Analysis and Prediction of Dammed Water Level in a Hydropower Reservoir Using Machine Learning and Persistence-Based Techniques

 , , , and
, , , and
Abstract
:1. Introduction
- We show that the long-term persistence of the total amount of dammed water at Belesar reservoir has a clear yearly pattern, which supports the application of persistence-based approaches such as typical year or AR models.
- We show how ML techniques are extremely accurate in short-term prediction, involving exogenous hydro-meteorological variables.
- We evaluated the performance of a number of the ML regressors such as multi-layer perceptrons, support vector regression, extreme learning machines, or Gaussian processes in this problem of short-term prediction.
- We finally show how the seasonal pattern of dammed water is very accused in this prediction problem; thus, it can be exploited to obtain better prediction mechanisms, mainly in short-term prediction.
2. Data and Methods
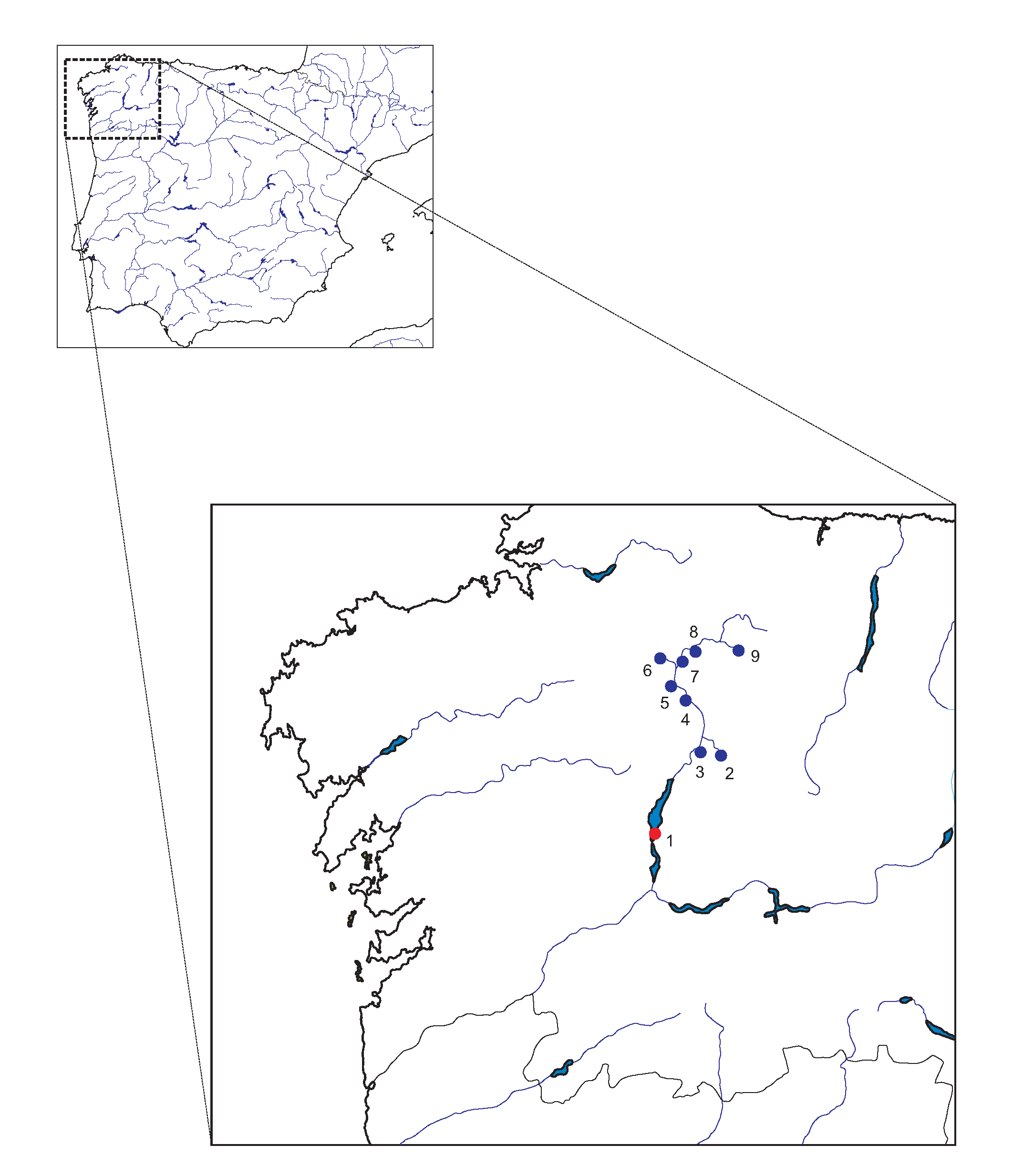
2.1. Data Description and Methodology
2.2. Detrended Fluctuation Analysis for Long-Term Persistence Evaluation
- (1)
- First, the periodic annual cycle of the time series is removed, by the procedure explained in detail in [27]. The process consists in standardizing the input time series of length N as follows:where stands for the original time series, represents the mean value of the time series, and is its standard deviation.
