-period IMFs. In addition, the shifting residue, the last component, generally represents the trend of the wind speed series. It can be clearly determined that the sub-series (IMF7) with the lowest frequency indicates that the major fluctuation of the raw wind speed series is highly similar to the original wind speed series.
- (2)
- When processing the original series using the fast ensemble empirical mode decomposition technique, different characteristic information can be extracted at different scales, leading to the strong regularity and simple frequency components of each IMF. The local fluctuations of the original series can also be fully captured using this method. Moreover, because of the similar frequency characteristics of each IMF, it is beneficial to reduce the complexity and enhance the efficiency and accuracy of the ABBP forecasting model.
- (3)
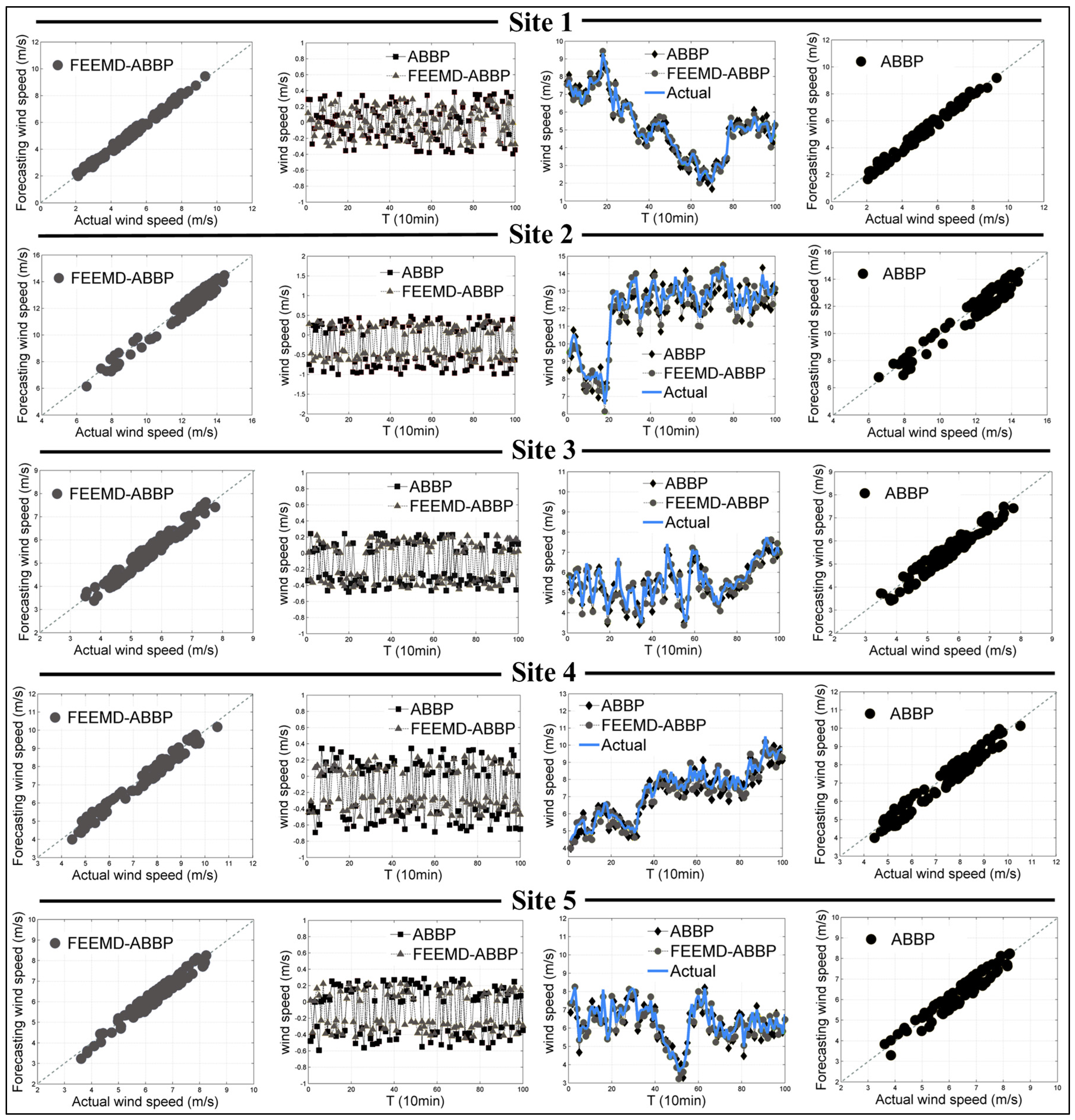
- The bold entries in Table 2 indicate the values of AE, MAE, MSE and MAPE that are the smallest among the FEEMD-ABBP and ABBP models. In this model comparison, it can be clearly observed that the fast ensemble empirical mode decomposition technology employed on the ABBP model performs better than the single ABBP model at all five sites. The MAPEs achieved by the FEEMD-ABBP model at the five sites are 3.2354%, 3.3234%, 4.2093%, 3.7402% and 3.754%, representing decreases of 1.2912%, 1.2432%, 0.6224%, 1.1648% and 0.6972%, respectively.
4.3.2. Experiment II: Strong Predictor (ABBP Model) vs. Weak Predictors
4.3.3. Experiment III: Forecasting Comparison Results
- (1)
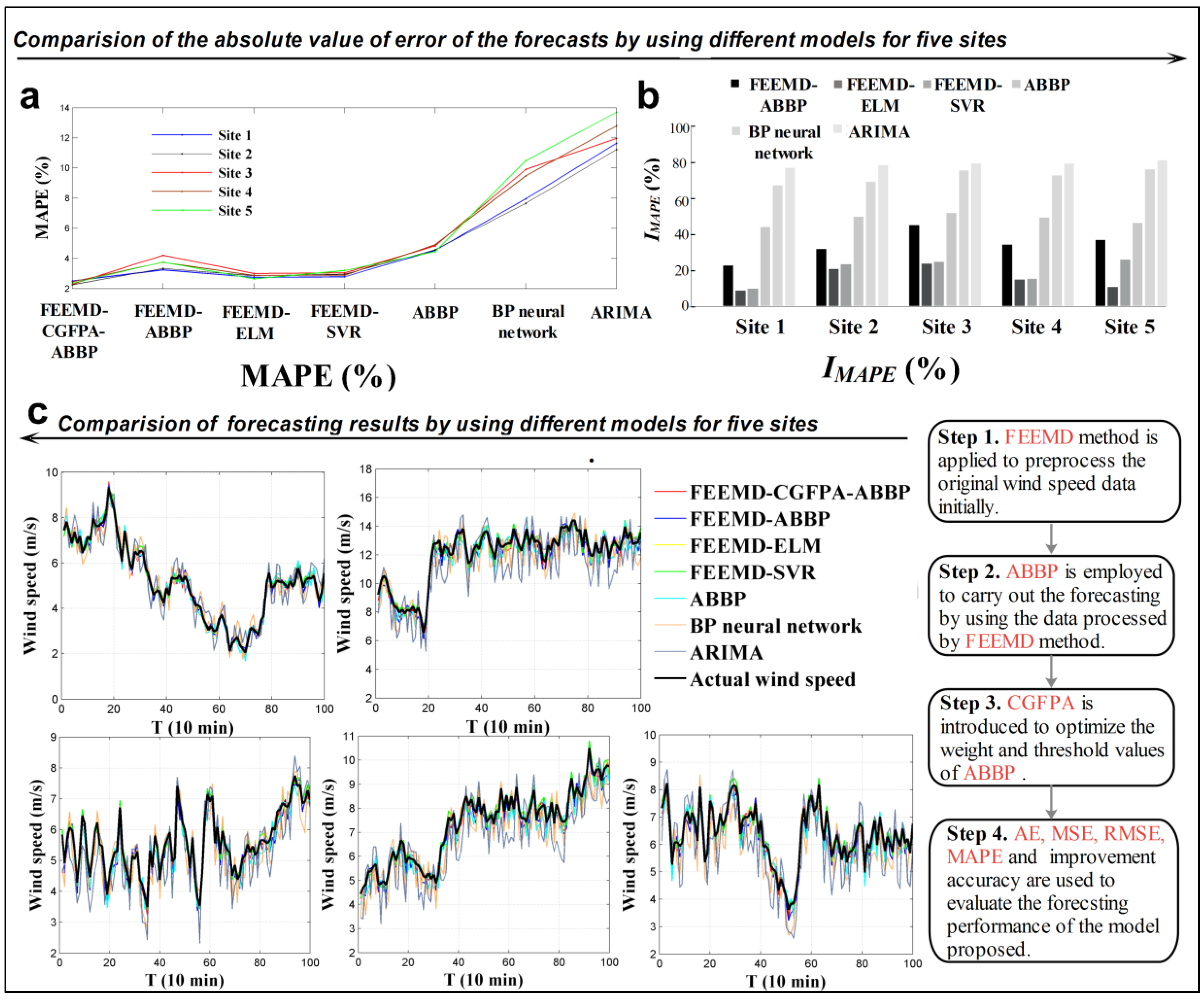
- The AE, MAE, MSE and MAPE values are calculated for the forecasts, and the corresponding results are compiled and presented in Table 4. The values in bold represent the AE, MAE, MSE, and MAPE values that are the lowest among all the forecasting models at the five sites. It can be clearly seen that the proposed hybrid model has the highest accuracy at all wind farm sites, with MAPE values of 2.4976%, 2.2495%, 2.2785%, 2.4397% and 2.3483% at Sites 1 through 5, respectively.
- (2)
- To compare the different performances between two forecasting models, the improvement accuracy is used, which is defined aswhere EC is the value of one of the forecasting performance evaluation criteria AE, MAE, MSE or MAPE. EC1 and EC2 denote the values of the evaluation criterion generated by the compared models (FEEMD-ABBP, FEEMD-ELM, FEEMD-SVR, ABBP, BP neural network, and ARIMA) and the proposed hybrid model. Table 5 shows the corresponding improvement of the proposed model. From Table 5, compared with the other forecasting models among all five sites, there are significant improvements for the proposed model forecast. For example, at Site 2, the FEEMD-CGFPA-ABBP model leads to 11.9941%, 18.6508%, 2257.8947%, 3589.362%, 62.2130% and 77.009% reductions in AE, 31.0846%, 35.0349%, 23.6241%, 28.5597%, 71.2193% and 80.0101% reductions in MAE, 51.0923%, 69.649%, 26.8657%, 36.8195%, 91.9141% and 96.1417% reductions in MSE, and 32.3128%, 41.4833%, 20.9092%, 23.4968%, 70.5879% and 79.9484% reductions in MAPE in comparison to FEEMD-ABBP, FEEMD-ELM, FEEMD-SVR, ABBP, BP neural network and ARIMA, respectively. Additionally, the maximum decreases in MAE, MSE and MAPE for the proposed hybrid model among all five sites are 82.3511%, 96.7654% and 86.8612%, respectively.