- (2)
- Then, the time series profile (integrated time series) is computed as follows:The profile is divided into non-overlapping segments of equal length s.For each segment , the local least squares straight-line is calculated, which measures its local trend. As a result, a linear peace-wise function compounding each linear fitting is obtained:where the superscript s refers to the time window length used to the linear fitting of each piece.
- (3)
- Then, the so-called fluctuation as the root-mean-square error from this linear piece-wise function and the profile is obtained, varying the time window length s:At the time scale range where the scaling holds, increases with time window s as power law . Thus, the fluctuation versus the time scale s would be depicted as a straight line in a log-log plot. The slope of the fitted linear regression line is the scaling exponent , also called correlation exponent. If this coefficient , the time series is uncorrelated, which means there is not long-term persistence in the time series. For larger values of , the time series are positively long-term correlated, which also means the long-term persistence exist across the corresponding scale range.
2.3. Auto-Regressive Moving Average Models
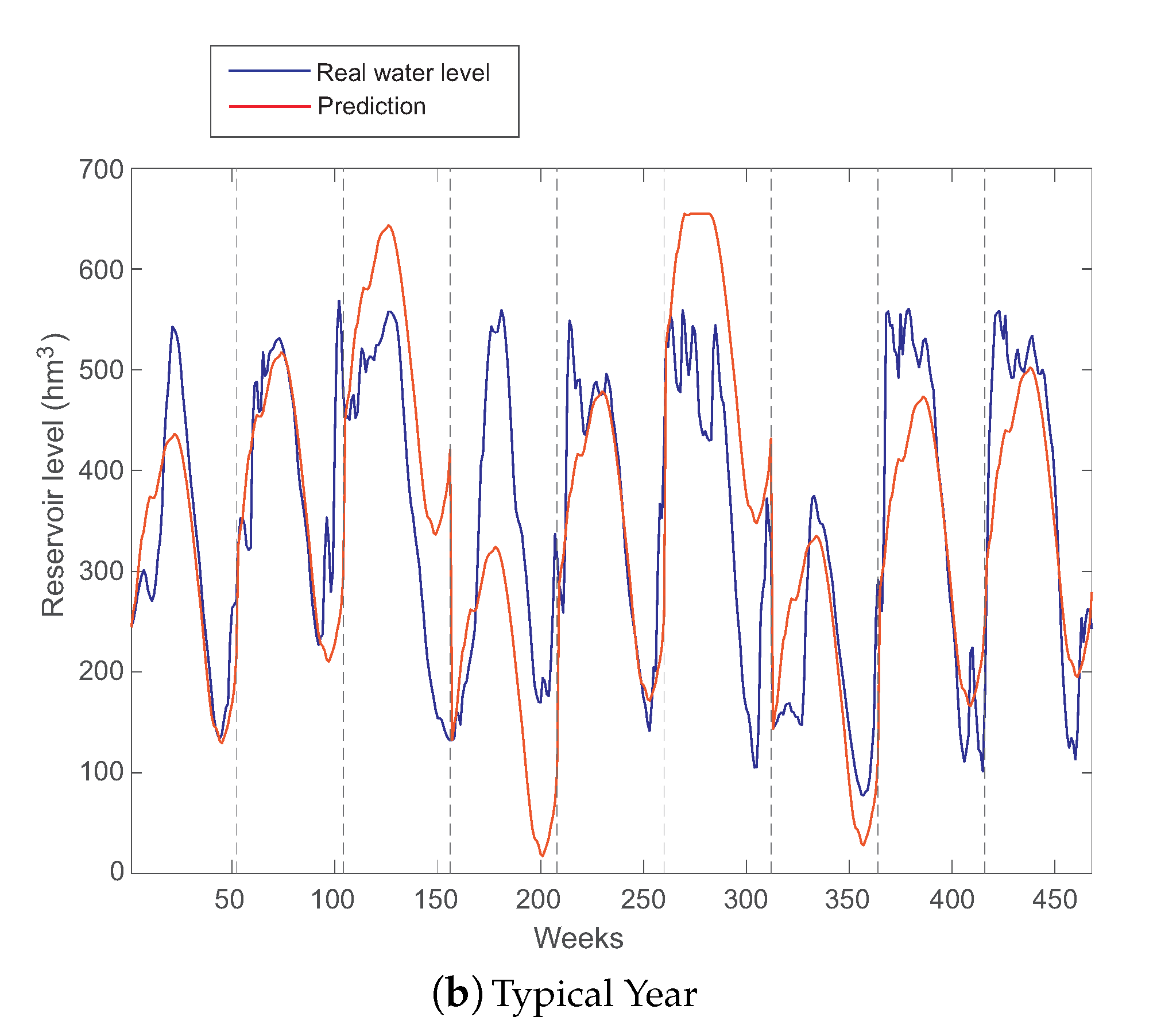
2.4. Typical Year Prediction Approach
2.5. Machine Learning Regression Techniques
2.5.1. Support Vector Regression
2.5.2. Multi-Layer Perceptrons
2.5.3. Extreme-Learning Machines
- 1.