- (3)
- Figure 6 illustrates the evaluation criterion values of the forecasts offered by the proposed hybrid model and that offered by the other models among the five sites. It is clearly indicated that the FEEMD-CGFPA-ABBP model can provide high and stable forecasting accuracy.
5. Discussion
5.1. Forecasting Availability
5.2. Bias-Variance Framework
5.3. Test of Hypothesis
6. Conclusions
- (1)
- The BP neural network can handle data with nonlinear features, and the AB strategy integrated with BP neural networks is adopted to overcome the uncertainty of the outcomes that can be attributed to the randomness of the initialization of the BP neural networks.
- (2)
- The modified CGFPA algorithm is utilized to optimize the parameters in the ABBP mode.
- (3)
- The experimental study of the wind-speed forecasting in five sites in Penglai, Shandong Province, China, effectively proves that the proposed hybrid model has higher precision and stability than FEEMD-ABBP, ABBP and other forecasting models.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A1. Empirical Mode Decomposition
| Algorithm A1: Empirical Mode Decomposition (PREPROCESSING_EMD). | |
| Parameters: | |
| δ—a random number between 0.2 and 0.3. | |
| T—the series length. | |
| 1 | /*Initialize residue r0(t) = x(t), i = 1, j = 0; Extract local maxima and minima of ri-1(t).*/ |
| 2 | for j = j + 1 do |
| 3 | for i←1 to n do |
| 4 | while (SDj < δ) do |
| 5 | Calculate the upper envelope Ui (t) and Li (t) by cubic spline interpolation. |
| 6 | Mean envelope (t) = [Ui (t) + Li (t)]/2; the ith component ri (t) = ri-1(t) − (t). |
| 7 | /*ri,j(t) = hi(t); i,j(t) be the mean envelope of ri,j(t).*/ |
| 8 | end while |
| 9 | Calculate ri, j (t) = ri, j-1(t) − i, j-1(t) |
| 10 | /*Let jth IMF as IMFi(t) = , j(t).*/ |
| 11 | /*Update the residue ri(t) = ri-1(t) − IMFi(t).*/ |
| 12 | end do |
| 13 | end do |
| 14 | return x(t) |
Appendix A2. Ensemble Empirical Mode Decomposition
| Algorithm A2: Ensemble Empirical Mode Decomposition. | |
| Parameters: | |
| Ne—the ensemble number of trials. | |
| α—the amplitude of added white noise. | |
| 1 | /*Obtain series ri(t) by adding white noise series N = {n1, n2,…, nNe} to series y(t).*/ |
| 2 | for j = j + 1 do |
| 3 | for i←1 to n do |
| 4 | ri (t) = y(t) + αni (t). |
| 5 | cij(t)←PREPROCESSING_EMD(ri ( t ) ); |
| 6 | /* Repeat M trials.*/ |
| 7 | end do |
| 8 | end do |
| 9 | Calculate the corresponding IMFs of the decomposition IMFj(t) |
| 10 | return IMFj(t) |
Appendix A3. Fast Ensemble Empirical Mode Decomposition
| Algorithm A3: Fast Ensemble Empirical Mode Decomposition (PREPROCESSING_FEEMD). | |
| Parameters: | |
| Ne—the ensemble number of trials. | |
| α—the amplitude of added white noise. | |
| M—the number of repeats of each trial | |
| 1 | foreach times←1 to M do |
| 2 | /*Obtain series ri(t) by adding white noise series N = {n1, n2,…, nNe} to series y(t).*/ |
| 3 | for j = j + 1 do |
| 4 | for i←1 to n do |
| 5 | ri (t) = y(t) + αni (t). |
| 6 | cij(t)←PREPROCESSING_EMD(ri ( t ) ); |
| 7 | /*sampling data at some points of series ri(t).*/ |
| 8 | end do |
| 9 | end do |
| 10 | end for |
| 11 | Calculate the corresponding IMFs of the decomposition IMFj(t) |
| 12 | return y(t) = |
Appendix B
Appendix B1. Adaptive Boosting (AB) Strategy
Appendix B2. ABBP Mode
| Algorithm B1: ABBP (PREDICT_ABBP). | |
| Input: | |
| P—the input data matrix | |
| Output: | |
| T—the output data matrix | |
| Parameters: | |
| Θ—the critical point of updating the weight distribution. | |
| k—the adjustment factor of weight distribution. | |
| Bt—the normalization factor. | |
| (S, TFt, BTFt, BLFt)—the parameters of BP neural network in MATLAB. | |
| iter —the number of weak predictors | |
| 1 | /*Initialize the weight distribution of m training sample Dt(i) = 1/m, error rate εn = 0.*/ |
| 2 | Sample normalization. xt = (xt − xmin)/(xmax − xmin). |
| 3 | /*Weak predictor forecasting. By selecting different BP network functions, construct different types of weak predictors.*/ |
| 4 | for t←1 to iter do |
| 5 | net = newff (P,T,S,TFt,BTFt,BLFt). |
| 6 | /*Obtain the error rate εt of forecast series gt(x) and the distribution weights of the next weak predictor.*/ |
| 7 | for i←1 to m do |
| 8 | /*Adjustment of test sample data weights.*/ |
| Dt+1(i) = Dt (i) / Bt. | |
| 9 | /*Output strong predictor function.*/ |
| 10 | end do |
| 11 | end do |
| 12 | return gout (x) |
Appendix C
Appendix C1. Flower Pollination Algorithm (FPA)
Appendix C2. Conjugate Gradient
References
- Hui, L.; Tian, H.Q.; Li, Y.F.; Lei, Z. Comparison of four adaboost algorithm based artificial neural networks in wind speed predictions. Energy Convers. Manag. 2015, 92, 67–81. [Google Scholar]
- New Record in Worldwide Wind Installations. Available online: http://www.wwindea.org/new-record-in-worldwide-wind-installations/ (accessed on 5 February 2015).
- Ferreira, C.; Gama, J.; Matias, L.; Botterud, A.; Wang, J. A survey on wind power ramp forecasting. In Report ANL/DIS; Argonne National Laboratory: Northeast Illinois, United State, 2011; volume 5, pp. 10–13. [Google Scholar]
- Ferreira, C.A.; Gama, J.; Costa, V.S.; Miranda, V.; Botterud, A. Predicting Ramp Events with a Stream-Based HMM Framework. Discovery Science; Springer Berlin Heidelberg: Berlin, Germany, 2012; pp. 224–238. [Google Scholar]
- Wang, J.Z.; Wang, Y.; Jiang, P. The study and application of a novel hybrid forecasting model—A case study of wind speed forecasting in china. Appl. Energy 2015, 143, 472–488. [Google Scholar] [CrossRef]
- Goh, S.L.; Chen, M.; Popovi, D.H.; Aihara, K.; Obradovic, D.; Mandic, D.P. Complex-valued forecasting of wind profile. Renew. Energy 2006, 31, 1733–1750. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, W.; Wang, J.; Han, T.; Kong, L. A novel hybrid approach for wind speed prediction. Inform. Sci. 2014, 273, 304–318. [Google Scholar] [CrossRef]
- Lei, M.; Shiyan, L.; Chuanwen, J.; Hongling, L.; Yan, Z. A review on the forecasting of wind speed and generated power. Renew. Sustain. Energy Rev. 2009, 13, 915–920. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pérez-Bellido, A.M.; Ortiz-García, E.G.; Portilla-Figueras, A.; Prieto, L.; Paredes, D. Hybridizing the fifth generation mesoscale model with artificial neural networks for short-term wind speed prediction. Renew. Energy 2009, 23, 1451–1457. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pérez-Bellido, A.M.; Ortiz-García, E.G.; Portilla-Figueras, A.; Prieto, L.; Correoso, F. Accurate short-term wind speed prediction by exploiting diversity in input data using banks of artificial neural networks. Neurocomputing 2009, 72, 1336–1341. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M.; Raissi-Ardali, G. Improvement of Auto-Regressive Integrated Moving Average Models Using Fuzzy Logic and Artificial Neural Networks (ANNs). Neurocomputing 2009, 72, 956–967. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ortiz-García, E.G.; Pérez-Bellido, A.M.; Portilla-Figueras, J.A.; Prieto, L.; Paredes, D.; Correoso, F. Performance comparison of multilayer perceptrons and support vector machines in a short-term wind speed prediction problem. Neural Netw. World 2009, 19, 37–51. [Google Scholar]
- Pourmousavi Kani, S.A.; Ardehali, M.M. Very short-term wind speed prediction: A new artificial neural network-Markov chain model. Energy Convers. Manag. 2011, 52, 738–745. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J.; Wang, J.; Zhao, Z.; Tian, M. Short-term wind speed forecasting based on a hybrid model. Appl. Soft Comput. 2013, 13, 3225–3233. [Google Scholar] [CrossRef]
- Landberg, L. Short-term prediction of the power production from wind farms. J. Wind Eng. Ind. Aerodyn. 1999, 80, 207–220. [Google Scholar] [CrossRef]
- Alexiadis, M.C.; Dokopoulos, P.S.; Sahsamanoglou, H.S.; Manousaridis, I.M. Short term forecasting of wind speed and related electrical power. Sol. Energy 1998, 63, 61–68. [Google Scholar] [CrossRef]
- Negnevitsky, M.; Potter, C.W. Innovative short-term wind generation prediction techniques. In Proceedings of the Power Systems Conference and Exposition, Atlanta, GA, USA, 29 October–1 November 2006; pp. 60–65.