- Randomly assign input weights and the bias , where , using a uniform probability distribution in .
- 2.
- Calculate the hidden-layer output matrix , defined as follows:
- 3.
- Calculate the output weight vector as follows:where is the Moore–Penrose inverse of the matrix [39] and is the training output vector, .
2.5.4. Gaussian Processes for Regression
3. Experiments and Results
3.1. Experimental Design
3.2. Long-Term Reservoir Level Analysis
3.3. Short-Term Reservoir Level Prediction
3.3.1. Standard Data, Random Partitioning
3.3.2. Standard Data, Temporal Partitioning
3.3.3. Seasonal Data, Temporal Partitioning
3.3.4. Discussion on Short-Term Prediction Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, D.; Lin, J.; Peng, Q.; Wang, D.; Yang, T.; Sorooshian, S.; Liu, X.; Zhuang, J. Modeling and simulating of reservoir operation using the artificial neural network, support vector regression, deep learning algorithm. J. Hydrol. 2018, 565, 720–736. [Google Scholar] [CrossRef] [Green Version]
- Lehner, B.; Liermann, C.R.; Revenga, C.V.; Vörösmarty, C.; Fekete, B.; Crouzet, P. High-resolution mapping of the world’s reservoirs and dams for sustainable river-flow management. Front. Ecol. Enviorn. 2011, 9, 494–502. [Google Scholar] [CrossRef] [Green Version]
- Akkose, A.; Bayraktar, A.; Dumanoglu, A.A. Reservoir water level effects on nonlinear dynamic response of arch dams. J. Fluids Struc. 2008, 24, 418–435. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, S.; Wang, G.; Han, Q.; Huang, G.; Wang, H.; Liu, Y.; Zhang, Y. Quantitative Assessment of the Influences of Three Gorges Dam on the Water Level of Poyang Lake, China. Water 2019, 11, 1519. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zheng, H.; Herron, X.; Liu, X.; Wang, Z.; Chiew, F.W.; Parajka, J. A framework estimating cumulative impact of damming on downstream water availability. J. Hydrol. 2019, 575, 612–627. [Google Scholar] [CrossRef]
- Chou, J.S.; Ho, C.C.; Hoang, H.S. Determining quality of water in reservoir using machine learning. Ecol. Inform. 2018, 44, 57–75. [Google Scholar] [CrossRef]
- Ahmed, U.; Mumtaz, R.; Anwar, H.; Shah, A.A.; Irfan, R.; García-Nieto, J. Efficient water quality prediction using supervised Machine Learning. Water 2019, 11, 2210. [Google Scholar] [CrossRef] [Green Version]
- Sentas, A.; Psilovikos, A. Comparison of ARIMA and Transfer Function (TF) Models in Water Temperature Simulation in Dam—Lake Thesaurus, Eastern Macedonia, Greece; Environmental Hydraulics—Christodoulou & Stamou, Ed.; CRC Press, Taylor and Francis Group: Boca Raton, FL, USA, 2010; Volume 2, pp. 929–934. [Google Scholar]
- Xu, C.; Xu, Z.; Yang, Z. Reservoir operation optimization for balancing hydropower generation and biodiversity conservation in a downstream wetland. J. Clean. Prod. 2019, 118885. [Google Scholar] [CrossRef]
- Jia, T.; Qin, H.; Yan, D.; Zhang, Z.; Liu, B.; Li, C. Short-Term Multi-Objective Optimal Operation of Reservoirs to Maximize the Benefits of Hydropower and Navigation. Water 2019, 11, 1272. [Google Scholar] [CrossRef] [Green Version]
- Wei, C.C. Wavelet kernel support vector machines forecasting techniques: Case study on water-level predictions during typhoons. Expert Syst. Appl. 2012, 39, 5189–5199. [Google Scholar] [CrossRef]
- Abdulkadir, T.S.; Salami, A.W.; Anwar, A.; Kareem, A.G. Modelling of hydropower reservoir variables for energy generation: Neural network approach. Ethiop. J. Enviorn. Stud. Manag. 2013, 6, 310–316. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, S.K.; Hossain, F. Maximizing energy production from hydropower dams using short-term weather forecasts. Ren. Energy 2020, 146, 1560–1577. [Google Scholar] [CrossRef]