- Kulkarni, M.; Patil, S.; Rama, G.; Sen, P. Wind speed prediction using statistical regression and neural network. J. Earth Syst. Sci. 2008, 117, 457–463. [Google Scholar] [CrossRef]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-arima models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Barbounis, T.G.; Theocharis, J.B. A locally recurrent fuzzy neural network with application to the wind speed prediction using spatial correlation. Neurocomputing 2007, 70, 1525–1542. [Google Scholar] [CrossRef]
- Focken, U.; Lange, M.; Moonnich, K.; Waldl, H.P.; Georg, B.H.; Luig, A. Short-term prediction of the aggregated power output of wind farms-astatistical analysis of the reduction of the prediction error by spatial smoothing effects. J. Wind Eng. Ind. Aerodyn. 2002, 90, 231–246. [Google Scholar] [CrossRef]
- Flores, P.; Tapia, A.; Tapia, G. Application of a control algorithm for wind speed prediction and active power generation. Renew. Energy 2005, 30, 523–536. [Google Scholar] [CrossRef]
- Mabel, M.C.; Fernández, E. Analysis of wind power generation and prediction using ANN: A case study. Renew. Energy 2008, 33, 986–992. [Google Scholar] [CrossRef]
- Monfared, M.; Rastegar, H.; Kojabadi, H.M. A new strategy for wind speed forecasting using artificial intelligent methods. Renew. Energy 2009, 34, 845–848. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W. Short term wind speed forecasting in La Venta, Oaxaca, México, using artificial neural networks. Renew. Energy 2009, 34, 274–278. [Google Scholar] [CrossRef]
- Sfetsos, A. A novel approach for the forecasting of mean hourly wind speed time series. Renew. Energy 2002, 27, 163–174. [Google Scholar] [CrossRef]
- Ren, C.; An, N.; Wang, J.; Li, L.; Hu, B.; Shang, D. Optimal parameters selection for BP neural network based on particle swarm optimization: A case study of wind speed forecasting. Knowl.-Based Syst. 2014, 56, 226–239. [Google Scholar]
- Sfetsos, A. A comparison of various forecasting techniques applied to mean hourly wind speed time series. Renew. Energy 2000, 21, 23–35. [Google Scholar] [CrossRef]
- Mohandes, M.A.; Halawani, T.O.; Rehman, S.; Hussain, A.A. Support vector machines for wind speed prediction. Renew. Energy 2004, 29, 939–947. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pastor-Sánchez, A.; Blanco-Aguilera, A.; Prieto, L.; García-Herrera, R. Feature Selection in Wind Speed Prediction Systems based on a hybrid Coral Reefs Optimization—Extreme Learning Machine Approach. Energy Convers. Manag. 2014, 87, 10–18. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pastor-Sánchez, A.; del Ser, J.; Prieto, L.; Geem, Z.W. A Coral Reefs Optimization algorithm with Harmony Search operators for accurate wind speed prediction. Renew. Energy 2015, 75, 93–101. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ortiz-García, E.G.; Pérez-Bellido, A.M.; Portilla-Figueras, J.A.; Prieto, L. Short term wind speed prediction based on evolutionary support vector regression algorithms. Expert Syst. Appl. 2011, 38, 4052–4057. [Google Scholar] [CrossRef]
- Ortiz-García, E.G.; Salcedo-Sanz, S.; Pérez-Bellido, A.M.; Gascón-Moreno, J.; Portilla-Figueras, A.; Prieto, L. Short-term wind speed prediction in wind farms based on banks of support vector machines. Wind Energy 2010, 14, 193–207. [Google Scholar] [CrossRef]
- Hui, L.; Chao, C.; Hong-qi, T.; Yan-fei, L. A hybrid model for wind speed prediction using empirical mode decomposition and artificial neural networks. Renew. Energy 2012, 48, 545–556. [Google Scholar]
- Wang, Y.; Wang, S.; Zhang, N. A novel wind speed forecasting method based on ensemble empirical mode decomposition and GA-BP neural network. In Proceedings of the 2013 IEEE Power and Energy Society General Meeting (PES), Vancouver, BC, Canada, 21–25 July 2013.
- Hui, L.; Hong-Qi, T.; Xi-Feng, L.; Yan-Fei, L. Wind speed forecasting approach using secondary decomposition algorithm and Elman neural networks. Appl. Energy 2015, 157, 183–194. [Google Scholar]
- Guo, Z.; Zhao, J.; Zhang, W.; Wang, J. A corrected hybrid approach for wind speed prediction in Hexi Corridor of China. Energy 2011, 36, 1668–1679. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Chen, C.; Li, Y. An experimental investigation of two Wavelet-MLP hybrid frameworks for wind speed prediction using GA and PSO optimization. Int. J. Electr. Power 2013, 52, 161–173. [Google Scholar] [CrossRef]
- Yang, X. Flower Pollination Algorithm for Global Optimization. Lect. Notes Comput. Sci. 2013, 7445, 240–249. [Google Scholar]
- Alam, D.; Yousri, D.; Eteiba, M. Flower pollination algorithm based solar PV parameter estimation. Energy Convers. Manag. 2015, 101, 410–422. [Google Scholar] [CrossRef]
- Bekdas, G.; Nigdeli, S.; Yang, X. Sizing optimization of truss structures using flower pollination algorithm. Appl. Soft Comput. 2015, 37, 322–331. [Google Scholar] [CrossRef]
- Tahani, M.; Babayan, N.; Pouyaei, A. Optimization of PV/Wind/Battery stand-alone system, using hybrid FPA/SA algorithm and CFD simulation, case study: Tehran. Energy Convers. Manag. 2015, 106, 644–659. [Google Scholar] [CrossRef]
- Dubey, H.; Pandit, M.; Panigrahi, B. Hybrid flower pollination algorithm with time-varying fuzzy selection mechanism for wind integrated multi-objective dynamic economic dispatch. Renew. Energy 2015, 83, 188–202. [Google Scholar] [CrossRef]
- Chakraborty, D.; Saha, S.; Maity, S. Training feedforward neural networks using hybrid flower pollination-gravitational search algorithm. In Proceedings of the 2015 International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), Noida, India, 25–27 February 2015; pp. 261–266.