- Yadav, B.; Eliza, K. A hybrid wavelet-support vector machine model for prediction of Lake water level fluctuations using hydro-meteorological data. Measurement 2017, 103, 294–301. [Google Scholar] [CrossRef]
- John, R.; John, M. Adaptation of the visibility graph algorithm for detecting time lag between rainfall and water level fluctuations in Lake Okeechobee. Adv. Water Res. 2019, 134, 103429. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, Y.; Liu, H.; Gao, H. In-situ water level measurement using NIR-imaging video camera. Flow Measur. Instrum. 2019, 67, 95–106. [Google Scholar] [CrossRef]
- Vanthof, V.; Kelly, R. Water storage estimation in ungauged small reservoirs with the TanDEM-X DEM and multi-source satellite observations. Remote Sens. Environ. 2019, 235, 111437. [Google Scholar] [CrossRef]
- Li, S.; Chen, J.; Xiang, J.; Pan, Y.; Huang, Z.; Wu, Y. Water level changes of Hulun Lake in Inner Mongolia derived from Jason satellite data. J. Vis. Commun. Image Rep. 2019, 58, 565–575. [Google Scholar] [CrossRef]
- Plucinski, B.; Sun, Y.; Wang, S.Y.; Gillies, R.R.; Eklund, J.; Wang, C.C. Feasibility of Multi-Year Forecast for the Colorado River Water Supply: Time Series Modeling. Water 2019, 11, 2433. [Google Scholar] [CrossRef] [Green Version]
- Pan, H.; Lv, X. Reconstruction of spatially continuous water levels in the Columbia River Estuary: The method of Empirical Orthogonal Function revisited. Est. Coast. Shelf Sci. 2019, 222, 81–90. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, P.; Zhao, Y.; Deng, C.; Li, Z.; Xiong, M. Error correction-based forecasting of reservoir water levels: Improving accuracy over multiple lead times. Environ. Model. Soft. 2018, 104, 27–39. [Google Scholar] [CrossRef]
- Goovaerts, P. Geostatistical prediction of water lead levels in Flint, Michigan: A multivariate approach. Sci. Total Enviorn. 2019, 647, 1294–1304. [Google Scholar] [CrossRef] [PubMed]
- Karri, R.R.; Wang, X.; Gerritsen, H. Ensemble based prediction of water levels and residual currents in Singapore regional waters for operational forecasting. Environ. Model. Soft. 2014, 54, 24–38. [Google Scholar] [CrossRef]
- Bazartseren, B.; Hildebrandt, G. Short-term water level prediction using neural networks and neuro-fuzzy approach. Neurocomputing 2003, 55, 439–450. [Google Scholar] [CrossRef]
- Chang, F.J.; Chang, Y.T. Adaptive neuro-fuzzy inference system for prediction of water level in reservoir. Adv. Water Res. 2006, 29, 1–10. [Google Scholar] [CrossRef]
- Wang, A.P.; Liao, H.Y.; Chang, T.H. Adaptive Neuro-fuzzy Inference System on Downstream Water Level Forecasting. In Proceedings of the 2008 IEEE Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Shandong, China, 18–20 October 2008; Volume 3, pp. 503–507. [Google Scholar] [CrossRef]
- Yang, S.; Yang, D.; Chen, J.; Zhao, B. Real-time reservoir operation using recurrent neural networks and inflow forecast from a distributed hydrological model. J. Hydrol. 2019, 579, 124229. [Google Scholar] [CrossRef]
- Chen, N.; Xiong, C.; Du, W.; Wang, C.; Lin, X.; Chen, Z. An Improved Genetic Algorithm Coupling a Back-Propagation Neural Network Model (IGA-BPNN) for Water-Level Predictions. Water 2019, 11, 1795. [Google Scholar]
- Samadianfard, S.; Jarhan, S.; Salwana, E.; Mosavi, A.; Shamshirb, S.; Akib, S. Support Vector Regression Integrated with Fruit Fly Optimization Algorithm for River Flow Forecasting in Lake Urmia Basin. Water 2019, 11, 1934. [Google Scholar] [CrossRef] [Green Version]
- Confederación Hidrográfica del Miño-Sil. Available online: https://www.chminosil.es/es/ (accessed on 23 March 2020).
- Climate Data Store. Available online: https://cds.climate.copernicus.eu/cdsapp#!/search?type=dataset (accessed on 23 March 2020).
- Yang, L.; Fu, Z. Process-dependent persistence in precipitation records. Phys. A 2019, 527, 121459. [Google Scholar] [CrossRef]
- Dey, P.; Mujumdar, P.P. Multiscale evolution of persistence of rainfall and streamflow. Adv. Water Res. 2018, 121, 285–303. [Google Scholar] [CrossRef]
- Box, G.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Salcedo-Sanz, S.; Rojo, J.L.; Martínez-Ramón, M.; Camps-Valls, G. Support vector machines in engineering: An overview. WIREs Data Min. Know. Disc. 2014, 4, 234–267. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprenhensive Foundation; Prentice Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y. Extreme learning machine: Theory and applications. Neurocomputing 2016, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cyber. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lázaro-Gredilla, M.; van Vaerenbergh, S.; NLawrence, N. Overlapping mixtures of gaussian processes for the data association problem. Patt. Recog. 2012, 45, 1386–1395. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E.; Williams, K.H. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Amari, S. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Mouselimis, L.; Gosso, A. ELM R Code and Documentation. Available online: https://cran.r-project.org/package=elmNNRcpp (accessed on 23 March 2020).
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.; Lin, C. e1071 Package. Available online: https://cran.r-project.org/package=e1071 (accessed on 23 March 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Blondel, M.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn Library. Available online: https://scikit-learn.org/stable/ (accessed on 23 March 2020).
- Denaro, S.; Anghileri, D.; Giuliani, M.; Castelletti, A. Informing the operations of water reservoirs over multiple temporal scales by direct use of hydro-meteorological data. Adv. Water Resour. 2017, 103, 51–63. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Series Descriptive Statistics | Water Level Data for Short-Term Prediction Since 2009 (hm) | Water Level Data for Long-Term Analysis Since 1964 (hm) |
|---|---|---|
| Minimum | 77.36 | 33.21 |
| 1st Quartile | 225.92 | 244.61 |
| Median | 374.92 | 391.64 |
| Mean | 354.42 | 371.80 |
| 3rd Quartile | 491.16 | 511.54 |
| Maximum | 560.68 | 653.62 |
| Standard Deviation | 147.19 | 161.00 |
| Dataset | Variables Included | Number of Variables |
|---|---|---|
| 1 | Upstream and tributaries’ flow | 19 |
| 2 | Upstream and tributaries’ flow & Precipitations | 28 |
| 3 | Upstream and tributaries’ flow, Precipitations & Reservoir output | 29 |
| 4 | Upstream and tributaries’ flow, Precipitations, Reservoir output & Snow data | 31 |
| MLP |
|---|
| Transfer function: {Logistic, Hyperbolic Tangent, ReLU} |
| Architecture: {25, 50, 75, 100, 125, 25:25, 50:50, 75:75, |
| 50:50:50, 75:50:25} |
| : |
| Learning rate: {, , , |
| , , , } |
| Training algorithms: |
| {Stochastic Gradient Descent: = {, , }, |
| Adam: = , = } |
| SVR Linear |
| C: |
| SVR rbf |