- Liu, H.; Tian, H.; Liang, X.; Li, Y. New wind speed forecasting approaches using fast ensemble empirical model decomposition, genetic algorithm, Mind Evolutionary Algorithm and Artificial Neural Networks. Renew. Energy 2015, 83, 1066–1075. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Ahmadi, M.; Ahmadi, M.A.; Mehrpooya, M.; Rosen, M. Using GMDH Neural Networks to Model the Power and Torque of a Stirling Engine. Sustainability 2015, 7, 2243–2255. [Google Scholar] [CrossRef]
- Buratti, C.; Lascaro, E.; Palladino, D.; Vergoni, M. Building Behavior Simulation by Means of Artificial Neural Network in Summer Conditions. Sustainability 2014, 6, 5339–5353. [Google Scholar] [CrossRef]
- Sun, J.; Jia, M.; Li, H. Adaboost ensemble for financial distress prediction: An empirical comparison with data from Chinese listed companies. Expert Syst. Appl. 2011, 38, 9305–9312. [Google Scholar] [CrossRef]
- Yang, X. Flower pollination algorithm: A novel approach for multiobjective optimization. Eng. Optim. 2014, 46, 1222–1237. [Google Scholar] [CrossRef]
- Shen, F.; Chao, J.; Zhao, J. Forecasting exchange rate using deep belief networks and conjugate gradient method. Neurocomputing 2015, 167, 243–253. [Google Scholar] [CrossRef]
- Chen, H.; Hou, D. Research on superior combination forecasting model based on forecasting effective measure. J. Univ. Sci. Technol. China 2002, 2, 172–180. (In Chinese) [Google Scholar]
- Xiao, L.; Wang, J.; Hou, R.; Wu, J. A combined model based on data pre-analysis and weight coefficients optimization for electrical load forecasting. Energy 2015, 82, 524–549. [Google Scholar] [CrossRef]
- Diebold, F. Comparing Predictive Accuracy, Twenty Years Later: A Personal Perspective on the Use and Abuse of Diebold-Mariano Tests. J. Bus. Econ. Stat. 2015, 33, 1. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Experimental Parameters | Default Value |
|---|---|---|
| BP neural network | Neuron number of the input layer | 4 |
| Neuron number of the hidden layer | 9 | |
| Neuron number of the output layer | 1 | |
| Learning velocity | 0.1 | |
| Maximum number of training | 1200 | |
| Training requirement precision | 0.00002 | |
| FEEMD-CGFPA-ABBP | Iteration time | 50 |
| Learning rate | 0.05 | |
| Training requirement accuracy | 0.00002 | |
| Maximum generation | 10,000 | |
| Population size | 50 | |
| P | 0.8 | |
| Convergence tolerance | 10−6 | |
| Maximum generation of CGFPA | 5 |
| Model | Evaluation Criteria | Sites | ||||
|---|---|---|---|---|---|---|
| Site 1 | Site 2 | Site 3 | Site 4 | Site 5 | ||
| FEEMD- ABBP | AE (m/s) | 0.0852 | 0.1864 | 0.1099 | 0.1744 | 0.1200 |
| MAE (m/s) | 0.1487 | 0.3786 | 0.2267 | 0.2646 | 0.2312 | |
| MSE (m/s) | 0.0302 | 0.1803 | 0.0707 | 0.0895 | 0.0663 | |
| MAPE (m/s) | 3.2354 | 3.3234 | 4.2093 | 3.7402 | 3.7540 | |
| ABBP | AE (m/s) | 0.1075 | 0.2902 | 0.1494 | 0.1905 | 0.1169 |
| MAE (m/s) | 0.2029 | 0.5442 | 0.2594 | 0.3459 | 0.2764 | |
| MSE (m/s) | 0.0544 | 0.376 | 0.0853 | 0.1640 | 0.1034 | |
| MAPE (m/s) | 4.5266 | 4.5666 | 4.8317 | 4.9050 | 4.4512 | |
| Site | Promotion Rate of Forecasting Capability | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Site 1 | 36.3386 | 35.2563 | 40.2408 | 31.1205 | 20.4267 | 18.3870 | 33.0996 | 33.5240 | 32.4778 | 25.7482 |
| Site 2 | 23.0712 | 31.4124 | 34.9932 | 22.0215 | 25.3227 | 23.1669 | 29.1917 | 24.1436 | 30.2869 | 25.4095 |
| Site 3 | 52.3192 | 61.4874 | 47.4144 | 59.7580 | 76.4501 | 61.2227 | 70.6485 | 50.1049 | 49.1766 | 42.7902 |
| Site 4 | 43.3198 | 51.3352 | 53.5042 | 60.5825 | 48.1239 | 42.3182 | 49.9652 | 48.6674 | 55.7053 | 44.2340 |
| Site 5 | 86.0674 | 80.3252 | 77.3724 | 86.1126 | 80.3361 | 85.7961 | 69.6470 | 81.5168 | 78.4243 | 63.8969 |
| Site | Evaluation Criteria | Models | ||||||
|---|---|---|---|---|---|---|---|---|
| FEEMD-CGFPA-ABBP | FEEMD-ABBP | FEEMD-ELM | FEEMD-SVR | ABBP | BP | ARIMA | ||
| Site 1 | AE (m/s) | 0.0652 | 0.0852 | −0.017 | −0.0187 | 0.1075 | 0.1538 | 0.3126 |
| MAE (m/s) | 0.1262 | 0.1487 | 0.1410 | 0.1615 | 0.2029 | 0.3740 | 0.5422 | |
| MSE (m/s) | 0.0218 | 0.0302 | 0.0253 | 0.0298 | 0.0545 | 0.1930 | 0.3733 | |
| MAPE (%) | 2.4976 | 3.2354 | 2.7360 | 2.7669 | 4.5266 | 7.9524 | 11.6348 | |
| Site 2 | AE (m/s) | 0.1640 | 0.1864 | −0.0076 | −0.0047 | 0.2902 | 0.4340 | 0.7134 |
| MAE (m/s) | 0.2609 | 0.3786 | 0.3416 | 0.3652 | 0.5442 | 0.9066 | 1.3054 | |
| MSE (m/s) | 0.0882 | 0.1803 | 0.1206 | 0.1396 | 0.3760 | 1.0905 | 2.2854 | |
| MAPE (%) | 2.2495 | 3.3234 | 2.8442 | 2.9404 | 4.5666 | 7.6482 | 11.2185 | |
| Site 3 | AE (m/s) | 0.0602 | 0.1099 | −0.0066 | −0.0068 | 0.1494 | 0.2155 | 0.3122 |
| MAE (m/s) | 0.1218 | 0.2267 | 0.1582 | 0.1691 | 0.2594 | 0.5331 | 0.6358 | |
| MSE (m/s) | 0.0197 | 0.0707 | 0.0259 | 0.0299 | 0.0853 | 0.3699 | 0.5618 | |
| MAPE (%) | 2.2785 | 4.2093 | 2.9943 | 3.0380 | 4.8317 | 9.9003 | 11.9585 | |
| Site 4 | AE (m/s) | 0.0922 | 0.1744 | −0.0227 | −0.0230 | 0.1905 | 0.4120 | 0.5521 |
| MAE (m/s) | 0.1711 | 0.2646 | 0.2093 | 0.2247 | 0.3459 | 0.6555 | 0.9086 | |
| MSE (m/s) | 0.0396 | 0.0895 | 0.0460 | 0.0537 | 0.1640 | 0.5676 | 1.0972 | |
| MAPE (%) | 2.4397 | 3.7402 | 2.8666 | 2.8800 | 4.9050 | 9.4724 | 12.8022 | |
| Site 5 | AE (m/s) | 0.0699 | 0.1200 | −0.0189 | −0.0210 | 0.1169 | 0.4211 | 0.3741 |
| MAE (m/s) | 0.1472 | 0.2312 | 0.1794 | 0.1912 | 0.2764 | 0.6464 | 0.8339 | |
| MSE (m/s) | 0.0289 | 0.0663 | 0.0332 | 0.0381 | 0.1034 | 0.5399 | 0.8939 | |
| MAPE (%) | 2.3483 | 3.7540 | 2.6311 | 3.1857 | 4.4512 | 10.4892 | 13.7014 | |
| Site | Evaluation Criterion | ||||||
|---|---|---|---|---|---|---|---|
| FEEMD-ABBP | FEEMD-ELM | FEEMD-SVR | ABBP | BP | ARIMA | ||
| Site 1 | AE (m/s) | 23.4742 | 483.5294 | 448.6631 | 39.3488 | 57.6073 | 79.1427 |
| MAE (m/s) | 15.1259 | 10.4965 | 21.8576 | 37.7902 | 66.2501 | 76.7211 | |
| MSE (m/s) | 27.8250 | 13.8340 | 26.8456 | 59.9822 | 88.7101 | 94.1632 | |
| MAPE (m/s) | 22.8048 | 8.7135 | 9.7329 | 44.8246 | 68.5938 | 78.5337 | |
| Site 2 | AE (m/s) | 11.9941 | 2257.8947 | 3589.3617 | 43.4770 | 62.2130 | 77.0090 |
| MAE (m/s) | 31.0846 | 23.6241 | 28.5597 | 52.0548 | 71.2193 | 80.0101 | |
| MSE (m/s) | 51.0923 | 26.8657 | 36.8195 | 76.5499 | 91.9141 | 96.1417 | |
| MAPE (m/s) | 32.3128 | 20.9092 | 23.4968 | 50.7407 | 70.5879 | 79.9484 | |