| C: |
| , |
| (where N is the number of input variables) |
| GPR |
| Kernel: {Dot Product, Radial, |
| Dot Product + White Noise} |
| ELM |
| Transfer function: {ReLU, Sigmoid, Radial} |
| Number of layers: 1 |
| Number of neurons: {50, 75} |
| Dataset | Model | RMSE (hm) | MAE (hm) |
|---|---|---|---|
| 1 | ELM | 33.68 | 19.61 |
| 1 | SVM (lin) | 35.85 | 22.76 |
| 1 | SVM (rbf) | 24.63 | 16.37 |
| 1 | MLP | 24.86 | 16.45 |
| 1 | GPR | 32.51 | 21.10 |
| 2 | ELM | 33.17 | 20.22 |
| 2 | SVM (lin) | 30.52 | 18.49 |
| 2 | SVM (rbf) | 30.63 | 22.42 |
| 2 | MLP | 22.94 | 16.28 |
| 2 | GPR | 36.91 | 21.57 |
| 3 | ELM | 32.50 | 17.93 |
| 3 | SVM (lin) | 28.72 | 15.58 |
| 3 | SVM (rbf) | 30.35 | 20.80 |
| 3 | MLP | 20.20 | 14.26 |
| 3 | GPR | 34.27 | 18.12 |
| 4 | ELM | 31.13 | 17.99 |
| 4 | SVM (lin) | 27.65 | 15.04 |
| 4 | SVM (rbf) | 29.79 | 20.24 |
| 4 | MLP | 20.44 | 14.04 |
| 4 | GPR | 36.22 | 18.29 |
| Dataset | Model | RMSE (hm) | MAE (hm) |
|---|---|---|---|
| 1 | ELM | 24.27 | 17.48 |
| 1 | SVM (lin) | 19.96 | 16.18 |
| 1 | SVM (rbf) | 19.34 | 14.55 |
| 1 | MLP | 21.66 | 17.24 |
| 1 | GPR | 21.74 | 18.28 |
| 2 | ELM | 24.86 | 18.31 |
| 2 | SVM (lin) | 25.35 | 20.79 |
| 2 | SVM (rbf) | 22.56 | 16.46 |
| 2 | MLP | 23.42 | 17.38 |
| 2 | GPR | 24.43 | 19.28 |
| 3 | ELM | 21.59 | 14.56 |
| 3 | SVM (lin) | 16.44 | 11.28 |
| 3 | SVM (rbf) | 19.28 | 12.09 |
| 3 | MLP | 21.12 | 15.17 |
| 3 | GPR | 17.00 | 11.99 |
| 4 | ELM | 22.87 | 15.10 |
| 4 | SVM (lin) | 18.60 | 12.74 |
| 4 | SVM (rbf) | 21.88 | 14.25 |
| 4 | MLP | 20.37 | 15.19 |
| 4 | GPR | 18.65 | 13.40 |
| Season | Model | Dataset | RMSE (hm) | MAE (hm) |
|---|---|---|---|---|
| Spring | SVR (Linear) | 3 | 17.41 | 13.94 |
| Summer | ELM | 1 | 7.83 | 5.73 |
| Autumn | Gaussian Process | 3 | 14.40 | 11.01 |
| Winter | SVR (RBF) | 1 | 22.14 | 15.39 |
| Average Metrics | 15.45 | 11.52 |
| Experiment | RMSE (hm) | MAE (hm) |
|---|---|---|
| Standard data, random partitioning | 20.20 | 14.26 |
| Standard data, temporal partitioning | 16.44 | 11.28 |
| Seasonal data, temporal partitioning | 15.45 | 11.52 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castillo-Botón, C.; Casillas-Pérez, D.; Casanova-Mateo, C.; Moreno-Saavedra, L.M.; Morales-Díaz, B.; Sanz-Justo, J.; Gutiérrez, P.A.; Salcedo-Sanz, S. Analysis and Prediction of Dammed Water Level in a Hydropower Reservoir Using Machine Learning and Persistence-Based Techniques. Water 2020, 12, 1528. https://doi.org/10.3390/w12061528
Castillo-Botón C, Casillas-Pérez D, Casanova-Mateo C, Moreno-Saavedra LM, Morales-Díaz B, Sanz-Justo J, Gutiérrez PA, Salcedo-Sanz S. Analysis and Prediction of Dammed Water Level in a Hydropower Reservoir Using Machine Learning and Persistence-Based Techniques. Water. 2020; 12(6):1528. https://doi.org/10.3390/w12061528
Chicago/Turabian StyleCastillo-Botón, C., D. Casillas-Pérez, C. Casanova-Mateo, L. M. Moreno-Saavedra, B. Morales-Díaz, J. Sanz-Justo, P. A. Gutiérrez, and S. Salcedo-Sanz. 2020. "Analysis and Prediction of Dammed Water Level in a Hydropower Reservoir Using Machine Learning and Persistence-Based Techniques" Water 12, no. 6: 1528. https://doi.org/10.3390/w12061528