| Site 3 | AE (m/s) | 45.2218 | 1012.1212 | 985.2941 | 59.7168 | 72.0808 | 80.7218 |
| MAE (m/s) | 46.2769 | 23.0088 | 27.9716 | 53.0581 | 77.1543 | 80.8458 | |
| MSE (m/s) | 72.1813 | 23.9382 | 34.1137 | 76.9516 | 94.6863 | 96.5019 | |
| MAPE (m/s) | 45.8686 | 23.9054 | 25.0000 | 52.8414 | 76.9850 | 80.9462 | |
| Site 4 | AE (m/s) | 47.1522 | 506.1674 | 500.8696 | 51.6149 | 77.6235 | 83.3040 |
| MAE (m/s) | 35.3134 | 18.2513 | 23.8540 | 50.5232 | 73.8924 | 81.1634 | |
| MSE (m/s) | 55.7549 | 13.9130 | 26.2570 | 75.8552 | 93.0221 | 96.3900 | |
| MAPE (m/s) | 34.7698 | 14.8922 | 15.2882 | 50.2596 | 74.2435 | 80.9427 | |
| Site 5 | AE (m/s) | 41.7288 | 469.8413 | 432.8571 | 40.1675 | 83.3896 | 81.3023 |
| MAE (m/s) | 36.3466 | 17.9487 | 23.0126 | 46.7615 | 77.2311 | 82.3511 | |
| MSE (m/s) | 56.3732 | 12.9518 | 24.1470 | 72.0441 | 94.6444 | 96.7654 | |
| MAPE (m/s) | 37.4465 | 10.7484 | 26.2862 | 47.2446 | 77.6125 | 82.8612 | |
| Site | Order | Forecasting Availability | ||||||
|---|---|---|---|---|---|---|---|---|
| FEEMD-CGFPA-ABBP | FEEMD-ABBP | FEEMD-ELM | FEEMD-SVR | ABBP | BP | ARIMA | ||
| Site 1 | 1st-order | 0.9750 | 0.9676 | 0.9701 | 0.9687 | 0.9547 | 0.9205 | 0.8837 |
| 2nd-order | 0.9618 | 0.9457 | 0.9534 | 0.9523 | 0.9214 | 0.8651 | 0.8143 | |
| Site 2 | 1st-order | 0.9775 | 0.9668 | 0.9709 | 0.9681 | 0.9543 | 0.9235 | 0.8878 |
| 2nd-order | 0.9644 | 0.9480 | 0.9554 | 0.9512 | 0.9310 | 0.8820 | 0.8247 | |
| Site 3 | 1st-order | 0.9772 | 0.9579 | 0.9663 | 0.9621 | 0.9517 | 0.9010 | 0.8804 |
| 2nd-order | 0.9633 | 0.9318 | 0.9466 | 0.9412 | 0.9264 | 0.8504 | 0.8093 | |
| Site 4 | 1st-order | 0.9756 | 0.9626 | 0.9672 | 0.9632 | 0.9510 | 0.9053 | 0.8720 |
| 2nd-order | 0.9604 | 0.9420 | 0.9499 | 0.9459 | 0.9208 | 0.8511 | 0.8055 | |
| Site 5 | 1st-order | 0.9765 | 0.9625 | 0.9671 | 0.9637 | 0.9555 | 0.8951 | 0.8630 |
| 2nd-order | 0.9631 | 0.9431 | 0.9531 | 0.9502 | 0.9292 | 0.8415 | 0.7935 | |
| Model | Bias-Variance | Diebold-Mariano Statistic Dt | |
|---|---|---|---|
| Bias | Var | ||
| FEEMD-CGFPA-ABBP | 0.0539 | 5.8145 × 10−3 | - |
| FEEMD-ABBP | 0.1084 | 7.8065 × 10−3 | 1.978135 ** |
| FEEMD-ELM | 0.0781 | 6.6987 × 10−3 | 1.690754 ** |
| FEEMD-SVR | 0.0911 | 6.9275 × 10−3 | 1.710435 ** |
| ABBP | 0.2611 | 1.4426 × 10−2 | 2.663514 * |
| BP | 0.3001 | 6.3582 × 10−2 | 2.980389 * |
| ARIMA | 0.4015 | 8.9901 × 10−2 | 3.115281 * |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heng, J.; Wang, C.; Zhao, X.; Xiao, L. Research and Application Based on Adaptive Boosting Strategy and Modified CGFPA Algorithm: A Case Study for Wind Speed Forecasting. Sustainability 2016, 8, 235. https://doi.org/10.3390/su8030235
Heng J, Wang C, Zhao X, Xiao L. Research and Application Based on Adaptive Boosting Strategy and Modified CGFPA Algorithm: A Case Study for Wind Speed Forecasting. Sustainability. 2016; 8(3):235. https://doi.org/10.3390/su8030235
Chicago/Turabian StyleHeng, Jiani, Chen Wang, Xuejing Zhao, and Liye Xiao. 2016. "Research and Application Based on Adaptive Boosting Strategy and Modified CGFPA Algorithm: A Case Study for Wind Speed Forecasting" Sustainability 8, no. 3: 235. https://doi.org/10.3390/su8030235